SPSS Modelerでカテゴリデータをフラグとして集計して横持ちデータに変換したり、ダミー変数化するフラグノードをPythonのpandasで書き換えてみます。
0.加工のイメージ
以下のID付POSデータから以下の3パターンの加工を行ってみます。
■加工前
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
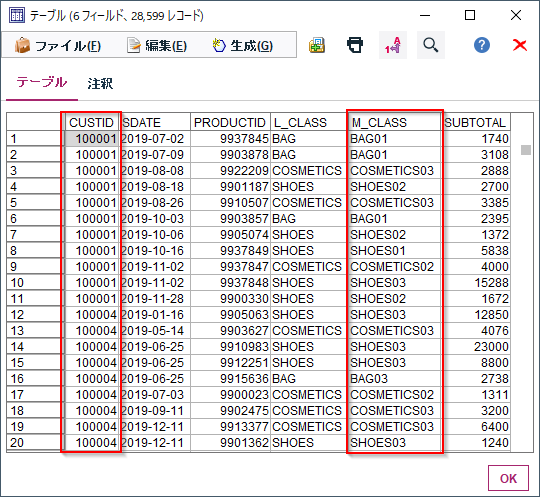
①各顧客毎に商品カテゴリ(M_CLASS)ごとの購入ありなしのフラグ化
②各顧客毎に商品カテゴリ(M_CLASS)ごとの購回数を集計
③商品カテゴリ(M_CLASS)をつかったモデルを作成するためにダミー変数化
1-1.①各顧客毎に商品カテゴリごとの購入ありなしのフラグ化。Modeler版
■加工後イメージ
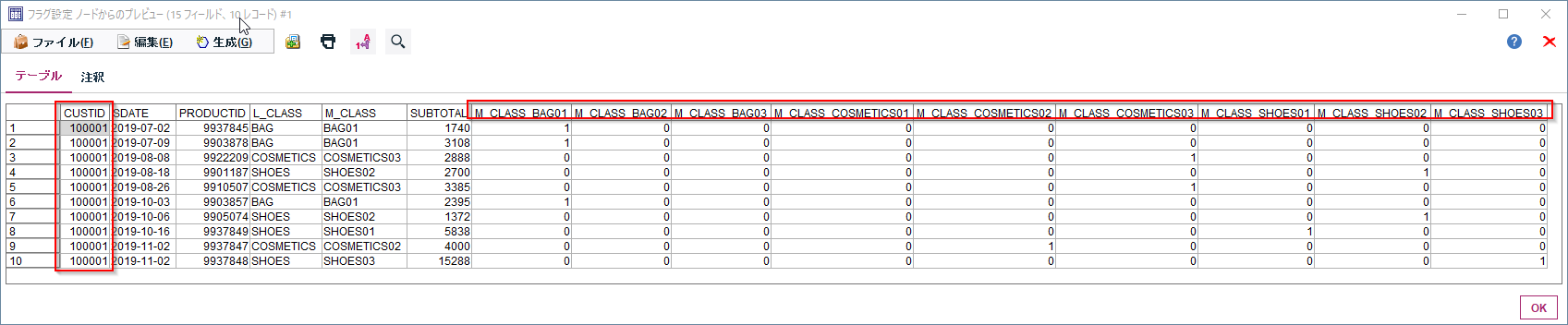
顧客毎(CUSTID)に商品中分類(M_CLASS)ごとの購入があったかどうかをフラグ化します。
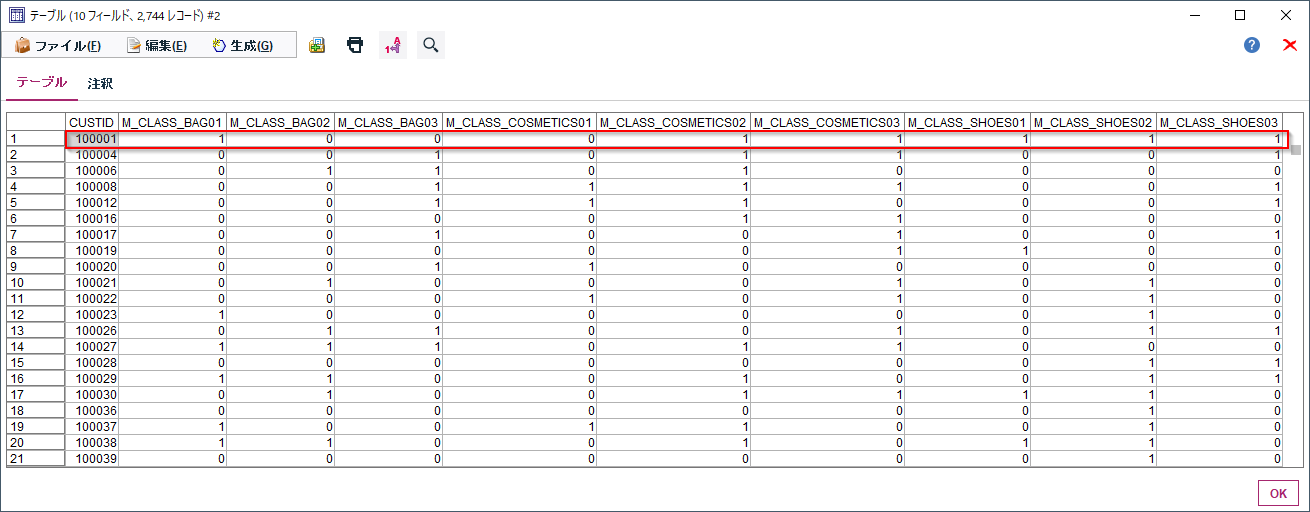
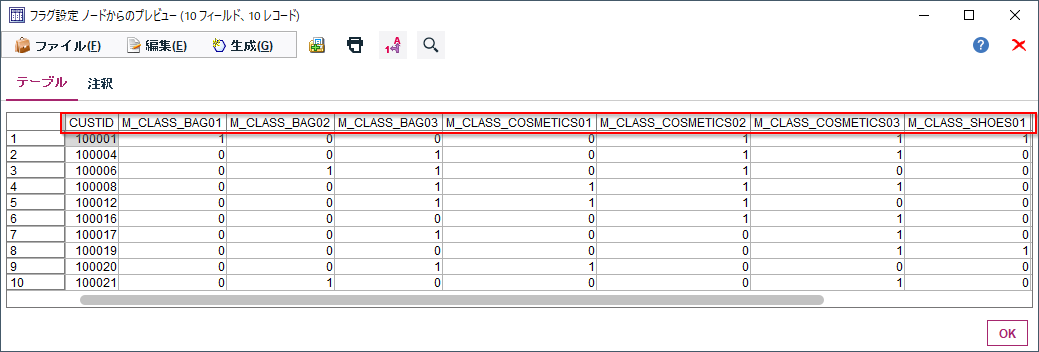
一行目をみるとCUSTID=100001はBAG01,COSMETIC02と03,SHOES01と02と03を購入したことがわかります。
フラグノードは、データ型ノードとの組合せで使われます。

