以下の記事も参考にして、SPSS Modelerの日付関連のclem関数を使って、よく行う特徴量抽出を行ってみます。そしてその処理をPythonのpandasで書き換えてみます。
タイムスタンプ型については以下の記事で紹介しています。
https://qiita.com/kawada2017/items/0546580314f5b67408b1
代表的なものとして以下の加工処理を行っていきます。
- 日付データの読み込み
- 文字列や数値からの日付データ生成
- 今日の日付の取得
- 日付の年、月、日の分解
- 曜日判定
- 日付の差の計算
- 年と月の差の計算
- 日付の大小比較
- 日付の加算減算
以下のID付POSデータを対象に行います。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。今回はこの中のSDATEのみを使います。
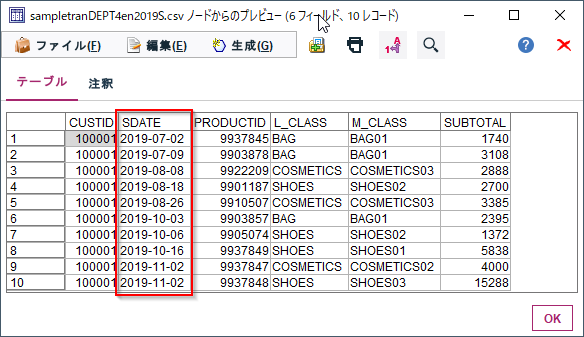
1m.① 日付データの読み込み Modeler版
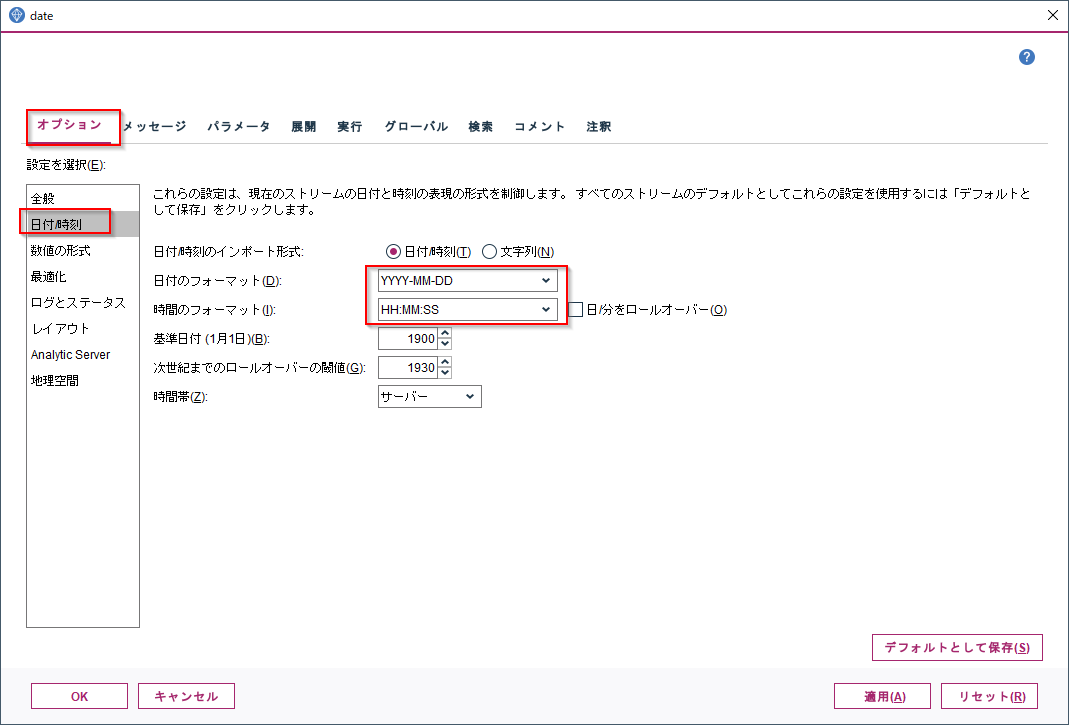
まずModelerの日付のフォーマットを確認しておきます。ストリームのオプションの「日付/時刻」の中にあります。YYYY-MM-DDがデフォルトです。
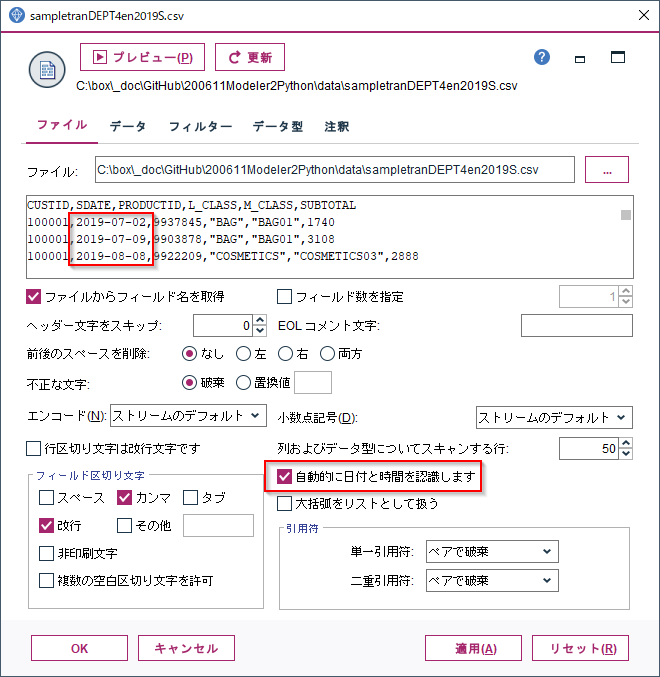
CSVデータを読み込んだ際に、デフォルトでは「自動的に日付と時間を認識します」のオプションが有効になっており、ストリームオプションで指定されていたYYYY-MM-DD形式で解釈できる文字列データは日付データとして読み込みます。
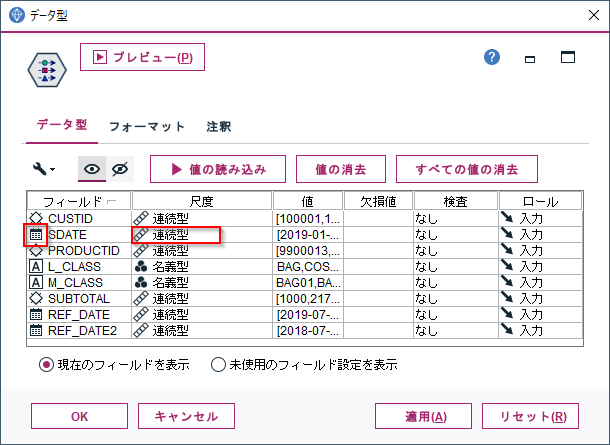
1p.① 日付データの読み込み pandas版
pythonには以下のような複数の日付型やTimestamp型があります。
- datetime.date
- datetime.datetime
- numpy.datetime64
- pandas._libs.tslibs.timestamps.Timestamp
#datetime.date
dtdt=datetime.date(2021, 6, 10)
print(dtdt)
print(type(dtdt))
#datetime.datetime
dtdtt=datetime.datetime(2021, 6, 10)
print(dtdtt)
print(type(dtdtt))
#numpy.datetime64
npdt=np.datetime64('2021-06-10')
print(npdt)
print(type(npdt))
#pandas._libs.tslibs.timestamps.Timestamp
pddt=pd.to_datetime('2021-06-10')
print(pddt)
print(type(pddt))
2021-06-10
<class 'datetime.date'>
2021-06-10 00:00:00
<class 'datetime.datetime'>
2021-06-10
<class 'numpy.datetime64'>
2021-06-10 00:00:00
