Data Science Experience Local(DSXL)のSPSS Modeler Flowsの機能を使って、故障予知モデルを作ってみます
SPSS Modeler Flowsの機能はオンプレのデスクトップソフトウェアのSPSS Modelerの機能をDSXL上で利用可能にした機能です。2018年1月のDSXL1.1.3ではBeta版になりますが、わかりやすい分析が可能ですので紹介します。
環境
DSXL 1.1.3.00 (20180122_0943) x86_64
参照
SPSS Modeler Flows add-on - IBM Data Science Experience
https://datascience.ibm.com/docs/content/local/canvas.html?audience=local&context=analytics
IBM SPSS Modeler - 概要 - 日本
https://www.ibm.com/jp-ja/marketplace/spss-modeler
A.事前準備
A1. 以下からプロジェクトのファイルをzipでダウンロードします。
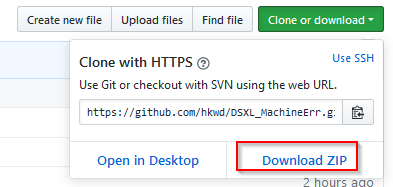
hkwd/DSXL_MachineErr
https://github.com/hkwd/DSXL_MachineErr
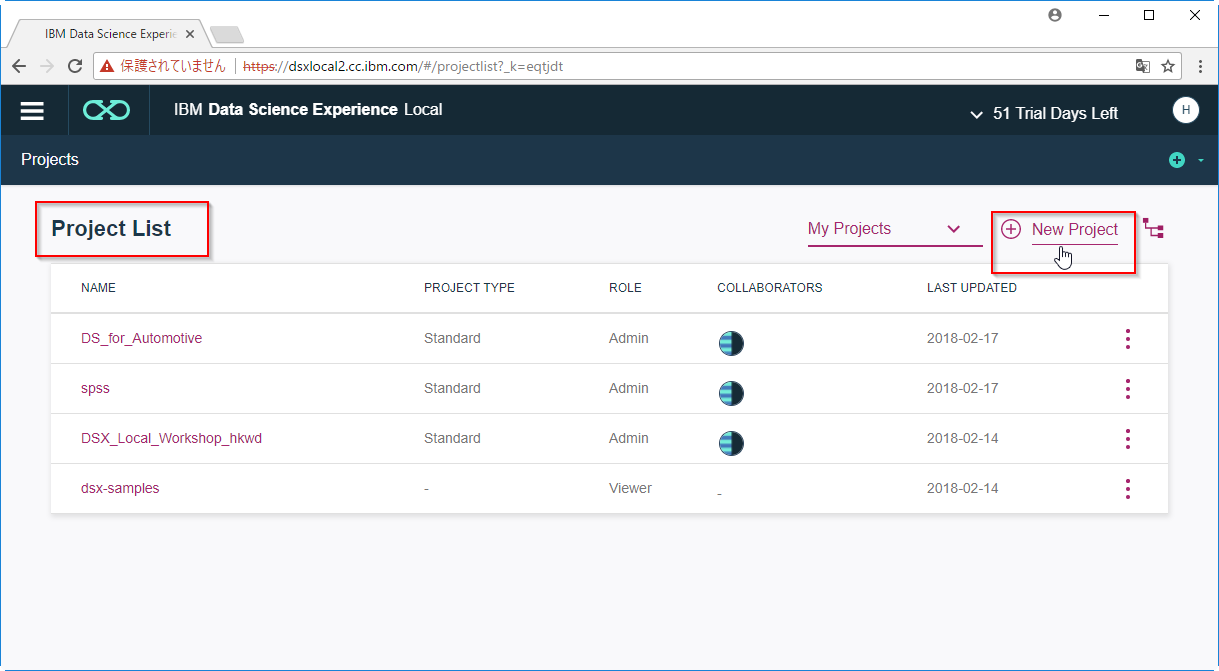
A2. DSXLにログインしプロジェクトにインポートします。
プロジェクトリストを開き、NewProjectでプロジェクトを作ります。
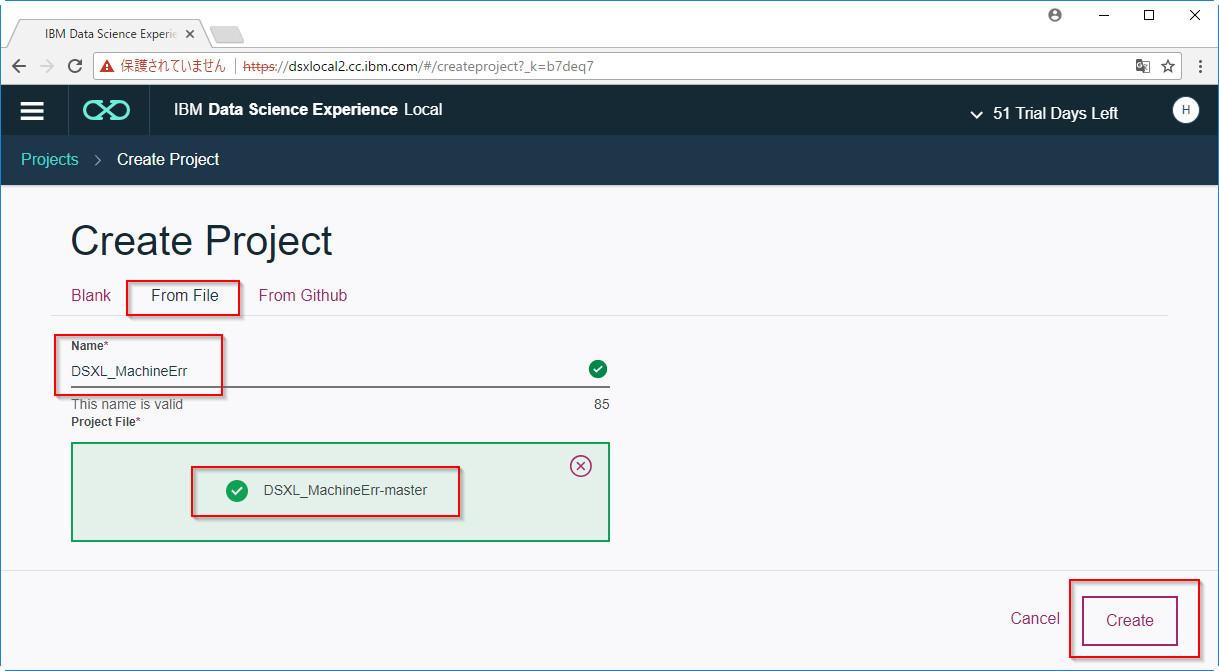
FromFileで先ほどダウンロードしたZIPファイルを指定し、Createします。
B.データの確認
B1. データを確認します
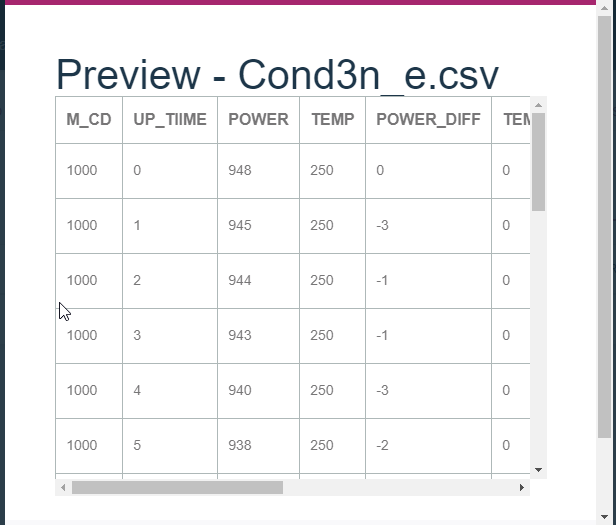
プロジェクトのAssetのDataSetsからCond3n_eというデータをPreviewします
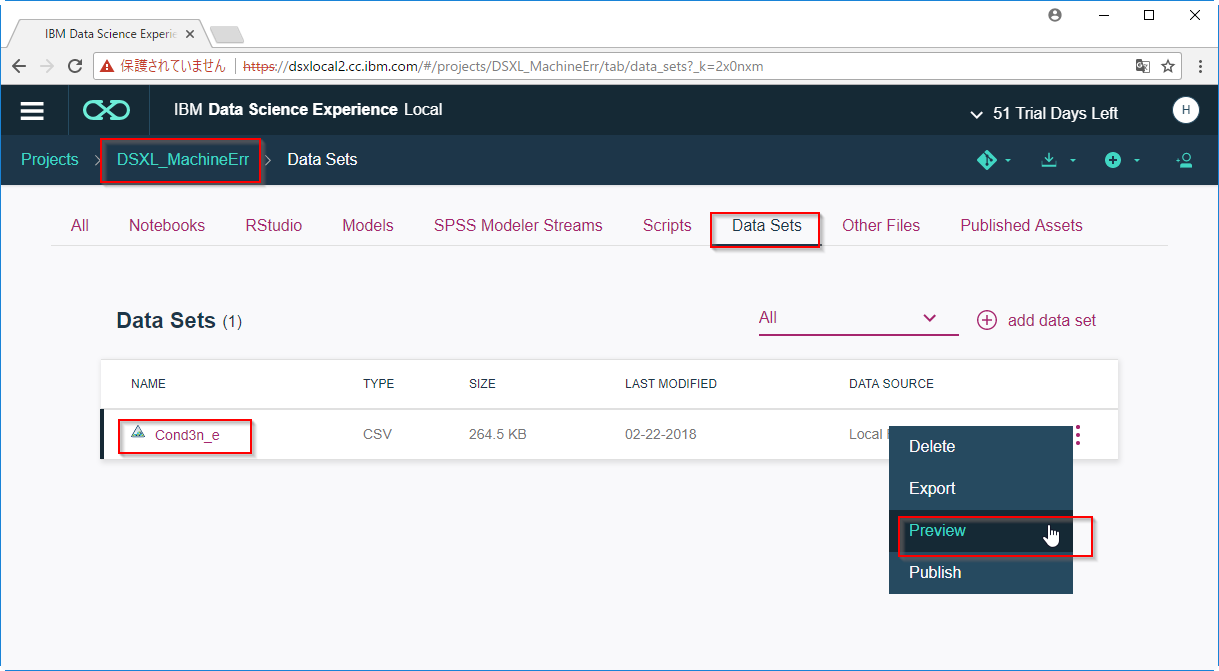
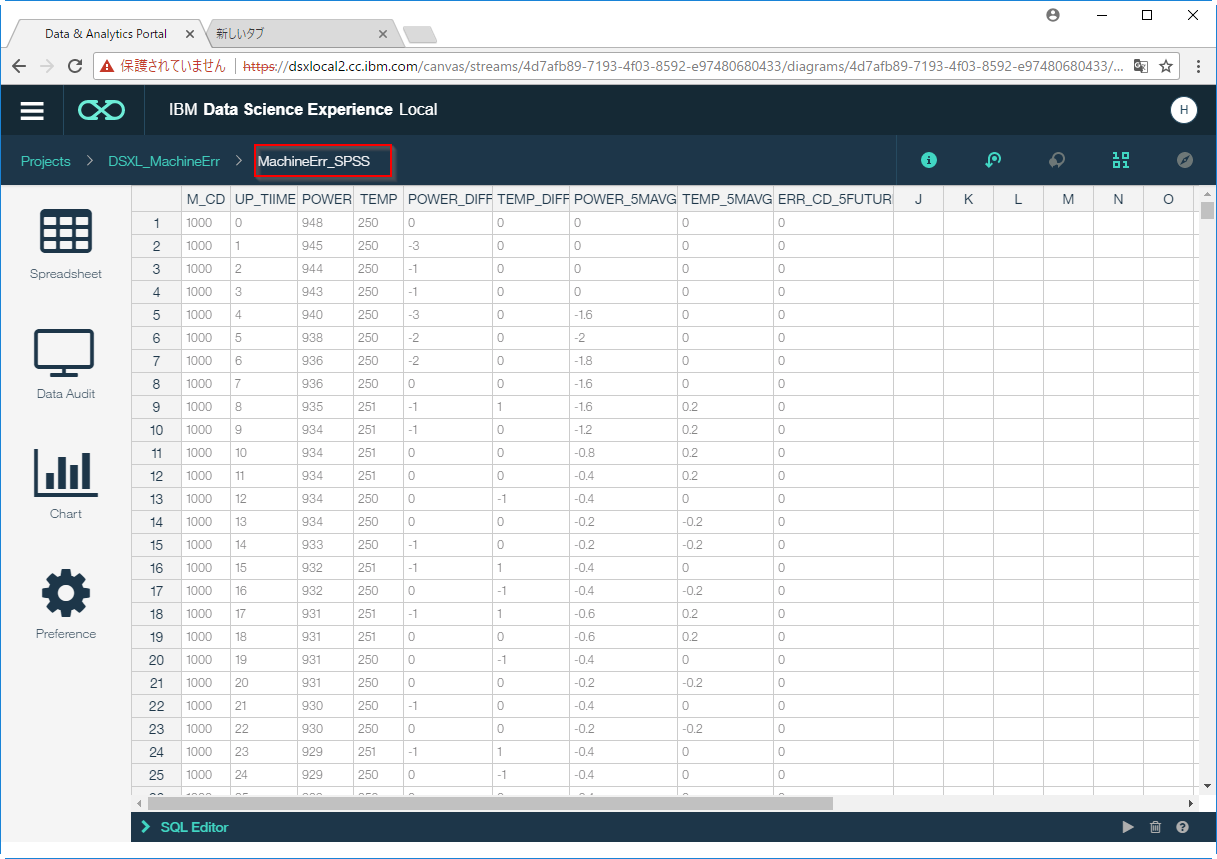
以下のようなデータが入っています。各列の意味は以下です。
M_CD: マシンコード
UP_TIIME: 起動時間
POWER: 電力
TEMP: 温度
POWER_DIFF: 電力差分
TEMP_DIFF: 温度差分
POWER_5MAVG: 電力差分5期移動平均
TEMP_5MAVG: 温度差分5期移動平均
