書誌情報
- 著者:Sergey Edunov△ Myle Ott△ Michael Auli△ David Grangier▽∗
- 所属:△Facebook AI Research, Menlo Park, CA & New York, NY. ▽Google Brain, Mountain View, CA.
- EMNLP 2018
- arXiv 2018/10/3
概要
- Back-Translation で学習データを生成する際,ノイズを付与することでより多様性のある学習データを生成した.
- 生成したデータで翻訳モデル(Transformer) を学習させたところ WMT'14 English-to-German でSOTA(BLEU 35.0 pt)
関連研究(半教師付きNMT)
単一言語コーパスは言語モデルの学習に使われてきた
- 翻訳においては出力言語側の言語モデルを学習させ,翻訳結果をより流暢にする
- 言語モデルと翻訳モデルの隠れ状態を結合することで翻訳精度を上げた研究も (Gulcehre et al.2017)
- 翻訳モデルと target-side 言語モデルの間でのパラメータ共有とマルチタスク学習 (Domhan and Hieber, 2017).
Back-translation
-
target -> source 翻訳システムを学習させ,単一言語 target データから 疑似 source データを作成し,疑似対訳コーパスを作成
- 対訳データが乏しいときに有効
- 少ない対訳データで学習 -> 新たに学習対を作成 (Karakanta et al.,2017)
-
互いに関係のない monolingual text を用いて back-translation を dual-learning に拡張 (Xia et al. (2017)
- source-to-tgarget, target-to-source を同一モデルで訓練
- 両方向に BT をして学習
-
同様のアイデアで教師なし学習もおこわなれた (Lample et al., 2018a,b)
疑似 source の生成
- BT では 疑似 source の生成に,ビームサーチもしくは Greedy Search を実行
- 入力に対して最も生成確率が高い文章を生成
- MAP推定を介した文章生成は単調になる傾向がある
- 常に最も確率が高い単語を生成するため
- 対話や,ストーリー生成など,不確実性が高い文章を生成するタスクについて問題になる
- BTにおけるのようなデータ拡張スキームにおいても問題になる
- ビームサーチ,貪欲方では,モデル分布の峰部分にのみ焦点があたり,単調な入力文が生成される
- これは真のデータ分布をカバーしていない
ビームサーチ出力にノイズを加えてモデル分布からサンプリングを行った
- 制限なしにサンプリングを行い,多様で時々ありえないような文章を生成
- Most likely word に制限したサンプリング
- 各ステップにおいて,output 分布から確率上位 k 個の token 選択
- k 個で確率を正規化した後に,k 個のうちから1つをサンプル
- ビームサーチの出力にノイズを付与
- source 文を 3種類のノイズで変換
- 10%の確率で削除
- 10%の確率で filler token に置換
- 単語の位置の入れ替え(3単語以内のところに一様ランダムに置き換え)
- source 文を 3種類のノイズで変換
実験設定
-
WMT'18 English-Germam news translation タスクに対して実験
- 下記条件のデータは除いた全てのデータに対してモデルを学習 (5.18M 対)
- ParaCrawl コーパス
- 250単語以上のセンテンス
- sourte/target lenght 比率が 1.5 以上のもの
- 下記条件のデータは除いた全てのデータに対してモデルを学習 (5.18M 対)
-
Back Translation には WMT'18 で与えられている German monolingual newscrawl data を使用
- 226M センテンス(重複を除く)
-
Moses tokenizer を使用した後に,source-target 共通の BPE 作成 (35K types)
-
newstest2012 を Develop データセットとしてパラメータ調整をした後に,newstest 2013, 2017 で test したパフォーマンスを最終結果とした
-
より大きな WMT'14 English-French に対しても同様に実験
- 肝心の WME'14 English-German についての設定が記載されていない?
-
評価方法
- case-sensitive tokenized BLEU
- detokenized BLEU
-
比較に用いるモデルは Transformer (Big) を使用
- 6 blocks in the encoder and decoder
- word representations of size 1024
- feed-forward layers with inner dimension 4096.
- Dropout is set to 0.3 for En-De and 0.1 for En-Fr
- 16 attention head
- Models are optimized with Adam (Kingma and Ba, 2015) using β1 = 0.9, β2 = 0.98, and ǫ = 1e − 8 and we use the same learning rate schedule as Vaswani et al. (2017).
