まずBERTとは?
- Googleが発表した自然言語処理モデルで、2019年からは検索エンジンにも使用されています。
- 文脈理解の精度が評価されています。
- 様々な自然言語処理タスクにファインチューニングする前の、ベースモデルとしても使用できます。
Tokenizerとは?
- 日本語の解析をする場合には単語、文字など何らかの部分に分ける必要があって、分割された文字列のことをトークンといいます。
- Tokenizerは文書を単語分割をして、それにIDという数値に変換するモジュールです。
- 分割方法はN-gramやMeCabなど様々
例えば、「今日の予定は池袋にご飯を食べに行きます」という文章をTokenizerしてみるとこちらのようになるイメージです。

分かち書きされた文章の単語それぞれが数値に変換されていますね。これをトークンというそうです。
bert-tokenizerノードを使ってみる
Node-REDで使用できるnode-red-contrib-bert-tokenizerというノードを使用して、さまざまな文章からどのようなトークンが得られるのか見てみます。
こちらのようにノードを組んでみます。(enebularを使用してます。)
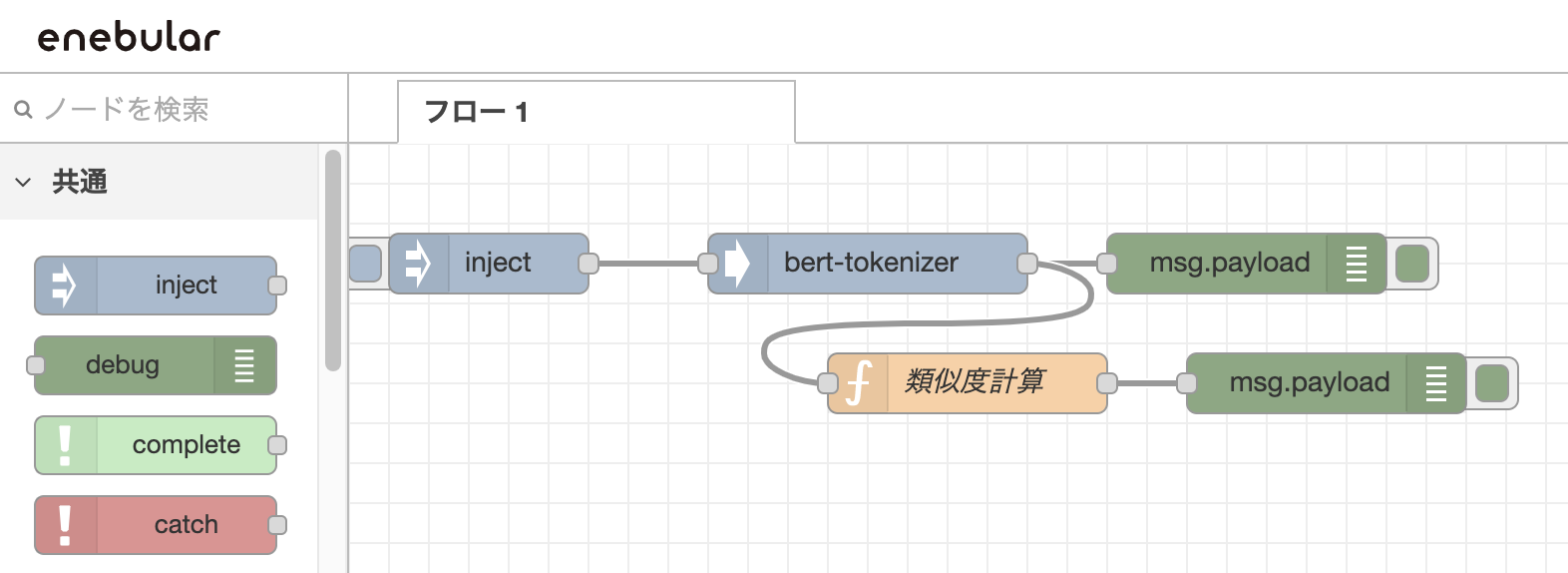
injectノードで何か文章を入力して、debugノードで中身を見てみるとこんな感じになります。
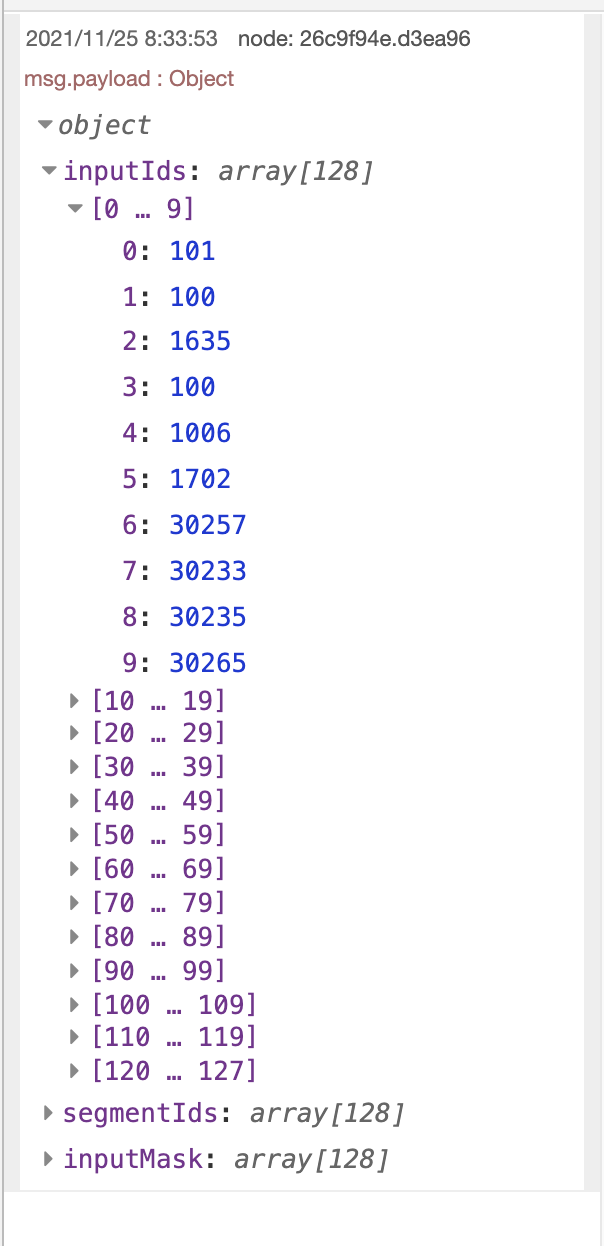
128個の配列の中にトークンとなる数字が格納される、という仕様のようです。
tokenizerされた結果を見てみます。
吾輩は猫である。名前はまだない。どこで生れたか頓(とん)と見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。
[101,100,1636,100,1636,100,1006,1666,30217,1007,100,1636,100,1636,100,1636,102,0,0,...]