ERR_CD_5FUTURE: 5期先エラーコード

C.モデル作成
DSXLのSPSS Modelerを使って、電力や温度の変化などから5期先のエラーコードを予測するモデルを作成します。
C1. SPSS Modeler Flows(またはStreams)のタブを開き、Add flow(またはStreams)でFlow(またはStreams)を作成を開始します。FlowまたはSteamとは分析の処理フローを定義した設計図のようなものです。
C2. Blankを選択し、任意の名前を付けてCreateします。
なお、ここで「From File」を選択するとオンプレ版のSPSS Modelerでつくった.strファイルを読み込むこともできます。
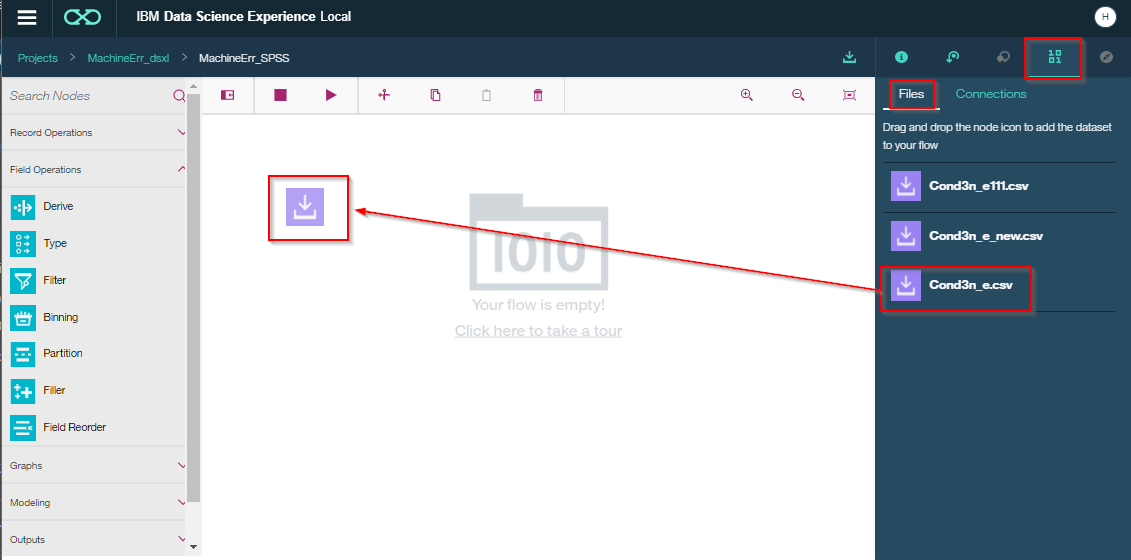
C3. 学習データを選択します。
Cond3n_e.csvをドラッグアンドドロップで中央のキャンバスという領域に置きます。
C4. データの中身を確認します。
Cond3n_e.csvのノードを選び右クリックでView Dataを選びます。
データが表示されました。
Stream名をクリックして、キャンバスに戻ります。
C5. データの型定義
