SPSS ModelerのPythonやRで書いた拡張ノードをあまりプログラミング言語に詳しくない方にでも簡単に使ってもらいたいことがあります。
そういう場合にはカスタムノードを作ることができます。
ここでは以下の記事で作った正規表現を行うPython拡張ノードをカスタムノード化してみたいと思います。
SPSS Modelerで正規表現を使う(Python拡張ノード版) - Qiita
この拡張ノードでは以下のようにNAMEという列の文字列から前株の「株式会社」という文字列を「(株)」に置き換えるNAME_REという列を追加しています。

プログラムの以下の部分で正規表現の対象となる列や置換したい文字列を指定しています。
#対象とする列名
target_col_name='NAME'
#追加する列名
res_col_name=target_col_name+'_RE'
#検索対象文字列
old='^株式会社'
#置換対象文字列
new=r'(株)'
カスタムノードではこの部分をGUIから指定できるようにします。
- サンプルストリームとカスタムノード
サンプルストリーム
regexppy.mpe
- テスト環境
- Modeler 18.3
- Windows 10 64bit
- Python 3.8.10
1 カスタムノードを作り始める
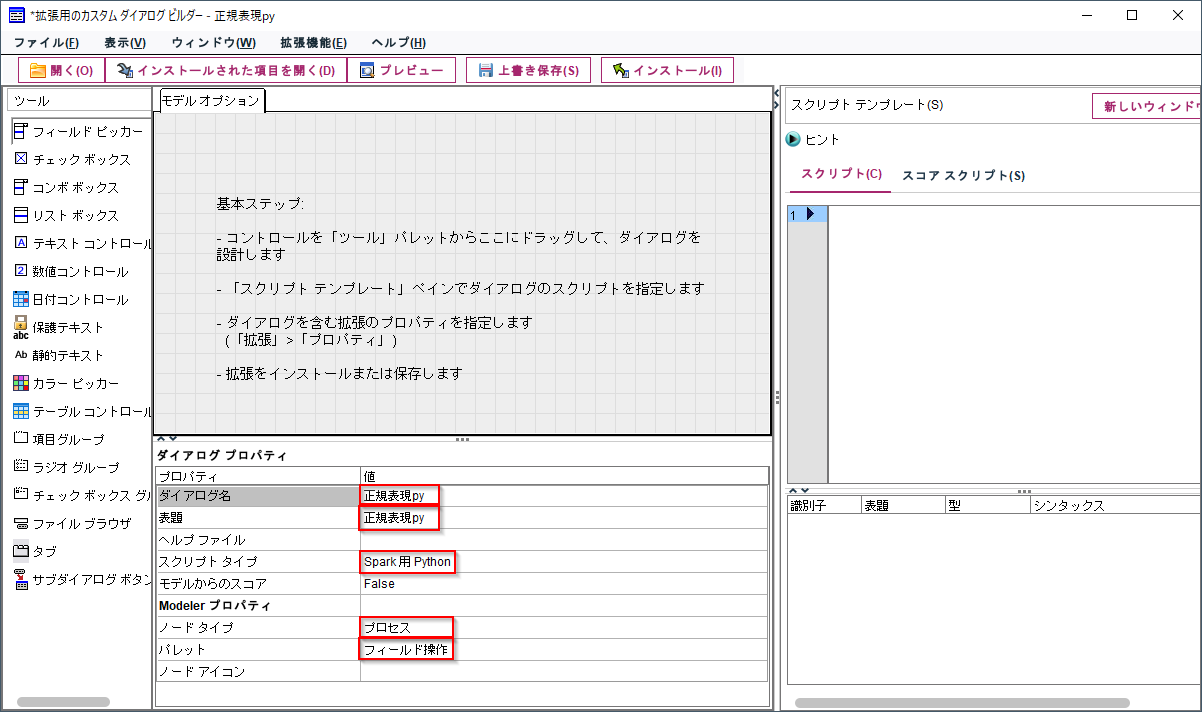
メニューの「拡張機能」の「カスタムノードダイアログビルダー」を起動します。

