-Msubst & -Mmsdoc
以前、こういう記事を書いた。これは辞書データに基づいて用語のチェックや一括置換をサポートするものだ。
その前にこういう記事を書いた。
これは、Micorosoft Office 文書をテキスト化して、通常のコマンドで処理できるようにするものだ。実装には、optex コマンドの textconv モジュールを使っている。最初の記事では greple の msdoc モジュールの中で実装しているが、これはその後 App::optex::textconv の機能を利用するように更新した。pptx のページ順序が正しくなかった問題も解決している。otpex は、次の記事で紹介している。
Word 文書を校正する
greple -Mmsdoc -Msubst ○○○.docx
さて、上記の手法を組み合わせると、Word 文書の内容を校正することができる。結果を見てもらった方が早いだろう。内閣官房が「オープンデータ基本指針」という文書を docx で配布しているので、それを対象にしてみる。短いので全部載せておこう
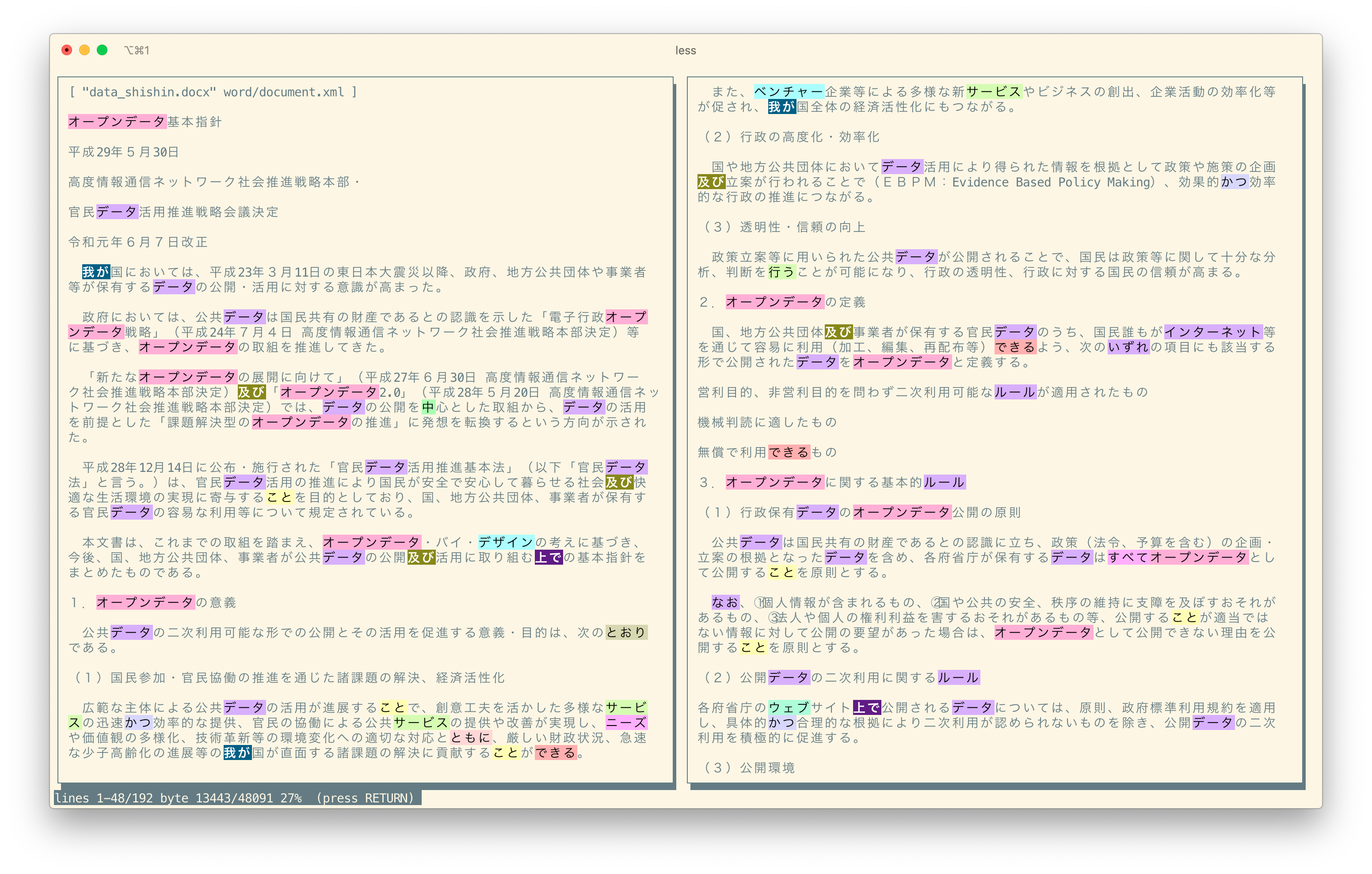



着色されているのはチェック対象になっている部分で、白抜きがルールに違反している用語だ。実行したコマンドはこれ:
greple -Mmsdoc -Msubst --all-sample-dict --check=any --all data_shishin.docx | ansicolumn -DPC2 --border=shadow-box | less
-Mmsdoc モジュールで Word 文書をテキスト化して、-Msubst モジュールの --all-sample-dict オプションでチェックしている。これは -Msubst モジュールに含まれている以下の3つのサンプル辞書をすべて適用するものだ。それぞれの辞書は、データから自動生成しているが、より実用的なものにするために若干手を入れてある。生成プログラムも含めて github に置いてあるので、興味のある方はご覧になってほしい。
