名前、ふりがなが連続しているフォームにおいて、ふりがなを自動入力する機能は、よく要求としてあがってきます。
jquery.autoKana.jsがよく使われているようですが、これはキーイベントを拾って、フリガナを作るので、
- Google日本語入力やATOKの予測変換
- スマフォのフリック入力
などで、ちゃんとキーイベントが発生しないものは、うまくフリガナを作ることができません。
(参考)
サーバサイドでフリガナを作る
ちょっと考えを変えて、サーバサイドで漢字からフリガナを生成するようにしてみます。
MeCabやKuromojiで形態素解析すると、漢字の"読み"も取得できます。
IPA辞書だと人名が弱いので、NEologdを使います。
https://github.com/neologd/mecab-ipadic-neologd
% echo '川島義隆' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd
川島 名詞,固有名詞,人名,姓,*,*,川島,カワシマ,カワシマ
義隆 名詞,固有名詞,人名,名,*,*,義隆,ヨシタカ,ヨシタカ
EOS
% echo '安倍晋三' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd
安倍 名詞,固有名詞,人名,姓,*,*,安倍,アベ,アベ
晋三 名詞,固有名詞,人名,名,*,*,晋三,シンゾウ,シンゾー
% echo '上島竜兵' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd
上島竜兵 名詞,固有名詞,一般,*,*,*,上島竜兵,ウエシマリュウヘイ,ウエシマリュウヘイ
EOS
ちゃんと読めてます。NEologdには有名人氏名が入っているので、そういうデータは姓名合わせて固有名詞になります。首相の名前が入っていないのは…何でなんでしょう、わかりません。
余談ですが…NEologd最高ですね!
⇒ echo '\(^o^)/😆' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd
\(^o^)/ 名詞,固有名詞,一般,*,*,*,\/,バンザイ,バンザイ
😆 記号,一般,*,*,*,*,キャハッ(笑),キャハッ,キャハッ
EOS
住所カナ
あまり住所のフリガナをWebサイトで入力するUIは見かけませんが、バックオフィス系ではそういう要求があることがあります。
住所のフリガナを作る場合、NEologdには、郵便番号-住所データのKEN_ALLが取り込まれているので、住所を入力するとフリガナがほぼ完璧に出ます。
% echo '東京都新宿区 西新宿8丁目17−1' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd
東京都 名詞,固有名詞,地域,一般,*,*,東京都,トウキョウト,トウキョウト
新宿区 名詞,固有名詞,地域,一般,*,*,新宿区,シンジュクク,シンジュクク
西新宿 名詞,固有名詞,地域,一般,*,*,西新宿,ニシシンジュク,ニシシンジュク
8 名詞,数,*,*,*,*,8,ハチ,ハチ
丁目 名詞,接尾,助数詞,*,*,*,丁目,チョウメ,チョーメ
1 名詞,数,*,*,*,*,1,イチ,イチ
7 名詞,数,*,*,*,*,7,ナナ,ナナ
− 記号,一般,*,*,*,*,−,ヒク,ヒク
1 名詞,数,*,*,*,*,1,イチ,イチ
EOS
が、京都は厳しいようです。
% echo '京都府京都市中京区御池通間之町東入高宮町206 御池ビル9F' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd
京都府 名詞,固有名詞,地域,一般,*,*,京都府,キョウトフ,キョウトフ
京都市 名詞,固有名詞,地域,一般,*,*,京都市,キョウトシ,キョウトシ
中京区 名詞,固有名詞,地域,一般,*,*,中京区,ナカギョウク,ナカギョウク
御池通 名詞,固有名詞,人名,一般,*,*,御池通,オイケドオリ,オイケドオリ
間之町 名詞,固有名詞,一般,*,*,*,間之町,アイノマチ,アイノマチ
東入 名詞,固有名詞,人名,姓,*,*,東入,ヒガシイリ,ヒガシイリ
高宮町 名詞,固有名詞,地域,一般,*,*,高宮町,タカミヤチョウ,タカミヤチョー
206 名詞,数,*,*,*,*,*
御池 名詞,固有名詞,人名,姓,*,*,御池,オイケ,オイケ
ビル 名詞,一般,*,*,*,*,ビル,ビル,ビル
9 名詞,数,*,*,*,*,*
F 名詞,固有名詞,組織,*,*,*,*
EOS
氏名
人名も、そこそこ出ますが、同じ漢字でもヨミの違うものがあります。N-Bestで複数の候補を表示させるようにするべきかと思います。
⇒ echo '東海林' | mecab -d /usr/lib/mecab/dic/mecab-ipadic-neologd -N 5
東海林 名詞,固有名詞,人名,姓,*,*,東海林,ショウジ,ショージ
EOS
東海 名詞,固有名詞,地域,一般,*,*,東海,トウカイ,トーカイ
林 名詞,接尾,一般,*,*,*,林,リン,リン
EOS
東海 名詞,固有名詞,人名,姓,*,*,東海,トウカイ,トーカイ
林 名詞,固有名詞,人名,名,*,*,林,リン,リン
EOS
東海 名詞,固有名詞,地域,一般,*,*,東海,トウカイ,トーカイ