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
この記事ではpandasのデータフレームを使うので、pandasのTimestamp型を使用していきます。ただし、加工方法によってはdatetimeを使う方が便利な場合もあるので組み合わせて使用していきます。
しかし、datetime.datetimeとnumpy.datetime64をいれると自動的にpandas._libs.tslibs.timestamps.Timestampに変換されていました。
dfdt.dtypesでみるといずれもdatetime64[ns]として表示されます。
datetime.dateはdatetime.dateのままでobjectとして認識されます。pandasにはdate型がなくTimestamp型しかないのでdate型は自動変換しないようです。
dfdt =pd.DataFrame({'datetimedate':[dtdt],
'datetimedatetime':[npdt],
'npdatetime':[npdt],
'pddatetime':[pddt]})
print(dfdt.dtypes)
print(type(dfdt['datetimedate'][0]))
print(type(dfdt['datetimedatetime'][0]))
print(type(dfdt['npdatetime'][0]))
print(type(dfdt['pddatetime'][0]))
datetimedate object
datetimedatetime datetime64[ns]
npdatetime datetime64[ns]
pddatetime datetime64[ns]
dtype: object
<class 'datetime.date'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
csvファイルからpandasに読むこむときにはデフォルトでは文字列型で読み込まれてしまいますが、パースして日付型として読み込むこともできます。
parse_datesに列を指定すると、その列が日付として解釈できれば日付型データとして読み込まれます。
#現在の日付
df = pd.read_csv('sampletranDEPT4en2019S.csv', parse_dates=['SDATE'])
print(df.dtypes)
print(type(df['SDATE'][0]))
以下ではSDATE列が、文字列としてではなく、datetime64[ns]型で読み込まれています。
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
dtype: object
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
- 参考
2m.② 文字列や数値からの日付データ生成 Modeler版
文字列や数値から日付型データを生成してみます。日付演算をするために文字列データから型変換をすることはよくあります。また年、月、日が別列に分かれて保存されている場合に、それらの列から日付型のデータを作成することもよくあります。
