紹介
この投稿は、Advent Calendar 2015 .. NextGen DistributedComputing system をキッカケにして初めています!
Advent Calendar1日目の記事です。
方針について
Spark、SparkStreamingが初めての方でも順を追っていただければスムーズに理解できるよう書きたいと思います。
開発はScalaベースです。Spark処理を書くためにScalaガッツり使いこなせないと分からないわけではないですが、
基本的なことは必要かと思います。
Scala基礎を習得するためには下記リンク先を参照することをお勧めいたします。
https://gist.github.com/scova0731/2c405ea55488d804b366
SparkStreamingの紹介
SparkStreamingとは
Sparkコアの拡張モジュールで、スケーラブル、高スループット、耐障害性を持ったlive-streamingデータを処理するもの。
データソースは、色々なところへ接続でき例えばKafka, Flume, Twitter, ZeroMQ, Kinesis, TCP sockets等から取り込める。
機能は、高レベル処理のmap, reduce, join, window等が使える。
最終結果は、filesystems, databases, live dashboardsにpush可能でマシーンラーニングやグラフ処理で使うことできる。

※引用元 http://spark.apache.org/docs/latest/streaming-programming-guide.html#overview
内部的には、SparkStreamingは入力streamを小さいbatch単位に分割し、Sparkエンジンでbatch処理している。
この処理を行うためにDStreamという抽象概念が実装されいる。
DStreamはSpark処理の基本単位であるRDDのシーケンスとなっている。
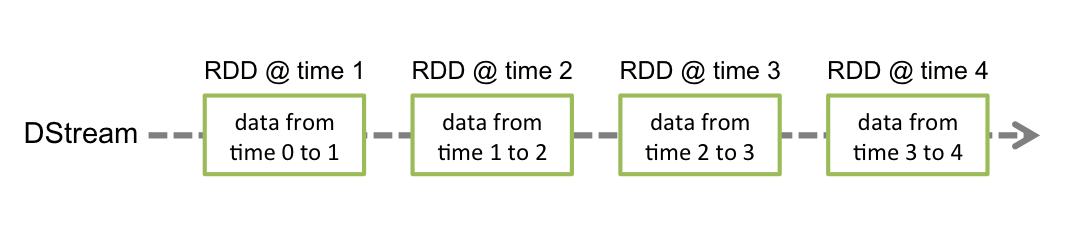
※引用元 http://spark.apache.org/docs/latest/streaming-programming-guide.html#discretized-streams-dstreams
Sparkとは
色々な用途に使える速い分散処理システム。Scala, Java, Python, Rで記述できる。
高度な処理を実行するためのツールとして、構造化されたデータに対するSparkSQL, 機械学習のためのMLlib,
グラフ処理のためのGraphX や ストリーム処理のためのSpark Streaming が使える。
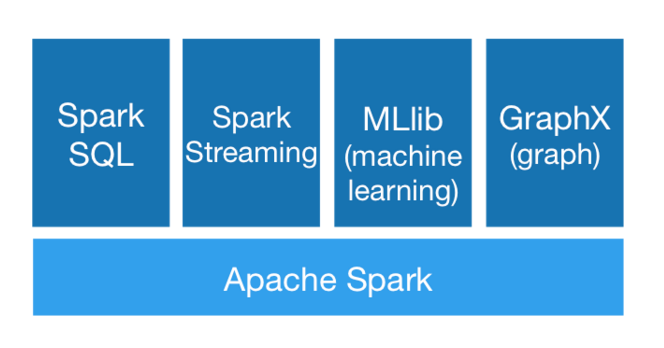 ※引用元 http://spark.apache.org/docs/latest/index.html
※引用元 http://spark.apache.org/docs/latest/index.html
手もとで簡単なサンプルを動かす。
ここでは実践的な開発へつなげるため、下記の紹介ガイドで紹介されているコードを手もとで動かすよう再実装しいきやす。
http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example
開発環境の準備
開発にはIntelliJ, scala_2.11, spark_1.5を使う
-
IntelliJを以下からDLする。(無料のCommunity Editionで問題なし)
https://www.jetbrains.com/idea/download/ -
sbt pluginインストール
IntelliJ起動後 sbt pluginをインストール -
IntelliJでのSpark設定は以下の記事がわかりやすい!
