SPSS Modelerの拡張モデルノードを使って、LightGBMを使ってモデリングとスコアリングを行いました。
■環境
Modeler 18.2.2
python 3.7.7(非Anaconda)
lightgbm 3.1.1
Windows 10
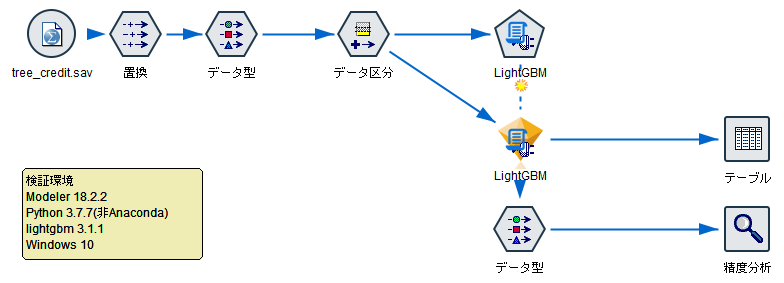
サンプルストリーム
事前作業
以下の@1000akiさんの記事を参考にSPSSの拡張ノードでPythonを利用できるようにしておきます。
pythonを導入して、options.cfgの設定まで行っておきます。
LightGBMの導入
個人フォルダに作っている場合は普通にpip installできますが、上の手順はAll Userで利用できるPythonを"C:\Program Files\Python37"に導入しているので、管理者権限でpip installを使う必要があります。
管理者権限でコマンドプロンプトを起動します。
cd "C:\Program Files\Python37"
python -m pip install lightgbm
python -m pip list
C:\Program Files\Python37>python -m pip install lightgbm
Collecting lightgbm
Using cached https://files.pythonhosted.org/packages/80/28/fecd02e7856e36afcdc71ee968b1b3859b3bc784e042991d5520e4d7be2c/lightgbm-3.1.1-py2.py3-none-win_amd64.whl
Collecting wheel (from lightgbm)
Using cached https://files.pythonhosted.org/packages/65/63/39d04c74222770ed1589c0eaba06c05891801219272420b40311cd60c880/wheel-0.36.2-py2.py3-none-any.whl
Requirement already satisfied: numpy in c:\program files\python37\lib\site-packages (from lightgbm) (1.20.1)
Collecting scikit-learn!=0.22.0 (from lightgbm)
Downloading https://files.pythonhosted.org/packages/16/33/e0b09b2810e355b667cd3b28850c36963735a77a431efdb2c2ca1c1c5cea/scikit_learn-0.24.1-cp37-cp37m-win_amd64.whl (6.8MB)
|████████████████████████████████| 6.8MB 3.3MB/s
Collecting scipy (from lightgbm)
