リコメンド的なことをやりたいという要求はよくありますが、協調フィルタリングを持ちださなくてもよい(持ち出せない)ケースは現実的には多いと思います。ユーザを特定してその嗜好を取れなかったり、あまりリピートして使うものでないシステムだったり。
例えば、あるカレー屋さんはトッピングを多く選ばせることで利ざやを稼いでいます。そこでトッピングを多く選ばせるために、食券券売機におすすめの機能を付けたいと思いました1。
このケースでは当然ユーザの嗜好は分かりません。
高々50個くらいのトッピングメニューしかないので、「おぉこんなトッピングが存在したとは…」という発見があるわけでもなく、人気の組み合わせが分かれば、十分販促に繋がると思います。
こういうパーソナライズしないリコメンドには、伝統的なマイニング技術のアソシエーションルールが良さそうです。
このアソシエーションルールを作るのを、SQLだけでやるという、SIerにとっては非常にありがたい本が「データ集計・分析のためのSQL入門」です。

この本のアソシエーション分析に沿いながら、簡単なリコメンド機能を実装してみます。
注文履歴を集計する
売上伝票には同時に選ばれたカレーベースとトッピングの組がデータとしてあります。
2015-12-24T00:30:01,ポーク,トマトアスパラ,フィッシュフライ
2015-12-22T00:31:05,ポーク,フィッシュフライ,ソーセージ,メンチカツ
ER図で表すと以下のとおりです。
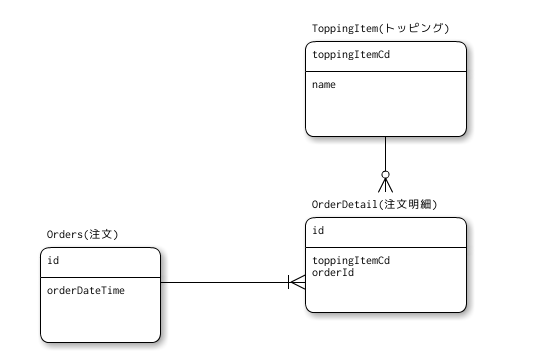
ここで、あるカレー屋において、カレーベースの違いによるトッピングの選ばれ方に差はないものとして、カレーベースは分析対象から落とします。また、トッピングメニューは季節ごとに期間限定の品があるので、日次集計しておいて、そこから直近3ヶ月の集計をするようにします。
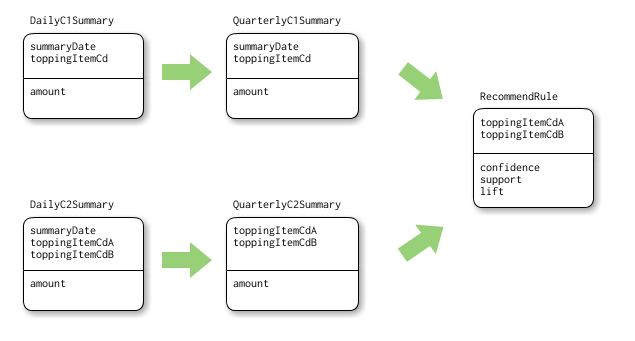
最終的にリコメンドのルールを導出します(これは次節で説明します)。
日次集計は、以下のようなSQLで集計可能です。
INSERT INTO DailyC1Summary
SELECT TRUNC(o.orderDateTime), od.toppingItemCd, COUNT(*)
FROM OrderDetail od
JOIN Orders o ON (o.id = od.orderId)
WHERE o.orderDateTime BETWEEN ? AND ?
GROUP BY TRUNC(o.orderDateTime), od.toppingItemCd
次に同時に注文されたトッピングの組を集計します。ここでは2つの組だけを集計し、ルールを作るようにします。
INSERT INTO DailyC2Summary(summaryDate, toppingItemCdA, toppingItemCdB, amount)
SELECT TRUNC(o.orderDateTime), od_a.toppingItemCd, od_b.toppingItemCd, COUNT(*)
FROM OrderDetail od_a
JOIN OrderDetail od_b
ON od_a.orderId = od_b.orderId
AND od_a.toppingItemCd <> od_b.toppingItemCd
JOIN Orders o ON (o.id = od_a.orderId)
GROUP BY TRUNC(o.orderDateTime), od_a.toppingItemCd, od_b.toppingItemCd
これで以下のような、日別のトッピング組合せのテーブルが出来上がります。
2015-12-22,ポーク,メンチカツ,254
2015-12-22,ポーク,フィッシュフライ,123
2015-12-22,ポーク,フィッシュフライ,123
毎日その日分の注文明細を集計し蓄積しておきます。
ここで作られた日別の集計を元に、直近3ヶ月の集計を行います。これはSUMとるだけなので簡単です。
INSERT INTO QuarterlyC1Summary(toppingItemCd, amount)
SELECT toppingItemCd, sum(amount)
FROM DailyC1Summary
WHERE summaryDate BETWEEN ? AND ?