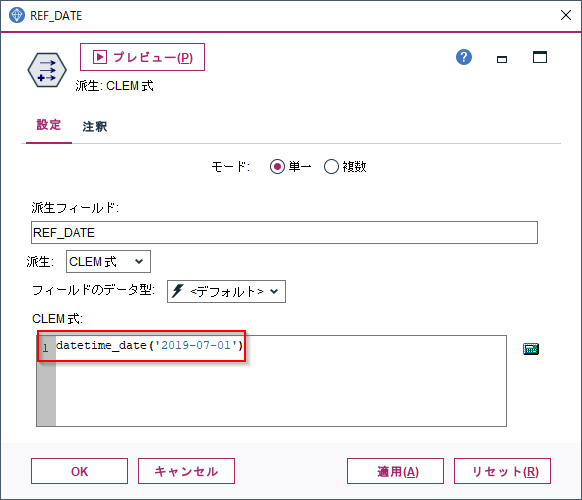
では、フィールド作成ノードで文字列から日付型データを生成してみます。datetime_dateという関数でストリームオプションで指定されていたYYYY-MM-DD形式で文字列を指定します。
datetime_date('2019-07-01')
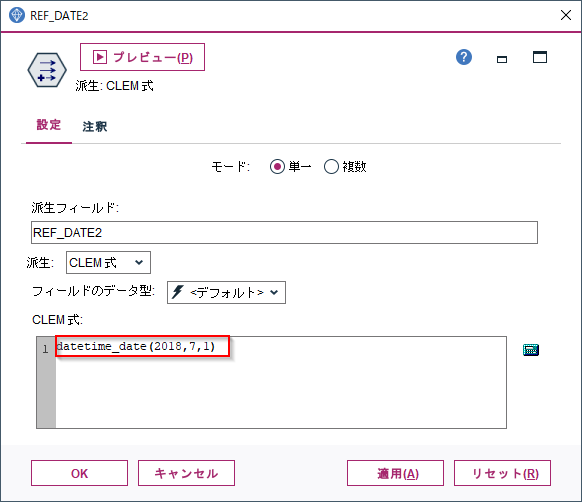
続いて、数値型データから日付型データを生成してみます。やはりdatetime_dateという関数を使いますが、年、月、日の数値をカンマ区切りで指定します。
datetime_date(2018,7,1)
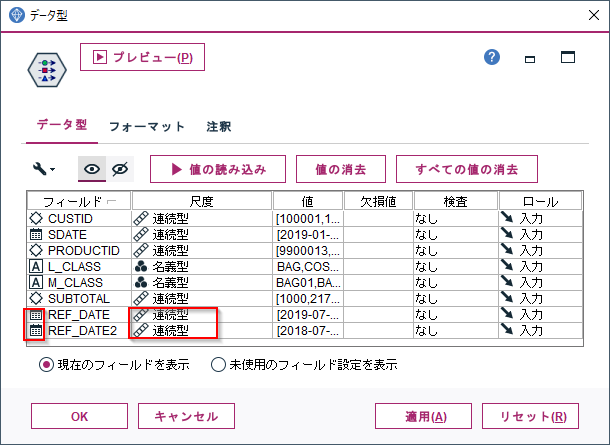
データ型ノードをつかって確認してみると、アイコンがカレンダーになり、尺度が連続型になっています。正しく日付型が生成されていることが確認できました。
2p.② 文字列や数値からの日付データ生成 pandas版
では、あらためて文字列から日付型データを生成してみます。pd.to_datetimeという関数でYYYY-MM-DD形式で文字列を指定します。YYYY-MM-DD形式以外のフォーマットの場合はformatstrのオプションでフォーマットを指定します。
df1['REF_DATE']=pd.to_datetime('2019-07-01')
続いて、数値型データから日付型データを生成してみます。時間情報のない日付データなのですが、datetime.dateだとobjectとして認識されてしまうので、それを避けるためにdatetime.dateではなくdatetime.datetimeで年、月、日を数値で指定してTimestamp型で生成します。
df1['REF_DATE2']=datetime.datetime(2018, 7, 1)
print(df1.dtypes)
REF_DATEもREF_DATE2もobjectとしてではなく、datetime64[ns]型で生成されていることがわかります。
SDATE datetime64[ns]
Power int64
Temperature int64
Pressure int64
Uptime int64
Status int64
Outcome int64
REF_DATE datetime64[ns]
REF_DATE2 datetime64[ns]
dtype: object
- 参考
3m.③ 現在の日付の取得 Modeler版
「現在の日付」を取得してみます。現在の日付はデータ生成日時の記録などによく使います。
フィールド作成ノードで「@TODAY」という関数を設定します。
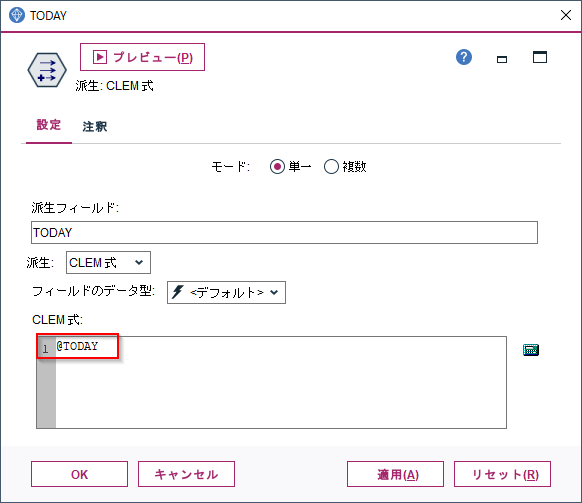
現在の日付が入ります。
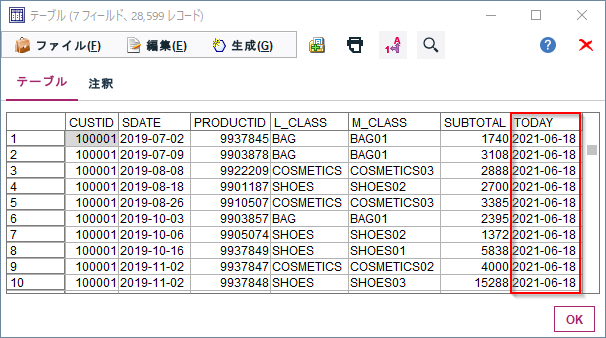
3p.③ 現在の日付の取得 pandas版
datetime.date.today()で現在の日付を取得し、pd.to_datetimeで型変換をします。
なお、np.datetime64('today')だと型変換不要で取得はできましたが、マニュアルにこの記述方法がなかったので、datetime.date.today()の方が堅いかと思います。