「ダイアログ名」と「表題」に一意になるノードの名前を入力します。
「スクリプトタイプ」は今回のスクリプトはPythonなので「Spark用Python」を選びます。
列のデータ加工なので「ノードタイプ」に「プロセス」を選び、「パレット」に「フィールド操作」を選びます。
2 コントロールの配置
GUIのコントロールをダイアログに配置します。
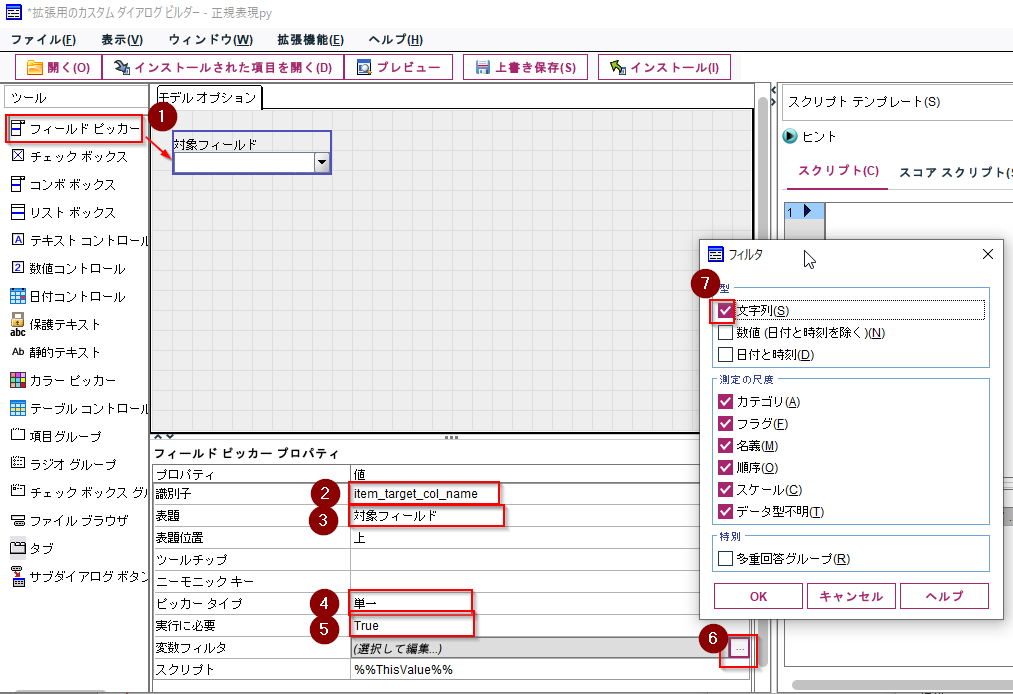
まず、正規表現適用の「対象フィールド」を指定する「フィールドピッカー」を配置します。
識別子、表題を指定します。識別子は「item_+変数名」のようにプログラムで呼び出す際にわかりやすい名前をつけることをお勧めします。
「ピッカータイプ」はここでは「単一」を選びます。これは一列だけを選ぶという意味です。「多重」にして複数列を対象できるようにしてもよいのですが、今回は元のプログラムが単一列を対象にしているので、その場合はプログラムの修正が必要です。
入力必須項目なので「実行に必要」は「True」を指定します。
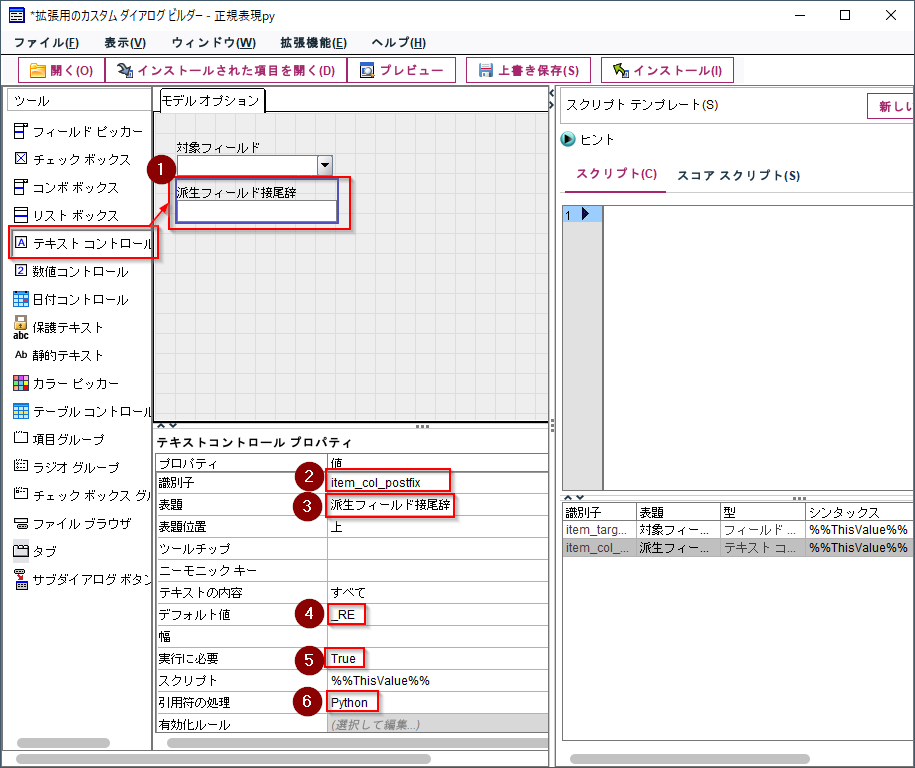
次に正規表現適用後の値を書き出す派生フィールド名に付ける接尾辞を入力する「テキストコントロール」を配置します。
識別子、表題を指定します。
「デフォルト値」には「_RE」を入れておきます。つまり派生フィールド名は「<対象フィールド>_RE」になります。
入力必須項目なので「実行に必要」は「True」を指定します。
「引用符の処理」は「Python」にしておきます。
そして、検索対象文字列を入力する「テキストコントロール」を配置します。
識別子、表題を指定します。
入力必須項目なので「実行に必要」は「True」を指定します。
「引用符の処理」は「Python」にしておきます。