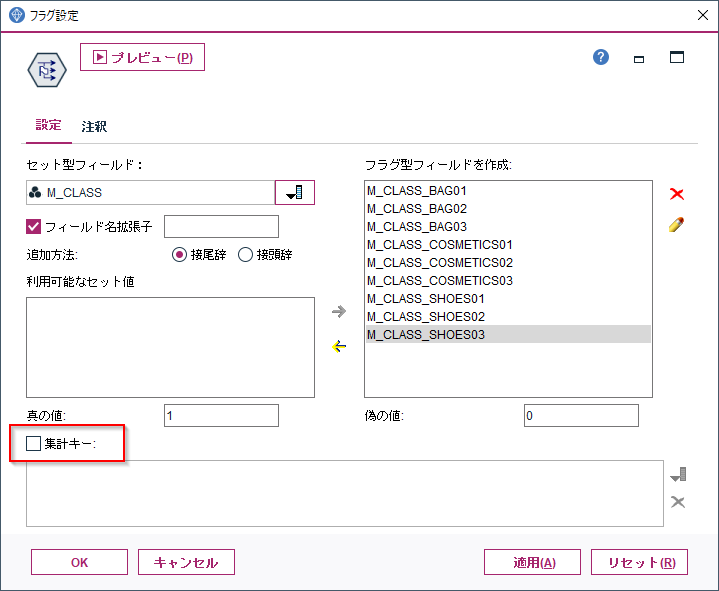
まずデータ型ノードで商品中分類(M_CLASS)にどんなカテゴリ値があるかを認識します。データ型ノードで「値の読み込み」を行うと、自動で中分類のすべてのカテゴリが認識されます。
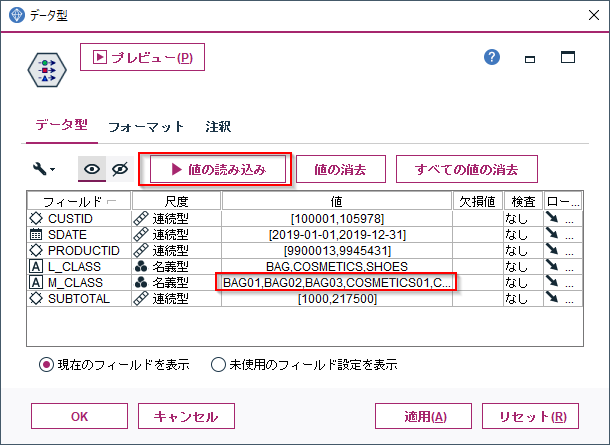
次にフラグノードでフラグ化させたいフィールドの値を選びます。以下の例では商品中分類(M_CLASS)にはBAG01,BAG02,BAG03,COMETICS01,COSMETIC02,COSMETIC03,
SHOES01,SHOES02,SHOES03があり、これらを列として展開して、購入があれば1(真の値)、なければ0(偽の値)を入れます。集計キーにCUSTIDを選ぶことで、CUSTIDで一意のレコードに集約されます。
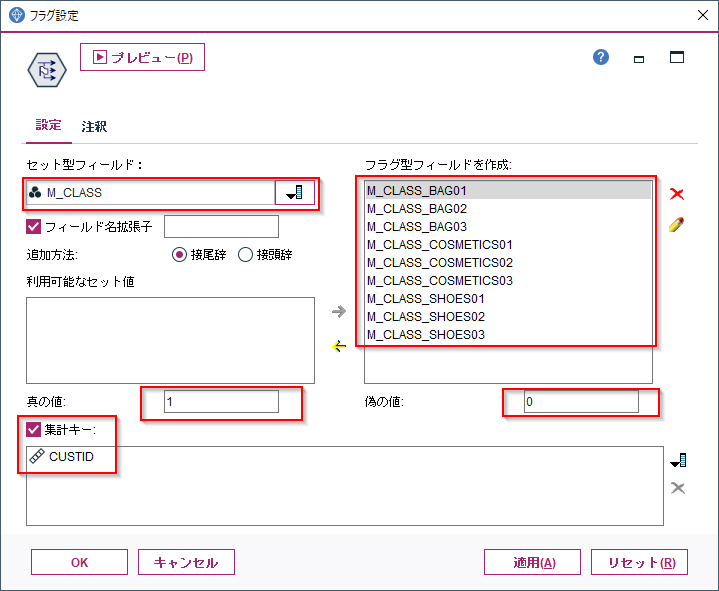
この設定の結果をプレビューすると下のようになります。顧客毎(CUSTID)に商品中分類(M_CLASS)ごとの購入があったかどうかをフラグ化できました。
フラグ化はアソシエーション分析の前処理でよく使われます。
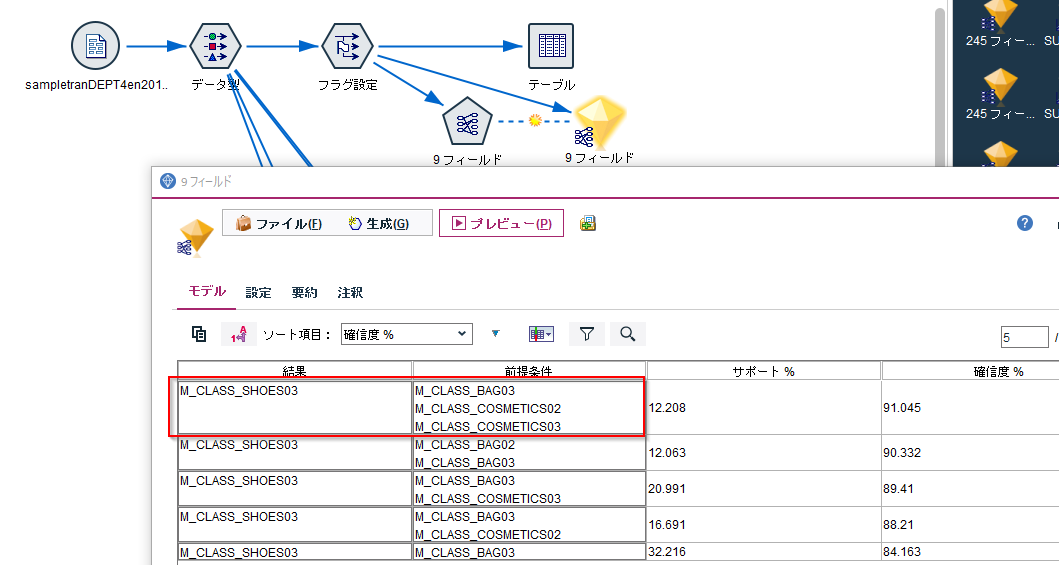
aprioriモデルなどをつかって、以下のようなBAG03、COSMETIC02,COSMETIC03を買っている人はSHOES03も買うといったルールを発見できます。