- use label smoothing with a uniform prior distribution over the vocabulary ǫ = 0.1
実験結果
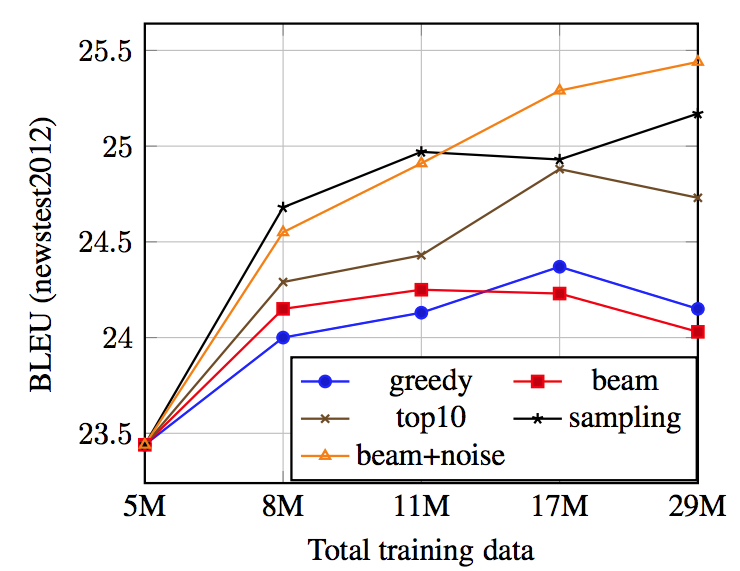
back-translation の方法を変えた際のモデルの精度変化
- beam + noise, sampling が最も高いスコアを示した (Fig1, Table1)
- back-translation で生成した 疑似source 文が多い程,最終的に高いスコアに収束
- 以降の実験では sampling を使用
back-translationの方法 5 種類
- greedy : 逆翻訳モデルから greedy に疑似source 文を生成
- beam : 逆翻訳モデルから beam search を用いて疑似source 文を生成
- top10 : 逆翻訳モデルから 生成確率上位 10位の中から 単語を生成して 疑似source 文を生成
- sampling : 逆翻訳モデルから 生成確率に基づいてランダムに単語を生成して 疑似source 文を生成
- beam + noise : 逆翻訳モデルから beam search を用いて生成した 疑似source 文にノイズを付与
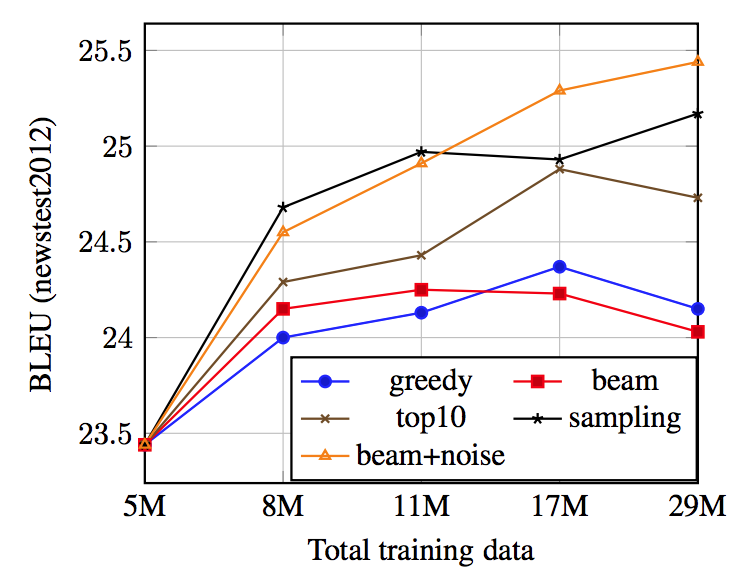
back-translation 手法の違いによるパフォーマンスの違いを解析
- 各手法,各epoch での 全token の Cross Entropy 誤差の平均を計算