Downloading https://files.pythonhosted.org/packages/06/c8/78d94bf4d039fd1ef878363491f2925e29b7ccfafa3dcd9dddfaeb0f4608/scipy-1.6.1-cp37-cp37m-win_amd64.whl (32.6MB)
|████████████████████████████████| 32.6MB 3.2MB/s
Collecting joblib>=0.11 (from scikit-learn!=0.22.0->lightgbm)
Downloading https://files.pythonhosted.org/packages/55/85/70c6602b078bd9e6f3da4f467047e906525c355a4dacd4f71b97a35d9897/joblib-1.0.1-py3-none-any.whl (303kB)
|████████████████████████████████| 307kB 3.3MB/s
Collecting threadpoolctl>=2.0.0 (from scikit-learn!=0.22.0->lightgbm)
Using cached https://files.pythonhosted.org/packages/f7/12/ec3f2e203afa394a149911729357aa48affc59c20e2c1c8297a60f33f133/threadpoolctl-2.1.0-py3-none-any.whl
Installing collected packages: wheel, joblib, scipy, threadpoolctl, scikit-learn, lightgbm
WARNING: The script wheel.exe is installed in 'C:\Program Files\Python37\Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed joblib-1.0.1 lightgbm-3.1.1 scikit-learn-0.24.1 scipy-1.6.1 threadpoolctl-2.1.0 wheel-0.36.2
WARNING: You are using pip version 19.2.3, however version 21.0.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
C:\Program Files\Python37>python -m pip list
Package Version
--------------- -------
joblib 1.0.1
lightgbm 3.1.1
numpy 1.20.1
pandas 1.2.3
pip 19.2.3
python-dateutil 2.8.1
pytz 2021.1
scikit-learn 0.24.1
scipy 1.6.1
setuptools 41.2.0
six 1.15.0
threadpoolctl 2.1.0
wheel 0.36.2
WARNING: You are using pip version 19.2.3, however version 21.0.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
