python初めて1年半の見習いです。
最近jupyter + SQLiteの組み合わせを使い始めて非常に
便利です。
ですがipython-sqlの導入時にちょっと苦労したのでその辺
を共有してみます。
自分のような初心者の助けになれば。
■自分の環境
・OS:Windows10
・Minicondaインストール済み(jupyter notebook使用可)
・データの分析で数M〜数十Mのcsvファイルを扱うので
Excelじゃツライ
・毎回read_csvするのもツライ。csvファイルがたくさん
あってファイルの管理もツライ
・かといってMySQLやPostgreSQL立てるのはちょっとアレ
■インストールするもの
・DB Browser for SQLite
・ipython-sql
■自分的結論
・データはSQLiteにまとめる
・データのSQLiteへの取り込みと簡単な内容チェックは
DB Browser for SQLiteでする
・データをガチャガチャやるときはjupyter notebookで
やる
■インストール
・DB Browser for SQLiteをインストール
(この辺はネットに情報が充実しているので省略)
・ipython-sqlのインストール
UbuntuならTerminalでpipすればさらっとインストール完了
するんですが、Windowsだとコマンドプロンプトでpip
できなかったので少し悩みました。
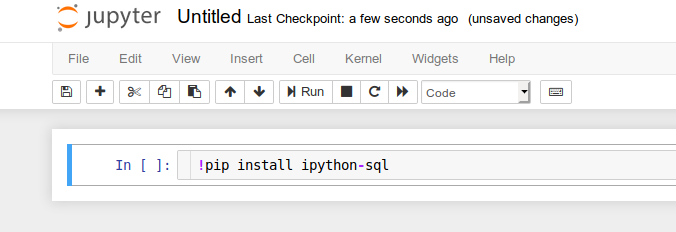
答えとしては、jupyter notebookで
!pip install ipython-sql
を実行しました。
■データの取り込み、テーブルの作成
・DB Browser for SQLiteでSQLiteファイルを開いてcsvを
インポートするのが楽と思います。
この辺も詳しい手順は省略。
■jupyterからSQLiteへの接続
PostgreやMySQLへの接続方法はネットに充実してたんですが、
SQLiteへの接続の情報はなかなかわかりづらくて苦労しました。
・前提条件
C:直下でjupyter notebookを開いてる
C:直下にデータを保存した「sample.sqlite3」がある
(要はnotebookと同じフォルダ内にsqliteファイルがある)
上記のような状態で下記を実行します
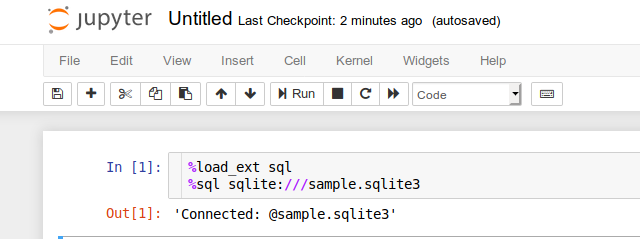
ポイントは「%sql sqlite:」の後はスラッシュ3本+カレント
ディレクトリにあるSQLiteファイル名。
これでsample.sqlite3に接続できました。
■データの取り出し
これでもうデータの取り出しはスイスイです。
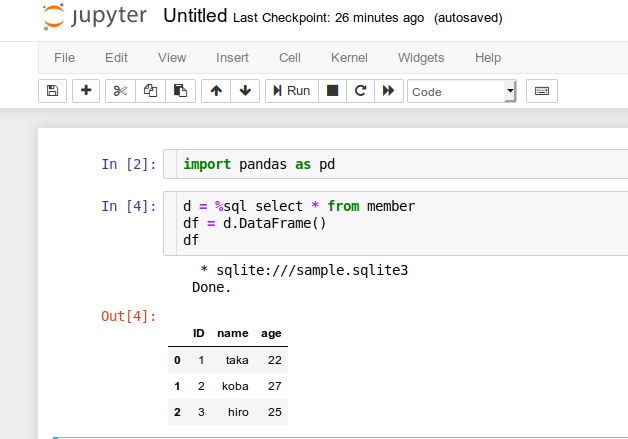
自分の場合はデータ取り出しと同時にpandasのデータフレーム
にしてしまいます。
なのでpandasもインポートしておきます。
例:テーブル「member」からデータ取り出し
あとはガチャガチャやるだけです。