- iOS/Androidアプリにおける状態管理の複雑さにリポジトリパターンを拡張して立ち向かう(1/3 考え方編) ← いまここ
- iOS/Androidアプリにおける状態管理の複雑さにリポジトリパターンを拡張して立ち向かう(2/3 実装方針編)
- iOS/Androidアプリにおける状態管理の複雑さにリポジトリパターンを拡張して立ち向かう(3/3 ライブラリ使い方編)
前置き
これはiOS/Androidに代表されるモバイルアプリにおいて、複雑になりやすい状態管理をリポジトリパターンの解釈を広げて解決しようという記事です。
今回説明するのはアプローチの一つなので、あくまでたくさんある意見の中の一つとして聞いて頂けると幸いです
iOS/Androidアプリにおける複雑さはどこから来るのか
最近のモバイルアプリは肝心なロジックはだいたいサーバーで持っていて、アプリはJsonなどのデータを受け取って表示するだけになっていることが多いも思います。
ただサーバーから渡されたデータを受け取って画面に表示するだけという、とてもとてもシンプルなことをしているはずなのにいつもバグに悩まされたりするのはなぜでしょうか?
状態管理の難しさ
私はiOS/Android等のモバイルアプリの複雑さの半分以上は状態管理から発生していると思っています。
サーバーから取得したデータをアプリ内キャッシュという形でSQLiteやSharedPreferences/UserDefaults等の設定値、あるいはRedux,FluxにおけるStoreという形で保持していることは多々あると思います。
それだけならまだしもiOS/Androidにおいては画面が重なっていくことも考えなければなりません。
それぞれの画面クラス(ViewController/Activity)やそれに付随するPresenterやViewModelでフィールド変数を持つことでその分状態の数(=インスタンス)が増えることがアプリにおける複雑さを加速させています。
アプリ内で明示的にキャッシュデータとして扱う気がなくとも、メンバー変数に値のコピーが渡った時点で事実上のキャッシュであるとみなすべきです。
そう考えればほとんどのアプリでオンメモリのキャッシュは持っていると捉えられると思います。
さらにいうと画面に描画された文字や画像も見方によってはキャッシュとみなせるでしょう。
 ***上記だけでもアプリ内に4つのキャッシュ(値のコピー)を持っていることがわかります***
***上記だけでもアプリ内に4つのキャッシュ(値のコピー)を持っていることがわかります***
そしてサーバー側のデータとそれら全てのキャッシュの整合性が常に保たれていないとアプリケーションは正しく動作しません。
どこかでずれが生じてしまうことで表示不具合や予期せぬ操作によるクラッシュにつながることがあります。
あるいは画面クラスに配置したデータの整合性を無理やり取ろうとして予期せぬ不具合を生んでいるケースもよく見かけます。
下記で2つのケースを紹介します。
ケース1: スプラッシュ画面でのキャッシュ構築
問題の一例としては、アプリ内のキャッシュありきで組まれている画面がある場合です。
よくあるのはアプリ起動時にスプラッシュ画面を表示して、API通信で必要な情報を取得しアプリ内にキャッシュとして取り込んでから本来の画面を開くケースです。
そしてその後はキャッシュがあるのが大前提で動作するというタイプのアプリは動作不良を生みやすいと考えます。

アプリを開く導線は一つとは限りません。
ホーム画面からアプリアイコンをタップする以外にも、通知から開いたりディープリンクやウィジェットから開かれるケースもあります。
そのような特殊な導線から開くと不具合を起こしたりキャッシュがないことでクラッシュに繋がったりしがちです。
もちろんあらゆるパターンをしっかり考慮してスプラッシュ画面を欠かさず通せば基本的には問題は起きないとは思いますが、
将来の開発までずっとヒューマンエラーのリスクは常に付きまといますし、あまりUXが良いとも言えないでしょう。