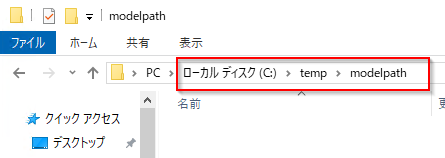
モデルを保存するパスを作っておきます。
モデルを保存するパスを作っておきます。
#ストリームの作成
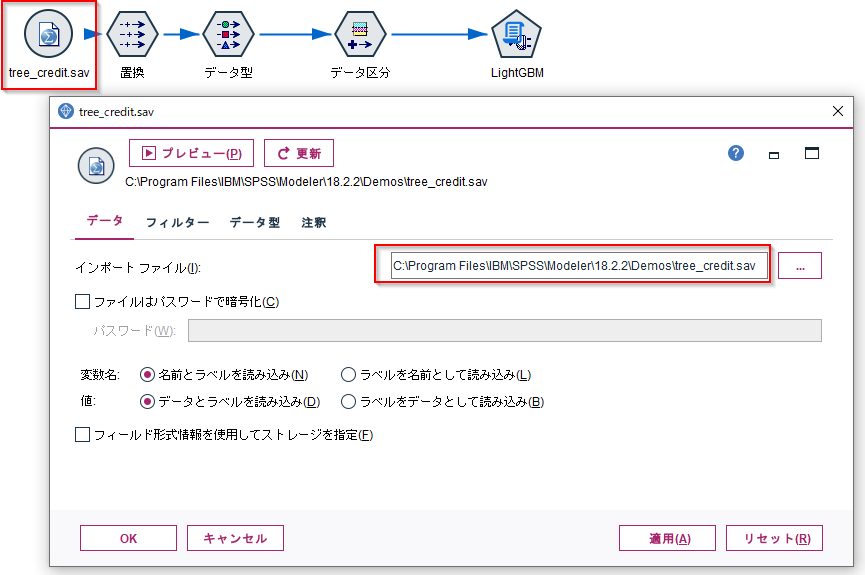
Demosフォルダにあるtree_credit.savを使います。
置換ノードで全列を整数型にしておきます。
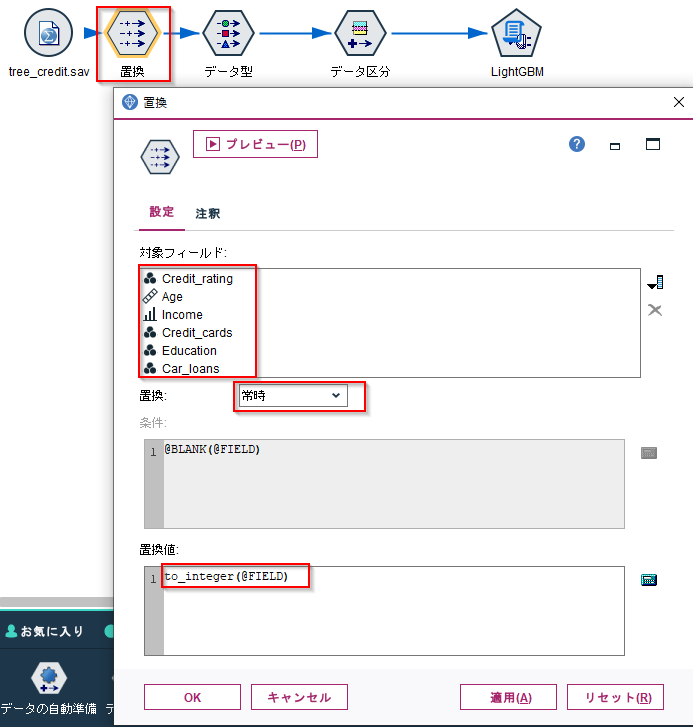
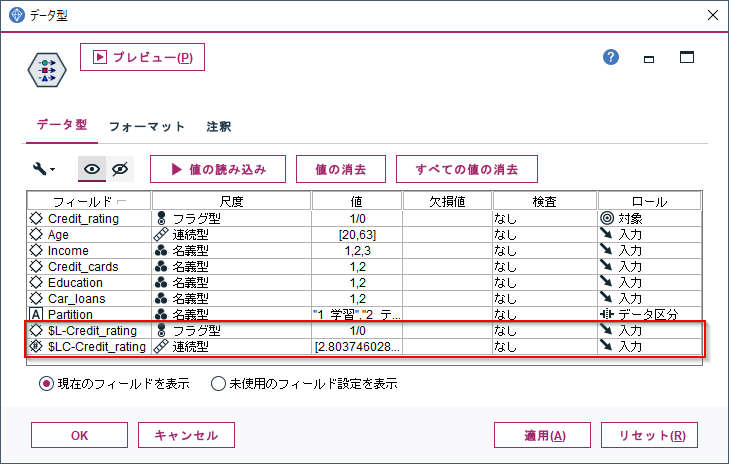
データ型ノードでCredit_ratingをフラグ型にして、ロールを対象にします。
IncomeからCar_loansは名義型にしておきます。
AgeやIncomeなどからCredit_ratingを予測するモデルを作ります。
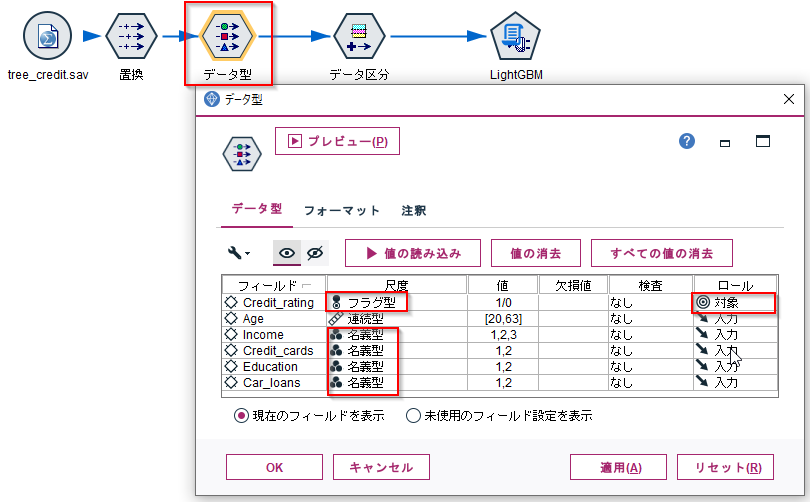
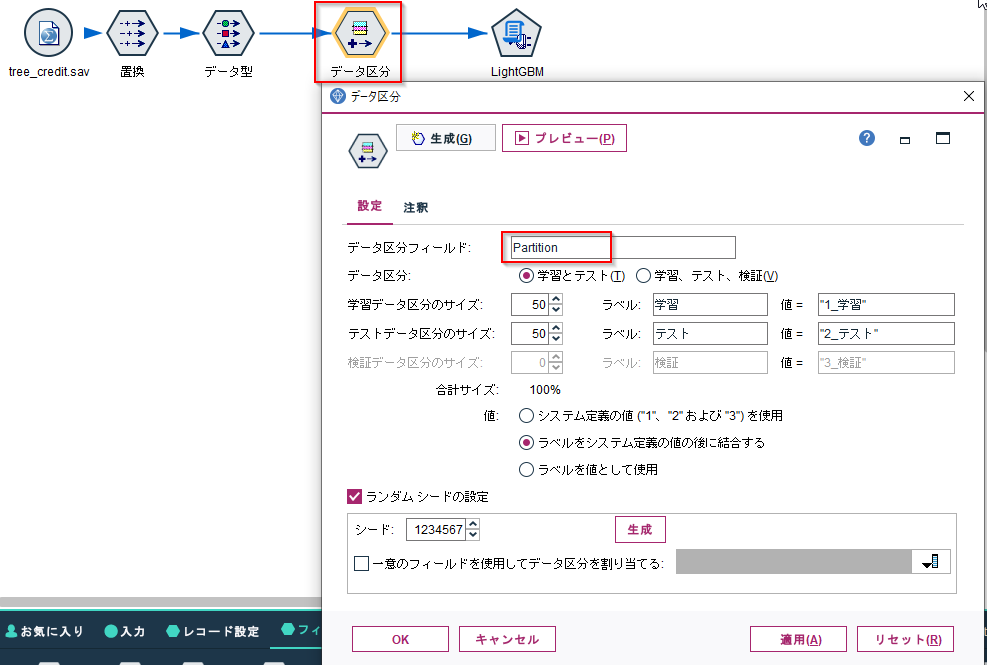
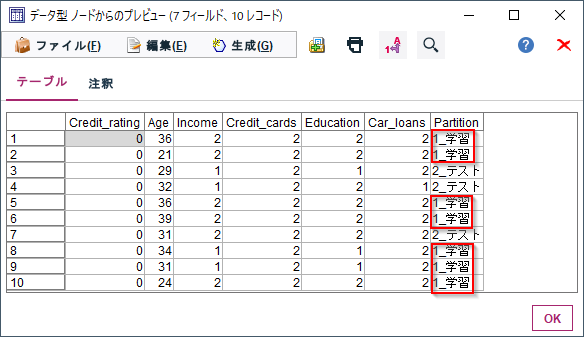
データ区分ノードで学習データとテストデータに分けます。
なお、Python連携でつかうPysparkが日本語列をうまく扱えないのでフィールド名を"Partition"に変更しています。
拡張モデルノードでPython for Sparkを選びます。
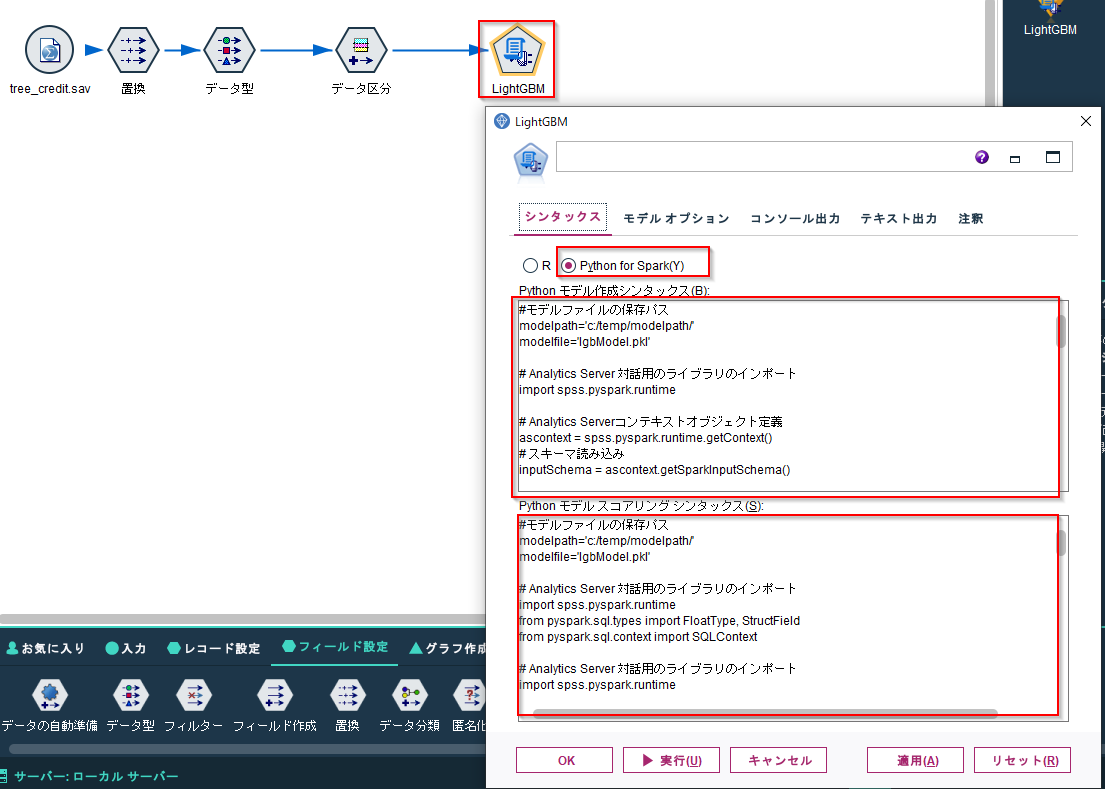
以下のlightGBMのモデリングとスコアリングのスクリプトを入力します。
#モデルファイルの保存パス
modelpath='c:/temp/modelpath/'
modelfile='lgbModel.pkl'
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
# スキーマ読み込み
inputSchema = ascontext.getSparkInputSchema()
#Roleから説明変数名と目的変数名を取得
predictors =[]
for col in inputSchema:
print(col.metadata['role'])
#説明変数列の取得
if col.metadata['role']=='input':
predictors.append(col.name)
#目的変数列の取得
elif col.metadata['role']=='target':
target=col.name
targetType=col.dataType
targetMeta={}
targetMeta['measure']=col.metadata['measure']
prediction_field = "$L-" + col.name
confidence_field = "$LC-" + col.name
#データ区分列の取得
elif col.metadata['role']=='partition':
partition=col.name
# データ読込
sdf = ascontext.getSparkInputData()