#現在の日付
df2['TODAY']=pd.to_datetime(datetime.date.today())
#以下だとobject型になる。
#df2['TODAY']=datetime.date.today()
#以下でも可能だったが、マニュアルにこの記述方法は見当たらなかった
#df2['TODAY']=np.datetime64('today')
print(df2.dtypes)
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
TODAY datetime64[ns]
dtype: object
- 参考
4m.④日付の年、月、日の分解 Modeler版
日付から年、月、日を取得してみます。時間毎のグループ化集計などのために抜き出すことがよくあります。
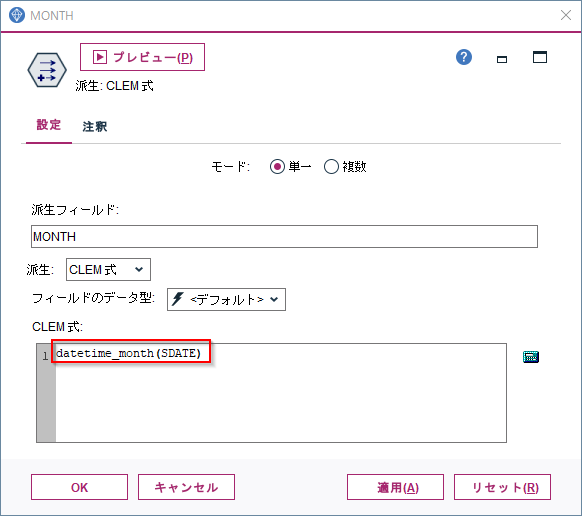
フィールド作成ノードでdatetime_year,datetime_month、datetime_dayという関数をつかって抜き出すことができます。ここではdatetime_monthで月を抜き出してみます。
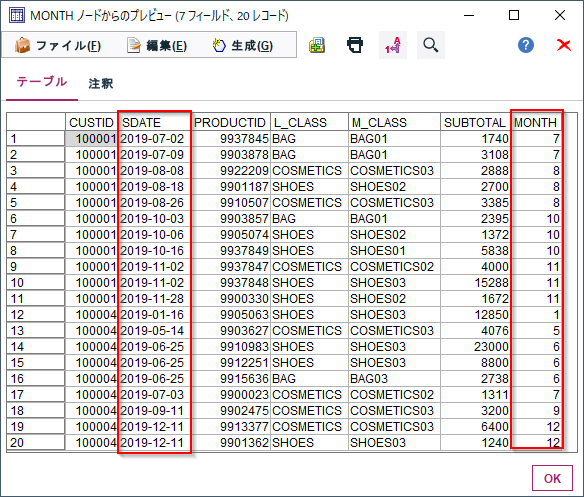
#4p.④日付の年、月、日の分解 pandas版
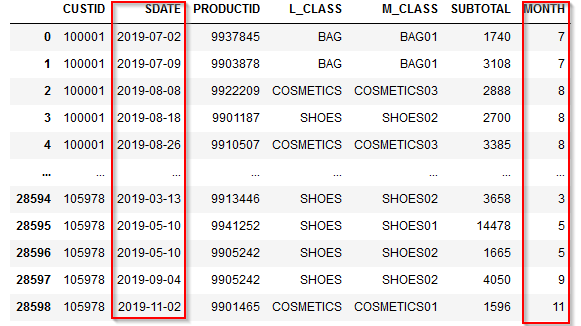
dtアクセサをつかって年year、月month、日dayの分解が可能です。dtアクセサはdayofyear(年初からの日数)やquarter(四半期)なども抜き出すことができます。
ここではdt.monthで月を抜き出します。結果はintで返ります。
df3['MONTH']=df3['SDATE'].dt.month
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
MONTH int64
dtype: object
- 参考
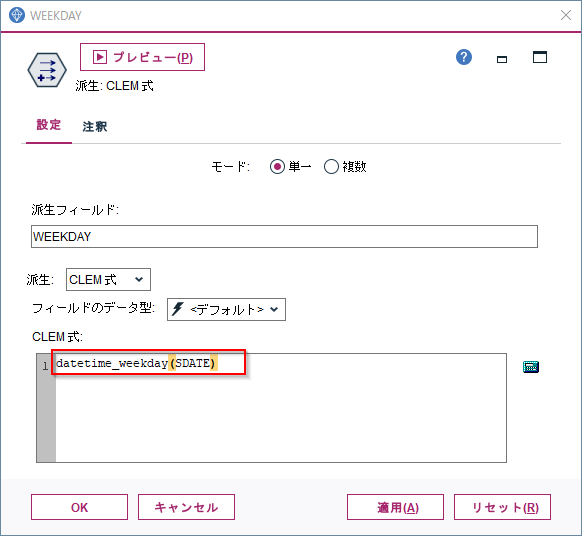
5m.⑤ 曜日判定 Modeler版
曜日によって購買傾向が変わることはよくありますので、曜日は重要な特徴量になります。
フィールド作成ノードでdatetime_weekdayという関数をつかって抜き出すことができます。1(日曜)~7(土曜) の範囲の整数として戻ります。
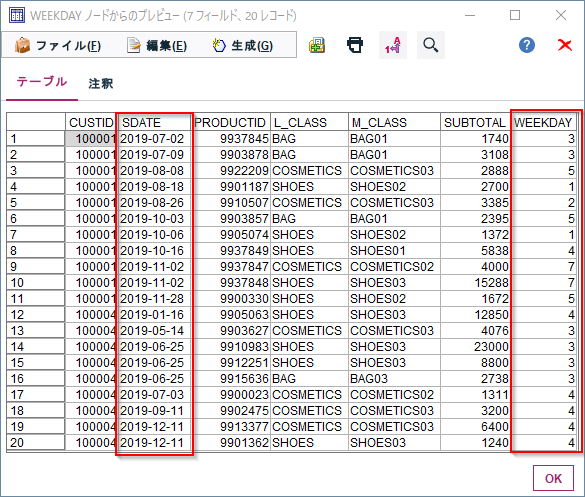
5p.⑤ 曜日判定 pandas版
dtアクセサをつかってweekdayでをつかって抜き出すことができます。0(月曜)~6(日曜)の範囲の整数として戻ります。Modelerと範囲が異なりますので、Modelerと同じ範囲にしたい場合は以下のようにシフトさせる必要があります。
#曜日判定。0(月曜)~6(日曜)
df4['WEEKDAY']=df2['SDATE'].dt.weekday
# Modelerにあわせて1(日曜)~7(土曜) の範囲の整数に変換。日曜は6+2=8になるので7.1で割った余り0.9を四捨五入して1にする
df4['WEEKDAYSPSS']=round((df2['SDATE'].dt.weekday+2)%7.1).astype(int)