- 24M 疑似source 文 で学習
- サブサンプリングした500K の疑似 source 文に対する誤差の平均を計算
- bitext に対しても同様に計算した
- sampling, beam + noise は誤差がなかなか小さくならず,モデルの学習に効果があり続ける事がわかる
- sampling 以外は 実際の bitext よりも誤差が小さくなっている
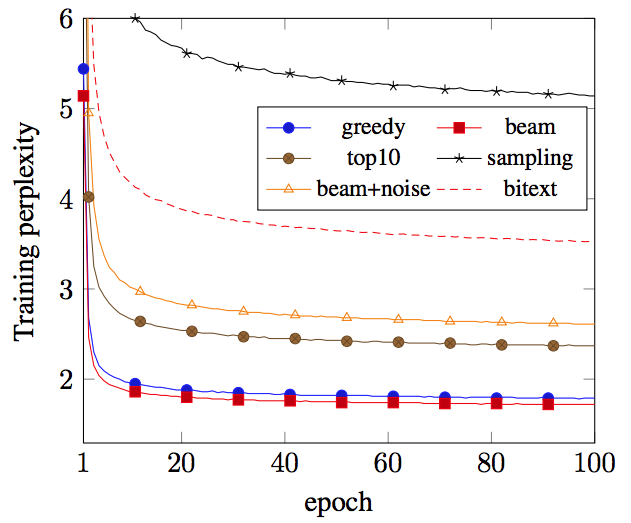
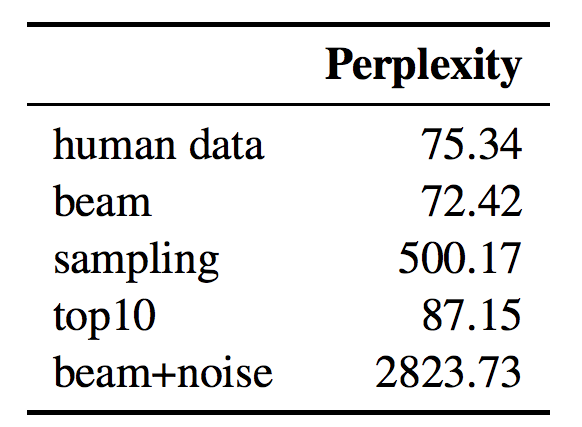
- 人間が作成した文章に対して学習した言語モデルを用いて,異なる back-translation 手法で生成したセンテンスの生成確率を評価
- beam search で生成したテキストが最も 生成確率が低く,言語として予測しやすいテキストになっている
- beam search で生成したテキストよりも, beam+noise, sampling で生成したテキストのほうがリッチな訓練データになっていると考えられる
- 多様性が低いと <-> 学習データとしてのモデルが学べる情報が少ない と考える
各 back translation 手法で生成される文章の例

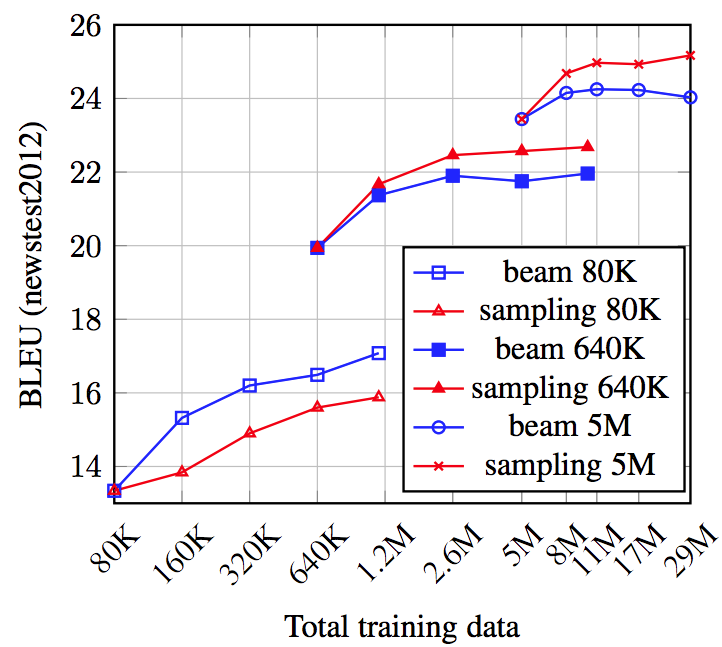
学習データの量が多い場合と少ない場合の比較
- 学習データの量が少ないと back-translation モデルの精度も低下し,結果として生成される疑似source 文を用いた学習の精度も低下すると考えられる.