- JTF日本語標準スタイルガイド(翻訳用) 第3.0版
- JTCA 外来語(カタカナ)表記ガイドライン 第3版
- Microsoft ローカリゼーション スタイルガイド
ansicolumn
そういえば、ansicolumn コマンドについてはまだ何も書いていなかった。これは column コマンドを ANSI シークエンスに対応させていたら、テキストデータのマルチカラムビューアになってきたものだ。この例では shadow-box というボーダースタイルを適用している (ただし、iTerm でないと綺麗に表示できない)。
仕様やインストール方法についてはこちらをどうぞ。禁則処理やページ末の単独行の排除など、ドキュメントを読みやすく表示する工夫がしてある。正直なところ、文字だけ読むならこっちの方が PDF より読みやすいと思う。
-Msubst --stat
結果だけを見たければこんな風だ。見やすいように、結果を少し加工してある。ansicolumn コマンドは、こんな風に使うこともできる。
全部で1531あるルールのうち48個が適用され、違反したパターンは36箇所ある。正常なパターンは257箇所だが、元々出所の異なる辞書を組み合わせているので、正か誤かに意味はない。
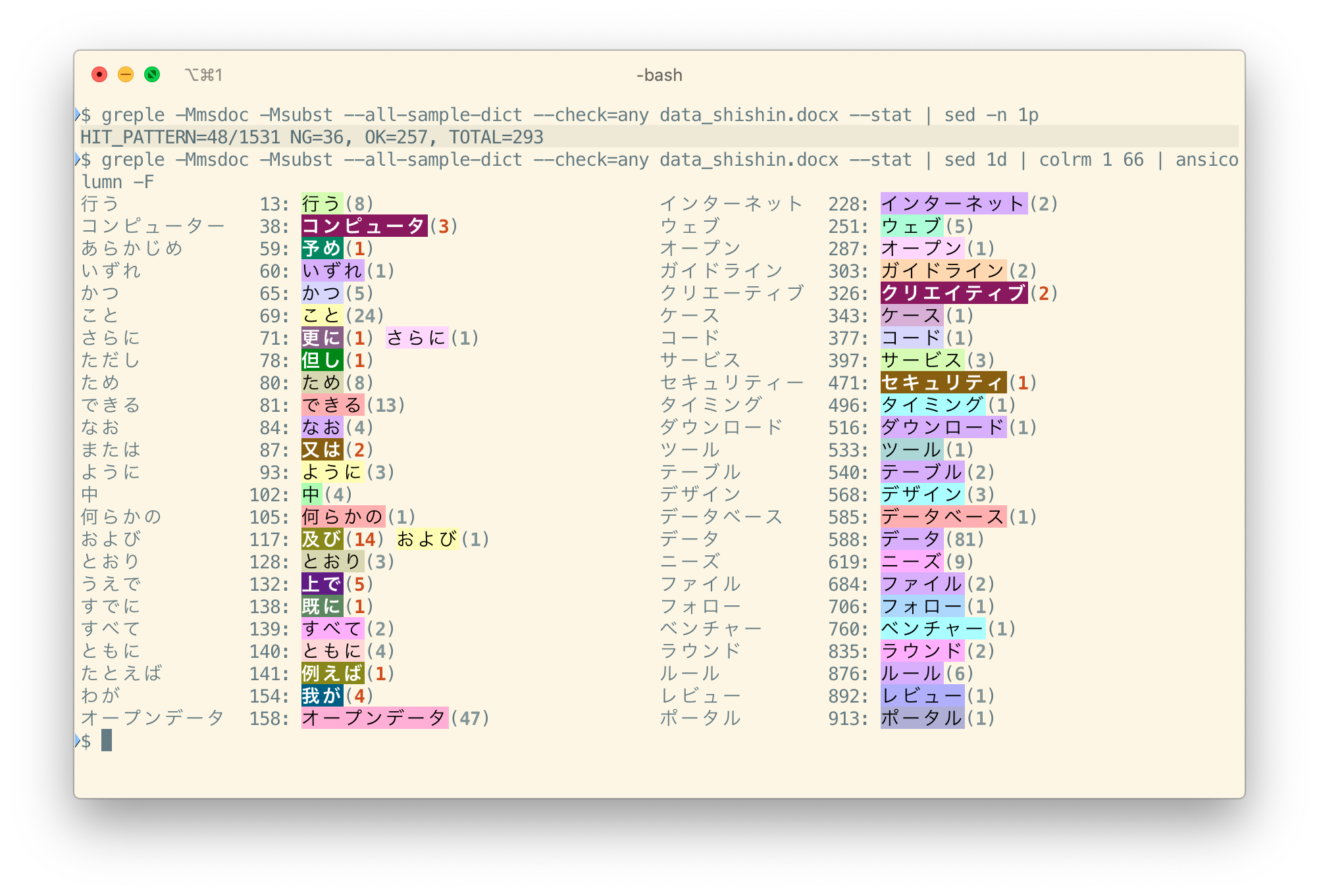
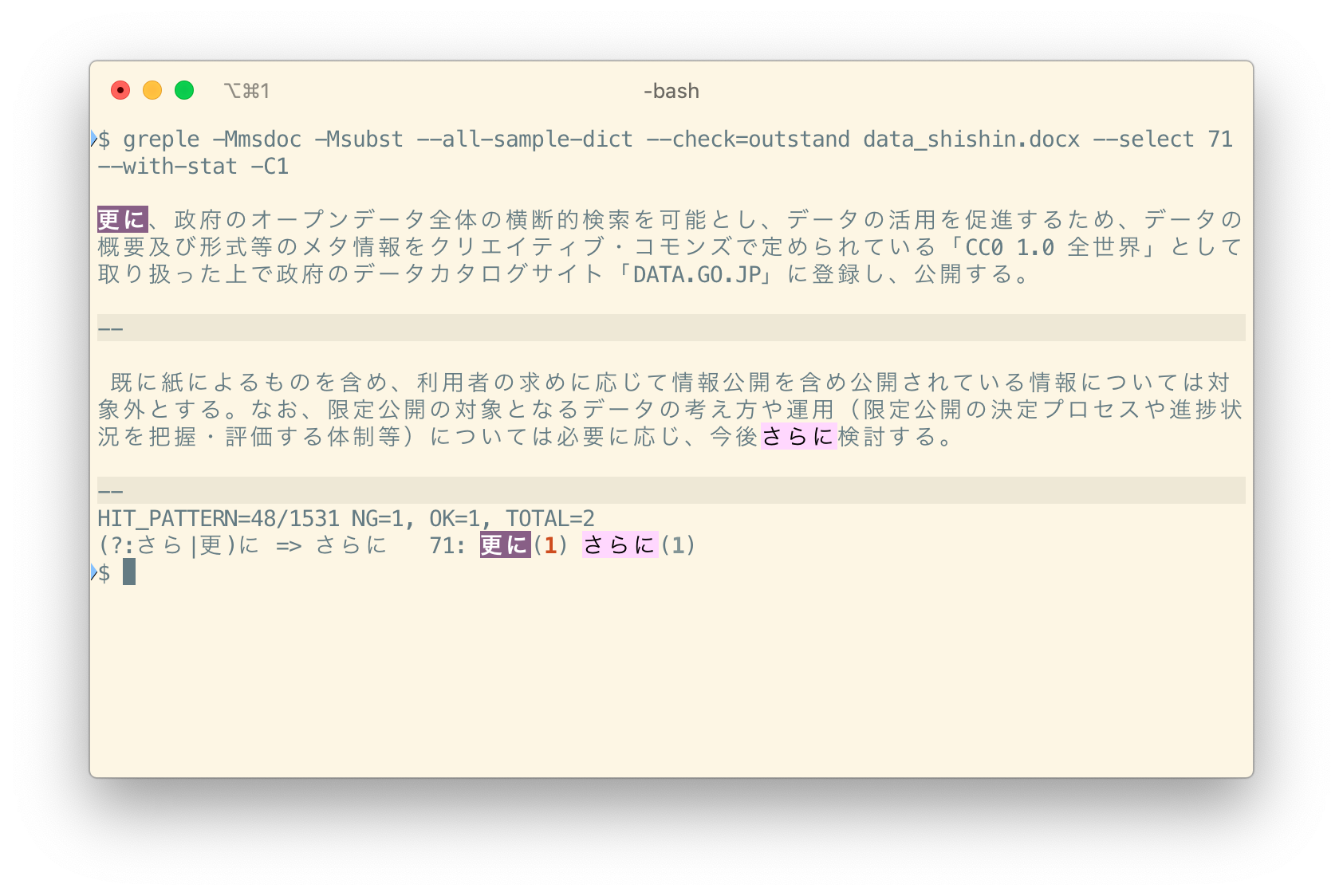
さすが政府の出している文書だけあって、表記揺れもほとんどない。2箇所だけある「及び」と「更に」について見てみよう。ルールは --select オプションで選択することができる。
更に vs さらに
接続詞かどうかで使い分けているんだろうか。よくわからないが、多分意図的なんだろう。
及び vs および
1箇所ある「および」は引用文ですね。ただ、括弧の対応がおかしいようです。

例外条件を設定する
実際の作業の中では、例外的に処理しなければならないケースが必ず出てくる。例えば、第三者が書いた文章の引用であったり、会社名等の固有名詞や書籍名などは自組織の都合で勝手に変えるわけにはいかない。
