概要
- Dual Learning に複数の Agent を追加した Multi-Agent Dual Learning を提案
- 翻訳モデルであれば 従来の Dual-Learning の枠組みでは一対の 順・逆翻訳モデルを用いている
- 本論文では 複数の順・逆翻訳モデルを用いた Dual-Learning を提案 ( モデルが増える分計算コストは増大)
- 対訳データ,monoligual データを用いることで SoTAパフォーマンスを達成
- WMT 2014 En->De において BLEUスコア 30.67 (Transfomer + 2.2pt)
Dual Learning Frame Work
Dual Learning で用いられるロス
$X \to Y \to X'$ と変換した際に $X, X'$の距離をロスとし(Y についても同様)式(1),これを最小化するようにモデル$f_0, g_0$を学習させる
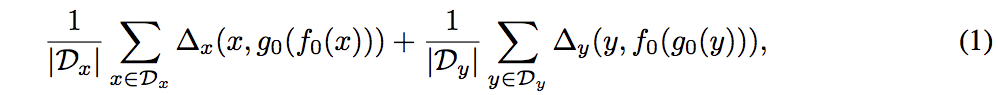
$D_x, D_y$:ドメインX, Yの学習データ
-
$f_0, g_0$:学習するドメイン変換 agent
- Multi-Agent な場合(本論文)では f,g をそれぞれ N個用意 $f_0 \sim f_{N-1}, g_0 \sim g_{N-1}$
- $f_0: X\to Y$
- $f_0$ を学習することを primal task と呼ぶ
- $g_0:Y\to X$
- $g_0$ を学習することを dual task と呼ぶ
$\Delta_x(x, x')$:x と x' の間のdissimilarity/distance を表現する関数
事前学習
- $f_i, g_i$ について(x, y)ペアデータがある場合は事前学習を行う
- ペアデータが存在しない場合は教師なし学習で訓練
- 各$f_i, g_i$ の違いは乱数シード
- 重みの初期化,学習データの順番等が変わる
Multi-Agent Dual Learning
$f_0 \sim f_{N-1}, g_0 \sim g_{N-1}$ をそれぞれ足し合わせてモデル $F_\alpha, G_\beta$ を作成
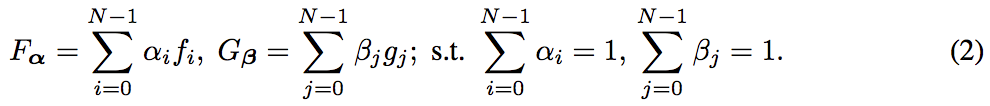
-
式(1)のロス関数は式(3)になる
- ※ Dual Learningでは$f_0, g_0$ のみ更に学習させる
残りの $f_1 \sim f_{N-1}, g_1 \sim g_{N-1}$ は事前学習したままで固定
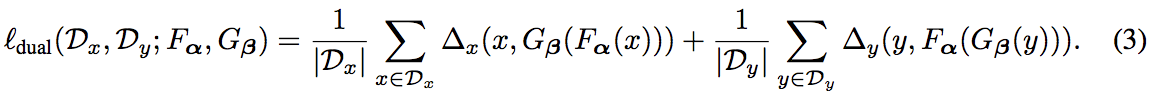
- ※ Dual Learningでは$f_0, g_0$ のみ更に学習させる
残りの $f_1 \sim f_{N-1}, g_1 \sim g_{N-1}$ は事前学習したままで固定
提案手法の他のモデルとの差異
-
Ensemble Learning : 複数の $f_i(x)$の出力を足し合わせて$y$を予測する方法
- $f_i$はそれぞれ独立に学習するが, 本論文の手法では式(3)で示すように一緒に学習する