#データ区分が学習のデータのみに絞る
print(sdf.filter(partition+" like '1%'").count())
if partition:
sdf=sdf.filter(partition+" like '1%'")
#Spark dataframeをPandasに変換
df = sdf.toPandas()
#lighgbmでモデル作成
import lightgbm as lgb
model = lgb.LGBMClassifier()
model.fit(df[predictors], df[target])
#モデルをファイルシステムに保存
import pickle
pickle.dump(model, open(modelpath+modelfile, 'wb'))
#モデルファイルの保存パス
modelpath='c:/temp/modelpath/'
modelfile='lgbModel.pkl'
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
from pyspark.sql.types import FloatType, StructField
from pyspark.sql.context import SQLContext
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
# スキーマ読み込み
inputSchema = ascontext.getSparkInputSchema()
#Roleから説明変数名と目的変数名を取得
predictors =[]
for col in inputSchema:
#説明変数列の取得
if col.metadata['role']=='input':
predictors.append(col.name)
#目的変数列の取得
elif col.metadata['role']=='target':
target=col.name
targetType=col.dataType
targetMeta={}
targetMeta['measure']=col.metadata['measure']
prediction_field = "$L-" + col.name
confidence_field = "$LC-" + col.name
#予測値のフィールドを出力スキーマに追加
outputSchema = inputSchema
outputSchema.fields.append(StructField(prediction_field, targetType, nullable=True,metadata=targetMeta))
outputSchema.fields.append(StructField(confidence_field, FloatType(), nullable=True))
ascontext.setSparkOutputSchema(outputSchema)
if not ascontext.isComputeDataModelOnly():
#スコアリングデータの読み込み
indf = ascontext.getSparkInputData()
