SPSS Modelerで既存のデータから関数などを使ってデータを加工する「フィールド作成」ノードをつかって、時系列センサーデータから特徴量抽出を行います。そしてその処理をPythonのpandasで書き換えてみます。
SPSS Modelerでは様々なデータ加工を行うノードが用意されていますが、「フィールド作成」ノードはかなり汎用的な自由度の高いデータ加工を行うノードです。
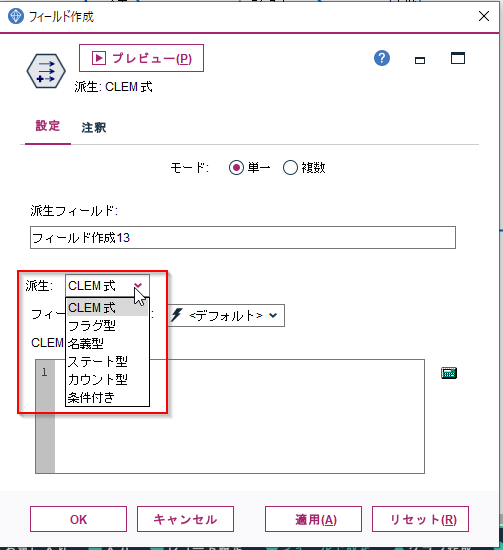
加工のパターンは「派生」のリストから選べます。派生というとイメージがしにくいですがderiveという英語の翻訳で、元のデータから派生してつくる加工のパターンという意味になります。
個人的によく使う順に説明します。
- CLEM式:四則演算や論理演算、関数をつかった加工。もっとも汎用的です
- 条件付き:IF文を作成して加工データを作ります
- フラグ型、名義型:IF文でフラグやカテゴリ型の変数を生成します
- カウント型:IF文などによって、累積値を生成します
- ステート型:IF文で状態の遷移から特徴量を生成します
いずれもレコードを上から順に処理します。特にカウント型やステート型ではレコードの処理順を意識することが必須になります。
汎用的なノードですのでさまざまな加工が考えられますが、今回は時系列のセンサーデータから特徴量を抽出する目的で利用してみます。
時系列のセンサーデータはそのままではあまり情報量がないため、有効な特徴量を加工してつくることが分析のカギになります。例えば「200Wを超えたらエラーになる」という単純な特徴がつかめれば簡単なのですが、実際にはそのセンサーの値がどう変化してきたか、例えば急激に電力量が上がっている、電力量が安定せずに増減をジグザグに繰り返しているなどの情報で分析しないと意味がある分析ができないことがほとんどです。
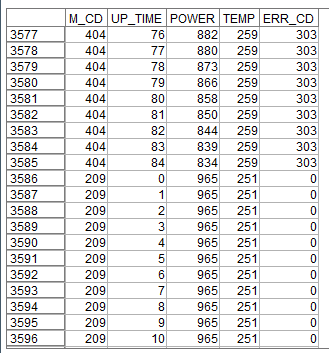
分析対象のデータは以下です。
M_CD: マシンコード
UP_TIIME: 起動時間
POWER: 電力
TEMP: 温度
ERR_CD: エラーコード
各マシンコードごとに起動時間にそって電力や温度の変化、そしてエラーがあればそれが時系列に記録されています。
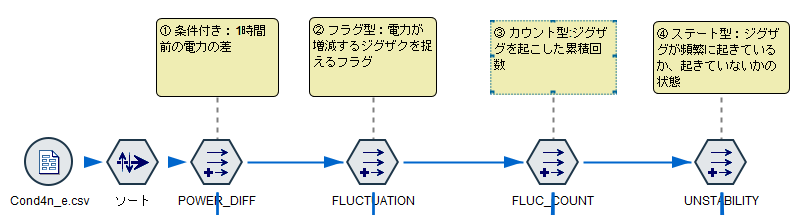
今回はこのデータから以下のような特徴量を作ってみます。