- そのような場合では back-translation 手法の違いは学習結果にどのような影響をもたらすのだろうか
back-translation モデルの学習に用いることのできるデータが多くなるほど, beam よりも sampling 手法で作成した 疑似source 文を用いて学習したモデルのパフォーマンスが上がった
- サンプル数が少ない場合はモデルの精度自体が低く,beam でもノイズがあるセンテンスが生まれている一方で,そのような状態で更に sampling でノイズを付与してしまうと,まったく学習に用いることのできないデータになってしまったと考えられる
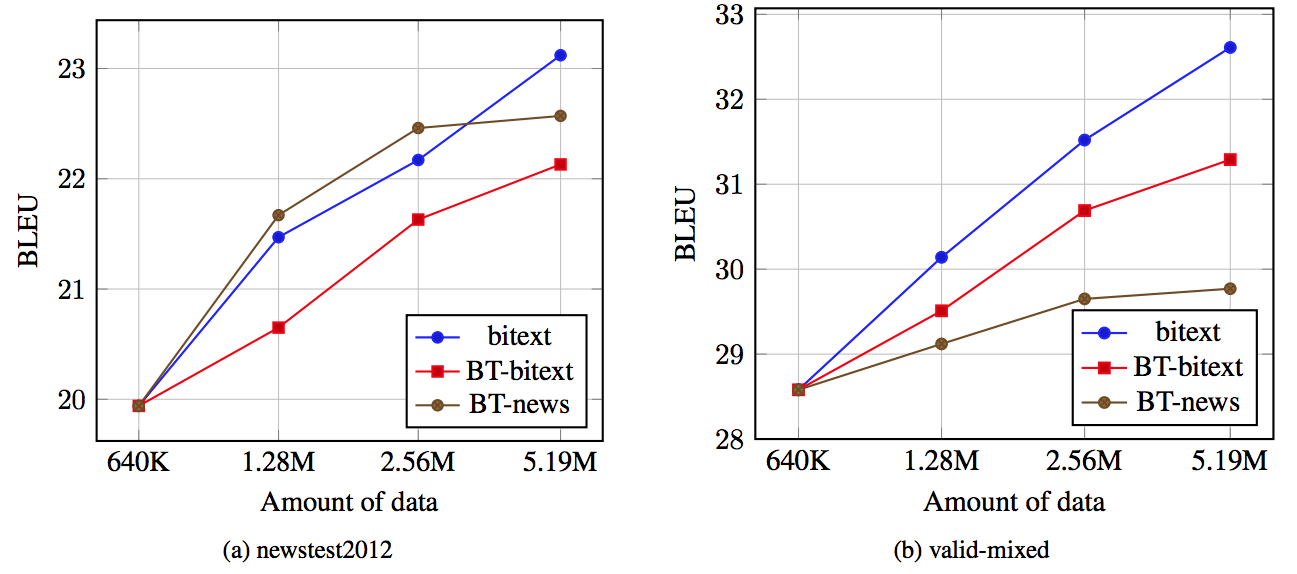
疑似データのドメイン適応への効果
-
対訳コーバスから 640K 対をサブサンプルして, back-translation モデルを学習
-
この 640k 対に加えて下記3パターンのいずれかで作成したデータで順翻訳モデルを学習 (back translate は sampling で実行)
- 残りの対訳コーパス (bitext)
- 残りの対訳コーパスに対して back translate して作成したデータ (BT-bitext)
- newscrawl データを back translate して作成したデータ(BT-news)
-
bitext は europarl と commoncrawl(ニュースについての文章はわずかしか存在しない)の2つから構成されている
- BT-news の場合とほかを比較することで domain adaptation について検討することができる
-
back-translate した文章がニュースのデータで,テスト対象が newsの文章であった場合(BT-news)は, 実際の位テキストデータと同じくらいモデルの精度を向上させることがわかった (a)
- 実際のデータを用いた改善幅の 83% を生成した疑似データによる改善で実現ができた.