林 名詞,一般,*,*,*,*,林,ハヤシ,ハヤシ
EOS
東海 名詞,一般,*,*,*,*,東海,トウカイ,トーカイ
林 名詞,接尾,一般,*,*,*,林,リン,リン
EOS
Javaでの実装
Kuromoji
StringBuilder sb = new StringBuilder(256);
try (JapaneseTokenizer tokenizer = new JapaneseTokenizer(null, false, JapaneseTokenizer.Mode.NORMAL)) {
tokenizer.setReader(new StringReader(kanjiText));
ReadingAttribute readingAttribute = tokenizer.addAttribute(ReadingAttribute.class);
CharTermAttribute charTermAttribute = tokenizer.addAttribute(CharTermAttribute.class);
tokenizer.reset();
while (tokenizer.incrementToken()) {
String kana = readingAttribute.getReading();
if (kana == null) {
kana = charTermAttribute.toString();
}
sb.append(kana);
}
}
住所のように確定的にいける場合は、こんな感じでいけます。
MeCab
N-bestで候補を複数作る場合は、MeCabを使います。
public static List<String> furiganizeCandidates(String name) {
Tagger tagger = new Tagger("-F%f[7] -d /usr/lib/mecab/dic/mecab-ipadic-neologd -E \\n");
return Arrays.stream(tagger.parseNBest(5, name).split("\n"))
.distinct()
.collect(Collectors.<String>toList());
}
UIイメージ
氏名漢字を入力したら、サーバに飛ばし、N-bestの候補を出力します。
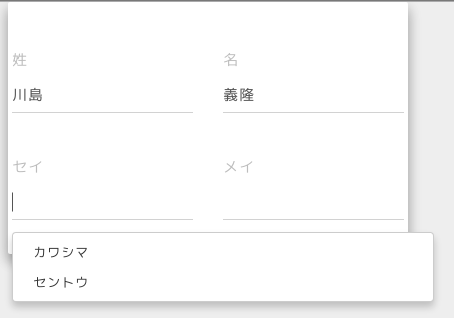
該当しないケースもあるので、キー入力はそのまま受けつけます。
フリガナをふる対象がわかっていれば…
例えば人名に限られるのであれば、形態素を使わなくとも、人名辞書を買ってきて、漢字からフリガナ変換させた方が、より正確にフリガナ・フリガナ候補出せるでしょう。
public class DictBaseFuriganizer {
static Multimap<String, String> furiganaMap = Multimaps.newMultimap(new ConcurrentHashMap<>(),
(Supplier<Collection<String>>) () -> new ArrayList<>());
private void initMap() throws IOException {
URL url = new URL("http://openlab.jp/skk/skk/dic/SKK-JISYO.jinmei");
try (InputStream in = url.openStream();
BufferedReader rdr = new BufferedReader(new InputStreamReader(in, "euc-jp"))
) {
String line;
while((line = rdr.readLine()) != null) {
if (line.startsWith(";")) continue;
String[] tokens = line.split("\\s*/\\s*");
String yomi = tokens[0];
for (int i=1; i<tokens.length; i++) {
String kanji = tokens[i].split(";")[0];
furiganaMap.put(kanji, yomi);
}
}
}
}
public Collection<String> furiganizer(String kanji) {
try {
initMap();
return furiganaMap.get(kanji);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
※キャッシュ実装は後ほどやります…
実行すると、ちゃんと変換テーブルからひけます。
new DictBaseFuriganizer().friganizer("東海林");
=> [しょうじ, とうかいりん]
ちなみに、人名で大変そうなキラキラネームは↓のようにして拾えます。(本当にそういう名前の人がいるのかどうか不明ですが…)
https://gist.github.com/kawasima/9205224
まとめ
コンシューマ向けサイトには、もっとボリュームのある辞書がないと実戦投入は難しそうですが、パンチ業務のようなところでは十分に入力補助として使えそうです。
;; TODO あとでExampleコード全量貼ります。