最後に、置換対象文字列を入力する「テキストコントロール」を配置します。
識別子、表題を指定します。
「引用符の処理」は「Python」にしておきます。
入力必須項目ではないので、「実行に必要」は「False」のままにしておきます。

3 スクリプトの記述
「拡張ノード」に書いたスクリプトをスクリプトの入力欄にコピーペーストします。
そして、各コントロールと対応する変数に「%%識別子%%」を入力します(コントロール上で右クリックをして「スクリプトテンプレートに追加」を選ぶと簡単に入力できます)。余計な空白などが入らないように気を付けてください。
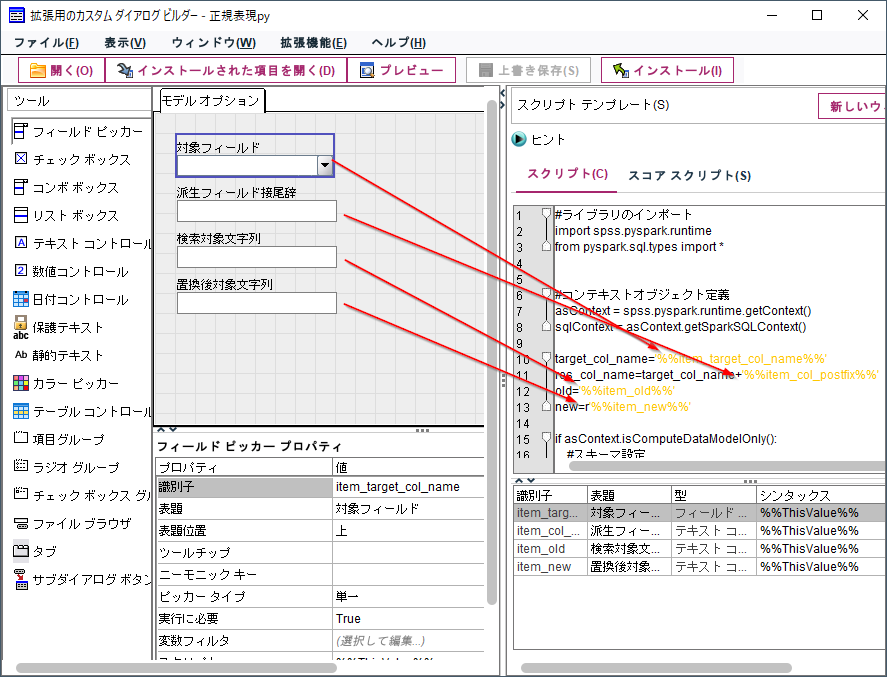
完成したスクリプトは以下です。
#ライブラリのインポート
import spss.pyspark.runtime
from pyspark.sql.types import *
#コンテキストオブジェクト定義
asContext = spss.pyspark.runtime.getContext()
sqlContext = asContext.getSparkSQLContext()
target_col_name='%%item_target_col_name%%'
res_col_name=target_col_name+'%%item_col_postfix%%'
old='%%item_old%%'
new=r'%%item_new%%'
if asContext.isComputeDataModelOnly():
#スキーマ設定
inputSchema = asContext.getSparkInputSchema()
outputSchema = inputSchema
outputSchema.fields.append(StructField(res_col_name, StringType(), nullable=True))
asContext.setSparkOutputSchema(outputSchema)
else:
#データ読込
indf = asContext.getSparkInputData()
df = indf.toPandas()
#正規表現加工
df[res_col_name]=df[target_col_name].str.replace(old, new, regex=True)
#データ書出し
outdf = sqlContext.createDataFrame(df)
asContext.setSparkOutputData(outdf)
4 拡張機能のプロパティ設定
「拡張機能」メニューの「プロパティ」を開きます。