- 本論文の手法では $f_0$ のみを最終的な推論に用いる
- duality は Ensemble Learning では考慮されていない
-
Knowledge distillation : 複数の$f_i(x)$の出力を足し合わせて予測したラベル $\hat{y}$ を用いてデータセット $(x, \hat{y})$を作成し,新たなモデルの学習に活用する方法
- $\hat{y}$の質を考慮していないが,本論文の手法では,duality を用いてフィードバックループを作成し,生成されたペアの質を評価している
翻訳タスクへの適用
- 翻訳タスクにおいて$\Delta_x, \Delta_y$ は負の対数尤度であるとみなせ,それぞれ式(4),(5)のようになる
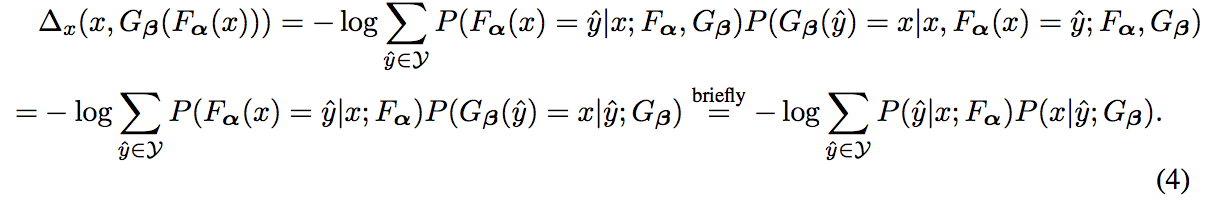
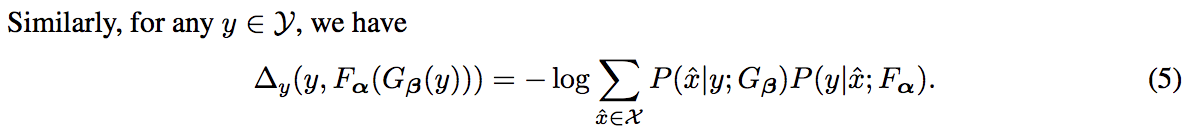
-
$\Delta_x, \Delta_y$ の上界 $\overline{\Delta_x}, \overline{\Delta_y}$ を定義し.これらを最小化することでモデルを学習
- Jensenの不等式を用いて式変形
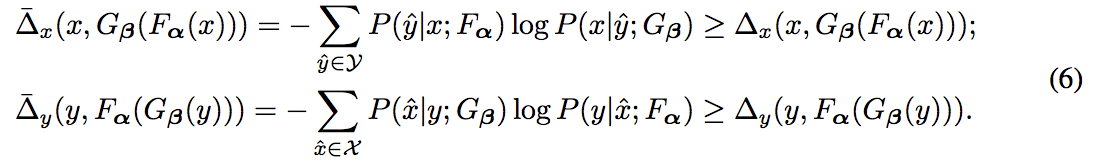
- Jensenの不等式を用いて式変形
式(3)のロスは式(6)を代入することで 式(7)となる
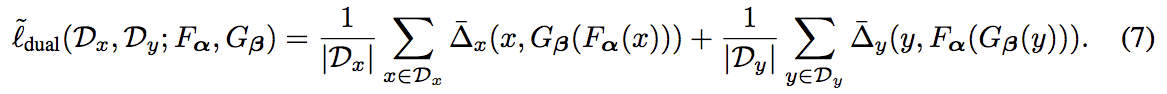
-
式(7) から $f_0, g_0$ のパラメータに関する微分は 式(8)の様に定義される
- 後段で行う勾配のモンテカルロ近似のために式(8) のように変形
- $F_\gamma$: $f_0$ を除いた $f_1 \sim f_{N-1}$ で構築されるモデル
- $\gamma = (0, \frac{1}{N-1}, ...,\frac{1}{N-1})$ : $f_0$についての係数だけ 0 になっている
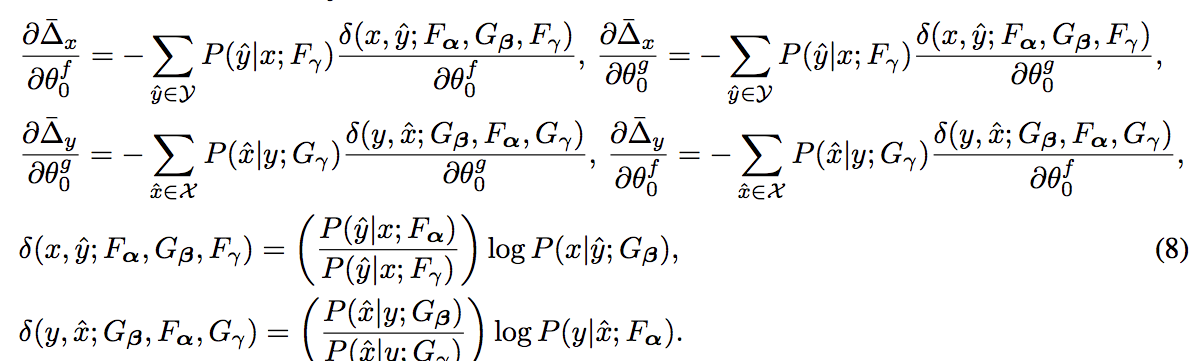
-
勾配計算のモンテカルロ近似
- 式(8)から,勾配を計算するわけだが全ての候補$\hat{x}$, $\hat{y}$に対して計算するのは非現実的
- $\hat{x}$, $\hat{y}$をサンプリングし,それらに対して勾配を計算し,式(8) を近似する
- 計算手順 例:$\frac{\partial \overline{\Delta_x}}{\partial \theta_0^f}$ を求める場合
- 入力$x$ に対して $\hat{y} \in Y$ を 分布 $P(\hat{y}|x;F_\gamma)$からサンプリング
- $\frac{\delta(x, \hat{y};F_\alpha, G_\beta, F_\gamma)}{\partial \theta_0^f}$ を計算しこれを$\frac{\partial \overline{\Delta_x}}{\partial \theta_0^f}$の近似値とする
-
オフラインで事前に $\hat{x}, \hat{y}$のサンプリングを行っておく