-
back-translate した文章がテスト対象とは異なる場合には,翻訳モデルのパフォーマンス向上への寄与は少ない(BT-news) (b)
-> back translate したデータは各ドメインへのモデルの最適化に用いる事ができるので,特定ドメインのサンプル数が少ない場合にm土地いると効果があるのでは
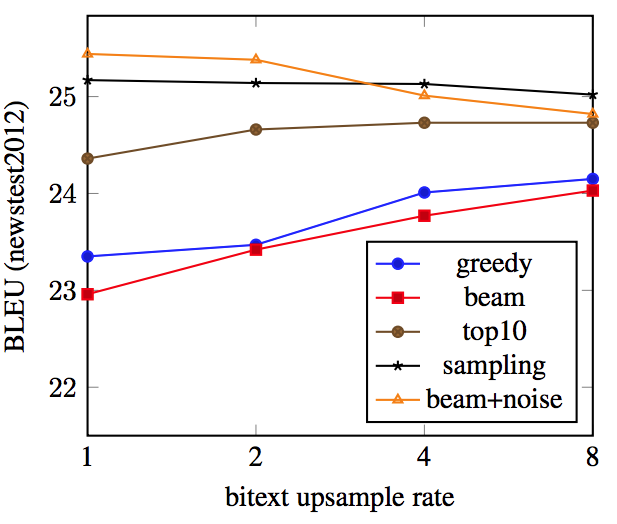
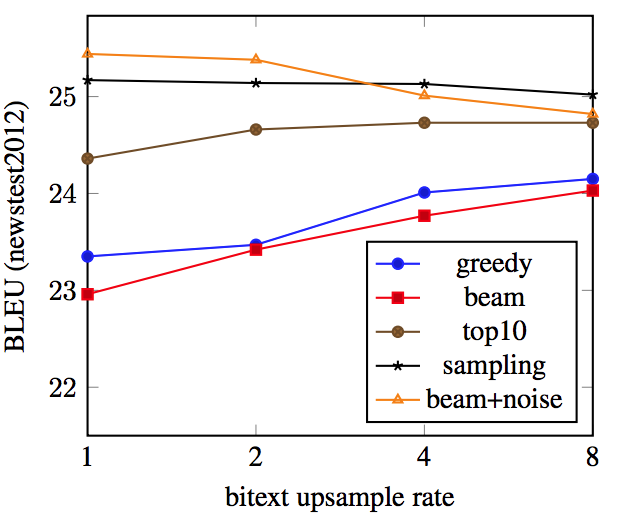
bitext のアップサンプリング
- bitext と 生成した疑似データを学習時に用いる比率をコントロールしてみたが,sampling, beam+noise の場合は パフォーマンスに変化は見られなかった.
- bitext 5M, 疑似データ 10M の時 updampling rate = 2 とすると,bitext 10M(同じものが2回出現), 疑似データ 10M で学習せることに相当
大規模データセットに対する検証結果
- WMT'14 English-German に対して back-translate(sampling) したデータも用いて学習させたところ SOTA達成
- WMT'14 のデータのみを使いこれまでで最も高い BLEU 35.0 pt を達成.
- 226M のドイツ語学習センテンスに対して back-translate で擬似データを作成,学習
- まず順翻訳モデルの学習を収束させてからか?
- upsampling rate = 16 とした
- 前の実験では効果がないといっていたがなぜか??
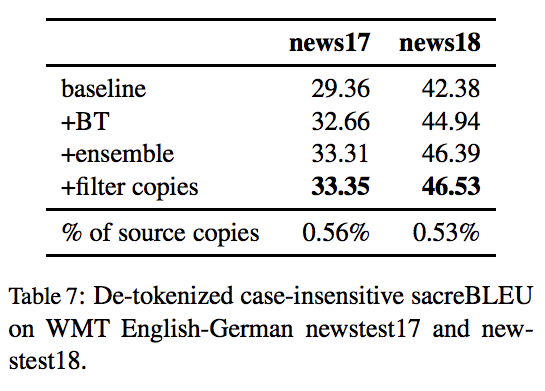
WMT'18 English-German news translation task へ挑戦し 1位 を獲得
- WMT'14 English-German に適用したモデルとほぼ同じ
- 6つの back-translate モデルをアンサンブル
- 使用可能な bitextに加えて newscrawl センテンス(226M) もしくは ドイツ語トークン?(5.8B) で学習
- updample ratio が 8(x1), 16(x1), 32(x4) と異なるモデル6つを用意
- 生成されたセンテンスと入力センテンスの間のユニグラムでのJaccard 類似度が 0.5 以上となったものは,入力文を翻訳せずコピーしただけのセンテンスとみなしてフィルタリング
- WMT'18 task の news-commentary データに対してのみ学習したモデルでの翻訳出力に置き換えた
- データセットのノイズが少ないため,このモデルはコピーを生成しにくかった.
- 出力の 0.5% は copy と判定された
- WMT'18 task の news-commentary データに対してのみ学習したモデルでの翻訳出力に置き換えた