① 条件付き:1時間前の電力の差
② フラグ型:電力が増減するジグザクを捉えるフラグ
③ カウント型:ジグザグを起こした累積回数
④ ステート型:ジグザグが頻繁に起きているか、起きていないかの状態
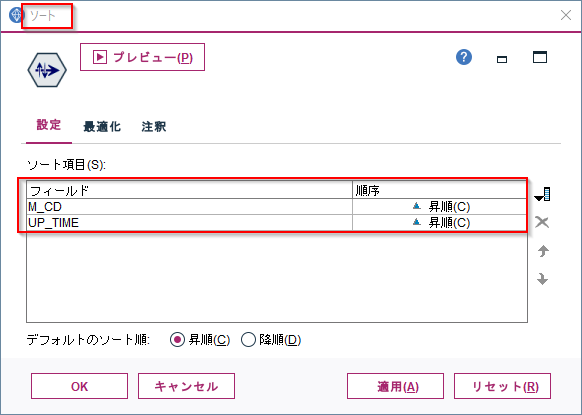
いずれもレコード順序が要な加工を行いますので、ソートノードをつかって各マシンコードと起動時間ごとにソートをしておきます。
1m.① 条件付き:1時間前の電力の差 Modeler版
「1時間前の電力との差」の特徴量を作ってみます。
フィールド作成ノードで「派生:条件付き」に設定します。
そうするとIF文の構造を表す入力項目がでてきます。実はIF文は「派生:CLEM式」でも書けるのですが、より可読性を高めるためには「派生:条件付き」を使うことをお勧めします。
まずThen:に@DIFF1(POWER)を入力します。@DIFF1はCLEM関数というModelerのビルトイン関数で、一行前との差を計算するというものです。これで1時間前の電力との差が計算できます。
次にIf:にM_CD = @OFFSET(M_CD,1)、Else:にundefを設定します。
@OFFSETとはN行前の値を参照するという関数です。ここでは1行前を参照しています。undefはNULLを意味します。つまり前行のM_CDと同じ場合は@DIFF1(POWER)を計算し、前行のM_CDと異なる場合は、別のマシンの電力との差を計算しても意味がないので、NULLを入れるという意味になります。
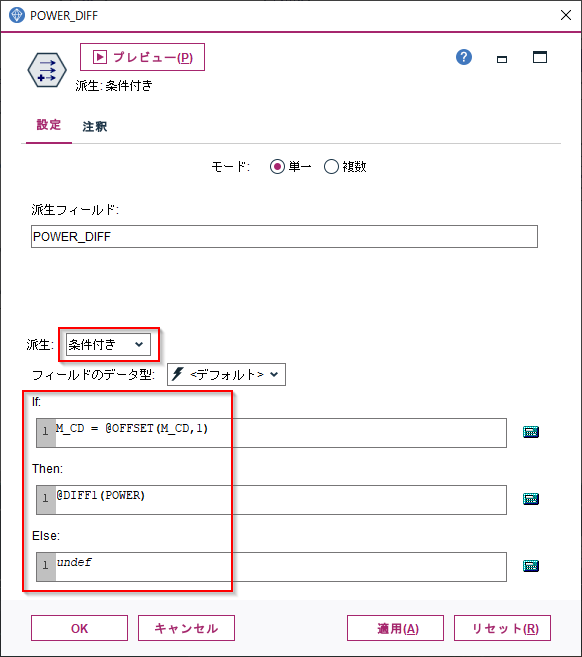
結果は以下のようになります。
POWER_DIFFという新しい派生列ができていて、前の行のPOWERから現在のPOWERを引いた値が入っています。930行目の例でいうと988W-991W=-3Wが入っています。
また、941行目をみると$null$が入っています。これは940行目までがM_CD=204のマシンのデータで、941行目からがM_CD=209 のマシンのデータなので電力との差を計算しても意味がないのでNULLを入れています。
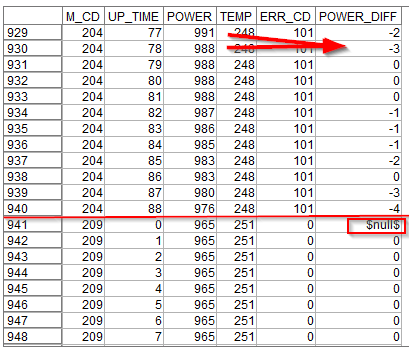
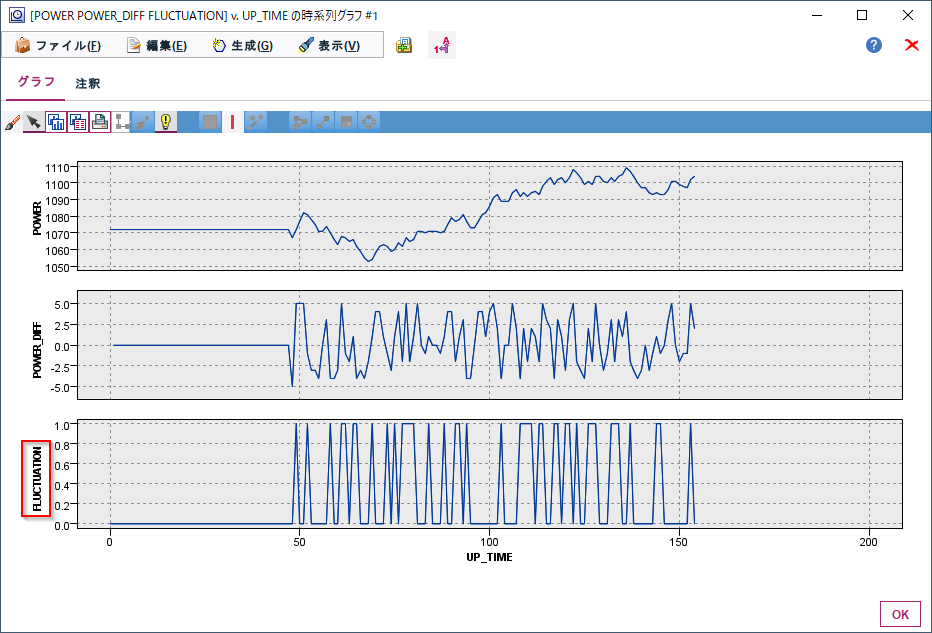
ちなみに時系列のグラフでM_CD = 1000とM_CD = 229の2台のマシンを見てみます。