- $F_\gamma, G_\gamma$ は事前学習により求まっており,dual learning によって変わることはないので事前に$\hat{x}, \hat{y}$をサンプリングすることができる
- GPU 上のメモリーを節約できる
対訳データ$(x,y)$が存在するときは事前学習の時同様に$f_0, g_0$の翻訳ロス・勾配を計算し dual_learning の勾配に加える
Multi-Agent Dual Learning 学習アルゴリズム
- 上記の勾配計算は Algorithm1 の様にまとめられる

学習設定
データセット
- IWSLT 2014 English <-> German 翻訳
- WMT 2014 English <-> German 翻訳
- WMT 2016 unsupervised NMT English <-> German translation
- newstest 2012, 2013 を合わせたものを Validation newstest2014 を Testに
- 英.独それぞれの monolingual データセットとして 8M センテンスずつ newscrawl2013 から取得
- 教師なし En <-> De 翻訳は先行研究 Lample et al.(2018) と同じデータを使用
モデル構造
- Transformer を使用
- IWSLT : transformer_small
- WMT : transformer_big
- unsupervised NMT : transformer_base Lample et al.(2018) と同じ
最適化と評価指標
- Adam を使用 (学習率等の減衰方法は Transformer元論文と同様)
- ビームサーチのサイズは 4 ~ 6
- BLEU で評価
Baselines
- back translation, knowledge distillation, two-agent dual learning それぞれのベースラインモデルを実装・比較
- back translation
- 逆翻訳モデル $g:Y\to X$ を対訳データセットで学習し,データセット {$(g(y), y) | y \in D_y$} を作成
- 元のデータセットに作成したデータセットを足し合わせた新たなデータセットで 翻訳モデル f を学習
- knowledge distillation
- 教師モデルを $f_T:X\to Y$ を対訳データから学習し,データセット {$(x, f_T(x))|x \in D_x$} を作成
- 元のデータセットに作成したデータセットを足し合わせた新たなデータセットで 翻訳モデル f を学習
- two-agent dual learning
- 式(1) の方法で翻訳モデル$f, g$ を学習
- back translation
実験結果
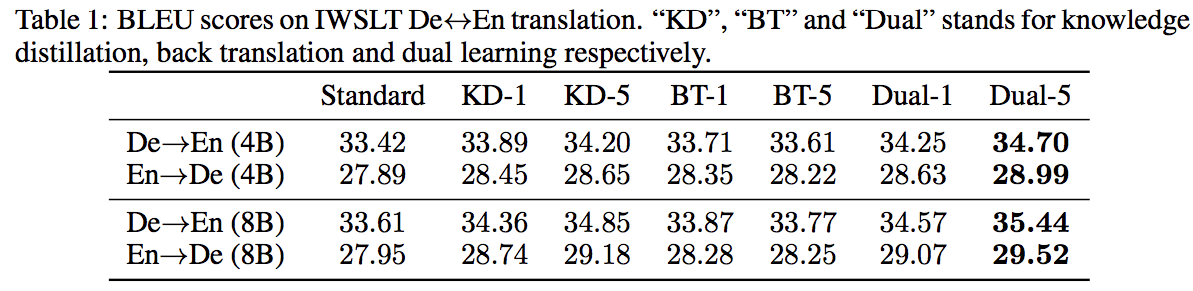
IWSLT データセットに対する翻訳結果
-
Dual-Learning モデルが最も高いパフォーマンスを示した.
