前書き
未精査なデータを利用して、何ができるかを調査する場合、「Jupyter Notebook」で処理を書いて、printなどで確認しならが作業していく。
そんなこんなを続けていくと「Jupyter Notebook」に書いた処理が大きくなっていき、収集がつかなくなる。
みたいなことがよくあるとの意見をよく見かけます。これは、「Jupyter Notebook」とPythonのprintが優秀なことの裏返しでもあります。
何ができるかを調査する時点で、作成するかもしれない処理の期待すべき動作を定義し、包括的なテストを実装することは、どう考えても現実的ではありませんが、部分的なテストといった面からであれば現実的です。まあこれは、Pythonに限った事ではないのですが、他の言語と比べるとPythonのユニットテストの話題が少ない気がしますので、「Jupyter Notebook」でPythonの書き方の説明をしながら、printではなくassertしていく投稿を作成しようと思います。本来であればpyファイルを分割してテストを実行する体にすべきなのですが、簡単に確認いただけることを優先してこの形としております。
PythonやRubyは、Javaと同じようにタイプセーフな言語です。
pythonがタイプセーフかどうかの議論はよく行われており。
「Stack Overflow」にもいろいろやり取りがあります。
Is Python type safe?
上記の議論の中で、以下の記載がありました。
The wikipedia article associates type-safe to memory-safe, meaning, that the same memory area cannot be accessed as e.g. > > integer and string. In this way Python is type-safe. You cannot change the type of a object implicitly.
ホント、勉強になりますね、「Stack Overflow」って、知りませんでした。私が無知すぎるだけなのですが・・・
Rubyもタイプセーフな言語です。これは個人的な感想なのですが、「Ruby On Rails」はユニットテストをちゃんと実装しないと脱線事故を起こす確率が高いと感じています。Rubyと同様でタイプセーフな言語であるJavaとは大違いです。Javaはユニットテスト書かなくても脱線事故は少ないです。Javaは、JDK5で導入されたジェネリックからかなり改善されたと思います。
これは、Rubyが動的型付け言語で、Javaが静的型付け言語である事に起因する部分が大きいと言えます。
rubyのgemであるadamantiumnなどの取り組みもあるのですが、それほどメジャーな潮流となっていないと感じます。
確かに「静的型付け言語」はカタカタとタイプ数が増えるので、軽快に実装しにくくなるとの事実はありますが、
2021年現在、Javaを例にすると、型推論やIDEの入力保管機能が充実していますので、十分軽快に実装できると感じております(個人差あるとは思いますが・・・)
String strValue1 = "hoge";
List<String> strList1 = new ArrayList<>()
List<String> strList2 = new ArrayList<String>()
//Java10から宣言時にデータ型の記述でvar(型推論)で定義可能
var strValue2 = "hoge";
//イミュータブルなLitならばList.ofで定義可能
//List.ofはJava 9から利用可能
var strList3 = List.of("hoge", "fuga");
脱線事故を減らすための取り組みとして、Pythonでも「Type Hints」が導入さています。
こちらが参考になると思います。実践!!Python型入門(Type Hints)
Pythonが「動的型付け言語」であることに魅力を感じている方には、イマイチ納得感がないものであると同時に、Rubyのなんだかザラザラした居心地の悪さを感じていて、その後Pythonを利用されている方には素晴らしいソリューションであるとも感じます。
「Type Hints」に関しては、「その他」の「Type Hints」で少し説明させていただきます。
前置きが長くなったのですが、「Python入門(pirnt少なめ、assert多め)」となります。
「Jupyter Notebook」で記述・実行していく形式となります。
ipynbファイルはgithubに登録しております。
基本的なデータ型
import pytest
pytestを利用するので、importします。
文字列型
str_value_1 = "hoge"
str_value_2 = "fuga"
# サイズと中身のチェック
assert len(str_value_1) == 4
assert str_value_1 == "hoge"
assert str_value_2 == "fuga"
# type 自身のtypeをチェック
assert type(str_value_1) is str
assert not type(str_value_1) is object
# isinstance 継承元も含めてチェック
assert isinstance(str_value_1, str)
assert isinstance(str_value_1, object)
# str_value_1の参照をstr_value_3として定義
str_value_3 = str_value_1
# str_value_1とstr_value_3は同じオブジェクトを参照しているのでisでtrue
assert str_value_1 is str_value_3
# str_value_1とstr_value_3は同じオブジェクトを参照しているのでidも一致
assert id(str_value_1) == id(str_value_3)
# strはイミュータブルな事を確認するためにidを取得
str_value_1_old_id = id(str_value_1)
# 値を変更するとidが変わることを確認
str_value_1 = str_value_1 + "hoge"
assert str_value_1 == "hogehoge"
str_value_1_new_id = id(str_value_1)
assert not str_value_1_new_id == str_value_1_old_id
宣言方法
動的型付け言語ですので、宣言の仕方はrubyとまったく同じとなります。
str_value1 = "hoge"
サイズと値の確認
# サイズと中身のチェック
assert len(str_value1) == 4
assert str_value1 == "hoge"
assert str_value2 == "fuga"
いきなりくどめなassertですが