M_CD = 1000は最初から単調に電力が-1W、-2W減少しており、一度も増えてはいません。最後の方で-5W、-6Wという比較的大きな減り方をしています。
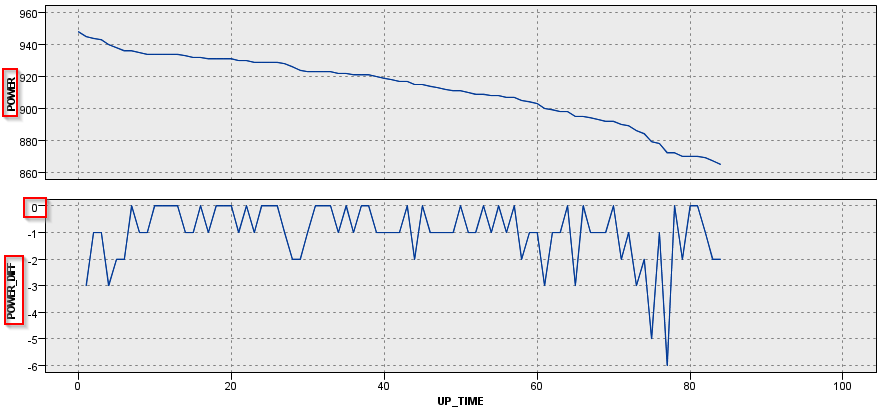
M_CD = 229の場合はかなりプラスの差もマイナスの差もあり、増減を繰り返していました。
1p.① 条件付き:1時間前の電力の差 pandas版
pandasではM_CDごとにグループ化してPOWERに対して、1時間前の計算をあらわすdiff(1)の計算を行ってdf['POWER_DIFF']という新しい列に入れています。
# 1時間前の電力の差
df['POWER_DIFF'] = df.groupby(['M_CD'])['POWER'].diff(1)
2m.② フラグ型:電力が増減するジグザクを捉えるフラグ Modeler版
M_CD = 229のマシンのように電力が増減を繰り返すことは電源に何か問題があるかもしれません。「1時間前の電力の差」だけですとその単一の値(例:-5W)だけでは、電力の増減のジグザグを捉えることはできていません。
電力の差がプラスからマイナスに転じた、もしくはマイナスからプラスに転じたことを示す特徴量を作ります。
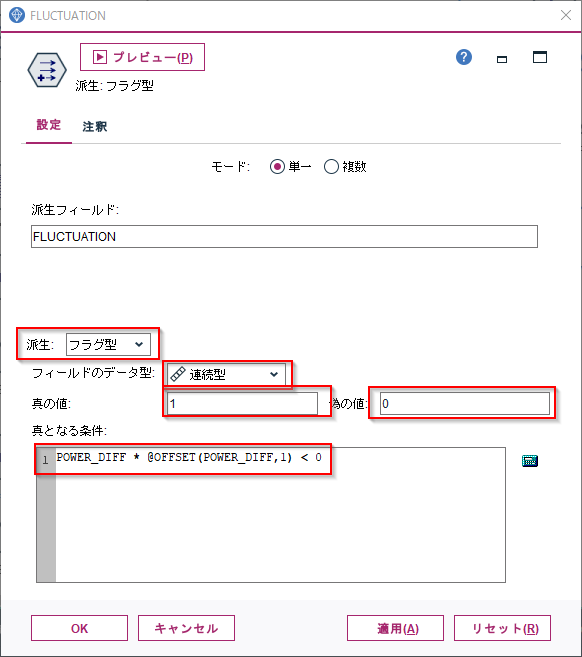
フィールド作成ノードで「派生:フラグ型」に設定します。
フィールドのデータ型はここでは後で時系列グラフに表示したかったので連続型にし、真の場合1,偽の場合は0としました。単にフラグが欲しいだけであれば、データ型はフラグ型のままで構いません。
真となる条件に
POWER_DIFF * @OFFSET(POWER_DIFF,1) < 0
を設定します。「1時間前の電力の差」*1時間前の「1時間前の電力の差」を計算しマイナスになるかを判定しています。
プラスとマイナスの掛け算はマイナスになり、プラス同士やマイナス同士の場合の掛け算はプラスになります。ですので、符号が反転した場合に、つまりジグザグが起きた場合にフラグを立てています。
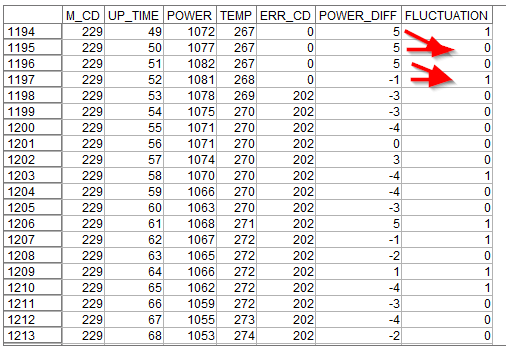
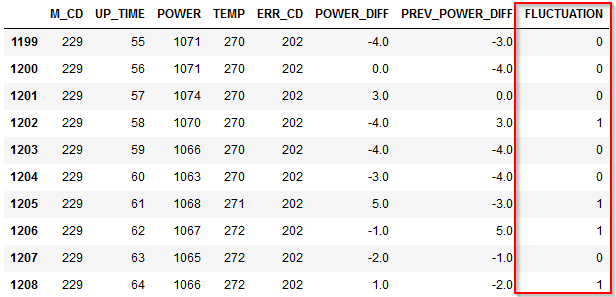
結果は以下のようになります。
FLUCTUATIONという新しい派生列ができていて、POWER_DIFFと前の行のPOWER_DIFFの符号が違う場合に1が入っています。