1-2.①各顧客毎に商品カテゴリごとの購入ありなしのフラグ化。pandas版
pandasでフラグ化する場合はget_dummies関数を使います。最初からget_dummiesを使っても、指定したデータに入っているカテゴリ値をすべて自動判定してフラグ化することができて便利なのですが、テストデータやスコアリングデータには学習データに存在するカテゴリが含まれていない可能性があるため、あらかじめカテゴリ値を定義することが推奨されます。
- 参考
- python】機械学習でpandas.get_dummiesを使ってはいけない - 静かなる名辞
https://www.haya-programming.com/entry/2019/08/17/184527
以下のようにM_CLASSに含まれるカテゴリのユニーク値でカテゴリを定義します。
M_CLASS_list=df1['M_CLASS'].unique()
df1["M_CLASS"] = pd.Categorical(df1["M_CLASS"], categories=M_CLASS_list)
df1["M_CLASS"].cat.categories
BAG01,BAG02,BAG03,COMETICS01,COSMETIC02,COSMETIC03,
SHOES01,SHOES02,SHOES03が定義されます。

そして、get_dummiesで0,1のフラグにします。
まず、df1[['CUSTID','M_CLASS']]でCUSTIDとM_CLASSに絞り込んだdataframeを与えます。そうしない場合はSDATE
などの集計に使わない他の列もついてきてしまいますので集計の際に厄介です。
columnsでフラグ化する列であるM_CLASSを指定します。
prefixで列名の接頭辞を指定しています。
.groupby('CUSTID').max()で、CUSTIDで一意にし、maxで0,1フラグ化されたカテゴリ値の最大値を取ります。つまり買っていれば1が立ちます。
df_flg1=pd.get_dummies(df1[['CUSTID','M_CLASS']],
columns=["M_CLASS"],
prefix="M_CLASS").groupby('CUSTID').max()
これでフラグ化ができました。
CUSTID=100001はBAG01,COSMETIC02,COSMETIC03,SHOES01,SHOES02,SHOES03を購入したことがわかります。

ちなみにdf1["M_CLASS"] = pd.Categorical(df1["M_CLASS"], categories=M_CLASS_list)の設定をしていない場合、対象としたdataframeに存在するカテゴリのみでフラグ化されてしまいます。
以下の例だと、カテゴリ設定していないdfの先頭5行に存在していたBAG01,COSMETIC03,SHOES02しかフラグ化されていません。