Nodesの一覧からField OperationsのTypeを選び、キャンバスにドラッグアンドドロップします。
そして、Cond3n_e.csvのノードと接続します。
次に右クリックをしてプロパティを開きます。
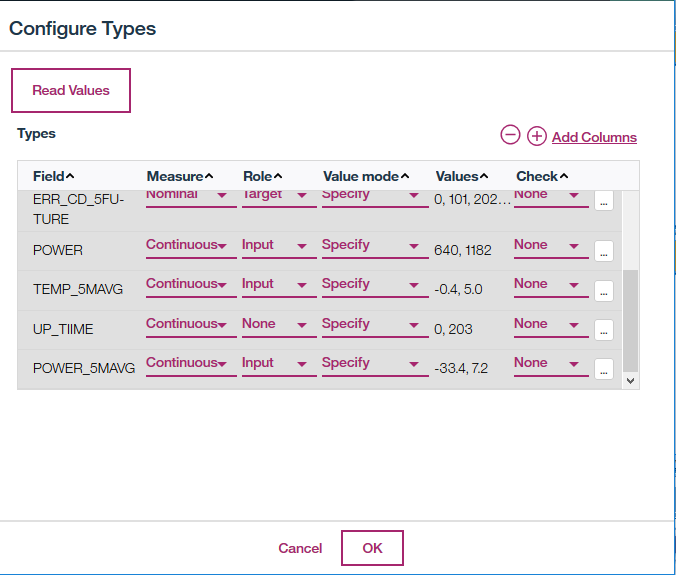
Settingsを開き、Configure Typesをクリックします。
Add Columnsで列のデータ型を定義します。
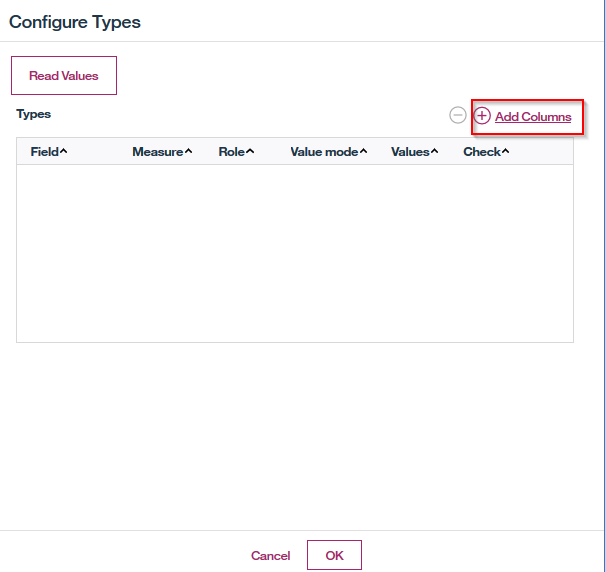
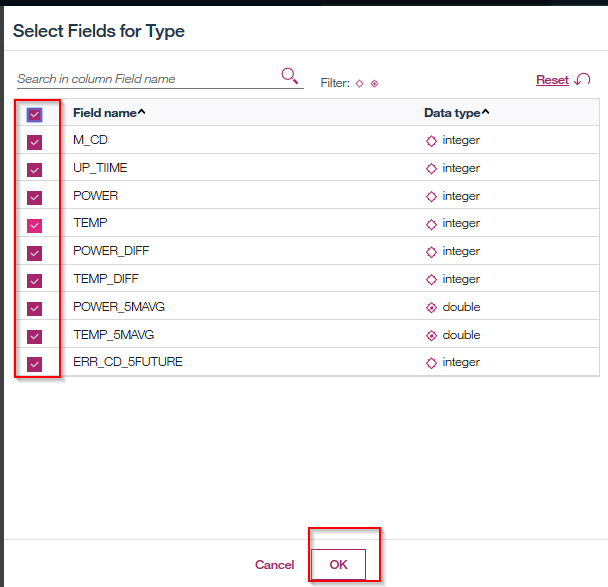
全ての列を選択し、OKをクリックします。
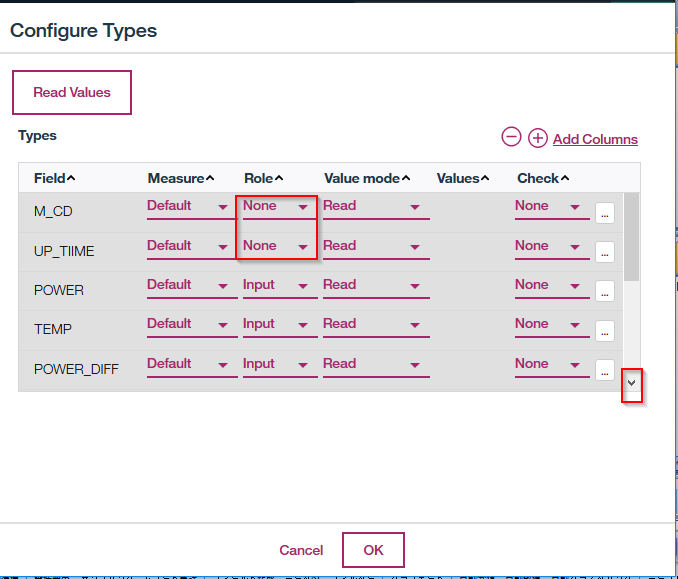
一番上の二つのM_CDとUP_TIMEのRoleをNoneに設定します。
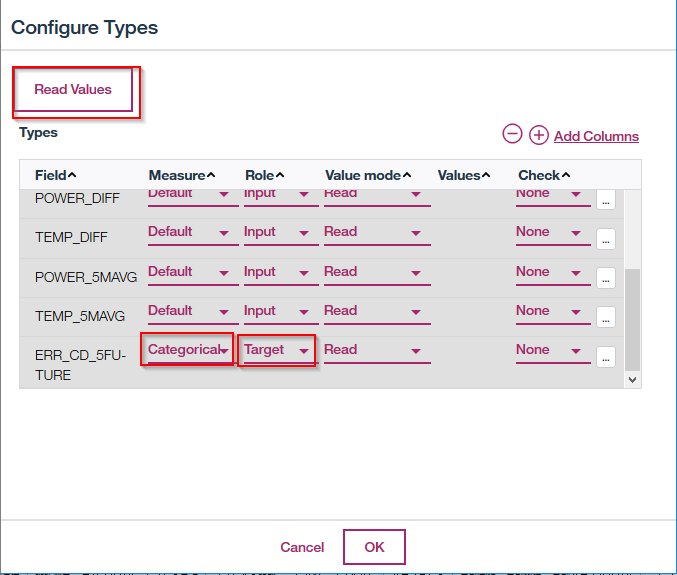
一番下の列のERR_CD_5FUTUREのMeasureを「Categorical」、Roleを「Target」に設定します。TEMPやPOWERをつかって、ERR_CD_5FUTUREを予測するという設定になります。Read Valuesをクリックします。
OKをクリックして閉じます。
C6. データの検査