str_value1の長さが4であること
str_value1が"hoge"であること
str_value2が"fuga"であること
を検証しています。
型チェック
# type 自身のtypeをチェック
assert type(str_value1) is str
assert not type(str_value1) is object
カタカタ言ってますので
type(str_value1) is strでstr_value1自身の型がstrであることを検証しています。
str_value1自身はobjectでないことをnot type(str_value1) is objectで検証しています。
# isinstance 継承元も含めてチェック
assert isinstance(str_value1, str)
assert isinstance(str_value1, object)
assert isinstance(str_value1, str)でstr_value1が継承元も含めて型がstrであることを検証しています。
assert isinstance(str_value1, object)でstr_value1が継承元も含めて型がobjectであることを検証しています。
pythonのデータ型は全てobjectの継承クラスとなりますので、str_value1もobjectの継承クラスとなります。
isとid
# str_value1の参照をstr_value2として定義
str_value3 = str_value1
# str_value1とstr_value2は同じオブジェクトを参照しているのでisでtrue
assert str_value1 is str_value3
# str_value1とstr_value2は同じオブジェクトを参照しているのでidも一致
assert id(str_value1) == id(str_value3)
str_value3はstr_value1と同じオブジェクトを参照しているので、assert str_value1 is str_value3となります。
同様にオブジェクトのidも同じになりますので、assert id(str_value1) == id(str_value3)となります。
strはイミュータブル
# strはイミュータブルな事を確認するためにidを取得
str_value1_old_id = id(str_value1)
# 値を変更するとidが変わることを確認
str_value1 = str_value1 + "hoge"
assert str_value1 == "hogehoge"
str_value1_new_id = id(str_value1)
assert not str_value1_new_id == str_value1_old_id
str_value1_old_id = id(str_value1)でstr_value1の値変更後にidが変わることを確認するために、変更前にidを取得します。
assert not str_value1_new_id == str_value1_old_idで値変更後にidが変わることを確認しています。
intとfloat
定義方法
intとfloatの定義、利用方法は以下のとおりです。
int_value = 100
# float 指数表記
float_value_1 = 0.01
assert type(float_value_1) is float
# float 指数表記 1 * 10の-2乗 == 0.01
float_value_2 = 1E-2
assert float_value_1 == float_value_2
# 16進数
hex_value = 0xff
assert type(hex_value) is int
# 2進数
bit_value = 0b11111111
assert type(bit_value) is int
# どちらも10進の255
assert hex_value == bit_value == 255
strをintとfloatに変換
文字列を数値に変換してみます。
# int(数値の文字列)でintに変換
int_value_from_str1 = int("100")
assert int_value_from_str1 == 100
# 固定長の数値文字列のような0詰めでも変換可能
int_value_from_str2 = int("0100")
assert int_value_from_str2 == 100
# intに数値以外を渡すとValueErrorが発生
with pytest.raises(ValueError):
int_value = int("hoge")
float_value_from_str1 = float("100")
assert float_value_from_str1 == 100.0
float_value_from_str2 = float("123.45")
assert float_value_from_str2 == 123.45
# floatに数値以外を渡すとValueErrorが発生
with pytest.raises(ValueError):
float_value = float("hoge")
with pytest.raises(ValueError):
int_value = int("hoge")
int_value = int("hoge")を呼び出すとValueErrorが発生することを確認しています。
intとfloatをstrに変換
数値を文字列に変換してみます。
assert str(200) == "200"
assert str(1.234) == "1.234"
# intを16進文字
assert "{:x}".format(255) == "ff"
# xとして解釈できない値を指定するとValueError
with pytest.raises(ValueError):
"{:x}".format("hoge")
# 先頭ゼロ詰めの固定長(4桁)の16進の文字列
assert "{:04x}".format(255) == "00ff"
# intを2進文字列
assert "{:b}".format(255) == "11111111"
# 先頭ゼロ詰めの固定長(10桁)の2進文字列
assert "{:010b}".format(255) == "0011111111"
bytes
str_value = "foo"
bytes_value = bytes([102,111,111])
# サイズと中身のチェック
assert len(bytes_value) == 3
assert bytes_value[0] == 102
assert bytes_value[1] == 111
assert bytes_value[2] == 111
# strに変換してチェック
assert bytes_value.decode('utf-8') == "foo"