greple の -Mxp モジュールを使うと、検索対象から外すパターンをファイルで指定することができる。例えば、外部文書の名称は『』で囲むというルールを守っているのであれば /『.*?』/というパターンをファイルに記述しておいて --exclude-pattern オプションでそのファイルを指定すればいい。上のような例でどうしてもパターン化できないものは、その文書専用のファイルに「今後さらに」「論文および」のように書いてしまうこともできる。エラーはゼロにすることが重要だ。
greple -Mmsdoc -Msubst -Mxp --exclude-pattern data_shishin.exclude --all-sample-dict --check=any data_shishin.docx --stat
一度修正するだけなら、Word の検索・置換機能を使って一つ一つ処理するのでも構わないだろう。しかし自動変換で対応できる環境を作っておけば、将来的に方針が変わったとしても過去の文書も含めて一括で処理することができる。何よりも、そんな非生産的な作業に人間の能力を使うべきではないし、どんなに注意深くやっても必ずミスは発生する。
Word 文書を修正する
さて、この辞書にしたがって自動修正した結果との diff を取るとこのようになる。
greple -Mmsdoc -Msubst --all-sample-dict --check=any data_shishin.docx --diff -U0 | sdif --cm '*TEXT=' | less

テキストファイルであれば、このように一括で文書ファイルを修正することができる。
しかし、Word 文書の場合はできないので、それをなんとかしたいというのが今回の記事の主題だ。
diff2vba