1195行目で言うと1時間前に5W増加し、この時間も5W増加していますので、単調に増えています。そのためフラグは0です。
一方で、
1197行目で言うと1時間前に5W増加していますが、この時間は-1Wと減少していますので、ジグザグが起きています。そのためフラグは1です。
グラフをみないとわからなかったジグザグの状況が1197行目の1レコードをみるだけでもわかるようになりました。
やはり時系列のグラフでM_CD = 1000とM_CD = 229の2台のマシンを見てみます。
M_CD = 1000は最初から単調に電力が減少しているので、ジグザグは起きていません。
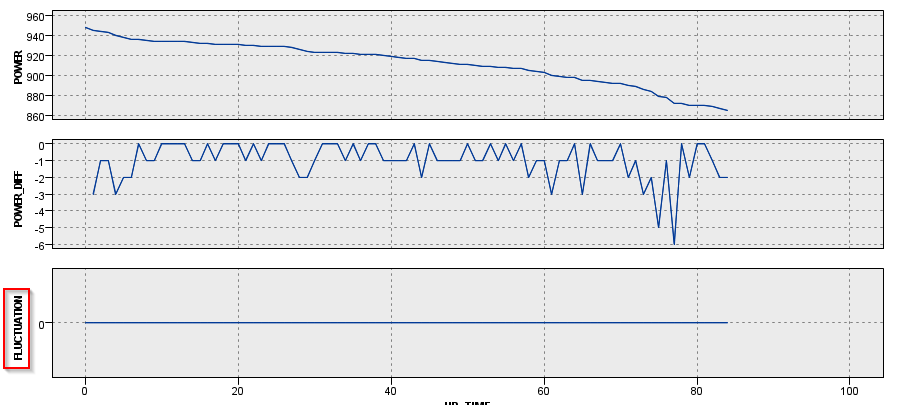
M_CD = 229の場合は細かく増減を繰り返していることがよく分かります
2p.② フラグ型:電力が増減するジグザクを捉えるフラグ pandas版
pandasでジグザグを捉えるフラグをつくることはすこしややこしくなります。
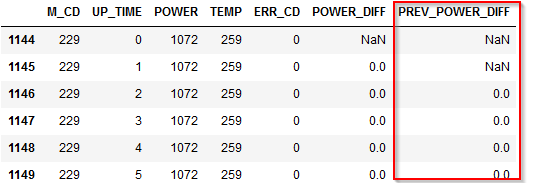
まず1時間前のPOWER_DIFFの変数を作ります。
M_CDごとにグループ化してPOWER_DIFFに対して、1時間前の値をshift(1)で参照し、df['PREV_POWER_DIFF']という新しい列に入れています。
# 1時間前のPOWER_DIFFの列を追加
df['PREV_POWER_DIFF'] = df.groupby(['M_CD'])['POWER_DIFF'].shift(1)
この列は最終的には不要なので、Modelerでは作成しなかった列ですが、pandasでは計算のために必要です。
次に関数func_fluctuationを定義します。この関数の中の以下のIF文で
if x.POWER_DIFF * x.PREV_POWER_DIFF < 0:
で「1時間前の電力の差」*1時間前の「1時間前の電力の差」を計算しマイナスになるかを判定しています。
そしてこの関数を各行に対してlambdaで呼び出して、結果をdf['FLUCTUATION']という新しい列に入れています。
注意が必要なのはaxis=1としていることで、pandas.Seriesからpandas.DataFrameに変換していることです。
# プラスとマイナスの反転判定をする関数
def func_fluctuation(x):