assert bytes_value.decode('utf-8') == str_value
# type 自身のtypeをチェック
assert type(bytes_value) is bytes
datetime
宣言
import datetime
dt_now = datetime.datetime.now()
assert type(dt_now) is datetime.datetime
base_year, base_month, base_day, base_hour, base_minute, base_second = 2021, 5, 23, 1, 10, 20
dt_value_1 = datetime.datetime(base_year , base_month , base_day)
assert dt_value_1.year == base_year
assert dt_value_1.month == base_month
assert dt_value_1.day == base_day
assert dt_value_1.hour == 0
assert dt_value_1.minute == 0
assert dt_value_1.second == 0
dt_value_2 = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second)
assert dt_value_2.year == base_year
assert dt_value_2.month == base_month
assert dt_value_2.day == base_day
assert dt_value_2.hour == base_hour
assert dt_value_2.minute == base_minute
assert dt_value_2.second == base_second
# tzinfoはdatetime.timezone.utcを指定して生成
dt_utc = datetime.datetime(base_year , base_month , base_day, tzinfo=datetime.timezone.utc)
# dt_utc.tzinfoはdatetime.timezone.utcとなるべき
assert dt_utc.tzinfo == datetime.timezone.utc
# dt_value1はtzinfo未指定なのでNoneとなるべき
assert dt_value_1.tzinfo == None
datetimeの比較
base_year, base_month, base_day, base_hour, base_minute, base_second = 2021, 5, 23, 1, 10, 20
dt_comp_value_1 = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second)
dt_comp_utc = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second, tzinfo=datetime.timezone.utc)
dt_comp_value_2 = datetime.datetime(base_year + 1, base_month + 2 , base_day + 3, base_hour + 4, base_minute + 5, base_second + 6)
assert (dt_comp_value_1 < dt_comp_value_2) == True
assert (dt_comp_value_1 <= dt_comp_value_2) == True
assert (dt_comp_value_1 > dt_comp_value_2) == False
assert (dt_comp_value_1 >= dt_comp_value_2) == False
assert (dt_comp_value_1 == dt_comp_value_2) == False
# date()メソッドで対応するdatetime.date(日付)が取得可能
assert dt_comp_value_1.date() == datetime.date(base_year, base_month , base_day)
# dt_comp_value_1とdt_comp_utcはタイムゾーンが異なるので同じではない
assert (dt_comp_value_1 == dt_comp_utc) == False
datetimeとtimedeltaの演算
base_year, base_month, base_day, base_hour, base_minute, base_second = 2021, 5, 23, 1, 10, 20
dt_calc_value1 = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second)
dt_calc_value2 = datetime.datetime(base_year + 1, base_month + 1 , base_day + 1, base_hour + 1, base_minute + 2, base_second + 3, 4)
# dt_calc_value2からdt_calc_value1を引いた差分のtimedelta
td = dt_calc_value2 - dt_calc_value1
assert type(td) is datetime.timedelta
# timedeltaで内部的に保持されるのは days, seconds, microsecondsのみ
assert td.days == 365 + 31 + 1
assert td.seconds == 1 * 60 * 60 + 2 * 60 + 3
assert td.microseconds == 4
# timedeltaの初期化 全て7daysの値を指定
td_week = datetime.timedelta(weeks=1)
td_days = datetime.timedelta(days=7)
td_hours = datetime.timedelta(hours=7*24)
td_minutes = datetime.timedelta(minutes=7*24*60)
td_seconds = datetime.timedelta(seconds=7*24*60*60)
td_milliseconds = datetime.timedelta(milliseconds=7*24*60*60*1000)
td_microseconds = datetime.timedelta(microseconds=7*24*60*60*1000*1000)