特定の画面の導線に頼ることなく、キャッシュありきでアプリケーションを動作させないようにし、
本当にそのデータが必要になったタイミングでキャッシュをなりAPIを参照するなりしてその画面自身が解決出来るようになるべきです。
ケース2: "いわゆる"いいねボタン問題
状態管理のよくあるシチュエーションの一つに「いいねボタン問題」というのがあります。
よくあるMater-Detailの画面構成をイメージしてみてください

ここでは選択したコンテンツに「いいね」が出来る機能があり、一覧画面と詳細画面いずれでもいいねが表示出来ると仮定します。
そして詳細画面にて「いいね」をタップした時をイメージしてください
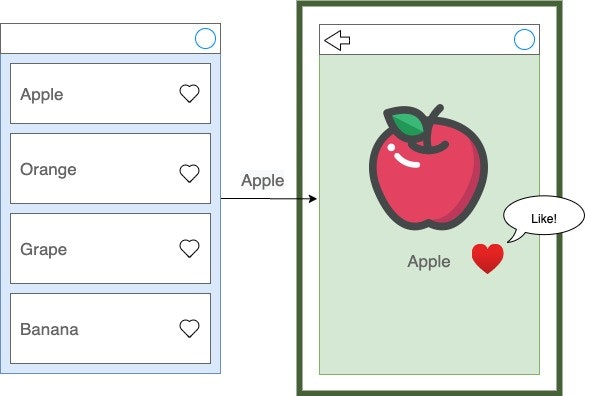
その後、一覧画面に戻ったら下記のように「Apple」というコンテンツにいいね(=ハート)は付いていてほしいですよね
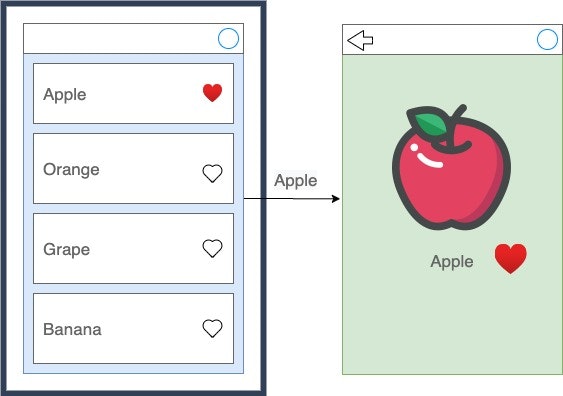
もちろん何も考えずに実装したら、一覧画面の「Apple」にはハートが付きませんよね
そこでなんらかの対応を取ると思いますが、どういった対応がよいでしょうか?
一番単純かつ最初に思いつくのは、詳細画面から一覧画面に戻る時にいいねを付けたというフラグを返してあげて、それを一覧画面側で受け取って表示を更新してあげることかもしれません。
もちろん今回のような単純な例であればそれで十分であることが多いと思いますが、プロダクトが成長してより複雑な画面構成になった場合はどうでしょうか?
以下のように複数の画面を経由する場合において「Orange」画面でいいねを付けた場合はどうでしょうか、一覧画面に戻るまでフラグを引きずり回すことになってしまいます。
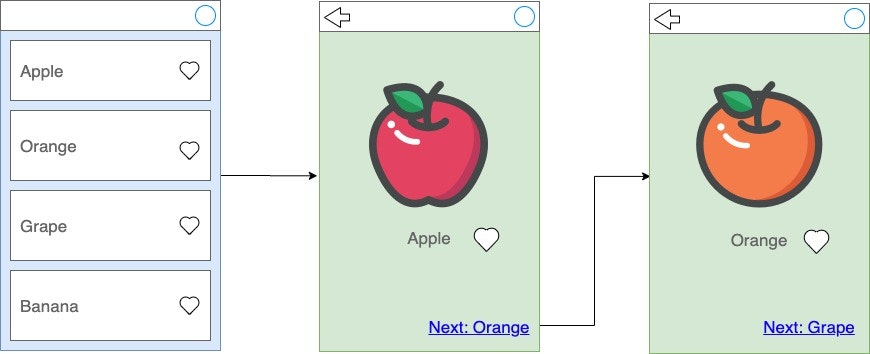
このようにアプリ内の至る所でキャッシュ(=フィールド変数)を持ってしまい、それがサーバーにあるデータと同期していないことで不具合や複雑さを生むということは多々あると思います。
リポジトリパターンを拡張して状態管理を解決する
これらの問題を解消するためにリポジトリパターンと、さらにSingle Source of Truth、Observerパターンという2つの要素を組み合わせてアプローチしてみます
リポジトリパターン
リポジトリパターンはすでに使っている方も多いのではないでしょうか。
Repositoryパターンとは「データをどこからどうやって取得するのかという技術的詳細を隠蔽して、抽象化したレイヤに任せることで保守や拡張性を高めるパターン」です。
データのI/O(入出力)に関して、特定の技術に依存したAPIやDBアクセス用のクラスやメソッドを直接使わず、共通化したRepositoryと呼ばれるレイヤーを通してアクセスさせるのが一般的です。
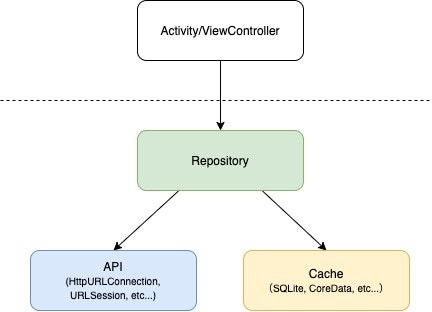
このようなパターンを取るメリットとしては、Repositoryを利用する側からはデータがDB上にあるのか、メモリ上にあるのか、はたまたサーバーにあるのかなどのデータがどこにあるかということと、そこから取得するための技術的詳細を知らなくてよいという事が挙げられます。
これによってRepositoryを利用する側からは
- 単純なデータのI/O(入出力)として扱うことが出来るため、コードをシンプルに保ちやすい
- Repository配下の部分をモックデータに差し替えやすくなり、テストも書きやすくなる。
- データ取得に関して変更が必要なコードがRepository配下に限定される
という利点が広く認識されていると思います。
リポジトリパターンでAPIとローカルキャッシュの兼ね合いをちゃんと隠蔽する
ここでリポジトリパターンの技術的詳細を隠蔽するという話を少し深堀りしたいと思います。
みなさんもリポジトリパターンはよく使われることが多いと思いますが、そのRepositoryクラスのメソッドは本当に技術的詳細を隠せているでしょうか?
例えば
- KotlinでAPI通信をしようとして