print(df4.dtypes)
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
WEEKDAY int64
WEEKDAYSPSS int32
dtype: object
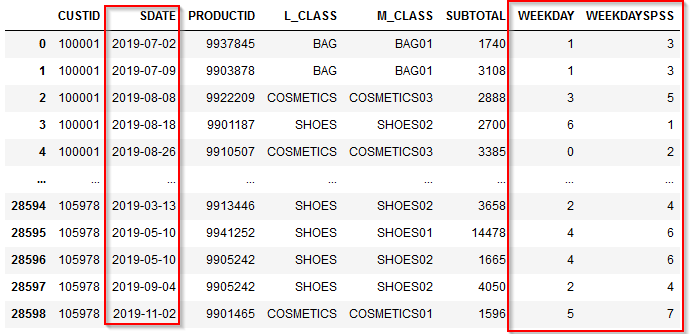
6m.⑥ 日付の差の計算 Modeler版
日付同士の差を計算してみます。購買間隔やイベント日からの日数など、日付差は重要な特徴量になりえます。
フィールド作成ノードでdate_days_differenceで日数差を取ります。
以下の例だと売上日(SDATE)- 基準日付(REF_DATE)の日数を返します。基準日付(REF_DATE)>売上日(SDATE)であればマイナスの値が返ります。
date_days_difference(REF_DATE,SDATE)
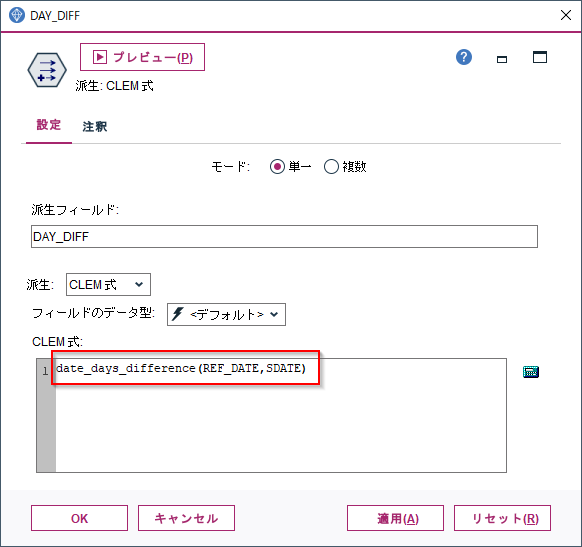
2019-07-01という基準日と売上日(SDATE)の差がDAY_DIFFに入っています。
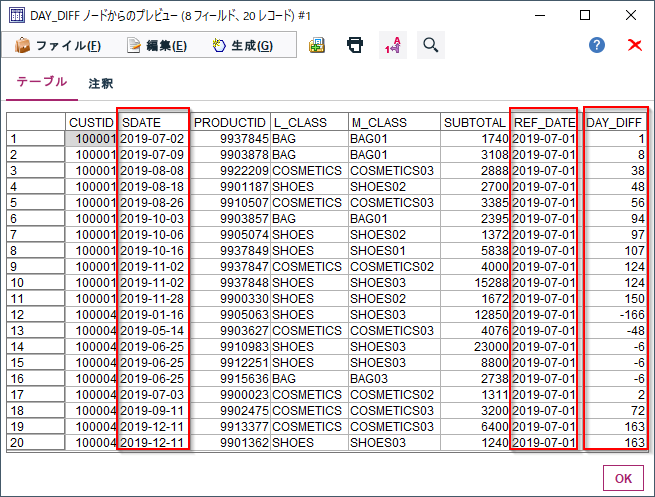
6p.⑥ 日付の差の計算 pandas版
まず、以下のように単純に日付の入った列の引算を行います。
df5["DAY_DIFF_TD"]=(df5["SDATE"]-df5["REF_DATE"])
これは整数ではなく、pandas._libs.tslibs.timedeltas.Timedeltaという特殊な型(df5.dtypesの結果だとtimedelta64[ns])で値を返します。
日付演算をする場合はこのままでよいのですが、整数として扱う場合にはdt.daysで変換します。
df5["DAY_DIFF_TD"]=(df5["SDATE"]-df5["REF_DATE"])
print(type((df5["DAY_DIFF_TD"])[0]))
df5["DAY_DIFF"]=(df5["SDATE"]-df5["REF_DATE"]).dt.days
#以下でも整数化は可能。
#df5["DAY_DIFF"]=((df5["SDATE"]-df5["REF_DATE"]) /np.timedelta64(1,'D')).astype('int')
print(df5.dtypes)
<class 'pandas._libs.tslibs.timedeltas.Timedelta'>
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
REF_DATE datetime64[ns]
DAY_DIFF_TD timedelta64[ns]
DAY_DIFF int64
dtype: object
DAY_DIFF_TDとDAY_DIFF秒の結果は同じですが、DAY_DIFF_TDにはtimedelta64[ns]型で格納され、DAY_DIFF秒は整数型になっています。
pandas.Series.dt.days — pandas 1.2.4 documentation
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.dt.days.html
7m.⑦ 年月の差の計算 Modeler版