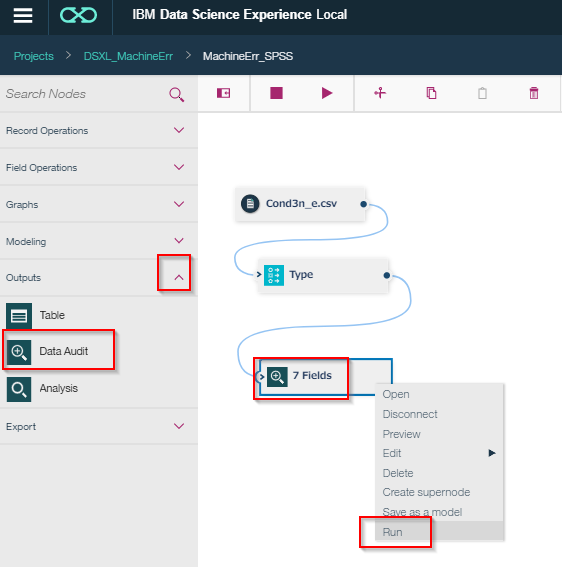
Nodesの一覧からOutputsのData Auditを選び、キャンバスにドラッグアンドドロップします。
そして、Typeノードと接続します。
次に右クリックをしてRunします。
実行がおわったら、view outputsのパレットを開き、Data Audit of [7 fields]をダブルクリックして内容を確認します。
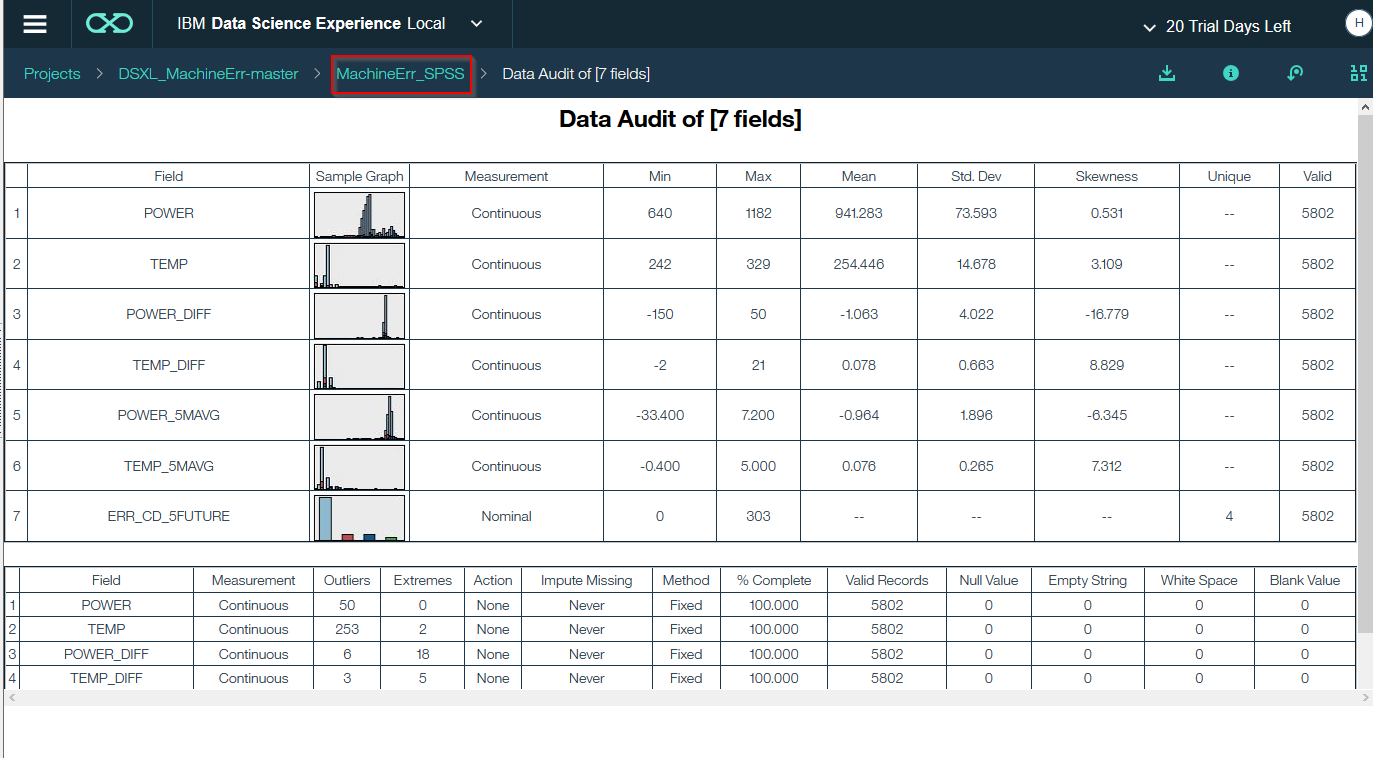
各列の最大値、平均、外れ値の数などの情報を一覧で確認することができます。
確認をしたらストリーム名をクリックしてキャンバスに戻ります。
C7. モデルの作成
Nodesの一覧からModelingのC5.0を選び、キャンバスにドラッグアンドドロップします。C5.0は予測分析のできる決定木アルゴリズムの一つです。
そして、Typeノードと接続します。
次に右クリックをしてRunします。
実行が終わるとモデルが作成されます。
右クリックでView Modelを選びます。
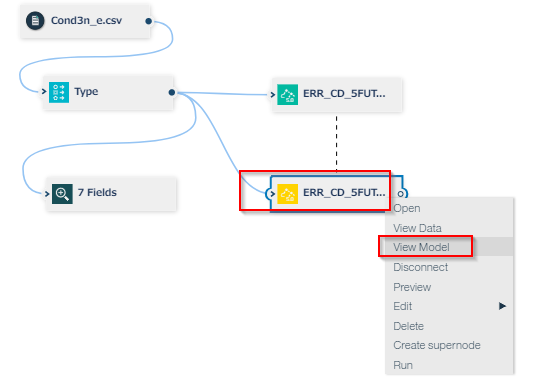
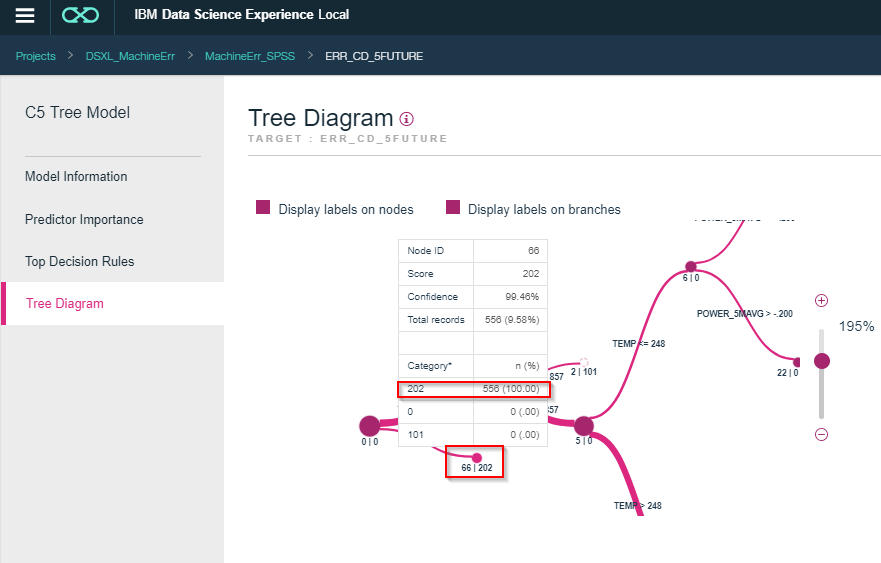