assert td_week == td_days == td_hours == td_minutes == td_seconds == td_milliseconds == td_microseconds
# total_seconds()メソッドで総秒数:floatが取得可能
assert td.total_seconds() == td.days * 24 * 60 * 60 + td.seconds + float(td.microseconds/1000000)
# dt_calc_value1にtdを足すと元の値に戻る
assert dt_calc_value1 + td == dt_calc_value2
# 割り算
assert datetime.timedelta(weeks=1) / datetime.timedelta(days=1) == 7
assert datetime.timedelta(weeks=1) / datetime.timedelta(minutes=1) == 7*24*60
dadatetimeからstrの変換
base_year, base_month, base_day, base_hour, base_minute, base_second = 2021, 5, 23, 1, 10, 20
dt_tzinfo_none = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second)
dt_utc = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second, tzinfo=datetime.timezone.utc)
dt_asia_tokyo = datetime.datetime(base_year, base_month , base_day, base_hour, base_minute, base_second, tzinfo=datetime.timezone(datetime.timedelta(seconds=32400)))
assert dt_tzinfo_none.strftime("%Y/%m/%d %H:%M:%S") == "2021/05/23 01:10:20"
# tzinfo=Noneの場合は、%zを指定しても無視される。
assert dt_tzinfo_none.strftime("%Y/%m/%d %H:%M:%S%z") == "2021/05/23 01:10:20"
assert dt_utc.strftime("%Y/%m/%d %H:%M:%S%z") == "2021/05/23 01:10:20+0000"
assert dt_asia_tokyo.strftime("%Y/%m/%d %H:%M:%S%z") == "2021/05/23 01:10:20+0900"
strからdadatetimeの変換
dt_from_str_1 = datetime.datetime.strptime('2021/05/23 01', '%Y/%m/%d %H')
assert type(dt_from_str_1) is datetime.datetime
assert dt_from_str_1 == datetime.datetime(2021, 5 , 23, 1)
dt_from_str_2 = datetime.datetime.strptime('2021/05/23 01:10:20+0900', '%Y/%m/%d %H:%M:%S%z')
assert type(dt_from_str_2) is datetime.datetime
assert dt_from_str_2 == datetime.datetime(2021, 5 , 23, 1, 10, 20, tzinfo=datetime.timezone(datetime.timedelta(seconds=32400)))
関数
定義
def greet(name):
return "こんにちは{}さん".format(name)
assert greet("hoge") == "こんにちはhogeさん"
条件分岐
if、elif、else
def if_sample(value):
if value == 1:
return "value is 1"
elif value == 2:
return "value is 2"
else:
return "else value"
assert if_sample(1) == "value is 1"
assert if_sample(2) == "value is 2"
assert if_sample(3) == "else value"
複合データ
list
# list
list_value = ["hoge", "fuga", "piyo"]
# サイズと中身のチェック
assert len(list_value) == 3
assert list_value[0] == "hoge"
assert list_value[1] == "fuga"
assert list_value[2] == "piyo"
assert type(list_value) is list
with pytest.raises(IndexError):
assert list_value[3] == ""
# index指定の変更
list_value[2] = "piyo2"
assert list_value[2] == "piyo2"
# 追加
list_value.append("hogera")
assert len(list_value) == 4
assert list_value[3] == "hogera"
# index指定の削除
del list_value[3]
assert len(list_value) == 3
list 型混在
list_value = ["hoge", 1, 2.0, 3, 4]
assert list_value[0] == "hoge"
assert type(list_value[0]) is str
assert list_value[1] == 1
assert type(list_value[1]) is int
assert list_value[2] == 2.0
assert type(list_value[2]) is float
tuple
tuple_value = (1, "two", 3, 4, 5)
assert type(tuple_value) is tuple
assert len(tuple_value) == 5
assert tuple_value[0] == 1
assert type(tuple_value[0]) is int
assert tuple_value[1] == "two"
assert type(tuple_value[1]) is str
# インデックスが2以降の要素を含むタプルの取得
assert type(tuple_value[2:]) is tuple