Word 文書は XML で書いてあるので、力づくで修正することもできるのかもしれないが、それは間違った努力のように思う。Word のことは Word にやらせればいいと考えて、diff の結果に基づいて文章を修正する VBA のスクリプトを生成するプログラムを見様見真似で作ってみた。Word の場合、1パラグラフが1行なので、間違った場所を変換してしまう可能性は極めて低いだろう。もっとも、文書の種類によってはその可能性はあるので、運用上気を付ける必要はある。
VBA 何それおいしいのというレベルなので、不調法についてはどうかご容赦いただきたい。
ベタベタ書くのもみっともないので、置換文字列を2次元配列で管理して、長いと読みにくいから改行入れて綺麗に表示できるようにしたら、継続行が多すぎるとか、構文が複雑すぎるとか言われてがっかりなのだ。結局ベタベタ書いたスクリプトしか実行できない。
Sub Patch()
With Selection.Find
.MatchCase = True
.MatchByte = True
.IgnoreSpace = False
.IgnorePunct = False
End With
With Selection.Find
.Text = " 我が国においては、平成23年3月11日の東日本大震災以降、政府、地方公共団体や事業者等が保有するデータの公開・活用に対する意識が高まった。"
.Replacement.Text = " わが国においては、平成23年3月11日の東日本大震災以降、政府、地方公共団体や事業者等が保有するデータの公開・活用に対する意識が高まった。"
.Execute Replace:=wdReplaceOne
End With
Selection.Collapse Direction:=wdCollapseEnd
End Sub
インストール
その後 CPAN にリリースしたので、cpanminus でインストールすることができる。
cpanm App::diff2vba
実行
GitHubリポジトリ をクローンして、テスト用の t/ フォルダーに適当な .docx ファイルを置いて make すれば、同様のスクリプトを生成するようになっている。