Predictor ImportanceをみるとTEMP、POWER_5MAVGが説明変数としての重要度が高いことがわかります。
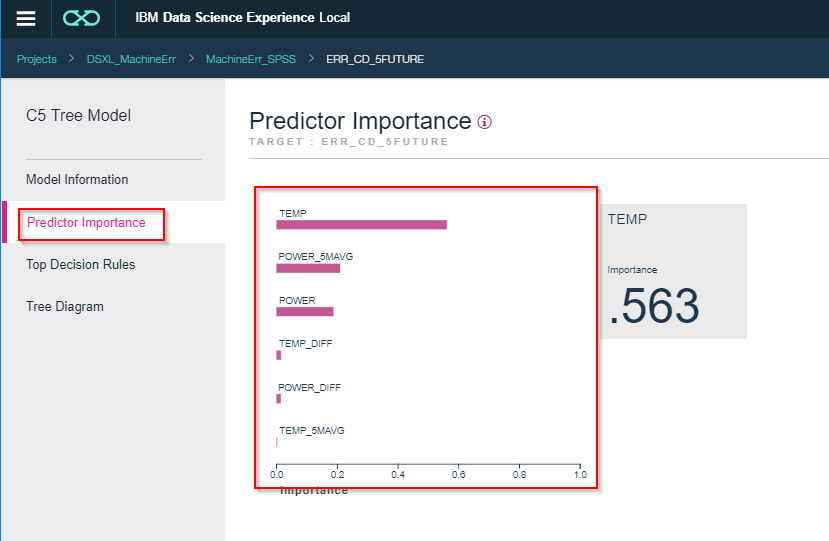
Tree DiagramをみるとTEMPが259度未満だと202のエラーと判定されることがわかります。また、TEMPが259度以上でもPOWERが857未満なら101のエラーと判定されることがわかります。
このようにどういう条件でどうなるかがすべて示されるのが決定木モデルの特徴です。Display labels on branchesにチェックをいれZoomを調整して参照してください。
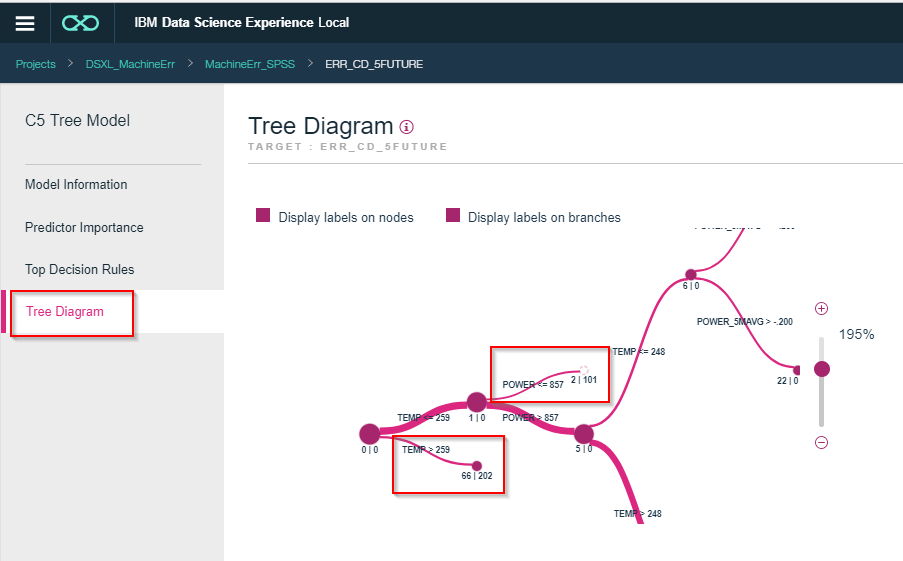
さらに202のノードにカーソルを合わせるとTEMPが259度未満の556件の全てが202のエラーであることがわかります。
C8. モデルの評価
ストリーム名をクリックし、キャンバスに戻ります。
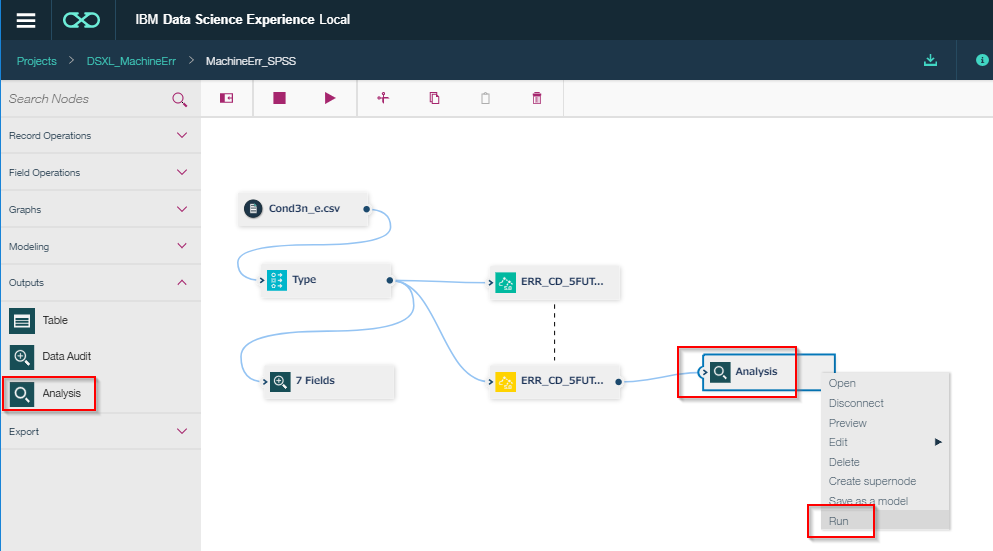
Nodesの一覧からOutputsのAnalysisを選び、キャンバスにドラッグアンドドロップします。
そして、モデルのナゲットノード(黄色)と接続します。
次に右クリックをしてRunします。
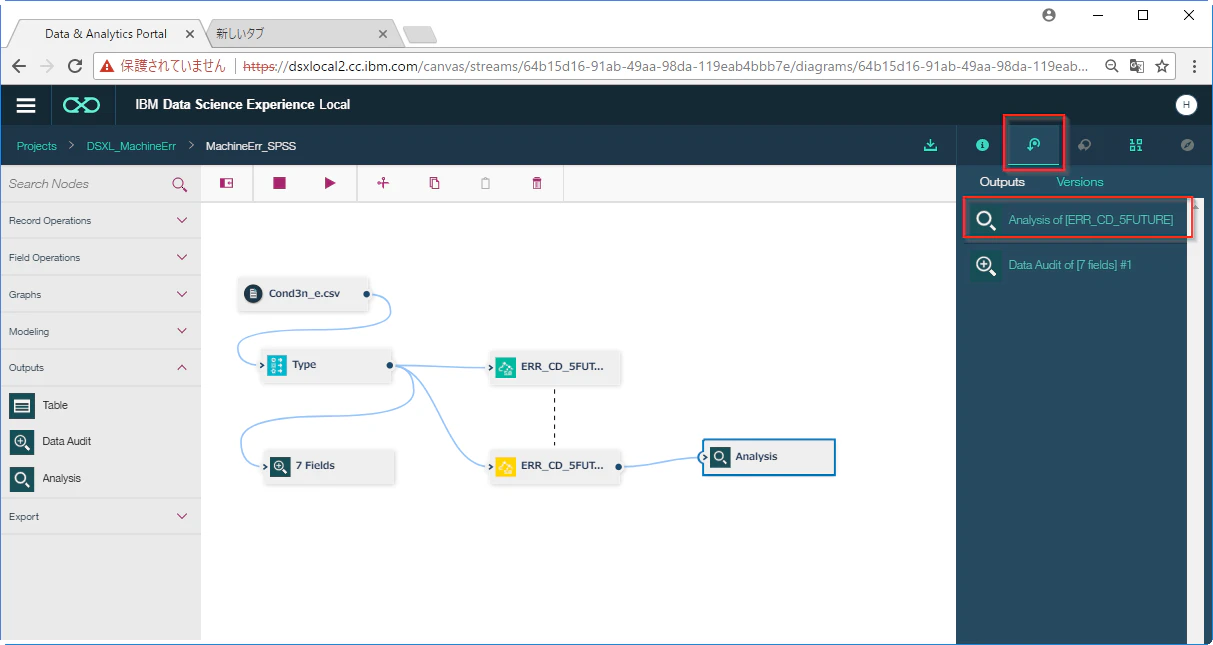
