ドキュメントの表記揺れ問題
複数人による共同作業で執筆や翻訳を行うと、用語の書き方が人によってまちまちで、最終的にそれを統一しなければならない。一人で作業していても、案外ばらつきがあったり、誤変換に気がつかないなど、用語のチェックと修正をする作業が必要になる。
今までに何回かそれなりのボリュームの文書を翻訳する機会があって、その度に自作ツールの greple を活用してきた。greple は、正規表現で文字列を検索できるだけではなく、マッチする条件を細かく指定することができる。たとえば参考文献のタイトルや引用文などを対象から外すことができないと実用的ではないのだ。実際のところ何年かに一度、翻訳仕事が入る度に進化してきた。
そもそもこのコマンドは、1990年代の初頭にWIDEプロジェクトの報告書の編集作業を助けるために作ったのが始まりだ。当時は mg (multi-line grep) という名前で、「がが」「にに」「のの」など、助詞の重複を見つけるのが当初の目的だった。その後、校正作業中に見つかったエラーを登録して使うようになった。2005年に出版した「BSDカーネルの設計と実装」の時に使用したファイルを整理すると、こんな具合だ。
送り仮名
[ 少い : 少ない ] [ 仕組み : 仕組 ]
片仮名表記
[ ヘッダー : へッダ ] [ インターネット : インタネット ] [ チェーン : チェイン ] [ ユーザ : ユーザー ] [ インタフェース : インタフェイス : インターフェイス ] [ シークエンス : シーケンス ] [ タイマー : タイマ ] [ スーパーユーザ : スーパユーザ ]
漢字/仮名
[ すべて : 全て ] [ まったく : 全く ] [ たとえば : 例えば ] [ みなす : 見倣す : 看做す ]
[ 通り : とおり : とうり ] [ 度々 : たびたび ] [ 時々 : ときどき ] [ 様々 : さまざま ] [ 元々 : もともと ] [ 次 : つぎ ] [ 大抵 : たいてい ] [ 諦める : あきらめ ] [ 様々 : さまざま ] [ 同士 : どうし ] [ 極めて : きわめて ] [ 続く : つづく ] [ 曖昧 : あいまい ] [ 出鱈目 : でたらめ ] [ 一体 : いったい ]
誤字/誤変換
[ 可能 : 加納 : 化膿 ] [ 解放 : 解法 ] [ 拡張 : 格調 ] [ 復号化 : 複合化 ] [ 対称型 : 対象型 ] [ リスト : リスと ]
訳語
[ ページフォルト : ページ例外 ] [ 無名オブジェクト : 匿名オブジェクト ] [ ソケット層 : ソケットレイヤ ] [ 補助データ : 付加データ ]
Greple subst モジュール
エラーを探すだけではなく、正しい表記に修正するために作ったのが subst モジュールだ。
たとえば、2014年に出版した「C/C++セキュアコーディング 第2版」の原稿に対して実行してみる。この本の原稿は、ちょっと特殊な HTML に近いフォーマットで執筆した。
<h1>Preface</h1>
<h1>はじめに</h1>
<p>
<p>
CERT was formed by the Defense Advanced Research Projects Agency
(DARPA) in November 1988 in response to the Morris worm incident,
which brought 10 percent of Internet systems to a halt in November
1988.
CERT は、1988年の Morris ワームによりインターネット上のシステムの10%が
停止するに至った事件を契機として、米国防総省国防高等研究計画局 (DARPA)
によって同年11月に設立されました。
CERT is located in Pittsburgh, Pennsylvania, at the Software
Engineering Institute (SEI), a federally funded research and
development center sponsored by the U.S. Department of Defense.
CERT は Pennsylvania 州 Pittsburgh の Software Engineering Institute
(SEI) の中にある研究開発センターで、米国防総省からの資金援助によって運
営しています。
</p>
</p>
見ればわかるように、原文と翻訳が空行を挟んで交互に書いてあり、奇数番目を集めれば原文、偶数番目を集めれば翻訳文ができあがるようになっている。この形式を処理するために greple の -Mbm といういモジュールを用意したが、その内容については詳しく触れない。
この本の校正用に用意した辞書ファイルはこのようなものだ。
([、。をがはにな])\g{-1} //
(?<!も)のの //
(?:へに|にへ) //
(一|ひと)つ // ひとつ
(迄|まで) // まで
(最早|もはや) // もはや
(関|かか)わらず // かかわらず
(或い?|あるい)は // あるいは