Retrofitライブラリを使うのか、Vollyライブラリを使うのか - SwiftでAPI通信をしようとして
AFNetworkingライブラリを使うのか、Alamofireライブラリを使うのか
はリポジトリパターンを使うことでうまく隠せているかと思います。
しかしながら、DBにアクセスしているRepositoryクラスのメソッドをそのままAPI通信して取ってくるように書き換えたら本当にそのまま動作するでしょうか?
メインスレッドで通信をしてしまったり、データの取得に時間がかかることを想定したUIになっていなかったりするのではないでしょうか?
データがローカルにあり、取得までの時間がほとんどかからないことを前提とした実装は真の意味で技術的詳細を隠せていないと私は考えています。
ローカルにデータがあろうがリモートにあろうが関係なく「データの取得」という粒度まで抽象化させることでRepositoryパターンの力を発揮できると思います。
Repositoryクラスの外側からは、
- データの取得に時間がかかるかもしれないしかからないかもしれない
- データの取得は失敗する可能性が常にある
ということだけを考えれば良いように作るべきと考えます。
もちろんデータ取得は非同期処理である可能性もあるので、一律非同期前提で組むのが良いと思います。
具体的にはRxJava,RxSwiftなどのリアクティブ系ライブラリにおける Observable などを戻り値として返すような形が好ましいです。
また、フルKotlinであればKotlin Coroutinesを使ってRepositoryクラスのメソッドをsuspend関数にしてあげることで非同期処理か否かを意識せずに扱えスッキリ書けますね。
interface MyRepository {
suspend fun getUser(): User
}
protocol MyRepository {
func getUser() -> Observable<User>
}
またRepositoryクラスにはキャッシュとAPIなどの取得先を区別したメソッドは作らないほうがよいです。
ローカルキャッシュを使うのか、APIからマスターデータを取得し直すのかはRepositoryクラスの内側で考えて外側にその都合を意識させないのがベストです。
有効なローカルキャッシュがあればそれを返却し、ローカルキャッシュが無効あるいは存在しない場合はAPIを通じて取ってくると言った具合です。
Repositoryのメソッド名もAPIを意識したfun fetchUser()やキャッシュから取ってくることを示すfun getCachedUser()などは避けるべきです。
このようなメソッドを作ってしまうと技術詳細を隠すことができず、その都合を外側に押し付けることになるためその分外側のコードが複雑になってしまいます。
簡単な例ですが、以下のようなケースは技術的詳細が外側に漏れ出してしてしまっています。
ゆえにその都合を解決するために条件式が外側に露出してしまっています。
var user = repository.getCachedUser()
if (user == null) {
user = repository.fetchUser()
}
このようなローカルキャッシュから取ってくるのかAPIから取ってくるのかといった都合をRepositoryクラス内に押し込むことで、外側からはデータを取ってくるということだけ注力すればよいようになり、外側から見た際にコードもシンプルになります。
val user = repository.getUser()
また、その他にもRepositoryパターンを組む上で気をつけたいのは、どこから取ってくるのかを抽象化するだけでなく何を使ってどうやって取ってきているかということも抽象化することです。
例えば、アプリ上でABテストを実施する際にFirebaseの機能であるRemoteConfigを使う場合にそれ特有である名前を付けることは避けましょう。
class RemoteConfigRepository {
....