if x.POWER_DIFF * x.PREV_POWER_DIFF < 0:
return 1
else:
return 0
# プラスとマイナスの反転判定をする関数を各行から呼び出し
df['FLUCTUATION'] = df.apply(lambda x:func_fluctuation(x),axis=1)
以下のように生成できました。
- 参考
- pandasで条件分岐(case when的な)によるデータ加工を網羅したい - Qiita
- https://qiita.com/Hyperion13fleet/items/98c31744e66ac1fc1e9f
3m.③ カウント型:ジグザグを起こした累積回数 Modeler版
M_CD = 229のマシンのようにジグザグが何度もある場合は電源に何か問題があるかもしれませんが、逆に数回のジグザクであれば問題ないと考えられるかもしれません。
起動後に累積でジグザグが何回発生したかという累積和の特徴量を作成してみます。
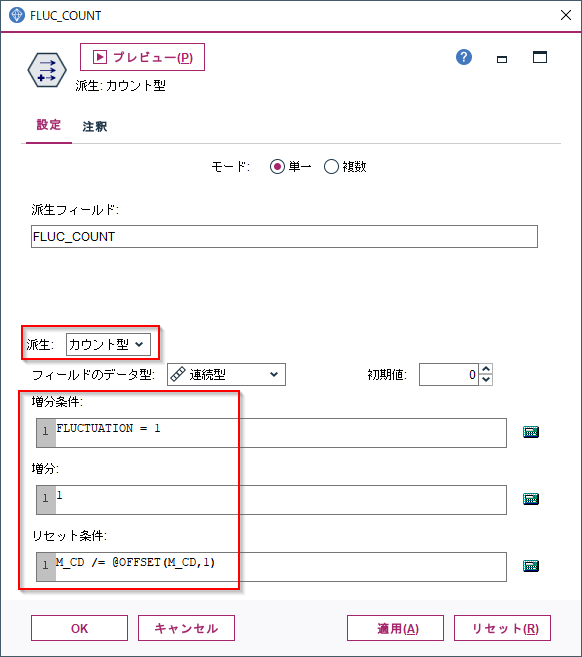
フィールド作成ノードで「派生:カウント型」に設定します。
増分条件に
FLUCTUATION = 1
増分は1
を設定します。ジグザグが発生した時に1つカウントアップするという意味です。
また、リセット条件にはM_CD /= @OFFSET(M_CD,1)を設定し、マシンが変わったらカウンターを0に戻すという設定をしています。
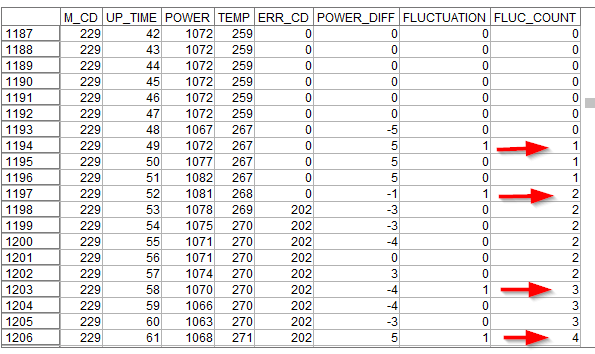
結果は以下のようになります。
FLUC_COUNTという新しい派生列ができていて、FLUCTUATIONに1が入ると1つずつカウントアップされていきます。
1194行目をみると、FLUCTUATIONが発生しているのでFLUC_COUNTが1になります。
その後1197行までは1が維持されます。そして1197行でまたFLUCTUATIONが発生しているので、2に増えています。
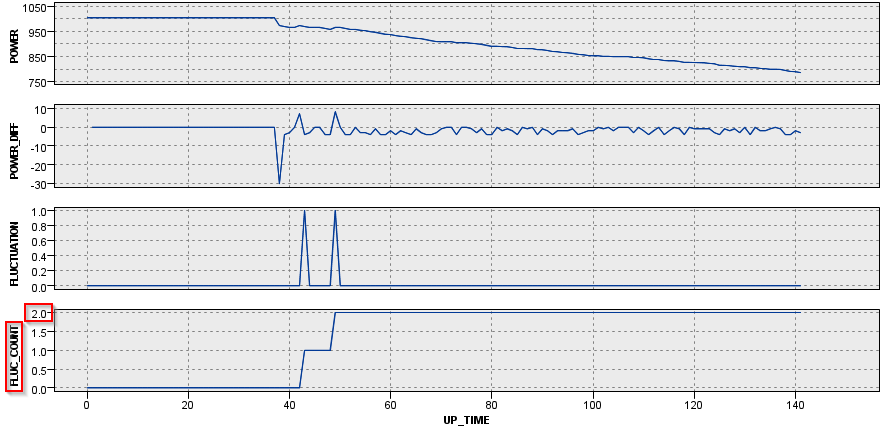
今度は時系列のグラフでM_CD = 104とM_CD = 229の2台のマシンを見てみます。
M_CD = 104は40時間過ぎに2回のジグザグがあり、その後は単調に電力が減少しています。なのでFLUC_COUNTは50時間後くらいからは2のままで保たれます。