assert tuple_value[2:] == (3, 4, 5)
# インデックスが3以降の要素を含むタプルの取得
assert tuple_value[3:] == (4, 5)
# インデックスが2より小さい要素を含むタプルの取得
assert tuple_value[:2] == (1, "two")
# インデックスが1以降で3より小さい要素を含むタプルの取得
assert tuple_value[1:3] == ("two", 3)
dict
dict_value = {1:"first", 2:"second", "three":"third"}
assert type(dict_value) is dict
assert len(dict_value) == 3
assert dict_value[1] == "first"
assert dict_value[2] == "second"
assert dict_value["three"] == "third"
# keys()でキーを取得
dict_value_keys = list(dict_value.keys())
assert type(dict_value_keys[0]) is int
assert type(dict_value_keys[1]) is int
assert type(dict_value_keys[2]) is str
# キーが存在しないとき
with pytest.raises(KeyError):
assert dict_value[4] == "third"
# getであればエラーならずNoneが返却される。
assert dict_value.get(4) == None
# エントリー追加
dict_value[4] = "fourth"
assert dict_value[4] == "fourth"
# エントリー削除
del dict_value[4]
assert dict_value.get(4) == None
set
# 100, 100.0は同一値なので単一エントリーになる
set_value = {"hoge", "hoge", "fuga", (1, 2), 100, 100.0, 200}
assert type(set_value) is set
# "hoge"は1個としてカウント、100, 100.0も同様
assert len(set_value) == 5
assert "hoge" in set_value
assert "fuga" in set_value
assert (1, 2) in set_value
# 100でも100.0でも含まれる
assert 100 in set_value
assert 100.0 in set_value
assert 200 in set_value
複合データの関連内容
zipとenumerate
# zip関数は、複数のイテラブルなオブジェクトの要素をまとめる関数
expected_dic = {1:"a", 2:"b", 3:"c"}
expected_tuple_list = ((1, "a"), (2, "b"), (3, "c"))
# item自体のfor
i = 0
for item in zip([1, 2, 3], ["a", "b", "c"]):
assert item == expected_tuple_list[i]
assert type(item) is tuple
i += 1
# key, valueのfor
for key, value in zip([1, 2, 3], ["a", "b", "c"]):
assert value == expected_dic[key]
assert type(key) is int
assert type(value) is str
# index付きのfor
for i, item in enumerate(zip([1,2,3], ["a", "b", "c"])):
assert item == expected_tuple_list[i]
range関数
result = []
for i in range(5):
result.append(i)
assert type(i) is int
assert result == [0, 1, 2, 3, 4]
# range関数の戻り値はrange
assert type(range(5)) is range
result.clear()
# 範囲指定
for i in range(1, 4):
result.append(i)
assert type(i) is int
assert result == [1, 2, 3]
result.clear()
# 負も指定可能
for i in range(-2, 3):
result.append(i)
assert type(i) is int
assert result == [-2, -1, 0, 1, 2]
result.clear()
# 増分指定
for i in range(1, 10, 2):
result.append(i)
assert type(i) is int
assert result == [1, 3, 5, 7, 9]
タプルやリストのアンパック
シーケンスのアンパックで変数(str)を一括で定義
str_value_1, str_value_2 = "hoge", "fuga"
assert str_value_1 == "hoge"
assert type(str_value_1) is str
assert str_value_2 == "fuga"
assert type(str_value_2) is str
シーケンスのアンパックで変数(str,int, float)を一括で定義
str_value, int_value, float_value = "hoge", 1, 2.0
assert str_value == "hoge"
assert type(str_value) is str
assert int_value == 1
assert type(int_value) is int
assert float_value == 2.0
assert type(float_value) is float
シーケンス(tuple)のアンパックで変数を一括で定義
bread1, bread2, bread3 = ("アンパン", "食パン", "カレーパン")
assert type(bread1) is str
assert bread1 == "アンパン"
assert bread2 == "食パン"
assert bread3 == "カレーパン"
*を利用したアンパック
str_first, str_second, *str_third = "hoge1", "hoge2", "hoge3", "hoge4", "hoge5"
assert str_first == "hoge1"
assert type(str_first) is str