い[ずづ]れ // いずれ
(全|まった)く // まったく
[無な]し // なし
(大抵|たいてい) // たいてい
(頂|いただ)(?=[いか-こ]) // いただ
(?<!実)(行な?|おこな)(?=[いうえおわっ]) // 行
(?!もちろん)(?!もつなが)(持|も)(?=[ちつて]) // 持
(もっと|最)も(?!、) // 最も
(特|とく)に // 特に
(予|あらかじ)め // 予め
押さ?え // 押え
仕組み? // 仕組み
受け?[取と](?=[ら-ろっ]) // 受け取
呼び?出(?=[さしすせそ]?) // 呼び出
組み?込(?=[まみむめも]?) // 組み込
呼び?[出だ] // 呼び出
書き?換え? // 書き換え
割り?当て? // 割り当て
切り?捨て? // 切り捨て
受け?渡し // 受渡し
\p{Han}{2,}\K[付つ]き // 付き
オーバー?フロー? // オーバーフロー
プライバシー? // プライバシー
ディレクター? // ディレクター
プログラマー?(?!ズ) // プログラマ
コンパイラー? // コンパイラ
セキュリテ[イィ]ー? // セキュリティ
ユーティリティー? // ユーティリティ
バイナリー? // バイナリ
リンカー? // リンカ
フィルター? // フィルタ
バッファー? // バッファ
コンピューター? // コンピュータ
コンテナー? // コンテナ
プロセッサー? // プロセッサ
ヘッダー? // ヘッダ
パーミッ?ション // パーミッション
インター?フェ[ーイ]ス // インタフェース
ガー?ベ[イーッ]?ジ // ガベージ
パラメー?タ // パラメータ
コンテ[キク]スト // コンテキスト
プラット(ホ|フォ)ーム // プラットフォーム
アドレッ?シング // アドレッシング
ウ[イィ]ンドウ // ウィンドウ
ウ[イィ]ルス // ウイルス
ケ[イー]パビリティ // ケイパビリティ
コマンドライン // コマンド行
マイクロソフト // Microsoft
[返戻]り値 // 戻り値
検[査出]漏れ // 検出漏れ
[送発][信進]元 // 発信元
[送発][信進]先 // 送信先
サービス(妨害|不能)攻撃 // サービス不能攻撃
改(竄|ざん) // 改竄
仮[装想] // 仮想
(関節|間接) // 間接
国[歌家] // 国家
[再最](?=[高低上下]) // 最
中[段断] // 中断
[複復][号合](?![的型]) // 復号
[開解]放(?![的型]) // 解放
(?<!社会|安全)(保障|保証) // 保証
[平並]行 // 並行
[函関]数 // 関数
[気機]密 // 機密
[謝誤]ま?り // 誤り
辞書ファイルの形式は単純で、対象とする文字列にマッチする正規表現と、正しい表記を並べて書くだけだ。間の // あってもなくてもいいのだが、greple の -f オプションで同じファイルを指定した場合、// 以降はコメントとして無視される。
追記: 2024年のバージョン 3.24 から、// で区切られたパターンについては、その前後および行頭以外の空白文字が有効になるように仕様変更された。これによって、パターンや置換文字列に空白を入れることが可能になっている。// を含まないデータについては、空白で区切られた項目の最後の2つを、それぞれパターンと置換文字列として認識する。たとえば、3つ項目があったら、最初の1つは無視される。
パターンはそれほど複雑ではないので大体は見ればわかると思う。ただ、(?=...) (?!...) (?<=...) (?<!...) あたりは馴染みがない人もいるかもしれない。これは look-ahead, look-behind という記法で、日本語では「先読み」「後読み・戻り読み1」などと呼ばれている。意味は、上のパターンをじっくり眺めていればわかるんじゃないだろうか。ある位置の先あるいは手前に指定したパターンがあるかないかを判断するためのものだ。たとえば (?<!実)行 は、「行」にマッチするが「実行」の2文字目にはマッチしない。大方の「保障」は「保証」の間違いだが、「社会保障」と「安全保障」は例外、といった具合だ。肯定の look-behind は (?<=...) よりも \K を使った方がわかりやすいことも多い。
サマリー情報
■ --dict, --stat, --check=outstand
実際に、この辞書を使って原稿をチェックしてみる。辞書ファイルは --dict オプションで指定し、--stat オプションをつけるとサマリー情報を表示する。デフォルトでは --check=outstand を指定したのと同じで、正しい表記ではないものを発見した場合に限り、違反した表記を太字の白抜き、正しい表記を通常のフォントで表示する。
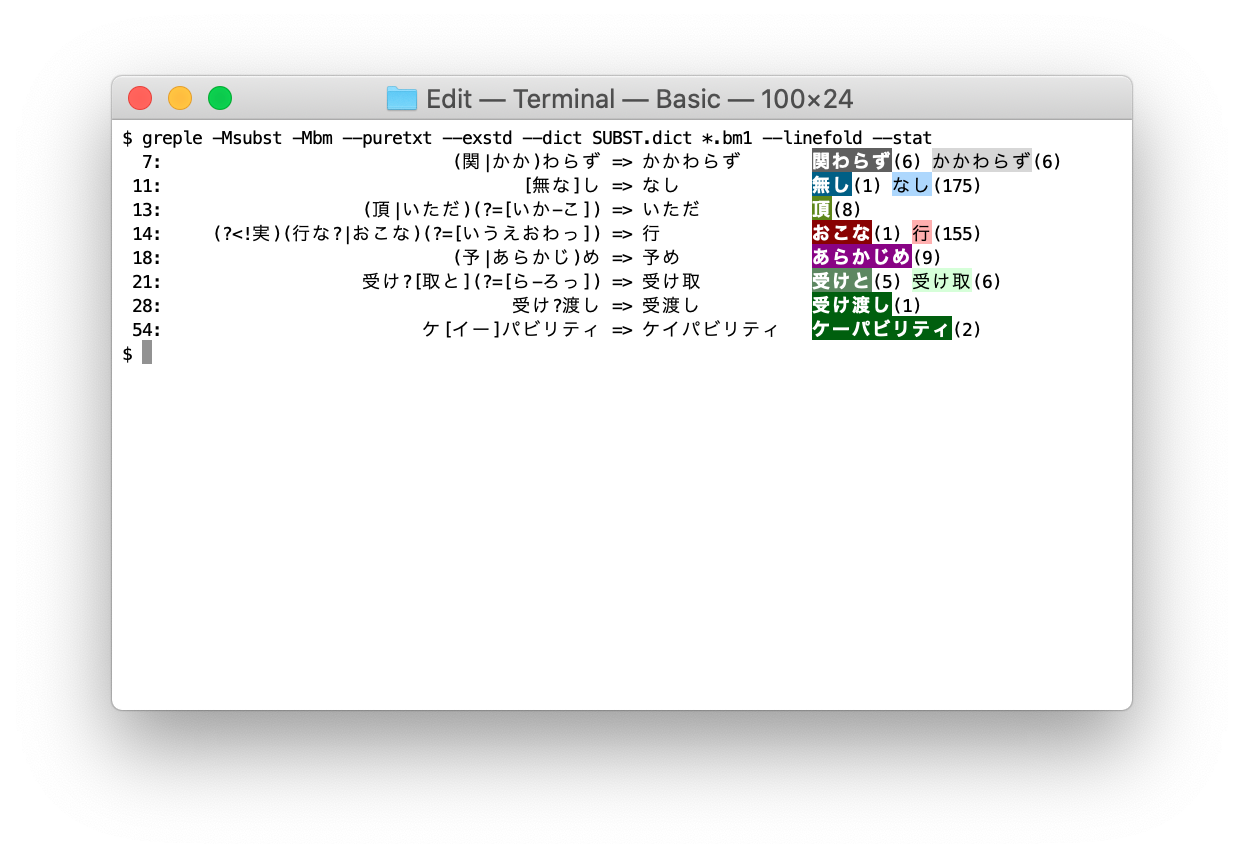
■ --check=[ok,ng,outstand,any,all,none]
マッチしたものをすべて表示したければ --check=any を指定する。ちなみに all はマッチしない項目も含めてすべて、ok は正しい表現、ng は違反表現、none はマッチしないものを示す。