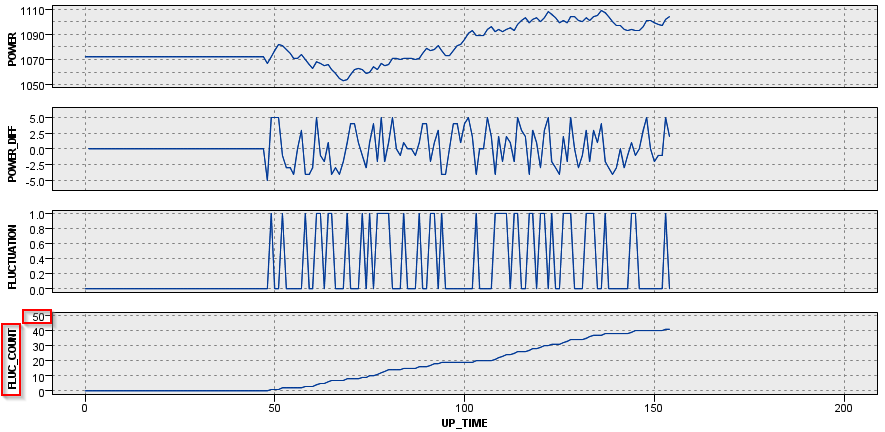
M_CD = 229の場合はずっと細かく増減を繰り返して40回以上ジグザグ状態を繰り返していました。
3p.③ カウント型:ジグザグを起こした累積回数 pandas版
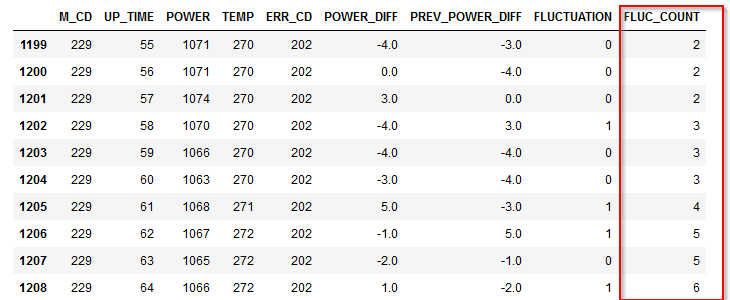
pandasでは累積和を計算するcumsum()という関数で計算をすることができます。
M_CDごとにグループ化してFLUCTUATIONの累積和をcumsum()で計算しdf['FLUC_COUNT']という新しい列に入れています。
# ジグザグを起こした累積回数
df['FLUC_COUNT'] = df.groupby(['M_CD'])['FLUCTUATION'].cumsum()
以下のように生成できました。
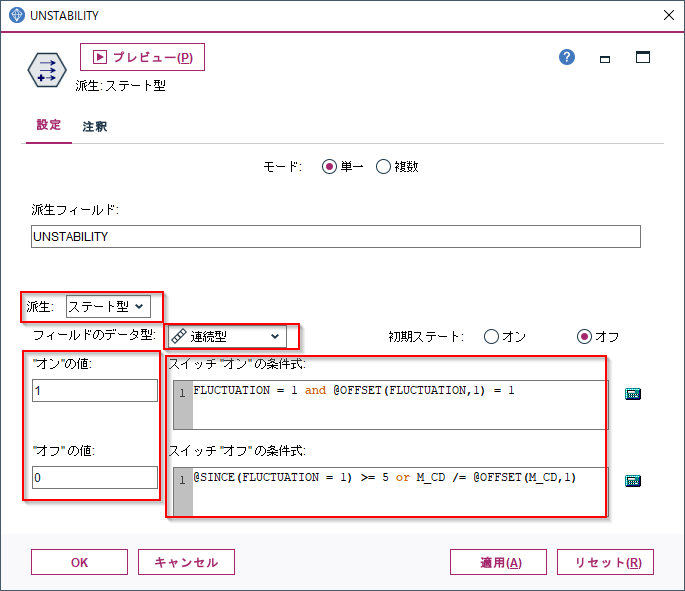
4m.④ ステート型:ジグザグが頻繁に起きているか、起きていないかの状態 Modeler版
ジグザグの状態も多少の変動であれば大きな問題はないかもしれません。一方でジグザグが短期間で繰り返すようならその後ジグザグがおさまってもその影響は残るかもしれません。
そういう複雑な状況を表現できるのが「派生:ステート型」になります。
フィールド作成ノードで「派生:ステート型」に設定します。
フィールドのデータ型はここでは後で時系列グラフに表示したかったので連続型にし、”オン”の場合1,”オフ”の場合は0としました。単にフラグが欲しいだけであれば、データ型はフラグ型のままで構いません。
スイッチ”オン”の条件式に
FLUCTUATION = 1 and @OFFSET(FLUCTUATION,1) = 1
を設定します。
これはジグザグが起きていて、1時間前にもジグザグが起きたということを意味します。
つまり2時間連続でジグザグが起きたということです。
次にスイッチ”オフ”の条件式に
@SINCE(FLUCTUATION = 1) >= 5 or M_CD /= @OFFSET(M_CD,1)
を設定します。
@SINCEは、引数として与えた式が成り立つのは何行前かという行数を数値を返します。@SINCE(FLUCTUATION = 1) >= 5 はジグザグが最後に起きたのが5行以上前ということを意味します。つまり逆に言うと、5時間以上連続でジグザグが起きていないので安定しているということを意味しています。
