この記事はRich HickeyのClojureのコンセプトを示したリソースへのリンク集です。
このリンクを追っていけば、LISPであることやBetter Javaであることなんてものは表面的な特長に過ぎず、イミュータビリティ(とシンプルさ)こそが最大の特長であるということに気付かされます。
ClojureはOut of the Tar Pit (PDF) という論文に基づいて、状態とふるまいを分離するように言語設計されています。レースコンディションのような偶発的におこりうる問題は、状態とふるまいが一体となった混沌から生まれるのであって、これを分離してどうしても避けることの出来ない状態の管理だけ特別に扱うという考え方です。
オブジェクト指向が状態を安易に変更できてしまうのは、「状態」と「アイデンティティ」が密結合しているためです。ある2つのオブジェクトが同一かどうかは、問題領域に依存しています。しかしアイデンティティというものは状態が刻一刻と変化しても不変なものだ、と考えるのが自然だしシンプルですよね。つまり「状態とは、ある時点でのアイデンティティの値である」という考え方です。「過去の私」と「現在の私」はアイデンティティとしては同一であり、状態(年齢や住所)が異なるわけです。そうなると状態が"更新"されると、困ったことがおきます。「過去の私」が参照できなくなってしまいますからね。したがって、状態とアイデンティティを分離したモデルでは、アイデンティティが参照する値は不変であり、状態が変わるということはアイデンティティの参照だけが変わるということになります。つまり値はイミュータブルだということです。
この「状態」「アイデンティティ」「値」「ふるまい」を分離して、時間軸をとらえるモデルをEpochal Time Model と呼びClojureの基礎概念になっています。2009年のJVMSummitで発表されたものです。Are We There Yet? (PDF)
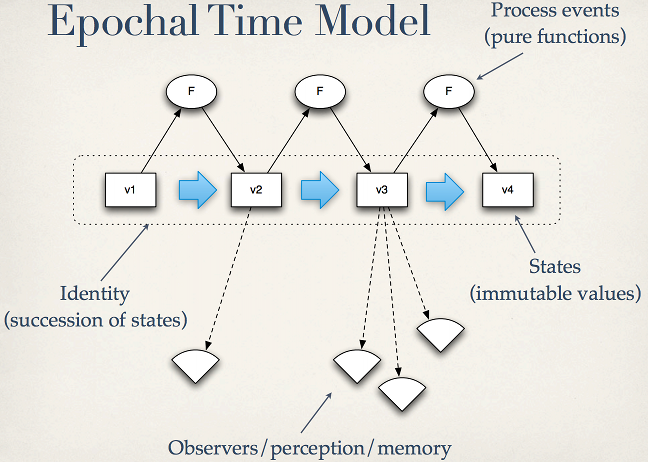
そして、この「状態」の考え方はClojureサイトの理念として掲げられています。
http://clojure.org/state [日本語訳] (http://www.geidai.ac.jp/~marui/clojure/state/)
http://clojure.org/rationale 日本語訳
さて「状態」と「アイデンティティ」と「ふるまい」を分離するのがシンプルだ、と言われればなんとなくそんな気がするのですが、それを追求した話がSimple Made Easy (PDF) に事細かに書いてあります。「シンプル」と「簡単」とは異なる概念でありClojureはとことん「シンプルさ」を追求した、というわけです。
ちなみにRich Hickeyは似た話をRailsConf2012でもしています。Simplicity Matters (PDF)
実用上イミュータブルな値が、並列実行なアプリケーションを書く上でシンプルなアーキテクチャを生み出すことは想像に難くないですが、気になるのは性能面です。
Javaにマルチスレッドな環境でsynchronized不要で読み書きできるコレクションにCopyOnWriteArrayList というものがあります。その名のとおり、書き込み時にリストそのものに変更を加えるのではなく、元のリストをコピーして変更を加えるというものです。コレクションがイミュータブルであるためには、そのような実装になるわけですね。当然ながら書き込みが多いと、リスト全体をコピーするのでメモリも喰うし、処理時間もかかります。
さてClojureは全ての値がイミュータブルなので、コレクションも当然ながらイミュータブルな訳ですが同じような問題はないのでしょうか?
ClojureではBit-partitioned hash triesというデータ構造を使って、イミュータブルでありながら省メモリで高性能を確保しています。
Rich Hickeyがこのデータ構造について話したスライドが以下になります。
Persistent Data Structures and Managed References (PDF)
これはIdeal Hash Trees という論文にもとづいて作られたデータ構造です。
リスト全体をコピーするのではなく、リストをツリー構造で表現しておいて、変更が必要なサブツリー以外はもとのツリーを参照するというものです。二分木に置き換えてわかりやすく解説したブログがあります。
http://hypirion.com/musings/understanding-persistent-vector-pt-1
http://hypirion.com/musings/understanding-persistent-vector-pt-2

二分木とは違い、Bit-Partitioned Hash Triesはツリーの深さが8あれば、350億の要素を格納できるので、実用上は検索も追加もO(1) で済むことになります。
ちなみに、このClojureのBit-Partitioned Hash Triesが強力なのでScalaにも移植しようぜ、という話があって物議を醸したようです。
https://issues.scala-lang.org/browse/SI-3724
結果的にこの提案は受け入れられなかったのですが、scala.collection.immutable.Vectorは似たような実装がされたようです。
文中リンクのRich Hickeyのスライドを見るにつけ、Clojureが非常によく練られたコンセプトをもとにイミュータビリティな設計がされていることが分かりますね。
なんてことのサワリについて社内イベントで話した内容がこちらになります。
https://www.slideshare.net/kawasima/tis-29266467
この中の後半にある、イミュータブル時代のフレームワーク darzana については別途書きたいと思います!