検索
--stat オプションをつけなければ、マッチした行を表示する。--linefold オプションをつけると、単語の途中で改行されていても検索対象となる。先に書いたように、デフォルトでは --check=outstand が適用され、誤りが見つかったパターンについて正誤すべてを表示する。
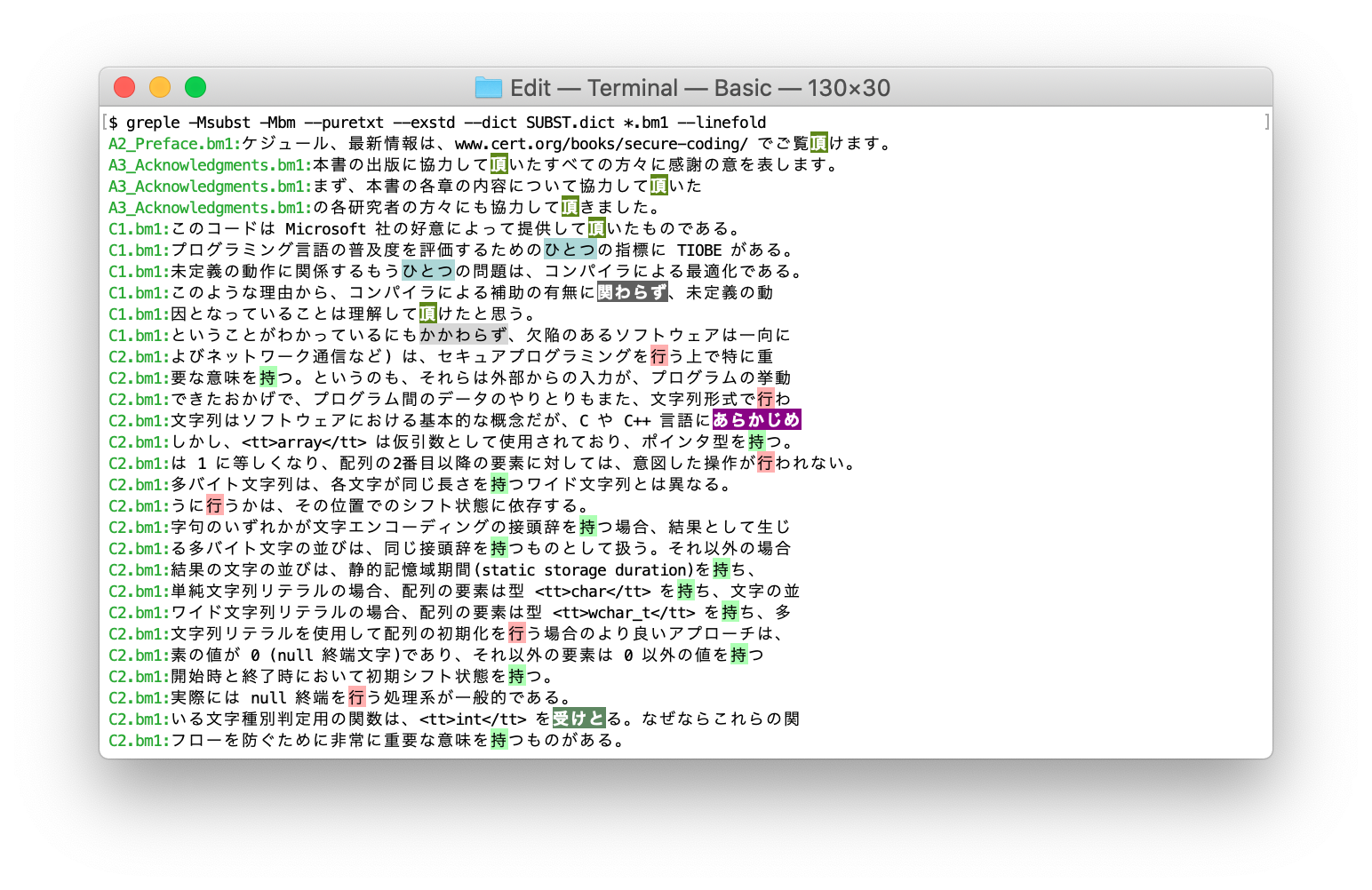
違反した行だけを表示したければ --check=ng オプションを指定する。