課題山積
家に検証環境がなく、まったく得意な分野ではないので、もし便利だと思う人がいたら協力していただけると助かります。github の issues にも上げておきます。
行頭の空白と行末の「。」が残ってしまう。
これは .IgnoreSpace と .IgnorePunct を False にすることで解決した。
最初の1つしか変換できない
これは、変換した後でセレクションが残ってしまい、次回はそこが検索対象になってしまうためだったようだ。現時点では、変換後に明示的にセレクションを解除することで対応している。
Selection.Range.Text を使う方法もあるようだが、こうすると置換した文字列の先頭にカーソルが残るようだ。それでも実用上は問題ないはずだが、なんとなく気持ち悪い。
脚注があると処理できない
上のパッチでうまく変換できる箇所とできない箇所があるので調べてみると、脚注を含んでいるとマッチしないことがわかった。
一度、脚注をすべて消去してから適用すると変換できる。仮にそのまま変換できたとしても、その時は脚注も消えるから同じことかもしれない。
脚注の中身が処理できない
脚注の中にある文章も置換することができない。
修飾情報は消える
フォントに関する情報などは消えてしまうが、そんなデコラティブな文書を対象にするとは考えにくいので、これは大した問題ではないだろう。
VB で diff を読んだ方がいいのかもしれない
diff データから VB のスクリプトを生成するようにしたが、どうもイケてないので、VB で diff データファイルを読み込んで、それにしたがって変換してもいいような気がしている。この環境で生成されるデータは、必ず - で始まる行と + で始まる行が続いて出てくるので、処理は単純だ。現在のスクリプトは、もう少し汎用的に作ってある。
将来的には、単純な置換だけではなく、挿入や削除にも対応する可能性もあるので、その辺も含めて考える必要はあると思う。直接 diff データを読むのではなく、JSON 等の中間データにするのは簡単だ。