カテゴリを定義したdataframeのdf1を使うと先頭の5行にはBAG01,COSMETIC03,SHOES02しかなくてもそれ以外のカテゴリもフラグ化されています。

2-1. ②各顧客毎に商品カテゴリ(M_CLASS)ごとの購回数を集計 Modeler版
先ほどは各商品カテゴリで購入の有無をフラグ化しましたが、次は何回購入したかを集計します。
■加工後イメージ
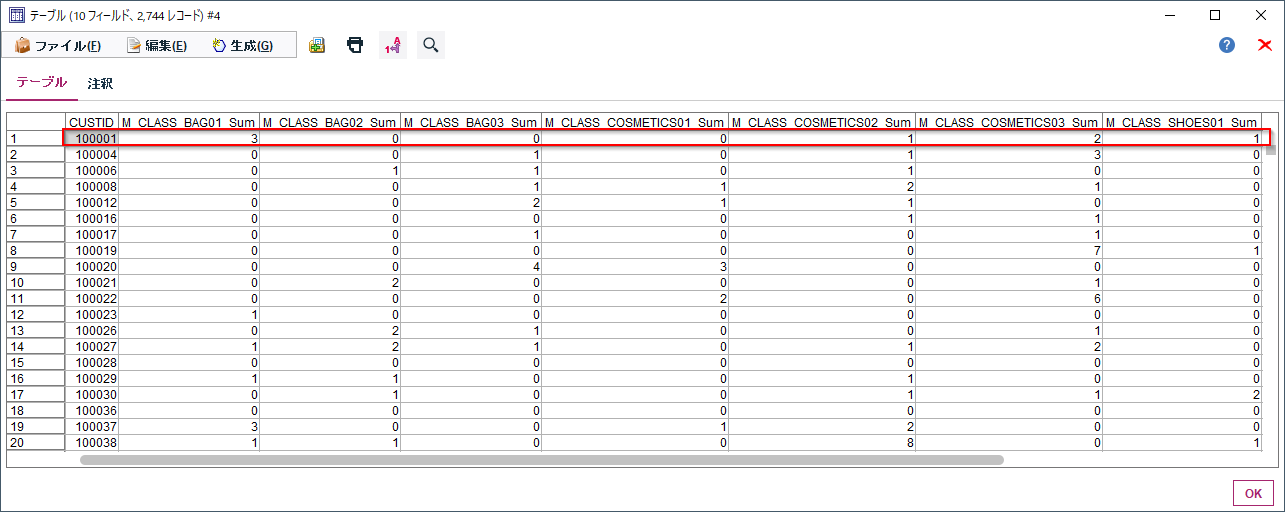
結果は以下のようになります。
一行目をみるとCUSTID=100001はBAG01を3回、,COSMETIC02を1回,COSMETIC03を2回,SHOES01を1回,SHOES02を3回,SHOES03を1回購入したことがわかります。
先ほどのデータ型ノードは流用して、フラグノードと集計ノードを使います。
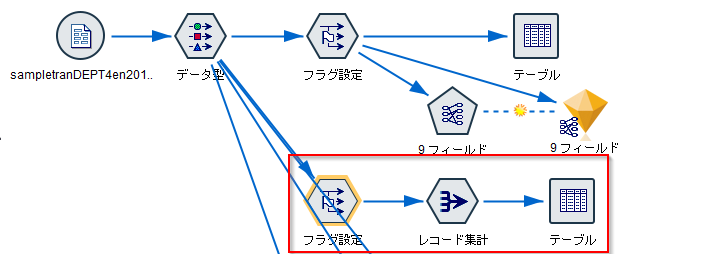
フラグノードの設定は基本的には先ほどと同じですが、フラグノード内では集計を行っていません。
プレビューをすると、フラグは作られていますが、CUSTIDで集約されていません。
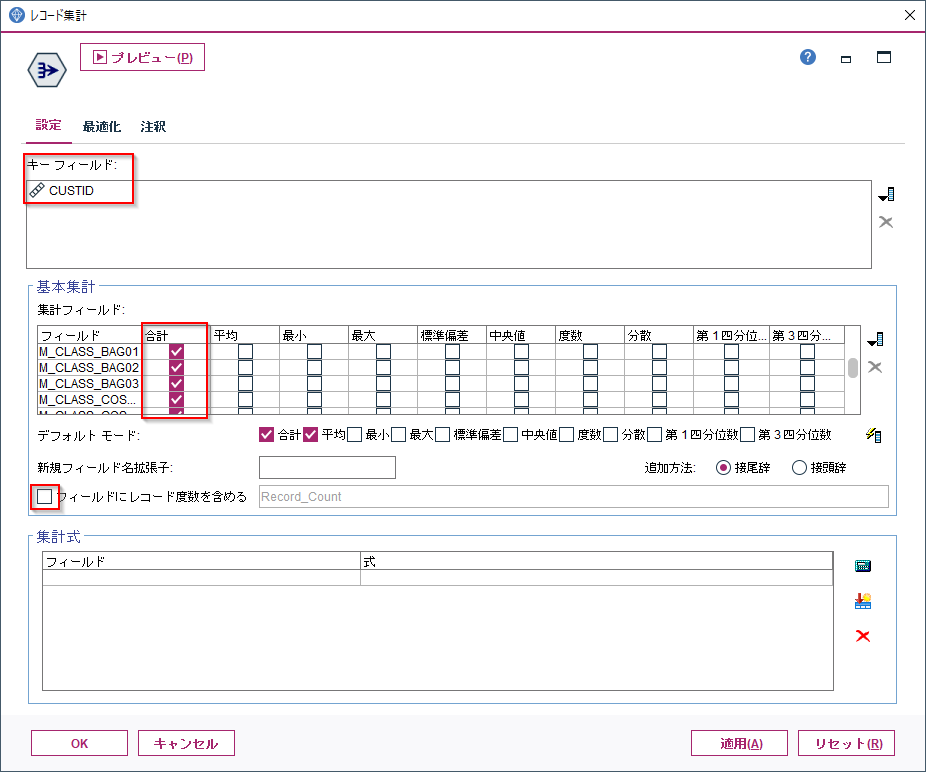
次の集計ノードでCUSTIDで集計しています。
ここで各フラグの列の合計を計算しています。(レコード件数は不要なのでチェックを外しています)。ちなみにここで最大値を選べば先ほどのありなしフラグと同じ結果になります。