置換/編集
■ --subst
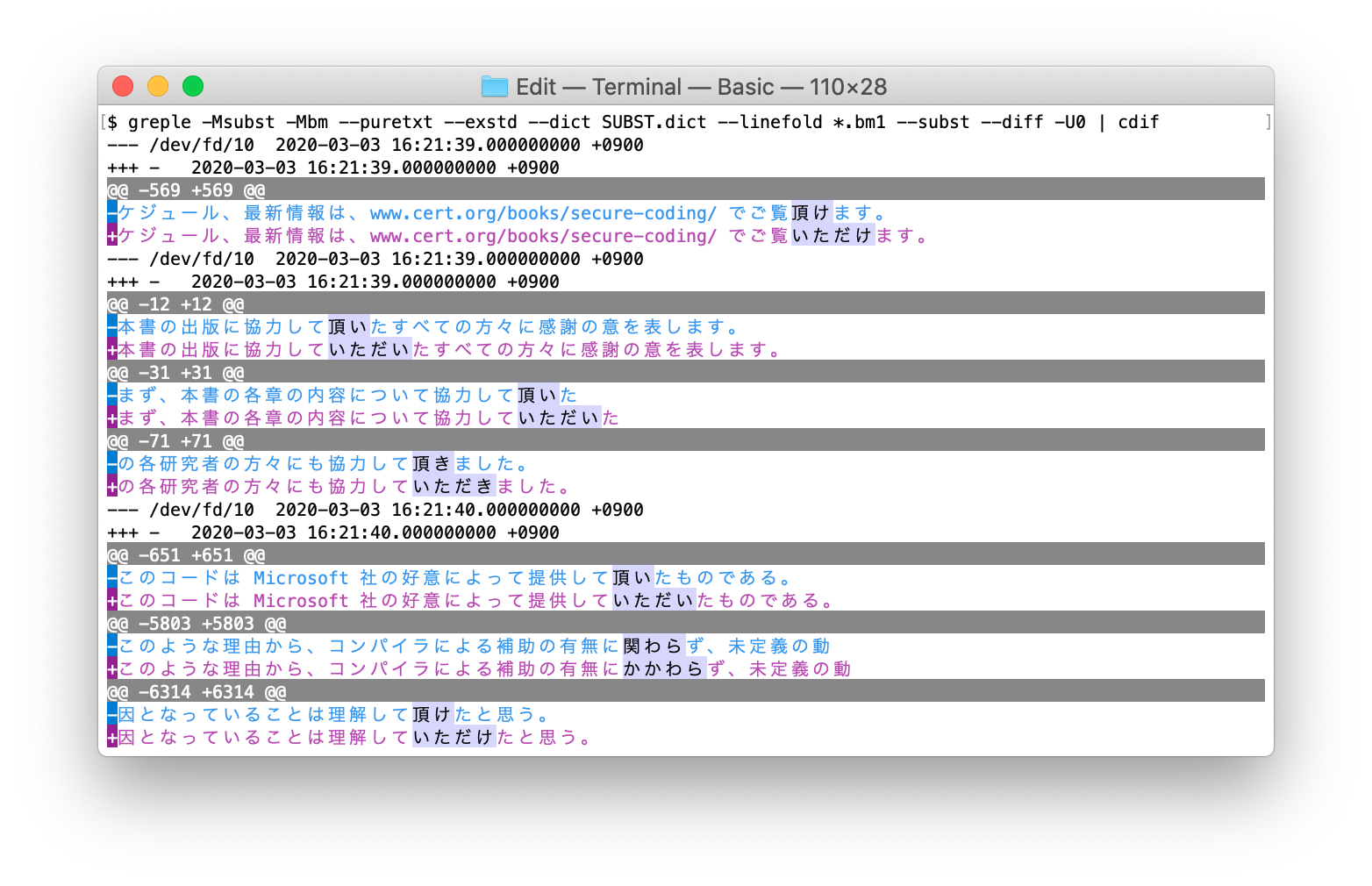
--subst オプションを付けると、違反した表記を正しい表記に置き換えて表示する。

