1-1 固定長ファイルノード[入力タブ]

1.ノードの目的
固定長のテキストファイル形式のデータを読み込みます。
2.解説動画(60秒)
TBD
3.クイックスタート
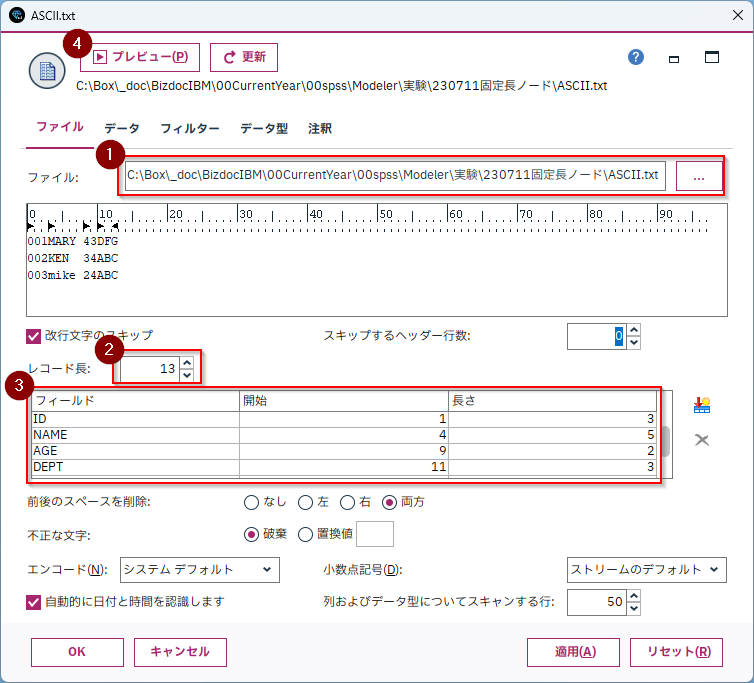
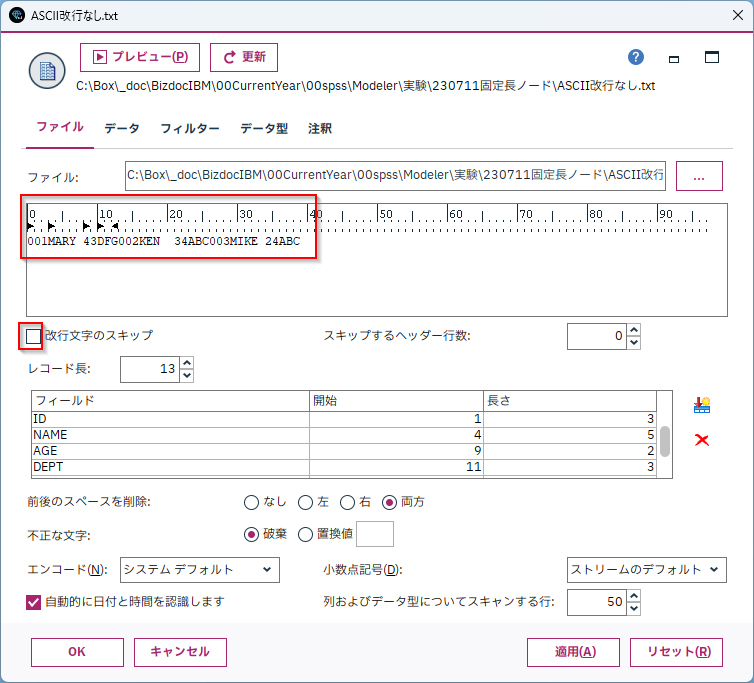
ファイルタブの[ファイル:]の[...]ボタンから読み込むファイルパスを指定します。
*サンプルのtxtファイルは[5.参考情報]からダウンロードできます。
[レコード長]に1レコードの長さを設定します。
各フィールド名と開始位置、長さを指定します。
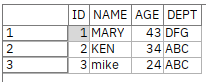
画面上のプレビューでデータが表示されます。
4.Tips
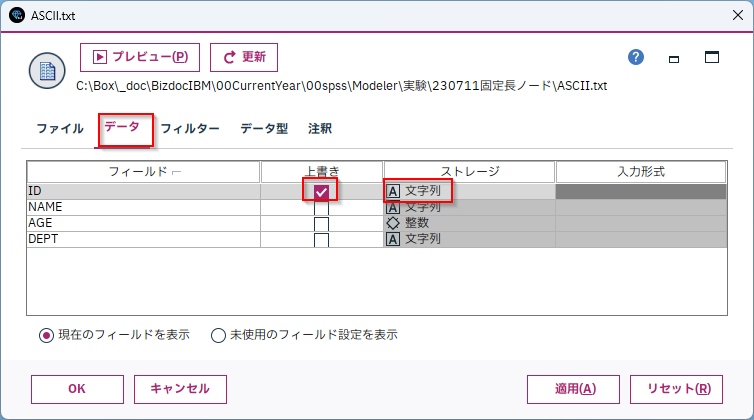
データ型の上書き
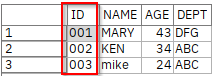
IDは自動的に「整数型」で読み込まれましたが、「文字列型」で読みたい場合は、[データ]タブで[上書き]にチェックをつけて、[ストレージ]に[文字列]を選びます。
改行なしデータ
固定長データは改行でレコードが区切られていなくても読むことができます。
[改行文字のスキップ]のチェックを外すと[レコード長]で指定した長さでレコードを区切ります。
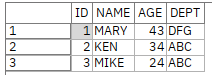
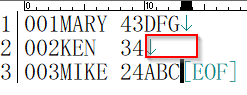
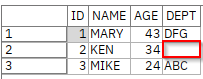
欠損値のあるデータ