年と月の差を計算してみます。イベントからの年数、月数や年齢など、年や月の差は重要な特徴量になりえます。
date_years_differenceやdate_months_differenceで差をとることはできるのですが、浮動小数点誤差が発生しうるので、整数化してから計算することがお勧めです。
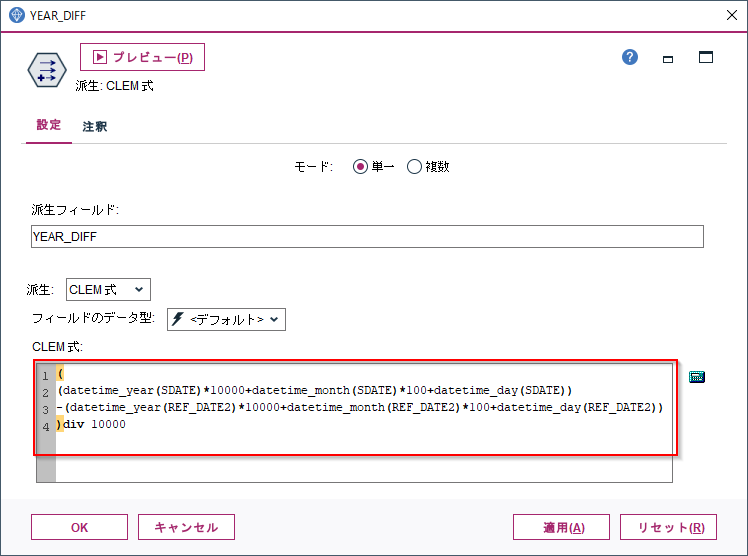
2019-07-01であれば、年に10000をかけ、月に100をかけて20190701のような10進の整数にしてから差を計算して、最後に10000で割った商で年の位のみを得ます。
以下の例だと売上日(SDATE)- 基準日付(REF_DATE)の年数を返します。
(
(datetime_year(SDATE)*10000+datetime_month(SDATE)*100+datetime_day(SDATE))
-(datetime_year(REF_DATE2)*10000+datetime_month(REF_DATE2)*100+datetime_day(REF_DATE2))
)div 10000
月の計算も同じように行えます。
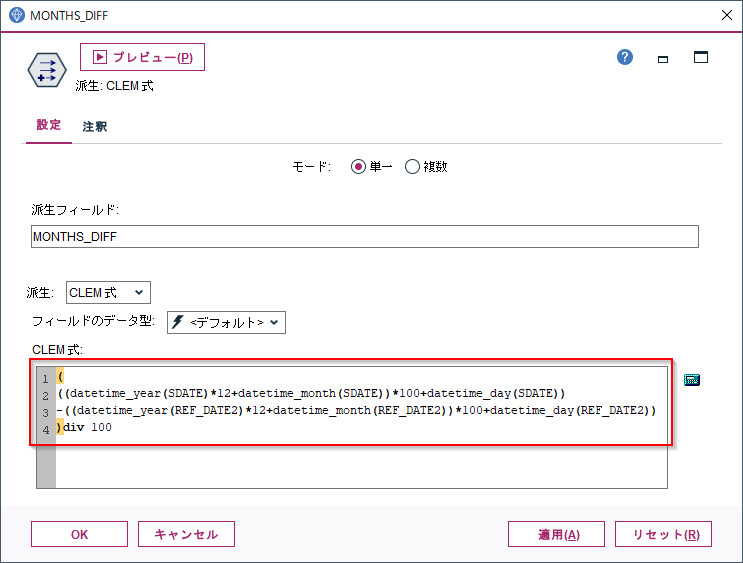
まず月の単位にするために年に12をかけ、それから100をかけます。2019-07-01であれば、(2019*12+07)*100+01で10進の整数にしてから差を計算して、最後に100で割った商で月の位のみを得ます。
(
((datetime_year(SDATE)*12+datetime_month(SDATE))*100+datetime_day(SDATE))
-((datetime_year(REF_DATE2)*12+datetime_month(REF_DATE2))*100+datetime_day(REF_DATE2))
)div 100
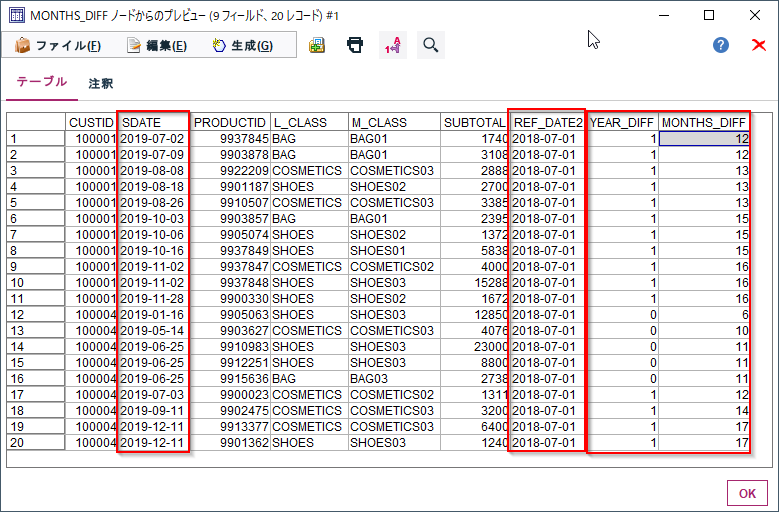
2019-07-01という基準日と売上日(SDATE)の年差がYEAR_DIFF、月差がMONTHS_DIFFに入っています。
7p.⑦ 年月の差の計算 pandas版
Modeler同様に浮動小数点誤差を避けるために10進の整数として計算します。
年の差については、まず以下で10進の整数に変換します。
df6["REF_DATE2"].dt.strftime('%Y%m%d').astype('int')
とすると、2019-07-01であれば、20190701のような10進の整数になります。この後、差をとってから//10000で年の位の商を得ます。
月の差についても、まず以下で10進の整数に変換します。
(df6["REF_DATE2"].dt.year*12*100+df6["REF_DATE2"].dt.strftime('%m%d').astype('int')
とすると、2019-07-01であれば、(2019*12*100)+0701で10進の整数になります。この後、差をとってから//100で月の位の商を得ます。
#10進の整数化してから引算
df6["YEAR_DIFF"]=(df6["SDATE"].dt.strftime('%Y%m%d').astype('int')-df6["REF_DATE2"].dt.strftime('%Y%m%d').astype('int'))//10000