■ --diff
変換後の結果を見てもピンとこないので、どのように変更されたか違いを見たい。そのためには --diff オプションを使用する。

どこが変更されたかわかりにくければ、たとえば cdif コマンドに通す。自分の環境では自動的に --mecab オプションが有効になっているので、mecab による形態素解析で分割された単位で比較している。
■ --replace, --overwrite
思ったように変更されていなければ、辞書ファイルを修正したり、greple のオプションで対象範囲を制限するなどして調整する。それが終わって、これでよしという状態になったら --replace オプションを使えばファイルを置き換えることができる。元のファイルは .bak という拡張子をつけて保存される。

追記: その後、git を使っている場合にはバックアップファイルが残るのが逆にわずらわしく思えてきたので、バックアップを残さない --overwrite というオプションを用意した。また、以前の仕様では、変更の有無にかかわらずファイルを更新してバックアップを残すようになっていたのだが、現在は変更があった場合のみ更新するようになっている。
■ git diff
git で管理していればこの状態で差分を見ることができる。

■ git add -p
何も問題がなければ、このまま git commit すればいい。
辞書ファイルや設定ではどうしても排除できない余計な修正が入っていた場合、git add -p コマンドを使えば、一つ一つ取捨選択することができる

ただ、これではどこが変わっているのかわかりにくい。1パラグラフが1文になっているような場合には一苦労だし、一箇所探すことはできたとしても、他にないことを確認するのはより困難だ。cdif のように色付けすることができればいいのだが、ちょっと調べた限りでは git にそのような機能はなかった2。いい方法があったら教えてほしい。
そこで git commit -p の出力をなんとかして cdif に通す方法を考えてみよう。
■ tmux + netcat
ターミナル用のマルチプレクサである tmux と netcat を組み合わせる。2つのウィンドウを開いて、一方で netcat -l -p 3333 | cdif を実行すると、3333番ポートで待ち受けた入力を cdif コマンドに与える。cdif は、diff 出力を発見すると変更点に着色し、それ以外のデータはそのままスルーする。
もう一方のウィンドウでは、セッションの出力を netcat localhost 3333 コマンドに送る。このためには tmux pipe-pane -o 'netcat localhost 3333' というコマンドを使う。

こうすると、下の画面で実行したコマンドの内容が、すべて上のウィンドウに送られるようになる。git diff を実行するとこんな具合だ。データは行単位でバッファリングされてしまうので、プロンプトは表示されていない。
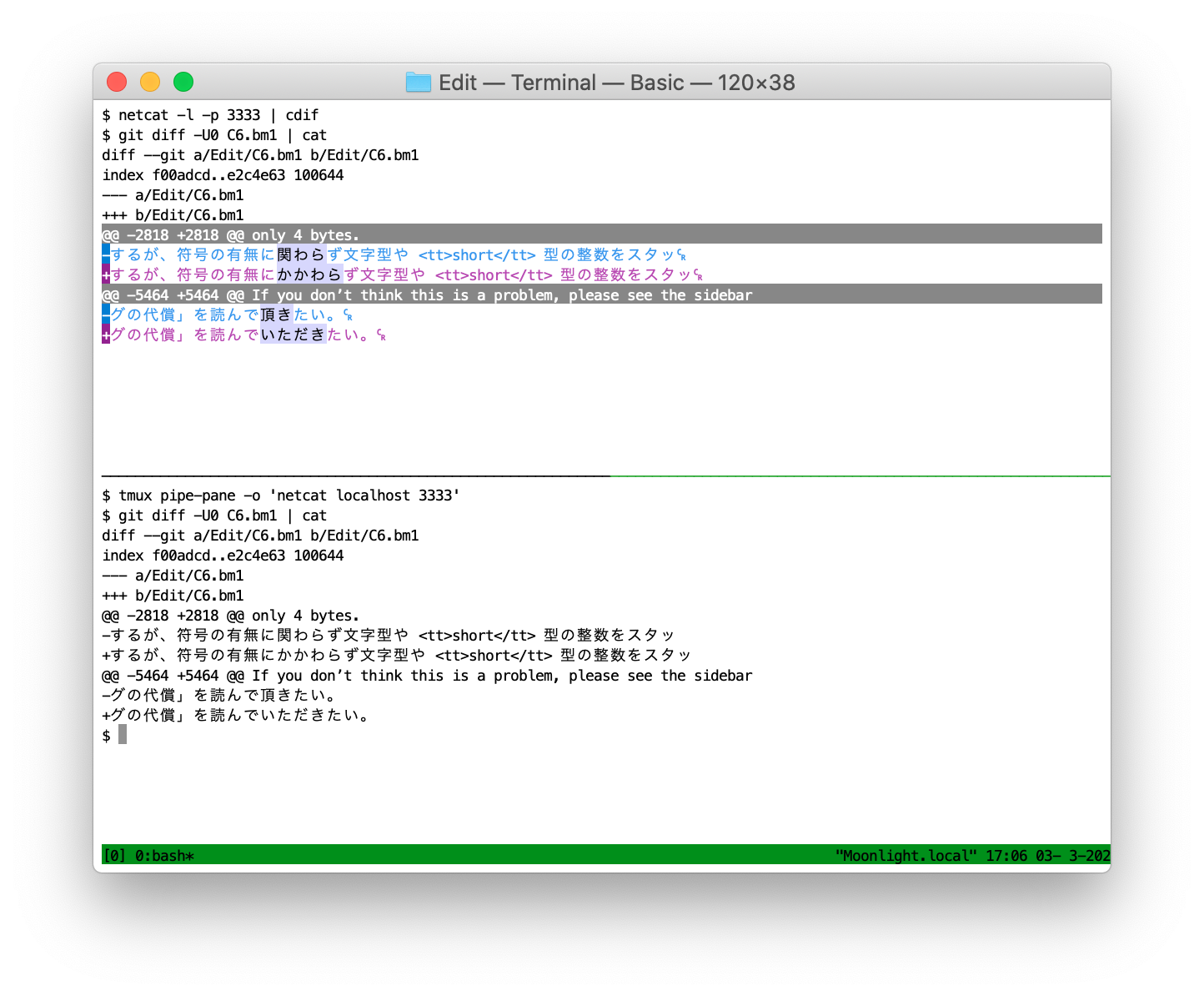
さて、この状態で git add -p コマンドを実行する。こうすれば、どこが変更されているのか一目瞭然だ。

