初投稿のテストを兼ねて。
greple の高速化
greple というコマンドを作っている (Markdown が壊れているのはご勘弁を)。
中身は少し気の利いた grep コマンドということだが、それは本題ではなく、こいつに正規表現で "." 、つまり1文字にマッチするパターンを検索させると、こういうひどい結果になる。
% wc -c C1.bm1
196483 C1.bm1
% time greple . C1.bm1 > /dev/null
62.587u 0.094s 1:02.71 99.9% 0+0k 0+0io 0pf+0w
もちろん、こんな使い方をするのが悪くて、マッチするパターンが少なければ、もっと普通の時間で終了する。
% time greple .+ C1.bm1 > /dev/null
2.353u 0.015s 0:02.37 99.5% 0+0k 0+0io 0pf+0w% time greple '(?=never)match' C1.bm1 > /dev/null
0.093u 0.010s 0:00.10 100.0% 0+0k 0+0io 0pf+0w
@- と @+ のアクセスが遅い
仕方ないかと諦めていたのだが、今日、ちょっとした変更を加えてみると、このように劇的に速くなった (とは言ってもまだ遅いのだが)。
% time greple . C1.bm1 > /dev/null
4.669u 0.056s 0:04.73 99.5% 0+0k 0+0io 0pf+0w
変えたのは一ヶ所だけで、
while (/pattern/g) {
my($s, $e) = ($-[0], $+[0]);
...
という部分を
while (/(pattern)/g) {
my($s, $e) = (pos() - length($1), pos());
...
にしただけ。
配列 @- と @+ には、マッチした先頭と末尾のオフセットが格納される。パターン全体が $-[0], $+[0]、最初のグループが $-[1], $+[1] という具合だ。pos() は、マッチした直後のオフセットを表すので $+[0] と同じ。そこからマッチした文字列の長さを引けば $-[0] と同じになるので、やっていることは同じ。
どうもこの配列にアクセスする負担が極端に大きいようなのだ。ただ、同じファイルに対して簡単なプログラムを作って試してみても、多少の差はあるものの、ここまでひどい違いは出ない。
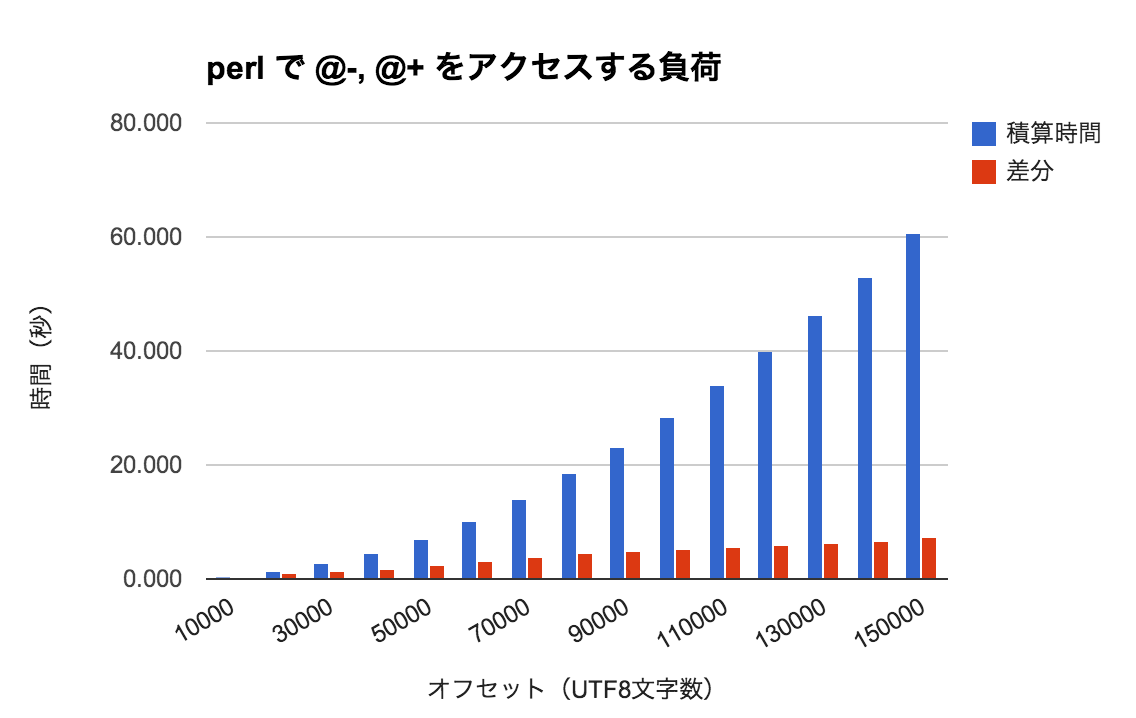
Unicode がいけないらしい
もう少し試してみると、utf8 から内部コードに変換するとひどいことになることがわかってきた。しかし、パターンマッチに時間がかかるのではなく、やはり配列にアクセスするのが遅く、これは pos() についても同様で、変換しない時に比べると極端に遅くなる。
そして、マッチ対象文字列の後ろに行けば行くほど指数関数的に遅くなっていく。先頭の10000文字の処理には0.34秒しかかからないのに、140000-150000文字を処理するのには7.43秒かかる。どうやら、値を求めるために、文字列の先頭から何かを計算しているような気がするのだ。
ちなみに、環境は OS X 10.9 標準の perl5.16。5.12 でも同様。これより新しいバージョンでは試していない。もう少し追求したいところだが、これにかまかけてると作業が進まないので、この辺で切り上げることにする。