「名前」にAsciiで名前をつけ、「要約」に入力をし、「続行」ボタンで閉じます。

5 カスタムノードの保存とインストール
ファイルメニューから「名前を付けて保存」を選びます。

適当なところに保存します。
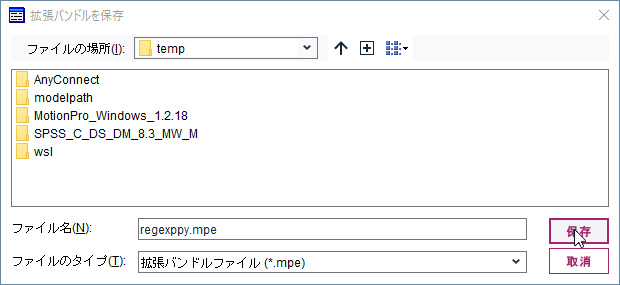
次に「インストール」ボタンをクリックします。

インストールされたというメッセージが出ます。
「ノードタイプ」に「プロセス」を選び、「パレット」に「フィールド操作」を選んだので、フィールド設定のパレットに導入されます。

ノードをキャンバスに置いて接続します。

「対象フィールド名」に「NAME」
「検索対象文字列」には「^株式会社」
「置換対象文字列」には「(株)」
を入力します。
NAME列の前株を「(株)」に置き換えるという設定です。
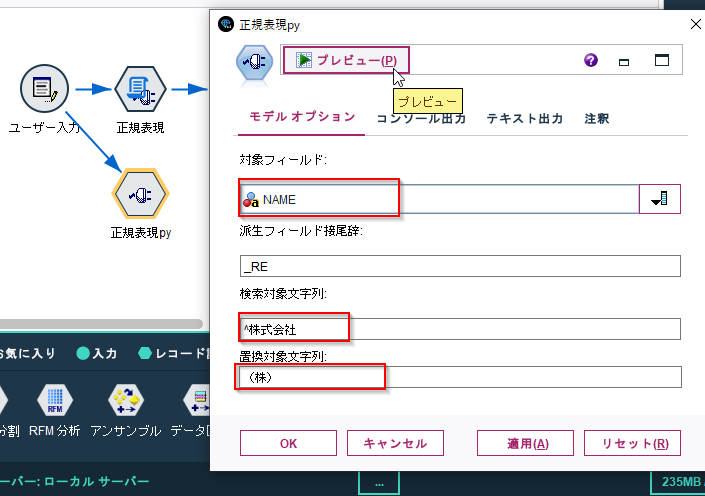
正しく変換できています。

このようにカスタムノードにすることで、プログラムを読めなくてもPythonを利用することができるようになります。
6 カスタムノードのアンインストール、再インストール、配布、上書きなど
まず、カスタムノードを使っているストリームを閉じておきます。
それからファイルメニューから「アンインストール」できます。
アンインストールするカスタムノードを選びます。
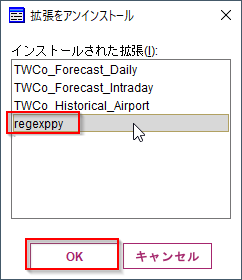
アンインストール前に保存をすることもできます。

パレットからなくなりました。
再インストールしたり、他の人のModelerに導入する場合には、「開く」で保存した.mpeファイルを開きます。
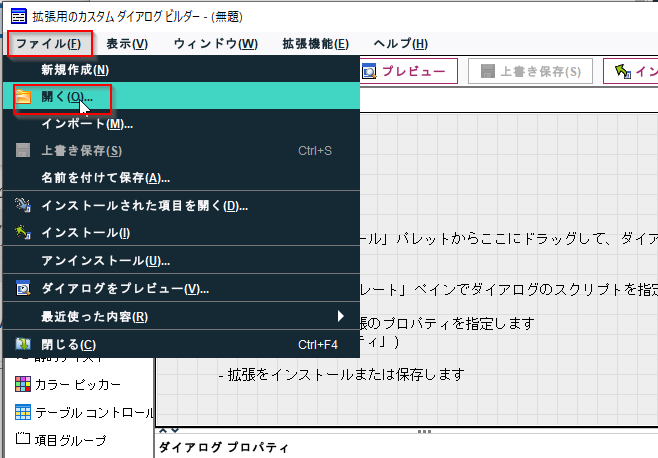
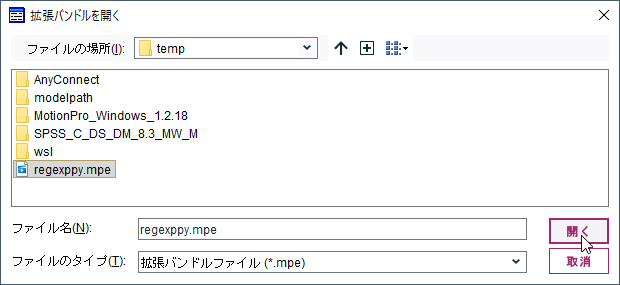
そして、「インストール」ボタンでインストールします。

また、すでにインストールしたカスタムノードを開く場合には「インストールされた項目を開く」で開きます。

修正を行って上書きをする場合には「インストール」ボタンを押し、上書きします。

参照
カスタム・ノードの作成と管理 - IBM Documentation