『Building Real-Time Analytics Systems』は、Apache Pinotのコミッタの方が書かれたリアルタイム分析システムについての概要、チュートリアル的な本です。簡単なサンプルコードも用意されているので、モダンなリアルタイム分析システムを体験してみることもできます。

リアルタイム分析の歴史
1990年代にCEP(Complex Event Processing)として誕生し、金融サービスにおける不正検知、センサーネットワークにおける異常の監視などでは使われたものの、標準化もされなかったので、広く普及はしませんでした。
2010年代にSamzaやStormが開発され、StormはTwitterのトレンドを表示するのに使われました。その後Storm開発者のMarzさんは、ラムダアーキテクチャを提唱しました。ラムダアーキテクチャはMarzさんの著書『Big Data』で詳しく語られています。

そして『Building Real-Time Analytics Systems』では、このラムダアーキテクチャを前世代のものと位置付け、モダンストリーミングスタックでは、
- クラウドネイティブ
- サーバレス
- 開発者エクスペリエンス
- SQL
を、その柱と位置付けているようです。
モダンストリーミングスタック
モダンストリーミングスタックは、以下のような構成であるとしています。
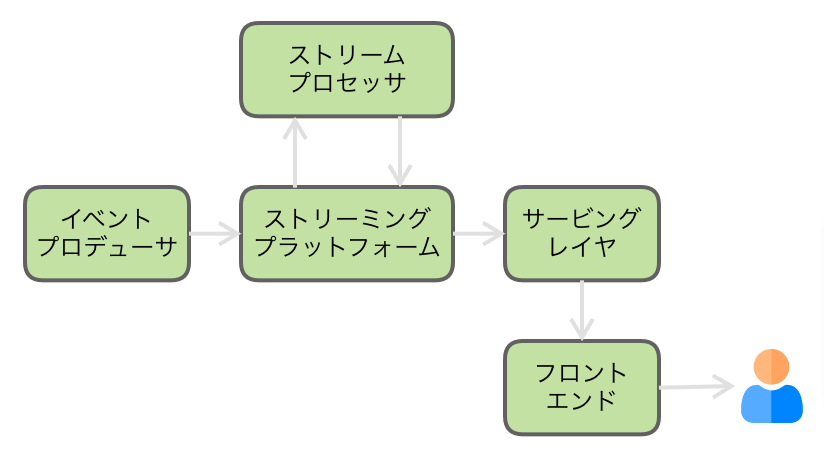
各構成要素の役割は以下のとおりです。
- イベントプロデューサ: ソースシステムの状態変化を検出し、下流のアプリケーションで使うイベントをストリーミングプラットフォームに投げ込む。これはソースシステムのアプリケーションで明示的にイベント発行することもあれば、CDCツールを使ってデータベースへの変更をキャプチャすることもある。
- ストリーミングプラットフォーム: 大量のイベントデータを溜め込み、それを複数のコンシューマにも並行して渡せる仕組み。すなわちKafkaが該当する。他の選択肢としては、Amazon KinesisやRedpanda、Apache Pulsar、Google Pub/Subなどがある。
- ストリームプロセッサ: ストリーミングプラットフォームからデータを読みこみ、集計したり、変換したり、フィルタしたりする。Flink、Spark Structured Streaming、Apache Beam、Kafka Streamsなどが該当する。これらの処理をSQLを使って書けるものもある。
- サービングレイヤ: ストリーミングプラットフォームで生成されたリアルタイム分析を利用するためのアクセスポイント。分析に使う(ストリームプロセッサで一次処理された)イベントを溜め込み、フロントエンドアプリケーションからのクエリに高速にレスポンスを返せる必要がある。KVSやNoSQLデータベースでも良いし、Apache Pinot、Apache Druid、Rockset、ClickHouseのようなもの達が該当する。
リアルタイム分析を何に使うか?
結局、分析系がリアルタイムであるのが必然な要求がないと、そこまで広まることがないわけですが『Building Real-Time Analytics Systems』では、以下のようなユースケースをあげています。
- パーソナライゼーション
- メトリクス
- 異常検知と根本原因分析
- ダッシュボード
- アドホック分析
- ログ分析
前世代でも問題なく出来ていたことが多く、モダンなスタックである必然性が薄いように思えます。
最後の13章には、以下の未来のユースケースが挙げられていて、こちらが本命のような気がします。
- エッジ分析
- コンピューティングとストレージの分離
- データレイクハウス
- リアルタイムデータ可視化
- ストリーミングデータベース
- サービスとしてのストリーミングデータプラットフォーム
- リバースETL
溜め込んでから分析するのではなく、分析に使ったら消えていくのでコスト削減のメリットがある、という点が、いくつかのユースケースでは共通してあります。これはStormが流行した時も言われていたと思うのですが、今やどんな企業でも使うかどうかわからないデータを、とにかく貯めるだけ溜めておいてある現状があるので、当時よりも響きやすいかもしれません。