http://qiita.com/imaifactory/items/823caa33639196f5459a
コードを書く
- 本体:sbtプロジェクトのsrc > main > scalaに作る。
package org.apache.spark.examples.streaming
import org.apache.spark.{Logging, SparkConf}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
/**
* `$ nc -lk 9999`で入力データを設定する。
*/
object NetworkWordCount extends Logging {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(10))
// localhost:9999で入力を受つける。
val lines = ssc.socketTextStream("localhost", 9999, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
- build:sbtプロジェクトのbuild.sbtを上書き
※名前衝突を避けるためMerge Strategyを記述する。
https://github.com/sbt/sbt-assembly#merge-strategy より
name := "ss1"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.11" % "1.5.2",
"org.apache.spark" % "spark-streaming_2.11" % "1.5.2"
)
// Merge Strategy
assemblyMergeStrategy in assembly := {
case PathList("javax", "servlet", xs @ _*) => MergeStrategy.first
case PathList(ps @ _*) if ps.last endsWith ".class" => MergeStrategy.first
case "application.conf" => MergeStrategy.concat
case "unwanted.txt" => MergeStrategy.discard
case x =>
val oldStrategy = (assemblyMergeStrategy in assembly).value
oldStrategy(x)
}
- plugins:sbtプロジェクトのproject > plugins.sbtを上書き
logLevel := Level.Warn
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.13.0")
- github:以下に今回のコード〜参考までに
https://github.com/kaz3284/4qiita/tree/master/sparkstreaming/ss1
buildする
cd /Users/kaz3284/github/4qiita/sparkstreaming/ss1 #sbtプロジェクトのホーム
sbt assembly
実行する
-
準備
pre-build版をDLして実行環境を作る。※手もとでspark-submitを動かせるようにするため。- 下記リンク先で「1.5.2」「Pre-built for Hadoop 2.6 and later」を選択してDL、解凍して${SPARK_HOME}とする。
http://spark.apache.org/downloads.html
- 下記リンク先で「1.5.2」「Pre-built for Hadoop 2.6 and later」を選択してDL、解凍して${SPARK_HOME}とする。
-
sparkstreaming起動
Macで実行する場合の例
export SPARK_HOME=/Users/kaz3284/develop/spark/spark-1.5.2-bin-hadoop2.6
export SS_SRC=/Users/kaz3284/github/4qiita/sparkstreaming/ss1
${SPARK_HOME}/bin/spark-submit ${SS_SRC}/target/scala-2.11/ss1-assembly-1.0.jar
- ncでメッセージ送る
nc -lk 9999
hello world hello world hello world
hello world hello world
hello world
- 下記のような標準出力が出れば手もとで動かせるSparkStreamingプログラム完成!!

- 補足:開発時に余計なメッセージを消す場合は以下を実施する。
cp ${SPARK_HOME}/conf/log4j.properties.template ${SPARK_HOME}/conf/log4j.properties
vi ${SPARK_HOME}/conf/log4j.properties
- 以下のように標準出力の部分をINFO=> WARNへ
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
最後に
今回は手もとでイジれるSparkStreaming開発を作りました!
次からは今回作った開発環境を拡張して行きます〜
次回はより実践的な集計のDataFrame, SQLを使って実装します
SparkStreaming開発の参考までに
- Spark Streaming Programming Guide
http://spark.apache.org/docs/latest/streaming-programming-guide.html - spark git
https://github.com/apache/spark - spark docs
https://spark.apache.org/docs/1.5.0/api/scala/index.html#org.apache.spark.package