assert str_second == "hoge2"
assert type(str_second) is str
assert str_third == ["hoge3", "hoge4", "hoge5"]
assert type(str_third) is list
str_first, *str_second, str_third = "hoge1", "hoge2", "hoge3", "hoge4", "hoge5"
assert str_first == "hoge1"
assert type(str_first) is str
assert str_second == ["hoge2", "hoge3", "hoge4"]
assert type(str_second) is list
assert str_third == "hoge5"
assert type(str_third) is str
dictのアンパック
def bread_info(name, price, cost):
return "name:{} price:{}, cost:{}".format(name, price, cost)
bread_dict = {"name":"アンパン", "price":"140", "cost":"50"}
assert bread_info(**bread_dict) == "name:アンパン price:140, cost:50"
リスト内包表記
strが要素のlist
person_name_list = ["{}さん".format(name) for name in ["源","結衣"]]
assert type(person_name_list) is list
assert person_name_list[0] == "源さん"
assert person_name_list[1] == "結衣さん"
dict キー:int 値:int
# 0 , 1, 2, 3, 4の値がキー、各キーの二乗の値が値のdict
squares = {number: number**2 for number in [0, 1, 2, 3, 4]}
assert type(squares) is dict
assert len(squares) == 5
squares_keys = list(squares.keys())
assert squares_keys == [0, 1, 2, 3, 4]
squares_values = list(squares.values())
assert squares_values == [0, 1, 4, 9, 16]
i = 0
for square_key in squares.keys():
assert square_key == i
i += 1
for i, square_key in enumerate(squares.keys()):
assert square_key == i
i = 0
for value_tuple in squares.items():
assert value_tuple == (i, i**2)
i += 1
i = 0
for key, value in squares.items():
assert key == i
assert value == i**2
i += 1
i = 0
for key, value in squares.items():
assert (key, value) == (i, i**2)
i += 1
dict キー:tuple 値:str
person_tuple_list = [('源', 40), ('結衣', 32)]
person_dict = {(name,age):('{} is {} years old.'.format(name, age)) for name,age in person_tuple_list}
assert type(person_dict) is dict
assert len(person_dict) == 2
person_dict_keys = list(person_dict.keys())
assert len(person_dict_keys) == 2
assert type(person_dict_keys[0]) is tuple
assert person_dict_keys[0] == person_tuple_list[0]
assert type(person_dict_keys[1]) is tuple
assert person_dict_keys[1] == person_tuple_list[1]
person_dict_values = list(person_dict.values())
assert len(person_dict_values) == 2
assert type(person_dict_values[0]) is str
assert person_dict_values[0] == "源 is 40 years old."
assert person_dict[person_tuple_list[0]] == "源 is 40 years old."
assert type(person_dict_values[1]) is str
assert person_dict_values[1] == "結衣 is 32 years old."
assert person_dict[person_tuple_list[1]] == "結衣 is 32 years old."
set
# ["源", "結衣", "桃太郎"]の長さが3より小さい要素のみを含むsetを宣言
person_name_set = {name for name in ["源", "結衣", "桃太郎"] if len(name) < 3}
assert type(person_name_set) is set
assert "源" in person_name_set
assert "結衣" in person_name_set
assert "太郎" not in person_name_set
raneと併用
result_list = [i for i in range(10) if i % 2 == 0]
assert type(result_list) is list
assert len(result_list) == 5
assert result_list == [0, 2, 4, 6, 8]
内包表記の問題点
宣言時に全てのデータが展開されるのでメモリ使用量を考慮する必要があります。
import random
import string
import os
import psutil
RANDAM_STR_ELEMENT_SIZE = 1024 * 1024
RANDAM_STR_LIST_SIZE = 10
def generate_randam_str(dat):
buffer = []
try:
for i in range(RANDAM_STR_ELEMENT_SIZE):
buffer.append(random.choice(dat))
return ''.join(buffer)
finally:
buffer.clear()
dat = string.digits + string.ascii_lowercase + string.ascii_uppercase
process = psutil.Process(os.getpid())
rss_value_1 = process.memory_info().rss
randam_str_list = [generate_randam_str(dat) for i in range(RANDAM_STR_LIST_SIZE)]
assert len(randam_str_list) == RANDAM_STR_LIST_SIZE
for i in range(RANDAM_STR_LIST_SIZE):
assert len(randam_str_list[i]) == RANDAM_STR_ELEMENT_SIZE
rss_value_2 = process.memory_info().rss
print("増分={}Kbyte".format((rss_value_2 - rss_value_1)/1024))
# 2回目以降に増分が見えなくなるので、randam_str_listを削除してインタラクティブセッションをきれいにする。
del randam_str_list
実行結果は以下のようになりました。値は実行時の状態により上下するとは思います。
増分=10160.0Kbyte
内包表記の問題点の解消方法
ジェネレーター式でイテレータを返却し、アクセス時だけメモリが利用されるようにする。
import random
import string
import os
import psutil
RANDAM_STR_ELEMENT_SIZE = 1024 * 1024
RANDAM_STR_LIST_SIZE = 10
def generate_randam_str(dat):
buffer = []
try:
for i in range(RANDAM_STR_ELEMENT_SIZE):
buffer.append(random.choice(dat))
return ''.join(buffer)
finally:
buffer.clear()
dat = string.digits + string.ascii_lowercase + string.ascii_uppercase
process = psutil.Process(os.getpid())
rss_value_1 = process.memory_info().rss
randam_str_list = (generate_randam_str(dat) for i in range(RANDAM_STR_LIST_SIZE))
rss_value_2 = process.memory_info().rss
print("増分1={}Kbyte".format((rss_value_2 - rss_value_1)/1024))
for randam_str in randam_str_list:
assert len(randam_str) == RANDAM_STR_ELEMENT_SIZE
rss_value_3 = process.memory_info().rss
print("増分2={}Kbyte".format((rss_value_3 - rss_value_1)/1024))
del randam_str_list
イテレータにアクセスしてメモリ利用量が上がらないことを確認しているで分かりにくいですが、改善ポイントとしては以下の部分となります。
- #randam_str_list = [generate_randam_str(dat) for i in range(RANDAM_STR_LIST_SIZE)]
+ #randam_str_list = (generate_randam_str(dat) for i in range(RANDAM_STR_LIST_SIZE))
実行結果は以下のようになりました。値は実行時の状態により上下するとは思います。
増分1=0.0Kbyte
増分2=1156.0Kbyte
class
定義
# class Python 3系は新スタイルクラスのみなので新旧を考慮する必要なし(PersonClass(object)と書いても問題なし)
# Python 2系(2.2以降)はclass PersonClass(object):と記載する必要あり
class PersonClass(object):
# クラス変数
next_person_id = 1
# 初期化メソッド内でインスタンス変数を宣言
def __init__(self, name, age):
# インスタンス変数 nameとageとperson_idを宣言
self.name = name
self.age = age
# 現在のPersonClass.next_person_idをperson_idにセット
self.person_id = PersonClass.next_person_id
# PersonClass.next_person_idをインクリメント
PersonClass.next_person_id += 1
def get_info(self):
return "name:{} age:{}".format(self.name, self.age)
def echo(self, echo_value):
return echo_value
assert type(PersonClass) is type
assert PersonClass.next_person_id == 1
person1 = PersonClass("name1", 10)
assert type(person1) is PersonClass
assert person1.name == "name1"
assert person1.age == 10
assert person1.person_id == 1
assert person1.get_info() == "name:name1 age:10"
assert person1.echo("hoge") == "hoge"
assert person1.echo(100) == 100
assert PersonClass.next_person_id == 2
person2 = PersonClass("name2", 11)
assert type(person2) is PersonClass
assert person2.name == "name2"
assert person2.age == 11
assert person2.person_id == 2
assert person2.get_info() == "name:name2 age:11"