df = indf.toPandas()
#ファイルシステム上のモデルを読み込む
import pickle
loaded_model = pickle.load(open(modelpath+modelfile, 'rb'))
#スコアリング
df[prediction_field] = loaded_model.predict(df[predictors])
df[confidence_field] = loaded_model.predict_proba(df[predictors])[:,1]
print(df)
#Sparkコンテキストの取得
sc = ascontext.getSparkContext()
#データの出力
sqlCtx = SQLContext(sc)
outdf = sqlCtx.createDataFrame(df,schema=outputSchema)
ascontext.setSparkOutputData(outdf)
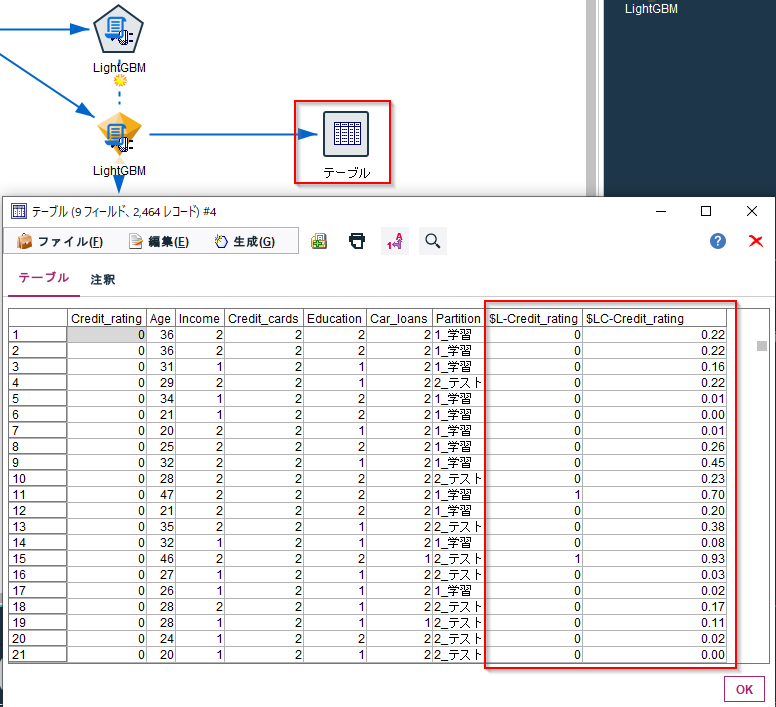
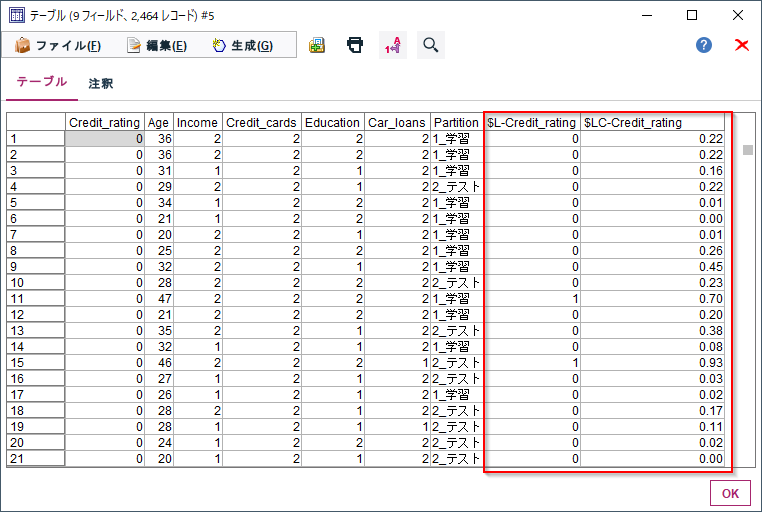
実行するとモデルナゲットができるので、テーブルノードを繋ぎます。
テーブルノードを実行すると$L-Credit_ratingに予測値、$LC-Credit_ratingに確信度が出力されます。
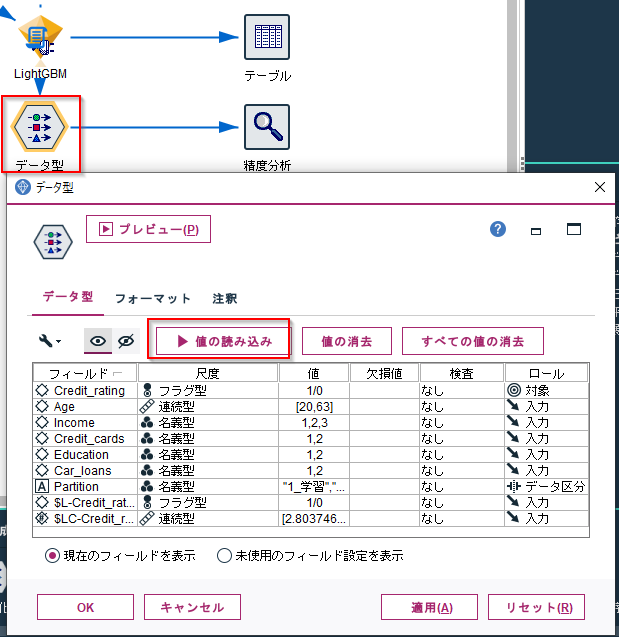
モデルナゲットにデータ型ノード+精度分析ノードも繋ぎます。データ型ノードで値を読み込みます。拡張ノードのモデルナゲットはインスタンス化した値を保持できないようなので、この作業をしないと後続の精度分析ノードがうまく動きませんでした。
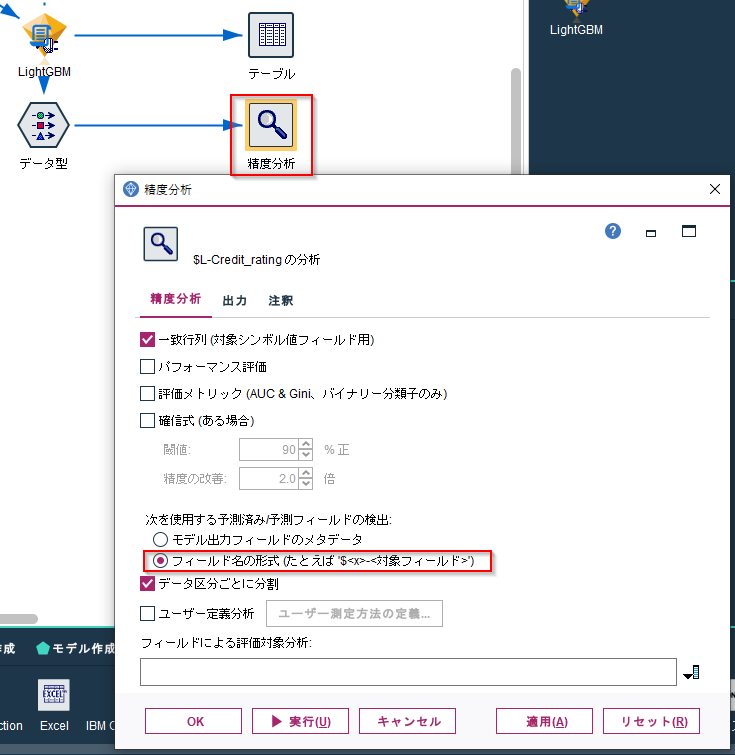
精度分析ノードで「次を使用する予測済み/予測フィールドの検出」で「フィールド名の形式」を選択します。これで$L-の接頭辞があるフィールドを予測結果列と認識します。
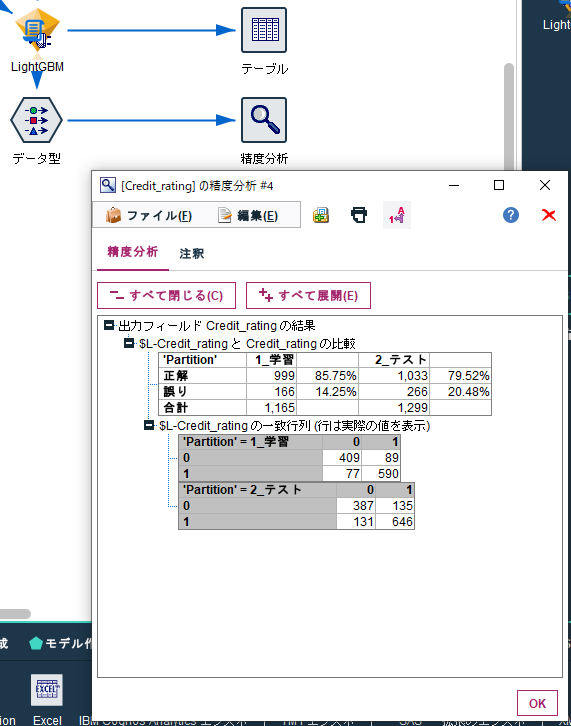
以下のように通常のモデルのように精度を確認できます。
#モデリングスクリプトの解説
最初にモデルの保存パスを定義しています。
本来はascontext.setModelContentFromStringでモデルナゲット内にモデルが保存できると思うのですが、どうしても失敗するために、ファイルシステム内に保存しています。
スコアリング時にはこのファイルが必要になります。特にModeler ServerやCADSと組み合わせて実行する場合など、別のマシンでスコアリングを行う場合には、同じ場所にモデルファイルがないと動きませんので注意が必要です。
#モデルファイルの保存パス
modelpath='c:/temp/modelpath/'
modelfile='lgbModel.pkl'
以下でModelerとのやり取りを行うためのコンテキストオブジェクトを作っています。
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
以下でノードへの入力データから説明変数名群と目的変数名、データ区分列名を取得するために、スキーマを読んでいます。