またM_CD /= @OFFSET(M_CD,1)はリセット条件になっていて、マシンが変わったらステータスをオフに戻すという設定をしています。
フラグ型と似ているのですが、オンとオフの条件を非対称にできるのがステート型です。ここではジグザグの不安定な状況が2回続いたら、オンにして、一方で安定状態は5回続かないとオフに戻さないということをしています。
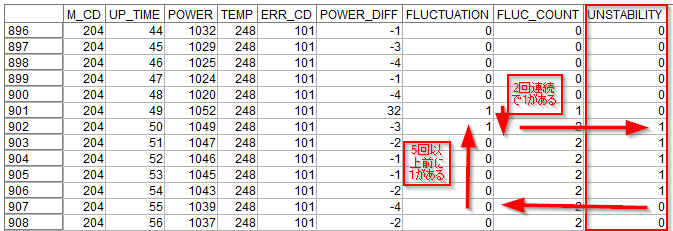
結果は以下のようになります。
UNSTABILITYという新しい派生列ができています。
まず902行目をみると、FLUCTUATIONに1が2レコード連続で入って1がたちます。ジグザグが2時間連続で続くことを不安定と判定したことになります。
次に903行目から906行目までは、FLUCTUATIONは0で発生していませんが、UNSTABILITYは1のままです。
そして907行目で5レコード以上前にFLUCTUATIONが1だったので、つまり5レコード以上連続でFLUCTUATIONが0だったので、UNSTABILITYが0に戻りました。ジグザグが5時間以上発生しなかったので、安定したと判定したことになります。
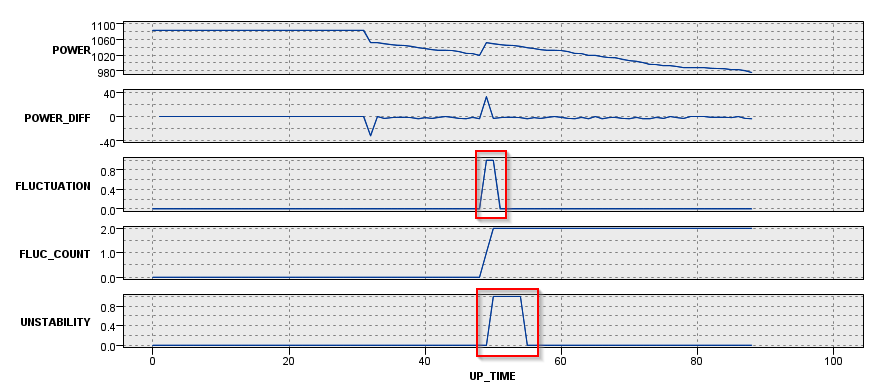
今度は時系列のグラフでM_CD = 204とM_CD = 229の2台のマシンを見てみます。
M_CD = 204は49時間過ぎに2回のジグザグがあり、その後は単調に電力が減少しています。なのでUNSTABILITYは一度1になった5時間後からは0のままで保たれます。
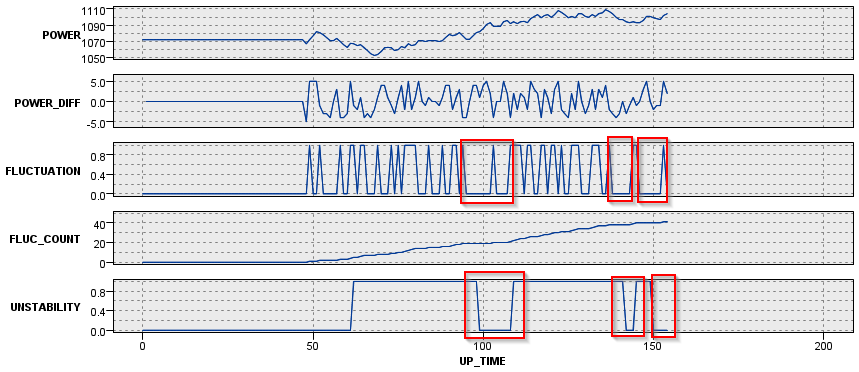
M_CD = 229の場合はずっと細かく増減を繰り返していて、UNSTABILITYは1である期間が長いのですが、5時間連続でジグザグがない状態が3回あり、その間はUNSTABILITYは0になっています。
4p.④ ステート型:ジグザグが頻繁に起きているか、起きていないかの状態 pandas版
pandasではこのような複雑な条件を表現するのは難しいので、ループ処理でシリアルな処理を考えました。
# 先頭行は安定の初期値
df.at[0, 'UNSTABILITY'] = 0
stable_seq_count = 0