}
これではRemoteConfigという技術的詳細がRepositoryクラスの外側に漏れ出してしまっているため、
本来の取得したいデータの名前であるABテストを取ってABTestRepositoryなどの名前のほうがよろしいかと思います。
class ABTestRepository {
....
}
Single Source of Truth
Single Source of Truthとは訳すと信頼できる唯一の情報源という意味合いで、有名なところだとReduxにて採用されている3原則の一つです。
Redux自体の説明は省きますが、ReduxではStoreと呼ばれる領域にデータを集約して、それをアプリケーション内で扱う唯一のデータとすることで個別の画面にデータの複製ができることがないようにし、状態管理をシンプルにしつつ不整合が起きないように考慮されています。

この原則を採用する際に注意したいのが、データを集約する場所を決めたらその外側でデータを保持してはいけないということです。
例えばこのSSOT原則を採用して一つのデータ源を作ったとして、その外側であるViewModel等で取得したデータをメンバー変数に独自に保持してしまったらこの原則は崩れてしまいます。
データを取得する場合は必ずそのデータ源から取得し、取得したデータは保持せず使い切ること(描画させる)を意識してください。
あるいはやむを得ず外側で保持する場合はデータ源にあるデータの変更に連動できるような仕組み(データバインディング等)を構築すべきです。
リモートにあるデータも含めたSingle Source of Truthを擬似的に実現する
仮にアプリ内ではデータを一元化してSSOT原則を確立したとしても、
サーバーが大前提にあるアプリの場合マスターデータはどうしたってサーバーにしかなくアプリ内にあるデータはあくまでキャッシュであることがほとんどです。
サーバーからのデータ取得と、キャッシュからのデータ取得で2つの情報源ができてしまいます。
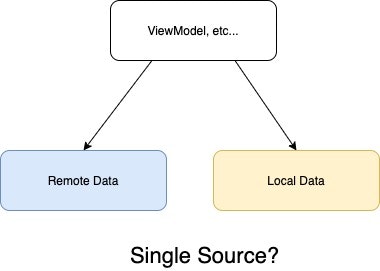
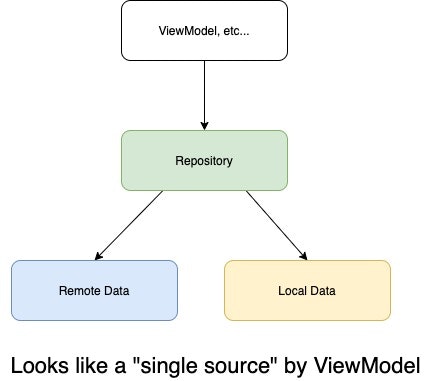
そこで組み合わせたいのがリポジトリパターンです。
どこからとってきたかという技術的詳細を抽象化する存在であるRepositoryを挟むことで、
外側から見たときに擬似的にSingle Source of Truthを実現させる(しているように見せる)ことが可能です。
この辺を組み合わせる具体的な実装の話は後ほど解説いたします。
Observerパターン
次にObserverパターンですが、これも自然と使っている方が多いと思います。
Observerとは観察者を意味する単語で、データの変更を監視して通知するための仕組みとして使われることが多いです。
代表的な実装としてはPub/SubライブラリやReactive系ライブラリが挙げられると思います。
具体的にはRxJavaやRxSwift,またKotlinであればFlowクラスを使ったり、SwiftであればCombineフレームワークに同様の機能が含まれています。
ここで重要なのはデータ側から変更を知らせてあげることができる点です。
この点はReduxでも採用されており、データが変わっているか変わっていないかわからないからとりあえずチェックしに行くというコードを排除することができます。
具体的には、AndroidにおけるonResume()やiOSにおけるviewWillAppear()が呼ばれるタイミングで雑にデータをロードし直すといったコードが不要になります。

画面側でデータの都合を考慮しなければならないことが減るため画面に表示されているデータとの不整合が減り、状態管理がよりシンプルになるはずです。
コードに落とし込むための追加の要素
ここまで状態管理における複雑さを解決するためのキーワードを解説してきました。
さらにこれに加えて実際のプログラムへ表現するにあたって必要な2つの要素を紹介します。
出来る限り早く値を返却する
これは言わずもがなですが、いくら非同期処理を前提に実装すると言っても毎回ユーザー待たせるのはUX的に良くないのでRepository内から返す値は可能な限り早く返す必要があります。