JTCA の外来語ガイドライン
一般財団法人テクニカルコミュニケーター協会 (JTCA) という組織で作成した「外来語(カタカナ)表記ガイドライン」という資料があり、2015年に第3版が発行されている。この文書は外来語をどう仮名表記するかというもので、明らかに外来語ではない由緒正しき日本語である「片仮名」を「カタカナ」と表記するのはどうよと思うのだが、まあそれは置いておこう。
内容の好き嫌いは別にして、それなりにまとまった資料なので、このガイドラインを元にした辞書ファイルを作ってみた。ガイドラインには769語が登録されていて、短かすぎたり矛盾したりしている単語を外した739語が辞書ファイルには登録されている。
最初のカラムは、ガイドラインで適用されているルールだ。このように、subst モジュールの辞書は、最後の2カラムだけを使うようになっているので、その前には何を書いても構わない。

ご覧のように、検索パターンと置換文字列が同じものも含まれている。これは「アラート」を「アラアト」書くなど、今時あり得そうにないパターンは入れていないからだ。「ビルディング」は「ビルヂング」とも書くぞという意見はあるだろうが、意図せず間違って書く人などいるわけがない。むしろ「ビルヂング」を間違って「ビルディング」と書いてしまうのはありそうな話だ3。
ファイルはガイドライン中のデータから自動的に生成していて、プログラムも同梱してあるので修正したい方は自由にいじってくれて構わない。一応、あり得そうにないパターンも網羅する --monomania (偏執狂) というオプションも用意してあるのでどうぞ。
ちなみに、ガイドラインのデータには不備も見受けられる。たとえばルール (6) で "pre" は「プリ」と読むと決めているのだが、巻末の表からは抜けている。中途半端に直しても仕方ないと思いそのままにしてあるので、一度網羅的にチェックした方がいいと思う。
■ --jtca-katakana-guide
この辞書ファイルは App::Greple::subst の配布に含まれているので、自動的にインストールされる。そして --jtca-katakana-guide というオプションで指定することができる。
■ パナソニック「TH-P50/46/42G2(かんたんガイド)」
JTCA のページ にこう書いてある。

というわけでガイドに準拠しているという「かんたんガイド」をこの辞書でチェックしてみた。

おー、さすがだ。何も出ない。もう少し内容を調べてみよう。

「かんたんガイド」というくらいで量は少ない。では、ということで、同じ製品の「基本ガイド」に対しても適用してみる。

こちらはガイドラインに準拠するつもりはないようだ。パナソニックのこのガイドラインに対する意気込みはビミョーという感じだろうか。
■ 富士通「テレビ操作ガイド(2010春モデル)」
もう一つ、このガイドラインに従って作られているという富士通のマニュアルもチェックしてみる。

おっと、どうしたことだ。「ノートンインターネットセキュリティ」は仕方ないが、他の部分は意図的にガイドラインに従っていないように見える。
■ プログラミング演習 Python 2019
ちょうど上原先生の twitter で喜多一先生のプログラミング演習 Python 2019という CC-BY-NC-ND ライセンスで公開されている資料が流れてきたので、これを対象にしてみた。