トークンを見てみると、100や1636という数字がたくさん出てきているので違和感を覚えます。トークンの元は単語なので、同じ単語じゃないと同じトークンにならないはず。
bert-tokenizerが使っているデフォルトの辞書があるかどうか調べてみました。
こちらのようです。見た感じほぼ英単語ですね。
日本語の文章だと辞書が不十分のため同じようなトークンに収束してしまうようです。
英語の文章をtokenizerしてみました。
I am a cat. I don't have a name yet. I have no idea where I was born. All I remember is that I was crying in a dark and dank place. This was the first time I saw a human being.
[101,1045,2572,1037,4937,1012,1045,2123,1005,1056,2031,1037,2171,2664,1012,1045,2031,2053,2801,2073,1045,2001,2141,1012,2035,1045,3342,2003,...]
トークン値バラけましたね。
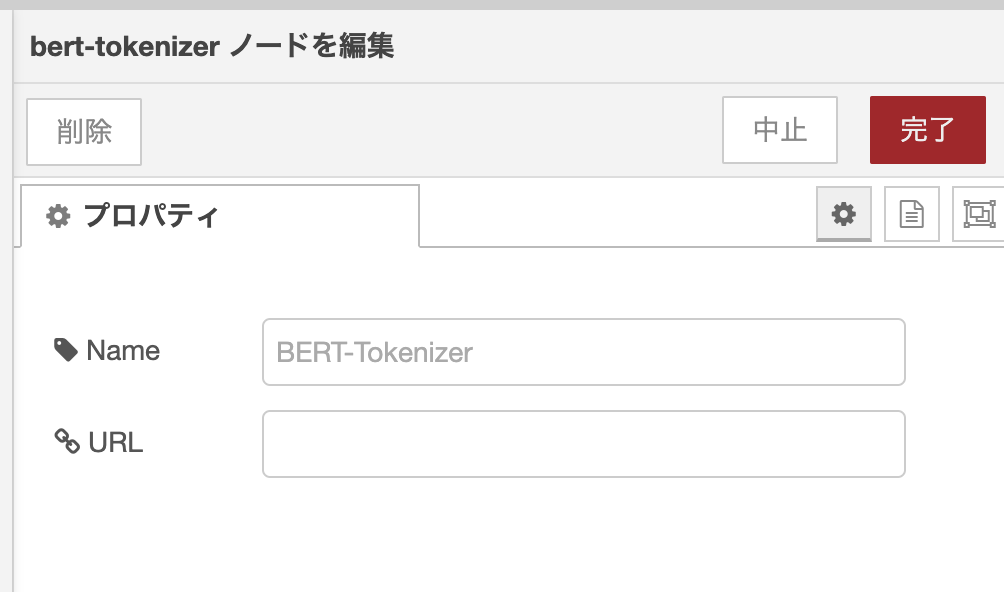
ちなみにbert-tokenizerノードにて辞書のURLを設定できるみたいでして、自分で作成した辞書を使ってbert-tokenizerノードを試すことができそうです。
使ってみた感想
取得できたトークン値を使って類似度計算など行ってみましたがうまくいきませんでした。(辞書データが同類の単語でマッピングされている訳ではないので当然ですね。)
分かち書きの値なのでBERT関係ないじゃん!と最初は直感的に感じたものの、挙動を見てみると辞書にない単語も何かしらのトークンになっているようなので、その辺りの類似単語判定的なところにBERTが使われているのだろうか?などと考察しました。
Tokenizerはそれ自体を自然言語処理に使うものというより、処理のベースやつなぎになるものかなというイメージです。どのように自然言語処理につなげられるのかもう少し調べてみたいなと思いました。