- multi-agent かつ,各 agent(Transformer) のブロック数が大きい(8 block)ほど高いパフォーマンスが得られた
- multi-agent かつ,各 agent(Transformer) のブロック数が大きい(8 block)ほど高いパフォーマンスが得られた
-
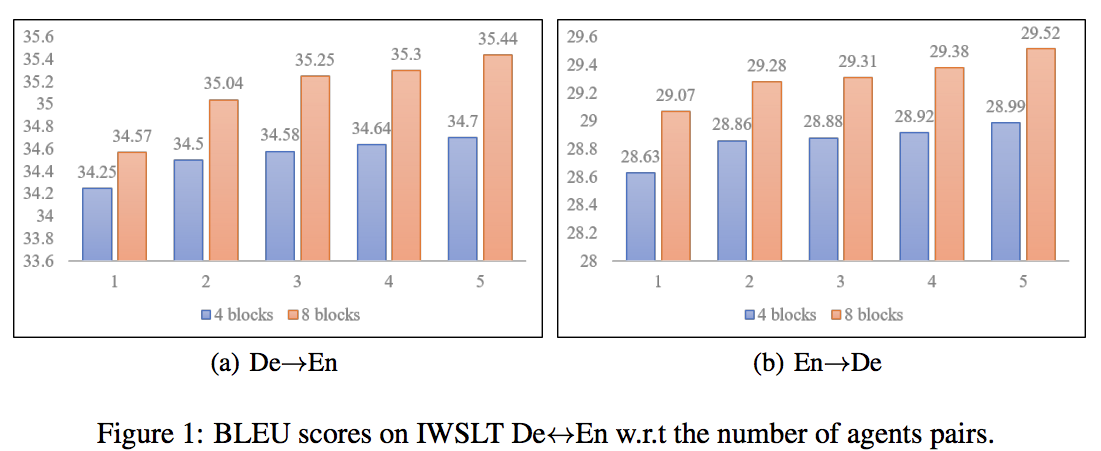
Agent の数を増やすほどパフォーマンスが向上した
- Agent を増やすほど計算コストは増加するが,一方でパフォーマンスの改善はサチる
- 以後,Agent数=3 で他のモデルと比較する
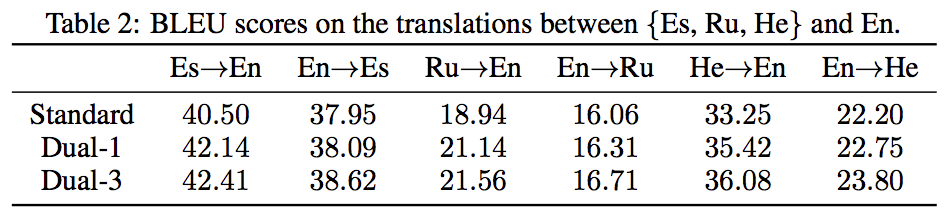
- English <-> German 以外のペアに対しても検証したところ一貫して, Dual-Learning モデルは高いパフォーマンスを示した
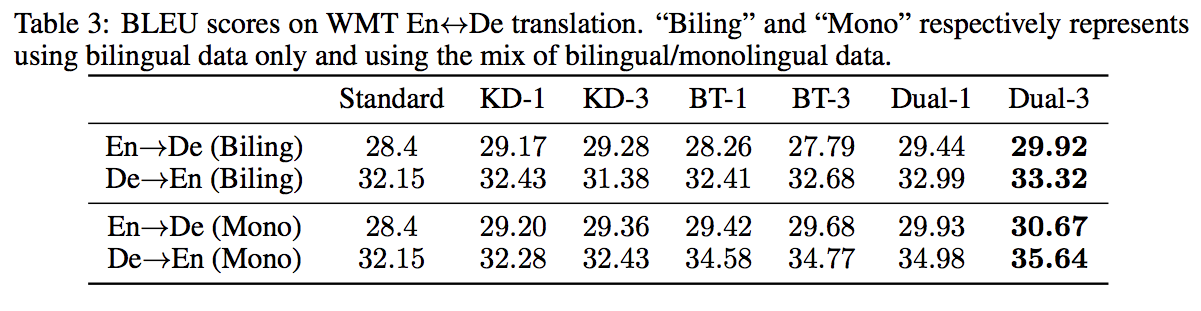
WMT データセットに対する翻訳結果
- Dual-Learning モデルが最も高いパフォーマンスを示した.
- 対訳データに対してのみ学習した場合と,対訳+monolingual データで学習した場合の両方を検証したところ monolingual データがある場合の方が高いパフォーマンスを示した.
Monolungual データに対する翻訳結果
- Lample et al.(2018) の方法で翻訳モデルを学習させた(Standard)後に更に knowledge-distillation, back-translation, dual-learning で学習させた際のパフォーマンスを比較
- dual-learning が最も高いパフォーマンスを示した.またこれは報告されている中では最も高い値である