「ウィンドウ」と「ボール」以外は最後の長音に関するものだ。ほとんどが意図的に選択され統一的に使われていて、極めて完成度が高いことがわかる。ただ、「ウインドウ」「コンピューター」「メモリー」「ユーザー」の4つは統一されていないように見える。
「ウインドウ」
文章中は「ウィンドウ」で統一されているが、プログラム中のコメントに1箇所「ウインドウ」表記があった。
「メモリー」
特定の単語に注目したい時には --select オプションで番号を指定することができる。
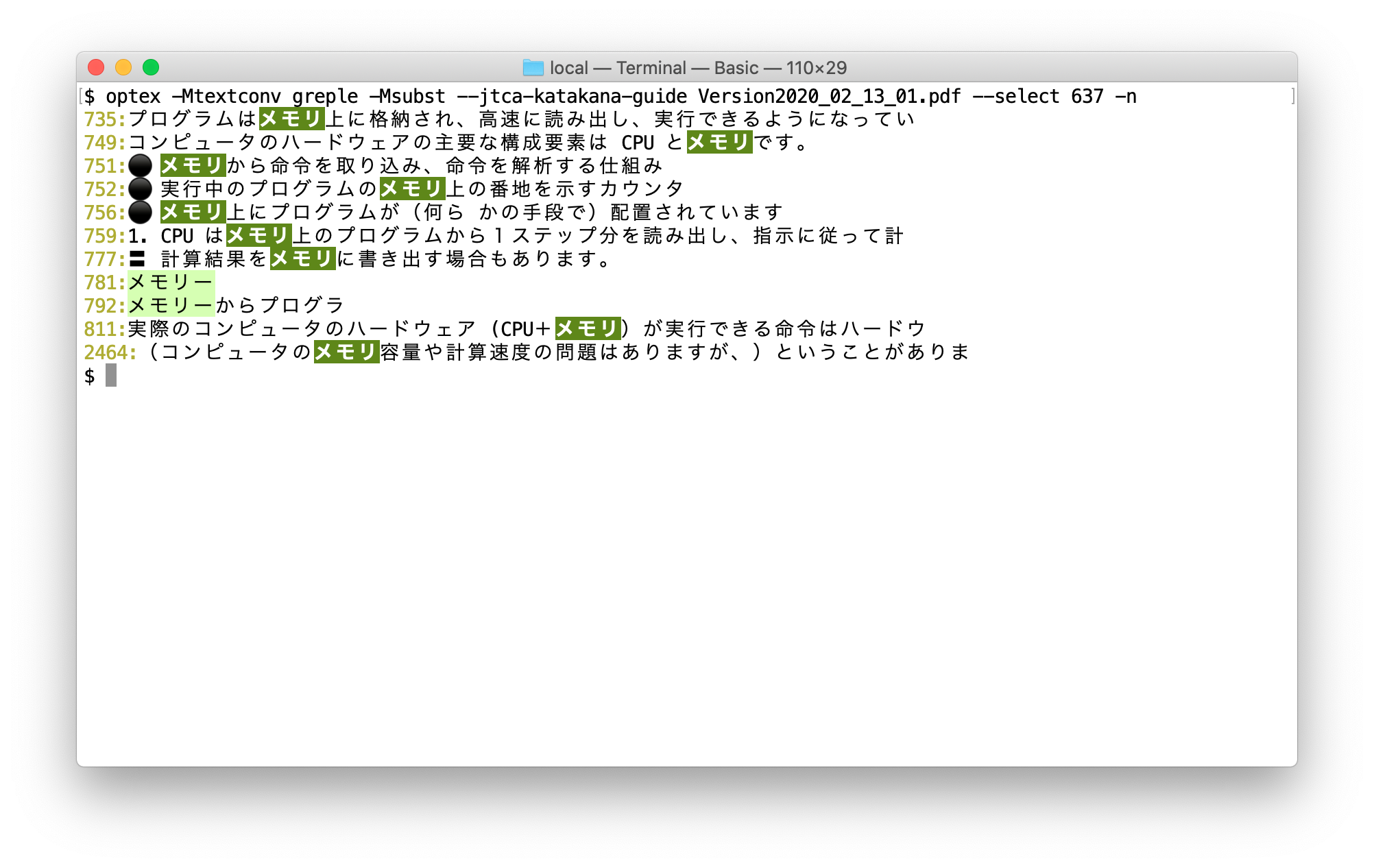
ほとんどが「メモリ」で統一されているが、2箇所だけ「メモリー」という表記がある。PDF を見てみると図の中で使われていた。これは誤記だろう。

「ユーザー」
次に「ユーザー」について調べてみる。
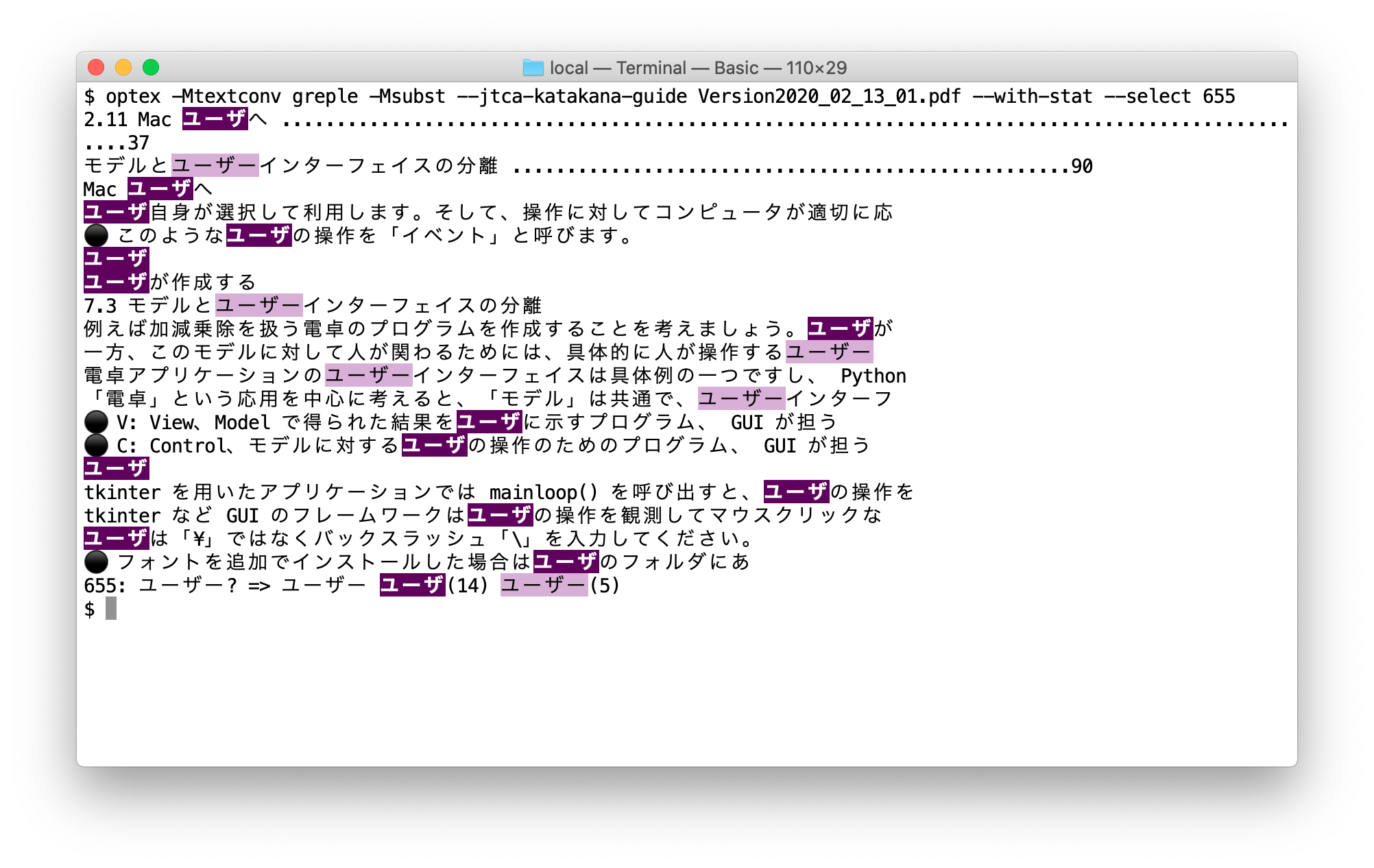
どうも利用者は「ユーザ」だが UI は「ユーザーインターフェイス」と表記しているらしい。greple の --outside オプションを使って「ユーザーインターフェイス」を検索対象範囲から外すとこうなった。