以下の2行目のデータはのデータを持っていませんが、正しく読むことができます。
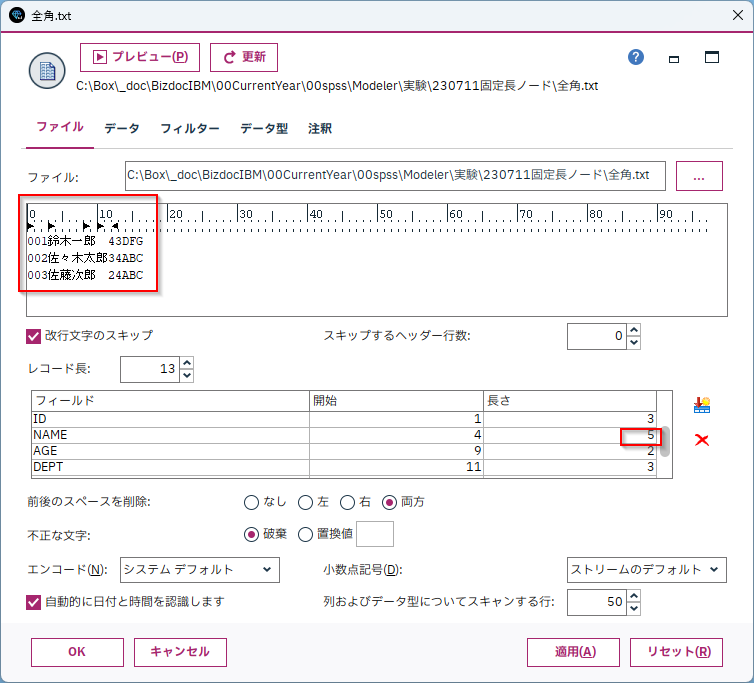
半角カナや全角の日本語データ
半角カナや全角の日本語データも読むことはできます。
ただし、バイト数ではなく、文字数で指定を行ないます。プレビューはずれて見えますが、正しく読めます。
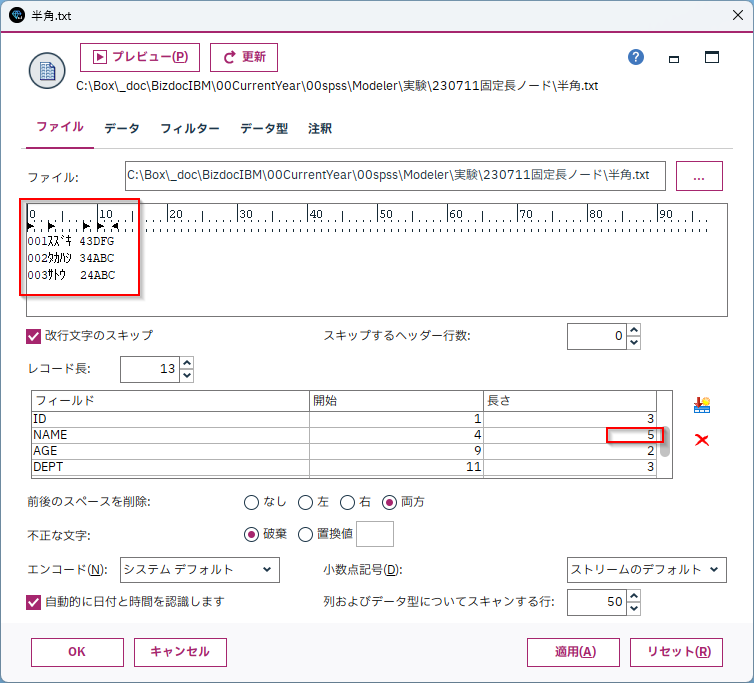
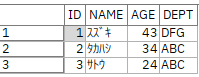
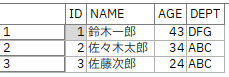
「鈴木一郎 」もShiftJISでは10バイトですが、ここでは文字数の5文字で指定します。
半角と全角のデータの混在
上記の通り文字数で長さを指定しますので、一つの列内に半角文字2文字と全角文字1文字を同じ長さとして扱っているデータが混在している場合、長さで途中で切られてしまいます。


こういうデータは文字数をそろえないと読み込むことができません。もしくはPythonなどで加工することになると思います。
列定義のスクリプト化
列がたくさんある場合はスクリプトで定義したくなることがありませす。以下の記事で紹介しています。
SPSS固定長ファイルノードの定義をmodelerスクリプトで自動化 - Qiita
固定長データ出力
固定長データ出力は専用のノードは用意されていませんが、以下のように[フラットファイル・エクスポート]をつかって出力することができます。
SPSS Modelerで固定長データ出力 - Qiita
5.参考情報
サンプルストリームとデータ
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次