結果がでました。先ほどのフラグよりもより顧客の特徴をあらわした変数ができています。
2-2. ②各顧客毎に商品カテゴリ(M_CLASS)ごとの購回数を集計 pandas版
pandas版での先ほどとの違いは.groupby('CUSTID').sum()で、maxdではなくsumを計算しているところです。
df_flg1=pd.get_dummies(df[['CUSTID','M_CLASS']],
columns=["M_CLASS"],
prefix="M_CLASS").groupby('CUSTID').sum()
期待の結果が得られます。

3-1. ③商品カテゴリ(M_CLASS)をつかったモデルを作成するためにダミー変数化 Modeler版
一般的に、カテゴリ変数を機械学習にかけるためには通常はカテゴリ変数から0,1のダミー変数を作ります。しかし、Modelerの場合は多くのモデルでは、自動的にダミー変数化してモデルを作ってくれるので意識することがあまりありません。ただ、線形回帰やロジスティック回帰などのいくつかのモデルではダミー変数化が必要です。
ここではその手順を示します。
データ型ノードは流用し、フラグノードでダミー変数を作ることができます。
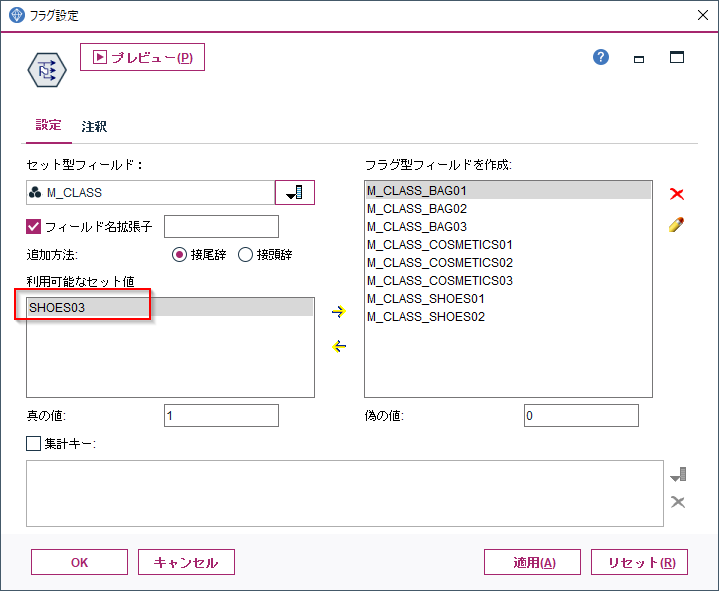
設定としては先ほどの設定から一つフラグを外します。ここではSHOES03をはずしました。