2箇所残っているが、これは「ユーザーインターフェイス」の途中で改行されているからだ。指定パターンを工夫すれば対応することもできるが、-p や -C オプションで周辺行を表示して確認すればいいだろう。
「コンピューター」
最後に「コンピューター」を見てみる。これは90箇所近くあるので5箇所ある「コンピューター」表記だけを表示する。この辞書では正しいパターンとされているので --check=ok オプションを指定する。

最初の例は「スーパーコンピューター」で、意図したものかは不明だ。残りはこれだけでは判断しにくいので -p オプションでパラグラフ単位で表示すると、どうやら引用文や書籍のタイトルであることがわかる。

辞書にない単語を探す
辞書にない片仮名単語にどんなものがあるか、辞書の最後に片仮名の連続にマッチするパターンを追加して実行するとこんな結果になった。このパターンはすべての片仮名単語にマッチするが、それ以前のマッチと重なるものは省くようになっている。その際、大量の警告が出るので --no-warn-overlap オプションをつけて抑制している。
$ optex -Mtextconv greple -Msubst --dict jtca-katakana-guide-3.dict+ Version2020_02_13_01.pdf --linefold --with-stat --check=any --no-warn-overlap

改行されてしまっているので、おかしなパターンも含まれている。「グロバール」「グルーバル」あたりは誤記だろう。Word のドキュメントを対象にすると、もっと有用な結果が得られるはずだ。この例で使っている optex -Mtextconv を使うと、PDF も docx ファイルも直接検索対象とすることができる。
最後から2番目のパターンは間に空白を含む片仮名の連続を検索していて、最後は単純に片仮名の連続を検索している。最初のパターンで パ ー ソ ナ ル コンピュータ にマッチした場合、すでに コンピュータ があるので選択されず、単独の パ ー ソ ナ ル がその後にマッチするらしい。
インストール
cpanm があれば、こうすれば App::Greple と App::Greple::subst モジュールがインストールされる。
$ cpanm App::Greple::subst
なければ、こうした方が早いかもしれない。
$ curl -sL http://cpanmin.us | perl - App::Greple::subst
記事の中で使っている App::sdif や App::optex::textconv なども同様。
マニュアルは、以下のような方法で読むことができる。
$ man App::Greple::subst
$ perldoc App::Greple::subst
$ greple -Msubst --man
github で subst を見てもらってもいい。
optex 等の使い方については以下の記事をどうぞ。
- MS Office ドキュメントや PDF ファイルを grep したり diff したりする - Qiita
- Word や PowerPoint のファイルを grep したり diff したりする - Qiita
-
オライリーの「詳説 正規表現」初版については監訳を担当し、タイトルも決めた。look-behind の訳語については、その時一番普及している用語として「後読み」を選んだんだったろうか。第2版の訳者である田和さんから「戻り読み」に変えたいという相談を受けて合意した。その後、今まで特に気にしたことはなかったが、今回改めて調べてみると「戻り読み」という訳語は定着していず、やはり「後読み」優勢のように見える。わかりにくいというのはその通りなので、では「後読み」という表記はそのままにして、読み方は「あとよみ」ではなく「うしろよみ」とすれば少しはマシなんじゃないかと思ったりした。少なくとも時間ではなく空間(方向)の問題だということはわかる。 ↩
-
git add -p を実行すると
git-add--interactiveという Perl スクリプトが実行される。ソースを斜め読みした限りでは、出力を操作するようなフックは見当たらない。 ↩ -
「ビルヂング」はなくなりつつあるようだ。https://style.nikkei.com/article/DGXBZO36894790Q1A131C1000000/ ↩