キャッシュが有効である限りは可能な限りキャッシュを使って値を返却させます。
データの状態を表現できる構造があること
データの実態とともに、今データが一体どういう状態なのかを表現できるようにしておいたほうがよいです
例えば以下のような情報です
- 今データが「処理していない」状態なのか、「読み込み中」の状態なのか、「エラー」の状態なのか
- 今データが「存在する」か、「存在しない」か
具体的なコードに落とし込むにあたり、
一例ですが以下のように実データをジェネリクスを使って保持できるクラスを用意しつつ、Observerパターンで状態の変化ごとに通知してあげることで表現できると思います。
sealed interface LoadingState<out T> {
data class Loading<out T>(val content: T?) : LoadingState<T>
data class Completed<out T>(val content: T) : LoadingState<T>
data class Error<out T>(val exception: Exception) : LoadingState<T>
}
enum LoadingState<T> {
case loading(content: T?)
case completed(content: T)
case error(error: Error)
}
実コードからは色々と省いていますが、イメージとしてはこのようなクラスで実データをラップすることでだいたいのシチュエーションに対応できると思います。
Repositoryパターンから返却する値としては以下になるイメージです。
interface MyRepository {
fun followUser(): Flow<LoadingState<User>>
}
protocol MyRepository {
func followUser() -> Observable<LoadingState<User>>
}
解決に必要な要素を整理する
改めてになりますが、以下の5つを要素を守りながらRepositoryパターンを実装をすることで
モバイルアプリにおける状態管理の複雑さを軽減させる一つのアプローチになり得るはずです。
- 使う側からキャッシュかAPIかなどどこから取ってきているかを意識させず整合性の取れた値を返す(Repositoryパターンの概念)
- 使う側でデータを変数などで保持せず、取得先を常に1箇所に絞る(Single Source of Truthの概念)
- データに変更があった場合は教えてくれる仕組みを用意する(Observerパターンの概念)
- 出来る限り早く値を返却する
- データの状態を表現できる構造が存在すること
大事なのは、上記の条件を満たしつつRepositoryクラスから返却されるインターフェースを柔軟性をもたせた上で安定させる(固定させる)ことです。
逆に言えば、気をつけなければならないのはそこだけです。他のものはあとからどうとでもなります。
インターフェース(=Protocol)さえ変わらなければ中身のコードの都合や修正に振り回されることなく、リファクタリングもしやすいはずです。
interface MyRepository {
fun followUser(): Flow<LoadingState<User>>
}
protocol MyRepository {
func followUser() -> Observable<LoadingState<User>>
}
個人的には、開発の初期でちょっと過剰じゃない?と思ったとしてもこのようなインターフェースにしておく価値はあると考えています。
また、今回説明したようなデータがあればそれを使い、なければ取ってくるといった挙動には別の利点もあって、サーバーから取得できるデータに関してはほとんど永続化させる必要がなくなるといったメリットもあります。
もちろんアプリ起動中はオンメモリで保持する必要はありますが、基本的にはどのタイミングでデータが揮発してもなんの問題もない作りになっているはずなので、SQLiteやCoreData、Realmなどのストレージ保存に頼る必要性が(大抵のAPI通信が前提で動くアプリでは)少なくなるはずです。