df6["MONTHS_DIFF"]=((df6["SDATE"].dt.year*12*100+df6["SDATE"].dt.strftime('%m%d').astype('int'))
-(df6["REF_DATE2"].dt.year*12*100+df6["REF_DATE2"].dt.strftime('%m%d').astype('int')))//100
#以下は1年未満でも1年になってしまう。
#df6["YEAR_DIFF"]=df6["SDATE"].dt.year - df6["REF_DATE2"].dt.year
#以下は浮動小数点誤差が発生する
#df6["YEAR_DIFF"]=(df6["SDATE] - df6["REF_DATE2"]).astype('<m8[Y]')
#df6["YEAR_DIFF"]=((df6["SDATE"] - df6["REF_DATE2"])/np.timedelta64(1,'Y')).astype('int')
#df6["MONTHS_DIFF"]=((df6["SDATE"] - df6["REF_DATE2"])/np.timedelta64(1,'M')).astype('int')
print(df6.dtypes)
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
REF_DATE2 datetime64[ns]
YEAR_DIFF int32
MONTHS_DIFF int64
dtype: object
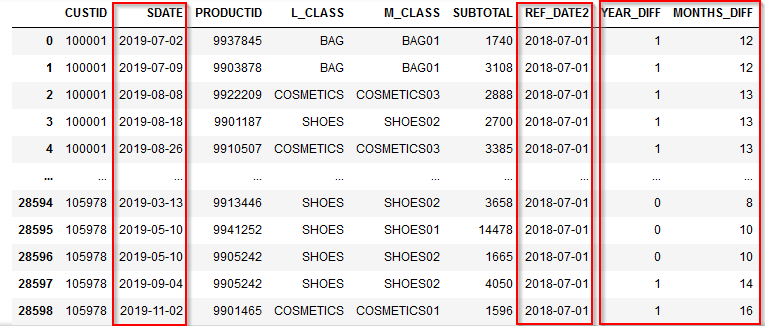
2019-07-01という基準日と売上日(SDATE)の年差がYEAR_DIFF、月差がMONTHS_DIFFに入っています。
pandas.Series.dt.days — pandas 1.2.4 documentation
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.dt.days.html
8m.⑧日付の大小比較 Modeler版
日付の大小比較をしてみます。イベント日以降の購入かというようなフラグの特徴量が作れます。
フィールド作成ノードで派生:フラグ型に設定し、条件に以下を入力します。基準日より後の購入日ならフラグを立てるという意味です。
SDATE>REF_DATE
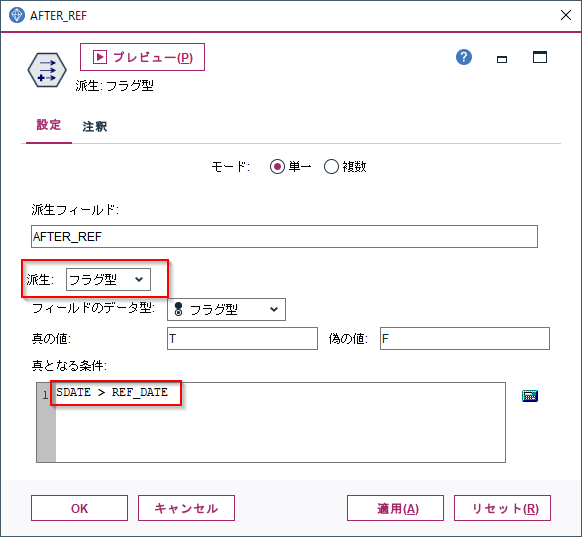
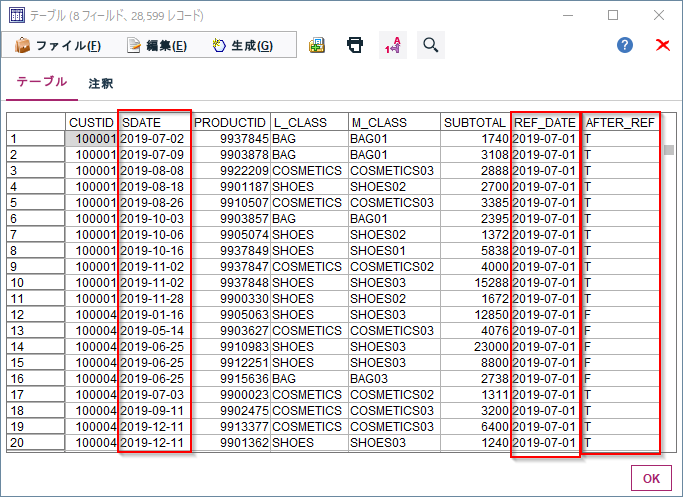
2019-07-01という基準日以降の売上の場合にAFTER_REFにTが立っています。
8p.⑧ 日付の大小比較 pandas版
以下のように単純に日付の比較式を代入します。結果はbool型で返ります。
df7["AFTER_REF"]=(df7["SDATE"]>df7["REF_DATE"])
print(df7.dtypes)```
```output:結果
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