実行がおわったら、view outputsのパレットを開き、Analysis of [ERR_CD_5FUTURE]をダブルクリックして内容を確認します。
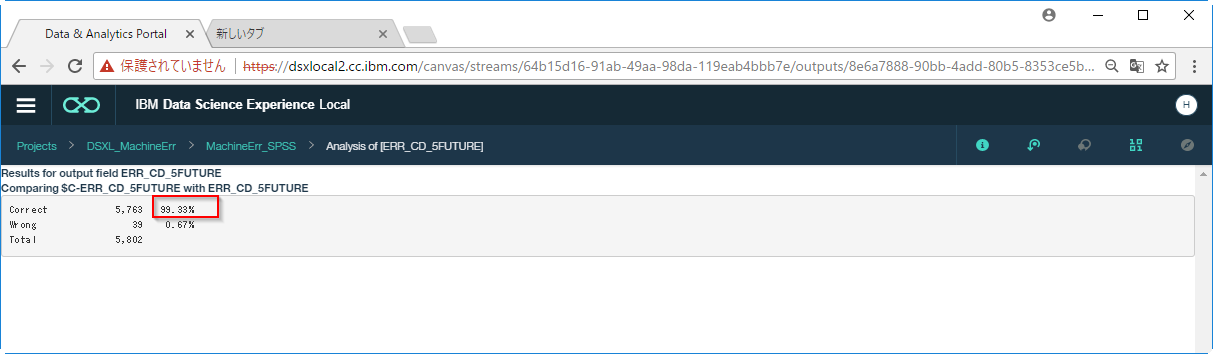
作成したモデルの精度は99.33%であることがわかります。
D. スコアリング
良いモデルができたので新しいセンサーデータをこのモデルにかけて将来のエラーを判定してみます。
D1. 新しいセンサーデータの入っているCond3n_e111.csvをファイルから選び、キャンバスに置きます。
そしてView Dataで中身を確認します。
ここにはERR_CD_5FUTUREの列はありません。POWERやTEMPから5期先のエラーを予測してみます。
ストリーム名をクリックして、キャンバスに戻ります。
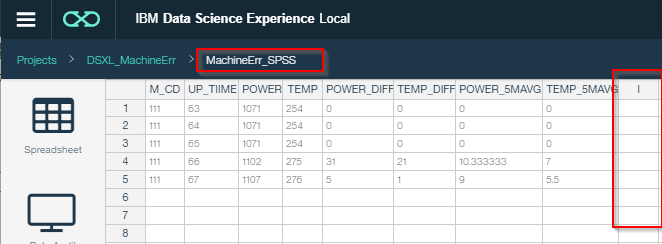
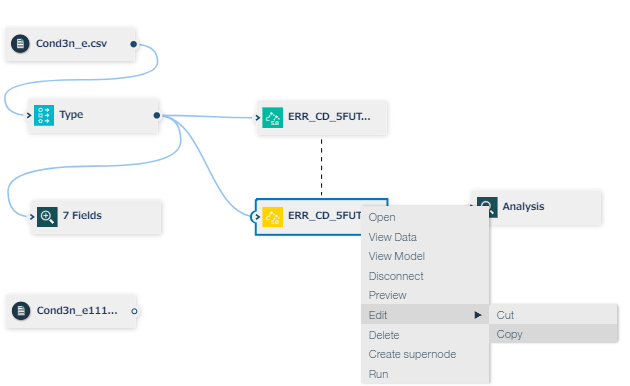
D2. モデルナゲットを右クリックしてコピーします。
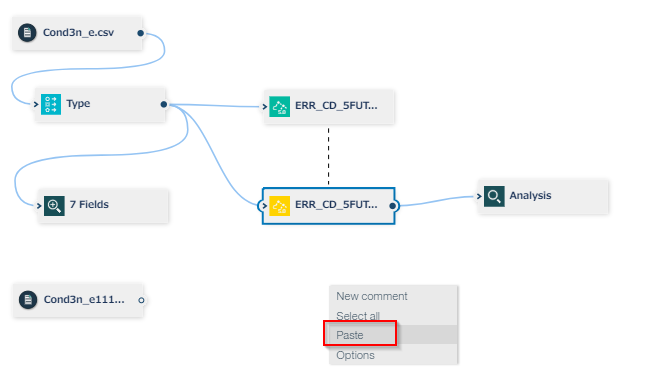
キャンバスの何もないところで右クリックして、Pasteします。