# スキーマ読み込み
inputSchema = ascontext.getSparkInputSchema()
#Roleから説明変数名群と目的変数名、データ区分列名を取得
predictors =[]
for col in inputSchema:
スキーマ情報には、以下のような各列の列名、データ型、尺度、ロールなどの情報が含まれています。
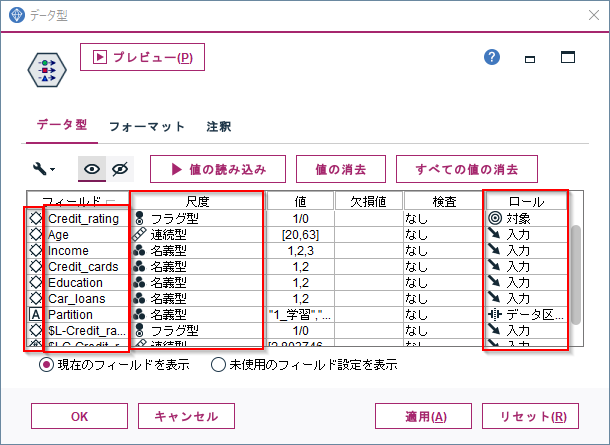
詳しくはマニュアルに書いてあります。
以下でロールが入力、つまり説明変数の列名のリストを作っています。
#説明変数列名リストの取得
if col.metadata['role']=='input':
predictors.append(col.name)
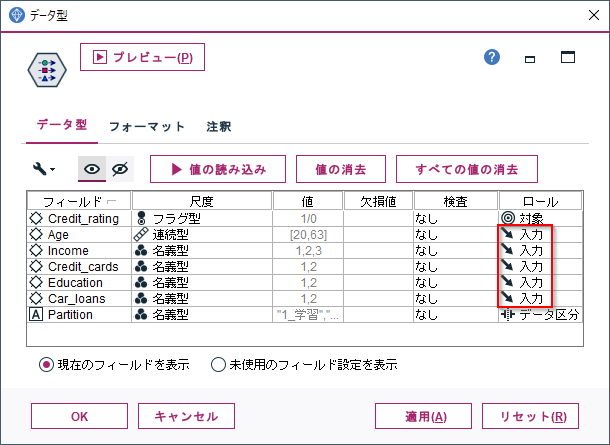
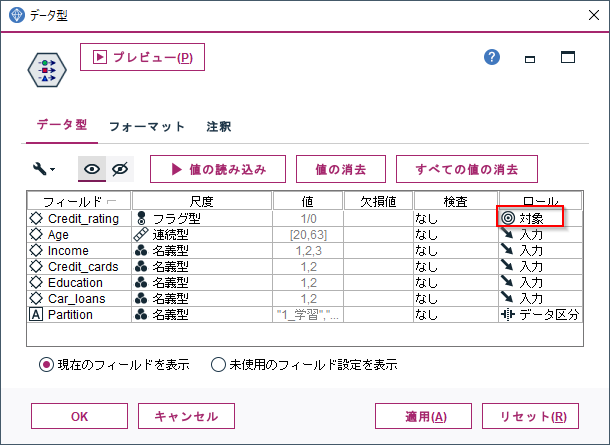
以下でロールが対象、つまり目的変数の列名を取得しています。
なお、対象列が複数あった場合は後からでてきたものが採用されます。
#目的変数列名の取得
elif col.metadata['role']=='target':
target=col.name
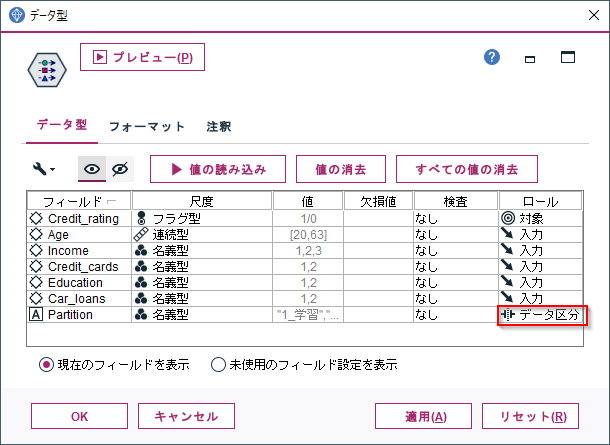
以下でロールがpartition、つまりデータ区分列名を取得しています。
なお、対象列が複数あった場合は後からでてきたものが採用されます。
#データ区分列名の取得
elif col.metadata['role']=='partition':
partition=col.name
以下でデータを読み込んでいます。
データ区分列名がある場合は、sdf.filter(partition+" like '1%'")で、1から始まる行、つまり学習データだけに絞り込んでいます。
Modelerから取得されるデータフレームはSpark DataFrameなので、sdf.toPandas()
でpandasのDataFrameにして取り扱いやすくしています。
# データ読込
sdf = ascontext.getSparkInputData()
#データ区分が学習のデータのみに絞る
if partition:
sdf=sdf.filter(partition+" like '1%'")
#Spark dataframeをPandasに変換
df = sdf.toPandas()
以下でLightGBMのモデルを作っています。
LightGBMには様々なパラメーターがありますが、ここではデフォルトで動かしています。
#lighgbmでモデル作成
import lightgbm as lgb
model = lgb.LGBMClassifier()
model.fit(df[predictors], df[target])
最後に、生成されたモデルをpickleを使ってシリアライズして、スクリプトの先頭で定義したmodelpath+modelfileに保存しています。
#モデルをファイルシステムに保存
import pickle
pickle.dump(model, open(modelpath+modelfile, 'wb'))