REF_DATE datetime64[ns]
AFTER_REF bool
dtype: object
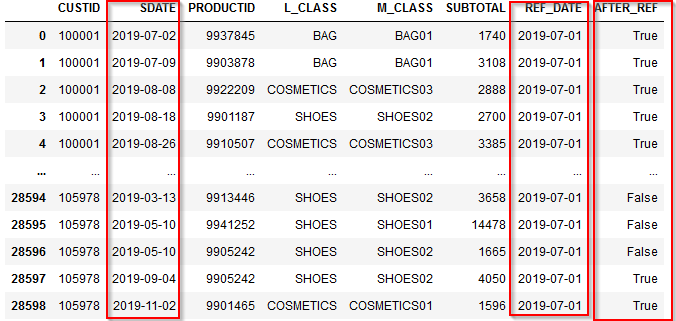
2019-07-01という基準日付以降の売上の場合にAFTER_REFにTrueが立っています。
9m.⑨ 日付の加算減算 Modeler版
日付に加算減算を計算してみます。購入から100日目というような計算です。初回購入から100日以内にリピート購入があった顧客を調べたいときなどに使います。
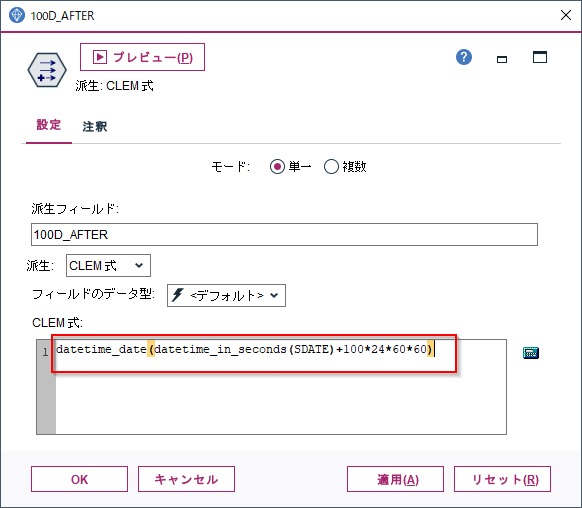
フィールド作成ノードでdatetime_in_secondsとdatetime_dateという関数をつかって、日付の100日後を生成してみます。
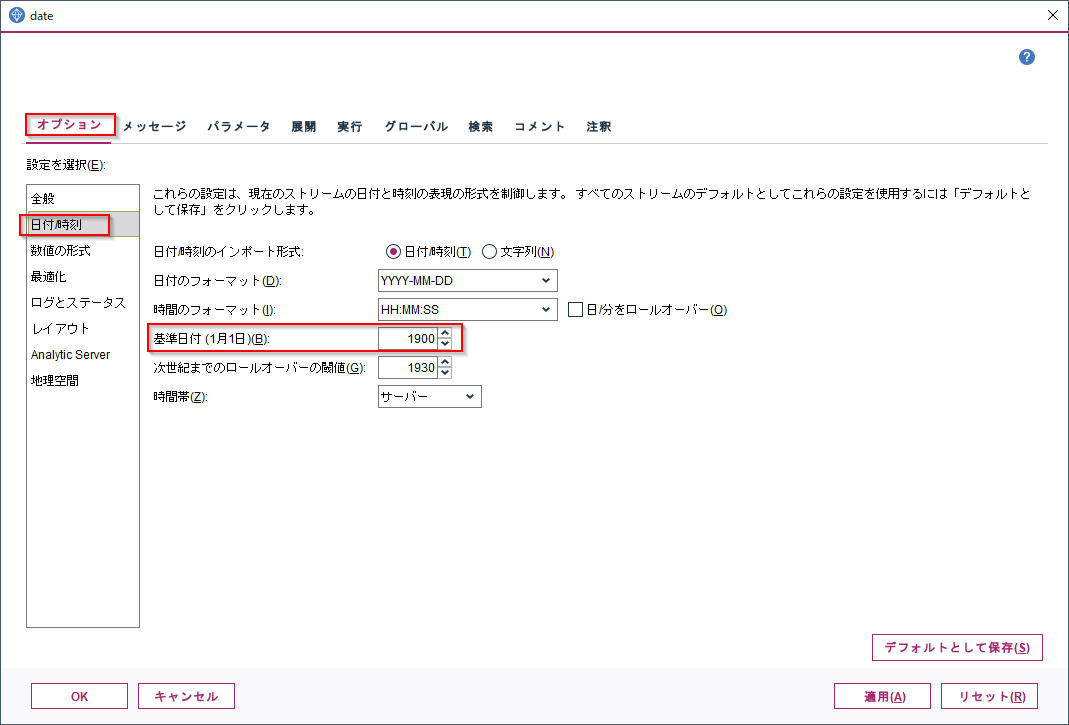
まずdatetime_in_seconds(SDATE)で日付を基準日からの秒数に変換します。
基準日はデフォルトだと1900-01-01です。
次にこの秒数に100日分の秒数を足します。100日*24時間*60分*60秒です。
そしてこの秒数をdatetime_dateで日付型に変換しなおします。
つまり式としては以下になります。
datetime_date(datetime_in_seconds(SDATE)+100*24*60*60)
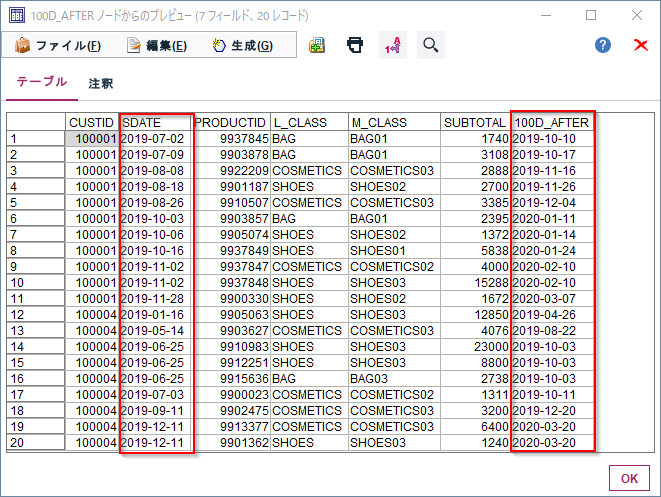
日付(SDATE)の100日後の日付が100D_AFTERに生成されました。
9p.⑨ 日付の加算減算 pandas版
datetime.timedeltaをつかって量と単位を指定して加算減算をします。以下の例は日付daysを100個分足す、つまり100日分足すという意味になります。'days'の部分を変えると時間'hours'、分'minutes'、秒'seconds'など別の単位でも加算減算が行えます。
df8['100D_AFTER']=df8["SDATE"]+ datetime.timedelta(days=100)
#以下でも同じ結果が得られる
#df8['100D_AFTER']=df8["SDATE"]+ np.timedelta64(100,'D')
print(df8.dtypes)
CUSTID int64
SDATE datetime64[ns]
PRODUCTID int64
L_CLASS object
M_CLASS object
SUBTOTAL int64
100D_AFTER datetime64[ns]
dtype: object
日付(SDATE)の100日後の日付が100D_AFTERに生成されました。
10. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/datetime/date.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/datetime/date.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.2.2
Windows 10 64bit
Python 3.8.5
pandas 1.0.5
numpy 1.19.2