assert PersonClass.next_person_id == 3
# クラス変数
next_person_id = 1
はクラス変数ですのでPersonClass.next_person_idで参照します。
継承
class EmployeeClass(PersonClass):
def __init__(self, name, age, employee_id):
super().__init__(name, age)
self.employee_id = employee_id
def get_info(self):
return "name:{} age:{} employee_id:{}".format(self.name, self.age, self.employee_id)
assert type(EmployeeClass) is type
employee1 = EmployeeClass("employee_name1", 13, "00001")
assert not type(employee1) is PersonClass
assert type(employee1) is EmployeeClass
assert isinstance(employee1, PersonClass)
assert isinstance(employee1, EmployeeClass)
assert employee1.name == "employee_name1"
assert employee1.age == 13
assert employee1.get_info() == "name:employee_name1 age:13 employee_id:00001"
アンダーバーとプロパティ
対象クラス
対象クラスは以下のとおりです。
class SampleClass:
def __init__(self, name):
self.name = name
self._name = "_{}".format(name)
# ネームマングリングで_SampleClass__nameに変更される。
self.__name = "__{}".format(name)
@property
def name1(self):
return self.name
@name1.setter
def name1(self, value):
self.name = value
@property
def name2(self):
return self._name
@name2.setter
def name2(self, value):
self._name = value
@property
def name3(self):
return self.__name
@name3.setter
def name3(self, value):
self.__name = value
検証処理
検証処理は以下のとおりです。
sample1 = SampleClass("sample_name1")
# メンバー名でアクセス
assert sample1.name == "sample_name1"
assert sample1._name == "_sample_name1"
# sample1.__nameは存在しないので、AttributeErrorが発生する。
with pytest.raises(AttributeError):
assert sample1.__name == "__sample_name1"
# ネームマングリング self.__nameは_クラス名__変数名に変換されるので
# _SampleClass__nameで参照可能
assert sample1._SampleClass__name == "__sample_name1"
# プロパティでのアクセス
assert sample1.name1 == "sample_name1"
assert sample1.name1 == sample1.name
assert sample1.name2 == "_sample_name1"
assert sample1.name2 == sample1._name
# プロパティでのアクセスすると__nameは参照可能
assert sample1.name3 == "__sample_name1"
継承時の検証処理
class SampleClassEx(SampleClass):
def __init__(self, name):
super().__init__(name)
self._SampleClass__name = "over write"
sample_ex = SampleClassEx("sample_ex_name1")
# _SampleClass__nameは上書きされる
assert sample_ex._SampleClass__name == "over write"
# プロパティでアクセスしSampleClassの__nameが上書きされていないことを確認
assert sample1.name3 == "__sample_name1"
assert not sample1.name3 == "over write"
その他
strの変更 頻繁なstr変更はパフォーマンス低下を招くのでlistのappendメソッドを利用
buffer = []
buffer.append("hoge")
buffer.append("fuga")
buffer.append("piyo")
result = ''.join(buffer)
assert result == "hogefugapiyo"
Type Hints
動的型付け言語であるPythonで型アノテーションを書けるようにするための構文です。PEP 484で提案され、Python 3.5で実装されました。実行には影響せず、mypyのようなツールで静的解析するために使わます。
def greet(name:str) -> str:
return "こんにちは{}さん".format(name)
assert greet("hoge") == "こんにちはhogeさん"
greet関数のnameがstrで、戻り値もstrであると指定しています。
def greet(name:str) -> str:
return 777
assert greet(1) == 777
greetを上記のように書き換えてもテストは成功します。
「Jupyter Notebook」だとmypyの静的解析が動作しませんので、.pyファイルに保存した時のイメージを以下に張り付けさせていただきます。
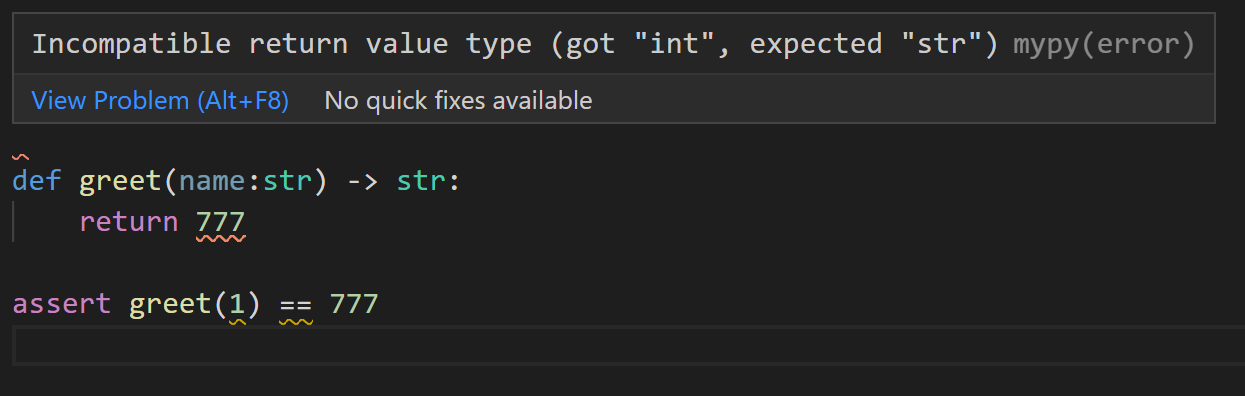
returnはstrと宣言しているのに、実際にはintとなっているとの解析結果となっています。

greetの引数はstrと宣言しているのに、実際にはintとなっているとの解析結果となっています。
ipynbファイルはgithubに登録しております。