スコアリングスクリプトの解説
モデリングスクリプトで指定したものと同じモデルファイル保存パスを指定します。
#モデルファイルの保存パス
modelpath='c:/temp/modelpath/'
modelfile='lgbModel.pkl'
モデリングスクリプトでも行ったように、Modelerとのやり取りを行うためのコンテキストオブジェクトを作っています。
モデリングスクリプトに加えて、ここでは新しいSparkDataFrameを作成するためにSQLContextを、また新しい列をつくるためにFloatType, StructFieldもインポートしています。
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
from pyspark.sql.types import FloatType, StructField
from pyspark.sql.context import SQLContext
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
以下でノードへの入力データから説明変数名群と目的変数名を取得するために、スキーマを読んでいます。モデリングスクリプトと同様です。
# スキーマ読み込み
inputSchema = ascontext.getSparkInputSchema()
#Roleから説明変数名と目的変数名を取得
predictors =[]
for col in inputSchema:
以下でロールが入力、つまり説明変数の列名のリストを作っています。ここもモデリングスクリプトと同様です。
#説明変数列の取得
if col.metadata['role']=='input':
predictors.append(col.name)
以下でロールが対象、つまり目的変数の列名を取得しています。
ここはモデリングスクリプトでのスクリプトに加えて、予測値列("$L-")や確信度列("$LC-")を追加するために列名を定義したり、データタイプ(col.dataType)や尺度(col.metadata['measure'])も取得しています。
#目的変数列の取得
elif col.metadata['role']=='target':
target=col.name
targetType=col.dataType
targetMeta={}
targetMeta['measure']=col.metadata['measure']
prediction_field = "$L-" + col.name
confidence_field = "$LC-" + col.name
以下で入力データのスキーマに予測値列と確信度列を追加して、出力スキーマとしています。予測値列は目的変数列のデータ型やメタデータをコピーしています。確信度列はFloatType()を指定しています。
#予測値列と確信度列を出力スキーマに追加
outputSchema = inputSchema
outputSchema.fields.append(StructField(prediction_field, targetType, nullable=True,metadata=targetMeta))