# 2行目(index=1)からループ処理
for index in range(1,len(df)):
#既定は直前のステータスを保持する
df.at[index, 'UNSTABILITY'] = df.at[index-1, 'UNSTABILITY']
#変動があった場合
if df.at[index, 'FLUCTUATION'] == 1 :
#連続安定カウントを初期化
stable_seq_count = 0
#変動が2回続いた場合、不安定状態判定
if df.at[index-1, 'FLUCTUATION'] == 1:
df.at[index, 'UNSTABILITY'] = 1
#変動がなかった場合、連続安定カウントをアップ
elif df.at[index, 'FLUCTUATION'] == 0:
stable_seq_count += 1
#連続安定カウントが5回以上続いた場合かマシンが別のマシンになった場合、安定状態判定
if stable_seq_count >= 5 or df.at[index, 'M_CD'] != df.at[index-1, 'M_CD']:
df.at[index, 'UNSTABILITY'] = 0
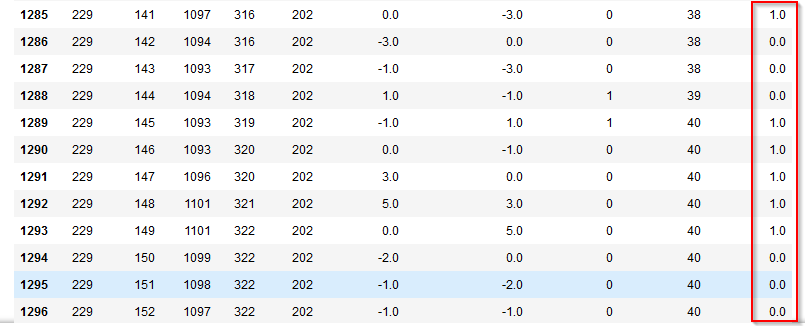
以下のように生成できました。
- 参考
- Python 3.x - データフレームの中の一個前の列を参照して、次の列の演算を行う Python,Pandas|teratail
- https://teratail.com/questions/64620
- Pythonのfor文によるループ処理(range, enumerate, zipなど) | note.nkmk.me
- https://note.nkmk.me/python-for-usage/
5. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/derive/derive3.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/derive/derive.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/Cond4n_e.csv
■テスト環境
Modeler 18.2.2
Windows 10 64bit
Python 3.6.9
pandas 0.24.1