下書き
概要
- AMRグラフから意味情報を保ったまま文章を生成する方法を提案
- 従来は linearized AMR から Seq2Seq モデルで decode していたが,これでは 非局所的な意味情報をモデル化できるものの,AMRのグラフ構造からの情報を失ってしまう
- 大きなグラフでは長いセンテンスが生成されてしまう
- 従来は linearized AMR から Seq2Seq モデルで decode していたが,これでは 非局所的な意味情報をモデル化できるものの,AMRのグラフ構造からの情報を失ってしまう
- グラフレベルの意味情報を直接 encode する LSTM構造を提案
- 従来のモデルを上回るパフォーマンス
Abstract Meaning Representation とは
- 文章を,意味関係を捉えた有向非巡回グラフで表現する方法
- 各ノードは Concept, 各エッジは Concept間の関係性を示す
- AMRの形式で文章の意味をグラフ構造に落とし込み,それを正しくセンテンスに復元できれば,何が嬉しいのか??
Tutorial: The Logic of AMR: Practical, Unified, Graph-Based Sentence Semantics for NLP
構文情報を用いたAbstract Meaning Representationの高精度アラインメント
自然言語処理において、意味解析は固有表現抽出、意味役割付与、共参照解析、固有表現抽出など多くの分野にまたがっている。しかしながら、それぞれの解析に関する研究は独立して行われており、別々の分野として発展してきた経緯がある。そのため、分野ごとにデータを学習する手法も、評価に用いるデータも、結果を評価する手法も異なっている。したがって、分野間の関連性や相互作用を捉えた解析を行うことは難しくなっており、複数の分野で解析されてきた意味表現を一括して表現することができる形式が長い間望まれてきた。
それを受けて新しく考案された意味表現方法が抽象的意味表現 (Abstract Meaning Representation,AMR) [2] である。AMR は文中から意味を持った概念のみを取り出し、それをグラフ構造で表現したものである。このグラフは根を持ちサイクル構造を内部に含まない有向グラフとなっている。例として、“The boy wants for the girl to believe him.” に対する AMR を図 1 と図 2 にて示す。図 1 は AMR を視覚的にわかりやすいグラフ構造によって図示したもの、図 2 はデータ中での AMR を示したもので両者が表現していることは同じである。
AMR にはその中の各部分が文中のどの単語に対応しているかという対応関係がデータ中で示されておらず、明らかではない。こうした対応関係を特定するのがアラインメント処理である。文から AMR を生成するパーザーのほとんどはアラインメント結果を利用して機械学習を行っており、精度が高いアラインメント処理は AMR の応用上重要になっている。
AMR-to-text generation
- AMR では単語の時制や活用の情報が除かれるため,AMRの各ノードを単にフレーズに変換してもぎこちない文章に鳴ってしまう
- Seq2Seqモデルを用いたモデルがこれまでの SOTA だが,入力としてAMRを用いるには グラフを直列にする必要があった
- グラフ上では近いノード(親・子)であっても直列化されるとだいぶ離れてしまい, RNNが元のグラフ構造を推測するのは困難
- グラフ構造を直接 Encode する LSTM 構造を提案
graph-to-sequence model
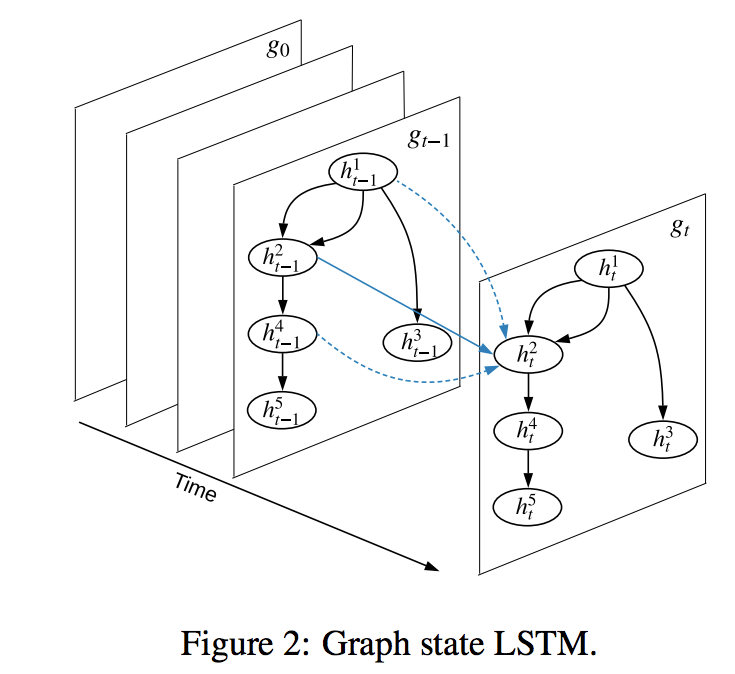
- $h^j_t$ : AMR グラフの各ノード j の時刻 t 隠れ状態 (時刻 0 の初期状態はハイパーパラメータで初期化)
- $x^l_{i,j}$ : AMR の ノードi からノード j へ伸びる ラベル l を持ったエッジ
これらを用いて,各ノードに対して 下記を定義し,これら4変数を入力した LSTM で各ノードの隠れ状態を $h^t_j$ を更新していく
- $x^i_j$ : 入力エッジベクトルの総和,
- $x^o_j$ : 出力エッジベクトルの総和
- $h^i_j$ : 入力ノード隠れ状態の総和
- $h^o_j$ : 出力ノード隠れ状態の総和
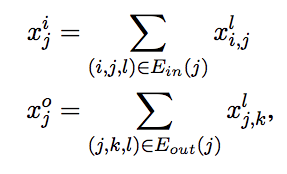
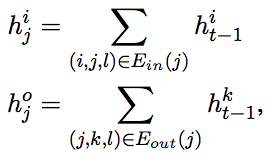
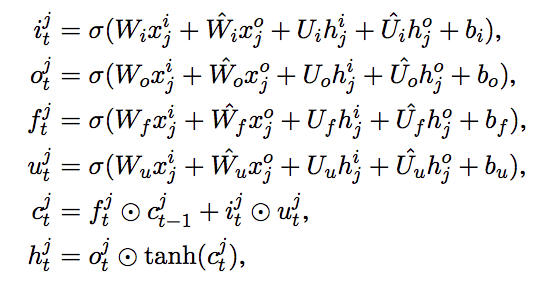
LSTMのステップ数
- 1ステップ計算する毎に,各ノードの隠れ状態には隣接するノードの情報が集約されていく
- N ステップ計算することで N 個先のノードの情報を得ることができる
- 直列なグラフであれば最悪でもノード数分計算すれば全体の情報を考慮することができる