outputSchema.fields.append(StructField(confidence_field, FloatType(), nullable=True))
ascontext.setSparkOutputSchema(outputSchema)
以下は実際にスコアリングを行う場合に以降のスクリプトを実行するという条件になります。
ここは少しややこしいところです。
ここまでのスクリプトはsetSparkOutputSchemaで出力スキーマを定義するものでした。モデルナゲットの後ろにノードを追加する場合、DataModelをComputeしてスキーマを定義することは必要ですが、実際にスコアリングしたデータは必要ありません。
ですので無駄なスコアリング処理をしないために、「スコアリングデータがいる場合にのみ」(Not isComputeDataModelOnly)、スコアリングをするスクリプトを実行するという条件を入れています。
マニュアルにDataModelOnly モードという解説があります。
if not ascontext.isComputeDataModelOnly():
以下で入力データを読み込んでPandasのDataFrameに変換しています。
#スコアリングデータの読み込み
indf = ascontext.getSparkInputData()
df = indf.toPandas()
以下で、スクリプトの先頭で定義したmodelpath+modelfileからモデルをファイルシステムから読み込みます。
#ファイルシステム上のモデルを読み込む
import pickle
loaded_model = pickle.load(open(modelpath+modelfile, 'rb'))
以下で、スコアリングをしています。predictは予測値を得ています。predict_probaは確信度を得ています。確信度はそれぞれのクラス、ここではCredit_ratingが0,1で値を返します。[:,1]でCredit_rating=1の確信度のみを取得しています。
#スコアリング
df[prediction_field] = loaded_model.predict(df[predictors])
df[confidence_field] = loaded_model.predict_proba(df[predictors])[:,1]
以下で予測値列と確信度列を追加したPandas DataFrameであるdfを、sqlCtx.createDataFrame(df,schema=outputSchema)でSparkDataFrameに変換しなおして、setSparkOutputDataでModelerに返しています。
#Sparkコンテキストの取得
sc = ascontext.getSparkContext()
#データの出力
sqlCtx = SQLContext(sc)
outdf = sqlCtx.createDataFrame(df,schema=outputSchema)
ascontext.setSparkOutputData(outdf)
参考
Python for Spark を使用したスクリプト