では、つぎにこれらを組み合わせて上記で紹介した複雑さの一例に対処してみます。
ケース1: スプラッシュ画面でのキャッシュ構築
スプラッシュ画面でキャッシュを積んでアプリ内ではキャッシュありきで動作しているケースも
Repositoryパターンを上記のルールのもと運用することであらゆる画面で有効なキャッシュがあればそれを使い、なければAPIで取ってくるという動作が強制されるため、スプラッシュ画面でキャッシュを積むという行為自体が不要になります。
つまり画面を開くためのキャッシュの前提条件を無くすことが可能(意識する必要がなくなる)で
スプラッシュ画面などの特定の画面を通るという導線に依存しなくなるので、より安全にアプリを運用できるはずです
ケース2: "いわゆる"いいねボタン問題
いいねボタン問題に対しても上記のルールに内包されているObserverパターンで解決することができます。
データを取得するという行為からデータを監視するという行為に変えることで、変更通知を受け取れるようにします。
またSingle Source of Truthが守られていればアプリ内で発生するあらゆるデータの変更をフックして通知を受けられるため、Repositoryの外側では常に整合性の取れたデータがリアルタイムに取得でき、「いいねをした」というフラグを画面間で引きずり回したり、画面が表示されたonResume()やviewWillAppear()などのタイミングでデータが変わっているかもしれないからチェックするといった行為も不要になります。
もちろんRepositoryの外側でデータの整合性を保つために、Repository内は整合性を取る処理を頑張る必要はあります。
例えば、いいねAPIを呼んでサーバーでいいねがされたらローカルキャッシュの情報も一緒に書き換えて整合性を取るなどの実装は必要になってくるかと思いますが、Repositoryの内側と外側で関心事が完全に分離するため外側はUIへの表示という仕事により注力できるはずです。
共通化出来る点とできない点
今回の話に沿ったRepositoryパターンを組むにあたって、Observerパターンを組み込んだりデータの状態を表現して通知する部分は共通化できます。
共通化できない部分としては実際にデータを取得・保存する部分とキャッシュの有効性を判断する部分が挙げられ、最低限必要な項目としては以下が挙げられます。
- データの状態を保持する機構
- キャッシュからの取得処理
- キャッシュへの保存処理
- API等のプライマリデータからの取得処理
- キャッシュが有効か否かの判断処理(時間、個数、etc..)
上記の5つがデータごとに実装が必要で、それ以外は基本的に変わることは少なく共通化出来る部分です。
以降の記事で紹介するライブラリもこの5つのみ実装すれば使えるように作ってあります。
[余談] Repositoryという名前
ここまでの内容はRepositoryパターンの延長という体でお話しましたが、本来はRepositoryクラスと聞くと単純なI/Oのみを扱うクラスをイメージする人が多いのではないでしょうか。
一つ前の画面のキャッシュが強く残るモバイルアプリにおいて単純なI/Oだけでは不十分だと感じたので本記事を書くに至ったわけですが、取得先の抽象化の他にReduxのような通知機能まで持つクラスを果たしてRepositoryクラスと呼んでいいのかは是非あると思います。
現在私の関わるプロダクトでは便宜上RepositoryというSuffixを使い続けていますが、人によっては大きく違和感を覚えることもあるかと思います。
そのような場合はSuffix名を変えたりするなどして開発メンバーの間で納得感のある命名に変えていくのがよいです。
ここまでのまとめ
今回は状態管理の複雑さに対処するための考え方の一つを紹介しました。
次回、次々回で具体的な実装への落とし込む方法や作成したライブラリの紹介もしますが、お伝えしたい本質は今回の記事にすべて詰まっています。
ぜひ、各アプリケーションに合わせた状態管理の設計を考えてみて下さい。
次回記事: iOS/Androidアプリにおける状態管理の複雑さにリポジトリパターンを拡張して立ち向かう(2/3 実装方針編)