GROUP BY toppingItemCd
INSERT INTO QuarterlyC2Summary(toppingItemCdA, toppingItemCdB, amount)
SELECT toppingItemCdA, toppingItemCdB, SUM(amount)
FROM DailyC2Summary
WHERE summaryDate BETWEEN ? AND ?
GROUP BY toppingItemCdA, toppingItemCdB
これは毎日全件集計し直します。
ルールの導出
ここでアソシエーション分析を使ったリコメンドでは、Confidenceを算出するわけですが、これはアイテム間に方向性がある(カメラを買った人にメモリカードを勧めるのはアリだけど、メモリカードを買った人にカメラを勧めるのはナシだよね…的な)ケースを想定しています。
2つの組合せのConfidenceは、Xを選んだもののうち、Yも選んだ割合で算出します。
Confidence(X \Rightarrow Y) = \frac{|X \cap Y|}{|X|}
しかし、あるカレー屋では、「イカカレーにエビにこみ、トッピングで」という注文と、「エビにこみカレーにイカ、トッピングで」という注文とは、等価なものです。トッピング間に順序性はありません。その刹那食べたいなーと思ったものを次々選べばよいのです。したがって、トッピングの共起性には方向性はありません。
ですが…、人気に極端に差があるトッピングの組合せを考えてみましょう。
(手仕込みヒレカツ, 100)
(オクラ山芋, 5)
(手仕込みヒレカツ, オクラ山芋, 3)
\frac{|手仕込みヒレカツ \cap オクラ山芋|}{|手仕込みヒレカツ|} = 0.03 \\
\frac{|オクラ山芋 \cap 手仕込みヒレカツ|}{|オクラ山芋|} = 0.6
方向性によって、大きくConfidenceに差が出てくるわけですが、「手仕込みヒレカツ」から見たときの「オクラ山芋」と、「オクラ山芋」から見たときの「手仕込みヒレカツ」はその重要度が大きく異なることが理解できるかと思います。
したがって、伝統的なConfidence、Support、Liftの指標を使ったルールを作ります。
Support(X \Rightarrow Y) = \frac{|X \cap Y|}{|A|} \\
Lift(X \Rightarrow Y) = \frac{Confidence(X \Rightarrow Y)}{Support(Y)}
Supportは、全トッピングの組うち、XとYが同時に選ばれた割合なので、「人気のトッピングの組合せランキング」に使えます。
Liftは、Xに対してYを勧めると、何もしないときに比べて、トッピングYが選ばれる率がどれだけ向上するかを示します。まさにリコメンドのための指標といえます。
ほとんどの人が選ぶトッピングがあるのであればLift値をベースにリコメンドのロジックを考えた方がよいし、特にそういうものがなければ、Confidence値の上位の者をリコメンドとして使うのもありかと思います(その場合は単に人気ランキング的になりますが…)。
今回カレーベースは外して考えているので、Confidenceでもまずはよいかもしれません。が、Lift値を算出するのも難しくはないので、全部計算はしておきます。
INSERT INTO RecommendRule(toppingItemCdA, toppingItemCdB, confidence, support, lift)
SELECT c2.toppingItemCdA, c2.toppingItemCdB,
c2.amount / c1a.amount AS confidence,
c2.amount / :c2_all AS support,
(c2.amount / c1a.amount) / (c1b.amount / :c1_all) AS lift
FROM QuarterlyC2Summary c2
JOIN QuarterlyC1Summary c1a ON c2.toppingItemCdA = c1a.toppingItemCd
JOIN QuarterlyC1Summary c1b ON c2.toppingItemCdB = c1b.toppingItemCd
リコメンド機能の実装
ここまで、データ処理できていれば、トッピング1つめを選んだ時に、以下のようにLift値でソートして上位を取得し、そのトッピングのボタンを光らせてやれば良いわけです。
SELECT t.toppingItemCd, t.name, lift
FROM RecommendRule rr
JOIN toppingItem t ON rr.toppingItemCdB = t.toppingItemCd
WHERE toppingItemCdA = ?
ORDER BY lift DESC
ということで「オクラ山芋」を選んだときのオススメは以下のようになりました!2
TOPPINGI NAME LIFT
-------- ---------------- ----------
MEAT0003 牛カルビ焼肉 6.88307692
OTHR0006 単品ポテト 3.62756757
MEAT0015 チキンにこみ 3.44153846
FISH0001 カキフライ(4個 3.44153846
)
MEAT0008 メンチカツ 3.37660377

まとめ
リコメンド対象アイテムが少なく、個人の嗜好をそこまで考慮することがないケースにおいては、SQLだけでリコメンド機能を比較的簡単に実装できました。私自信十数年前のインターンで、アソシエーション分析の実装したことあるくらいの知識しかないので、ツッコミやおすすめのトッピングの組合せなどございましたらコメントいただけると幸いです。