D3. Cond3n_e111.csvから貼り付けたモデルナゲットに接続し、さらびNodesの一覧からOutputsのTableを選び、キャンバスにドラッグアンドドロップします。
そして、モデルナゲットノードと接続します。
次に右クリックをしてRunします。
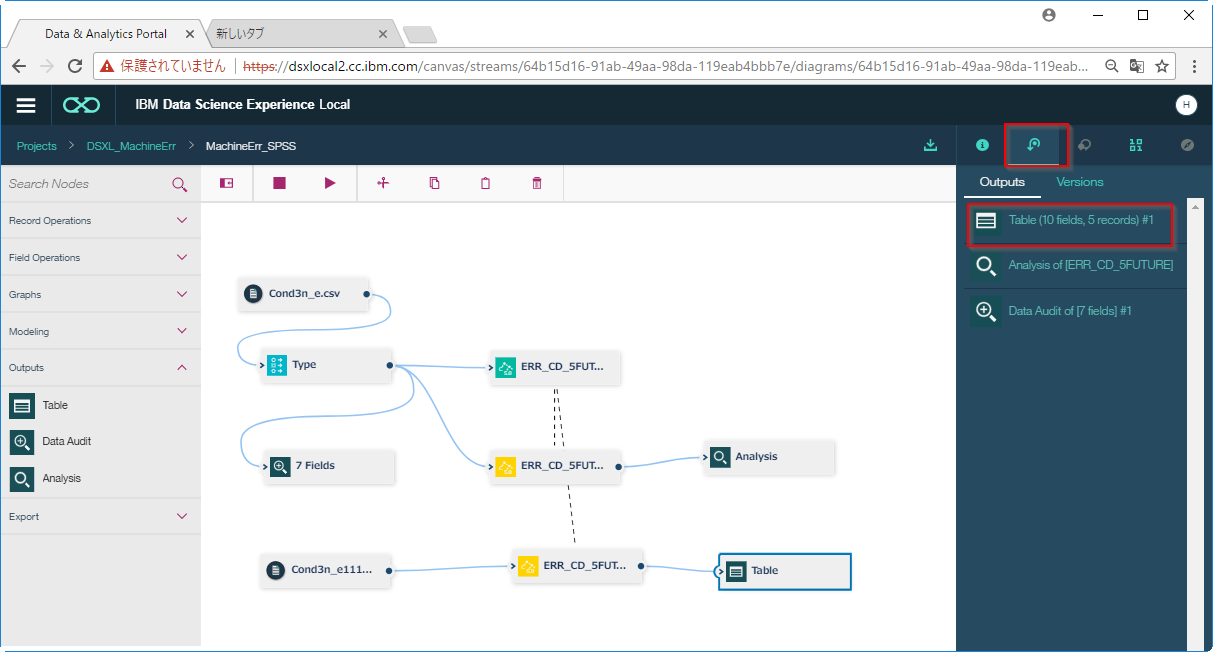
実行がおわったら、view outputsのパレットを開き、Table(10 fields,5 records)をダブルクリックして内容を確認します。
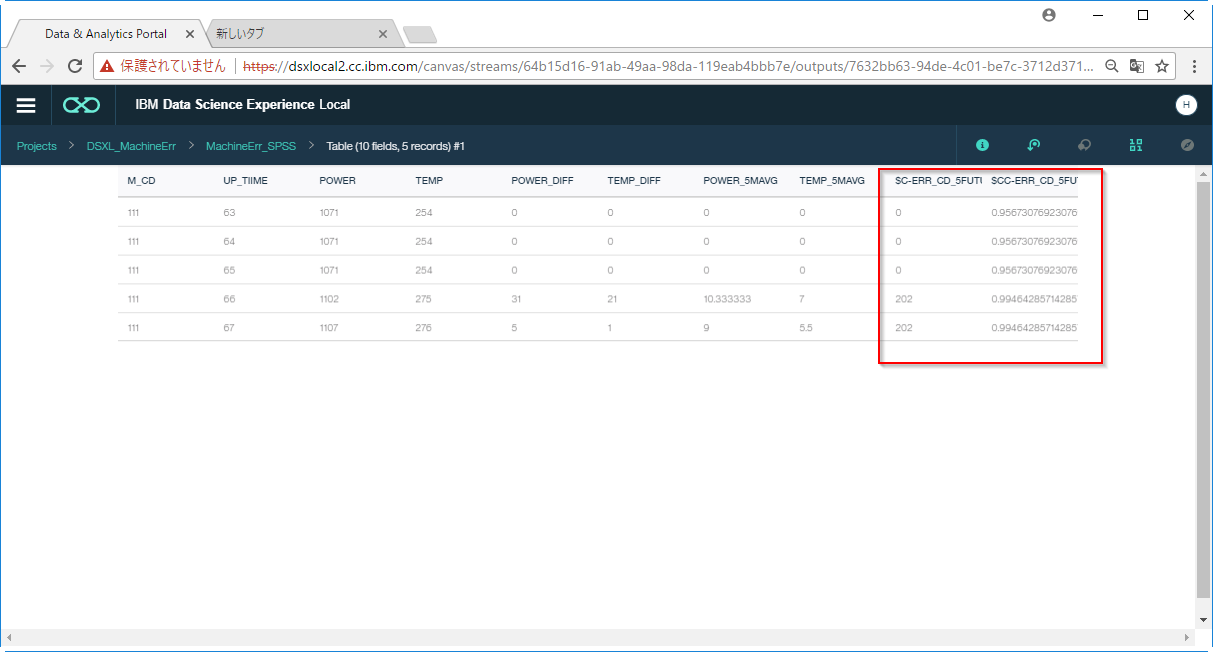
D4. 新たに$ERR_CD_5FUTUREと$CC-ERR_CD_5FUTUREの列が追加されています。
$ERR_CD_5FUTUREが予測結果です。$CC-ERR_CD_5FUTUREがその確度を示しています。このデータの場合、4レコード目でPOWERやTEMPに大きな変化があったときに将来エラーコード202が起きる可能性が9割以上あると予測をしています。
おわりに
現在のベータ版ではSPSS内でのみしかスコアリングができませんが、近い将来、センサーデータをためたCSVからバッチでスコアリングしたり、REST APIでアプリから予測したりすることができるようになることが期待されます。