最後の一つのダミー変数は、他のダミー変数がすべて0であることで表現できます。残してしまうとモデルが不安定になるため外す必要があります。
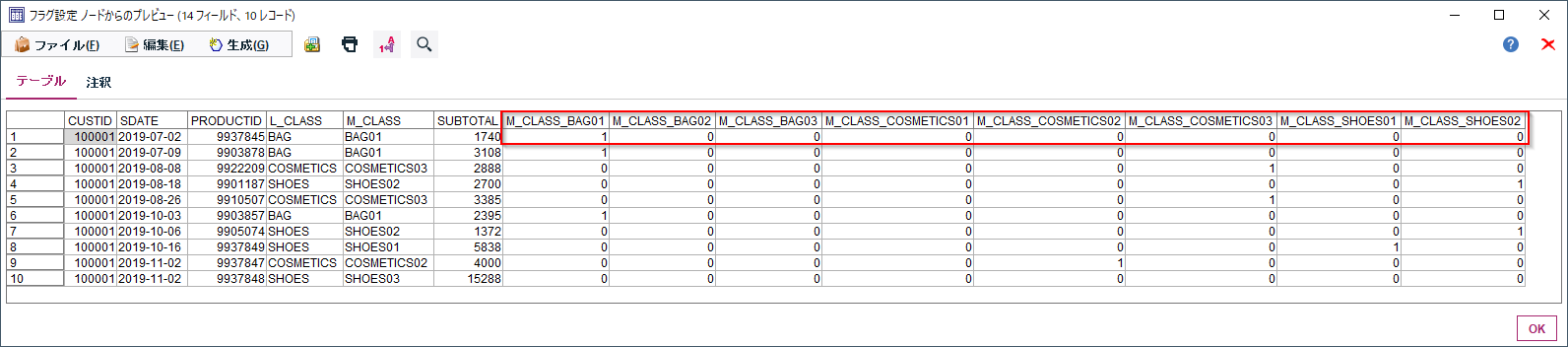
以下のようにSHOE03以外がダミー変数化されました。
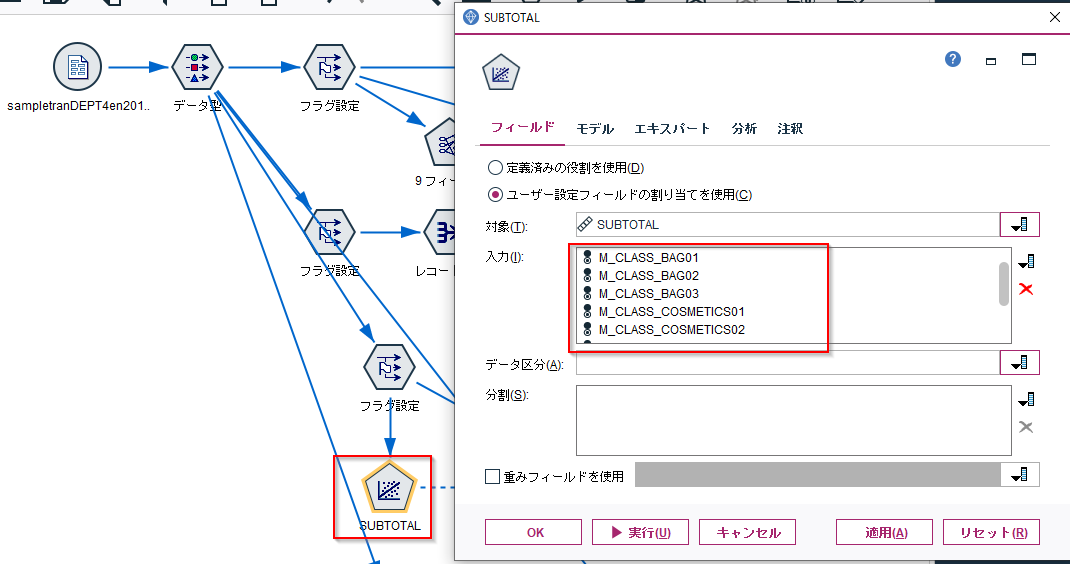
このようにダミー変数化すると、以下のように線形回帰モデルの説明変数として入力が可能になります。
なお、1次線形回帰モデルではダミー変数化しなくても説明変数として入力が可能です。
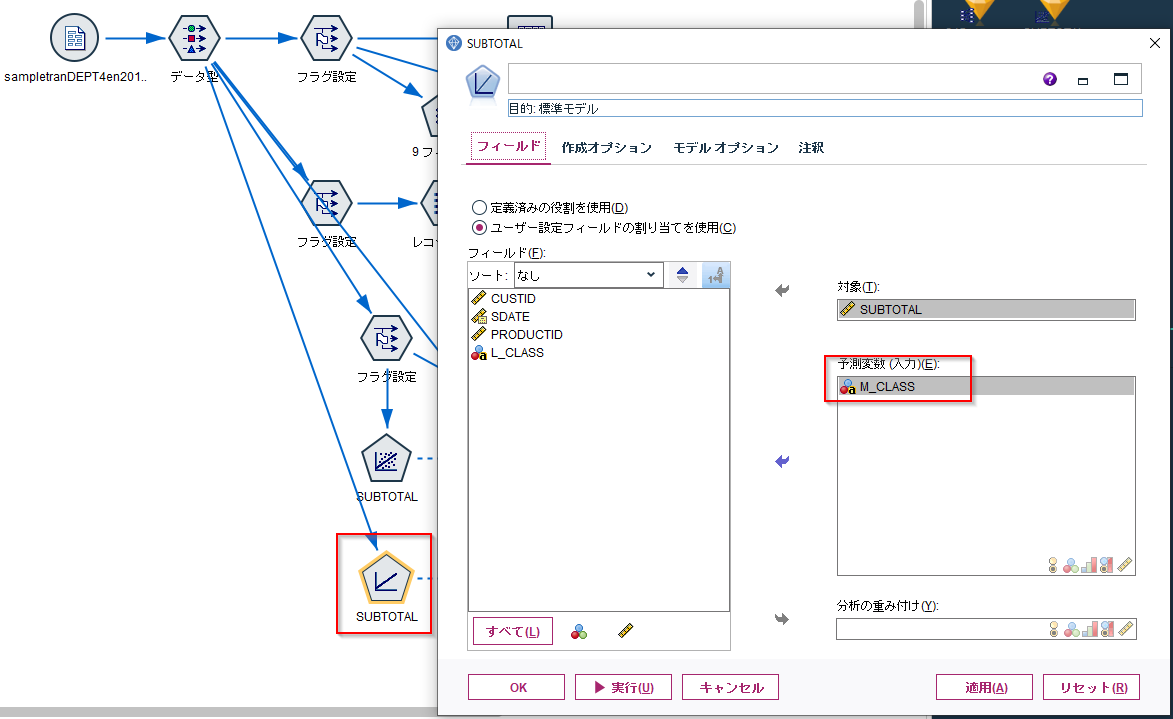
作成後のモデルの係数を確認すると、内部的にダミー変数が作られたことがわかります。そのため1次線形回帰モデルではフラグノードは不要です。
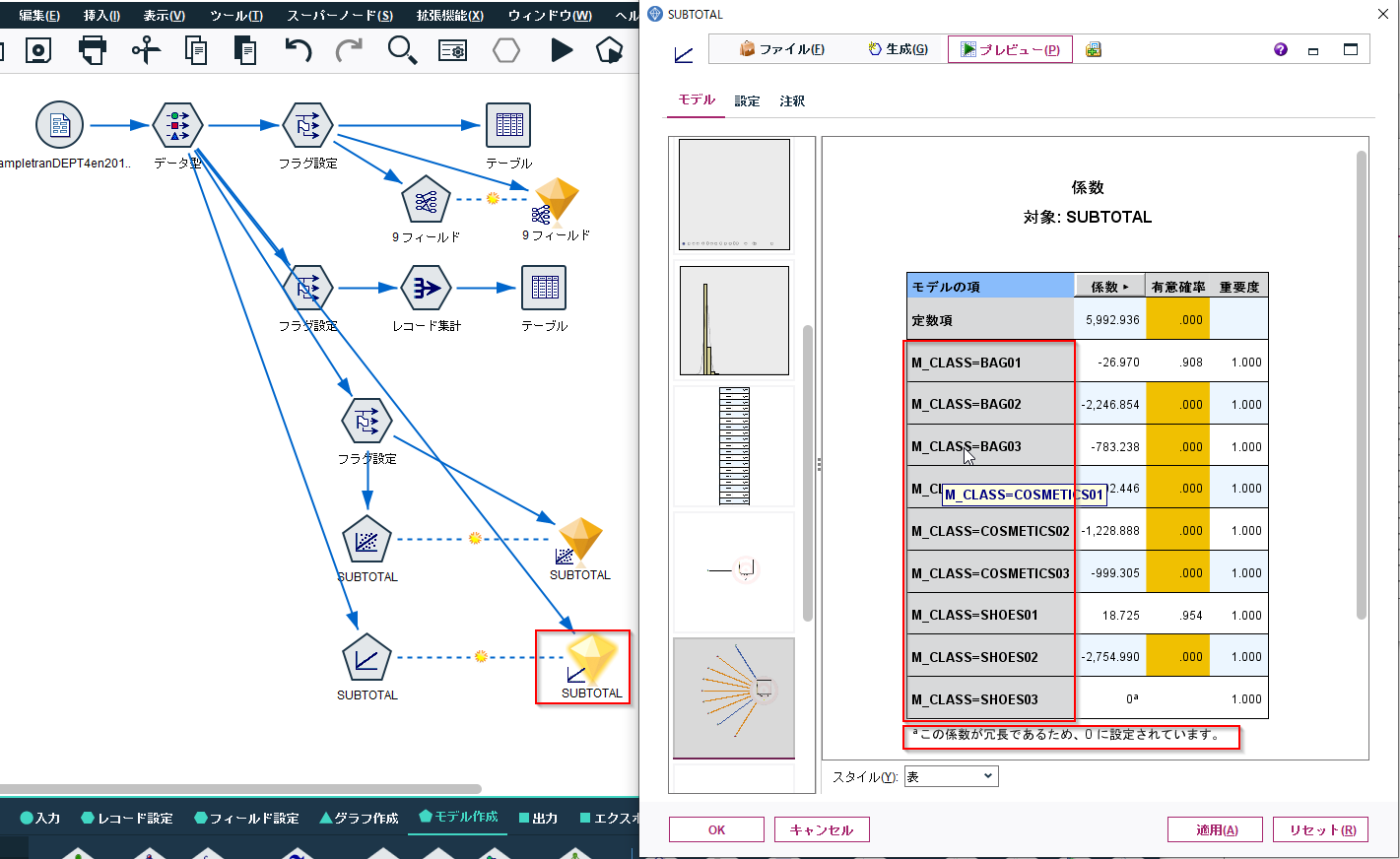
3-2. ③商品カテゴリ(M_CLASS)をつかったモデルを作成するためにダミー変数化 pandas版
scikitlearnをはじめとしてPythonのモデル作成では原則としてカテゴリ型の変数はダミー変数化する必要があります。もともとget_dummiesはフラグ化というよりはダミー変数をつくるために用意されている関数になるため、名前もそういう名前になっています。
ダミー変数を作る場合は
drop_first=Trueを指定します。このオプションによって、ModelerでSHOES03を作らなかったように、カテゴリ数-1個のダミー変数を作ります。
また、groupbyなどの集計は不要になります。
df_dummy=pd.get_dummies(df1,columns=["M_CLASS"],prefix="M_CLASS",drop_first=True)
以下のようになります。Modelerとの違いが2点ありますが、ダミー変数作成という意味では気にする必要はありません。
1.DROPされたダミー変数はSHOES03ではなくBAG01になっています。
2.M_CLASSの列自体はなくなっています。

4. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/blob/master/flag/flag.str?raw=true
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/flag/flag.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.2.1
Windows 10 64bit
Python 3.6.9
pandas 0.24.1
5. 参考情報
pandas.get_dummies — pandas 1.0.5 documentation
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.get_dummies.html