SPSS Modelerのデータ検査ノードをPythonで書き換えます。データの傾向が一覧でつかめるのでとても人気のあるノードです。目的変数がカテゴリ型が連続型かによって動きが異なるところがありますが、今回は目的変数がカテゴリ型である場合の書き換えを行います。
0.データ
目的変数
Risk:信用リスク
説明変数
Age:年齢
Income:収入ランク
Credit_cards:クレジットカード枚数
Education:学歴
Car_loans:車のローン数
年齢や収入ランクから信用リスクを判定する2値分類のモデルを評価します。
1m.①データ検査 Modeler版
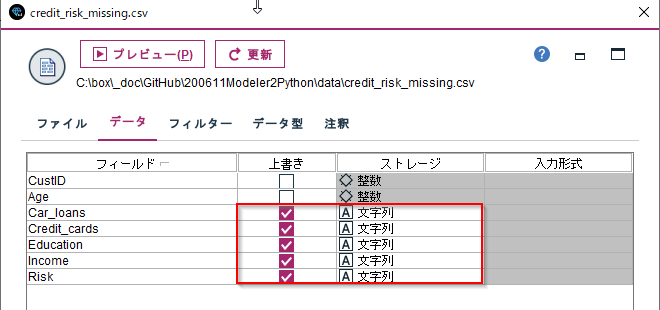
まず、CSVの読み込み時にカテゴリ型のデータを文字列で読み込みます。これはデータに意図的に欠損値や空白データを混入させているためです。Car_loans、Credit_cards、Education、Income、Riskは文字列に上書きしています。
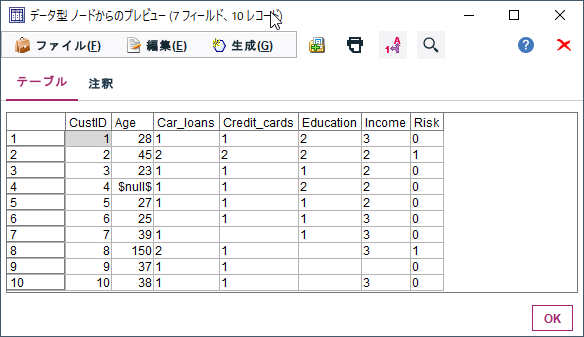
プレビューすると以下のように連続型の欠損値は$null$で表され、カテゴリ型の欠損値は空文字や空白文字で表示されます。
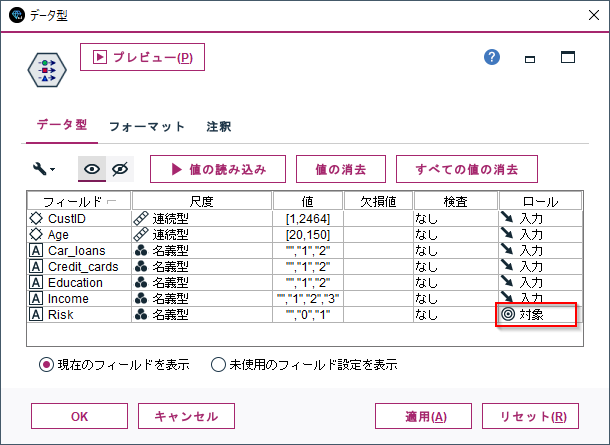
次に、データ型ノードで説明変数、目的変数の定義を行います。
「値の読み込み」ボタンをクリックします。その後、Riskのロールを「対象」(目的変数の意味)を設定します。
後はデータ検査ノードを実行するだけです。
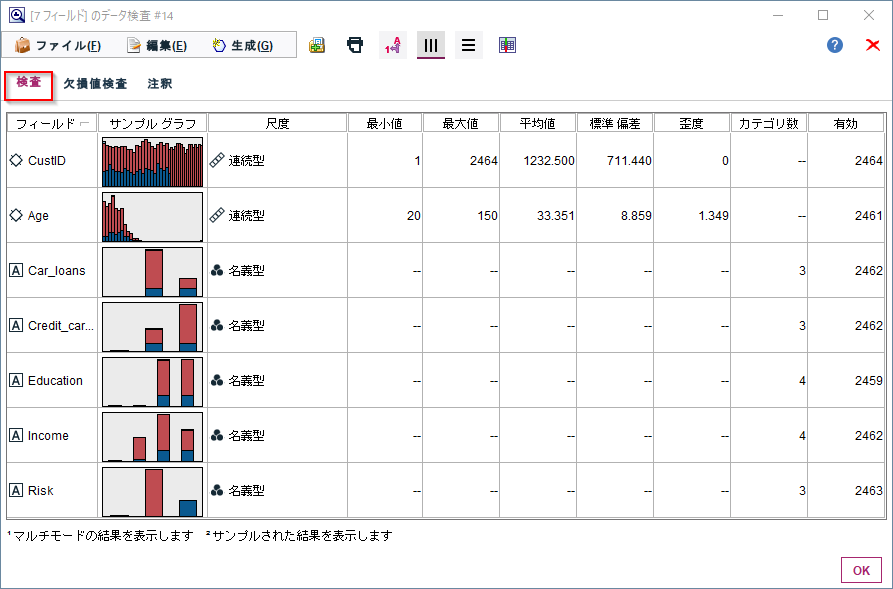
サンプルグラフでは連続型のデータはヒストグラム、カテゴリ型のデータは度数の棒グラフを目的変数のRiskの値を元に色分けしてくれます。このグラフで各変数の分布と目的変数と各説明変数の関係性がぱっと見で把握できるのがとても良いところです。
また、連続型については最小、最大、平均値、標準偏差、歪度が集計されます。
そして、カテゴリ型についてはカテゴリ数が集計されます。
「有効」はNULLや空白値を除いた有効なデータ件数です。
次に欠損値検査タブを見てみます。
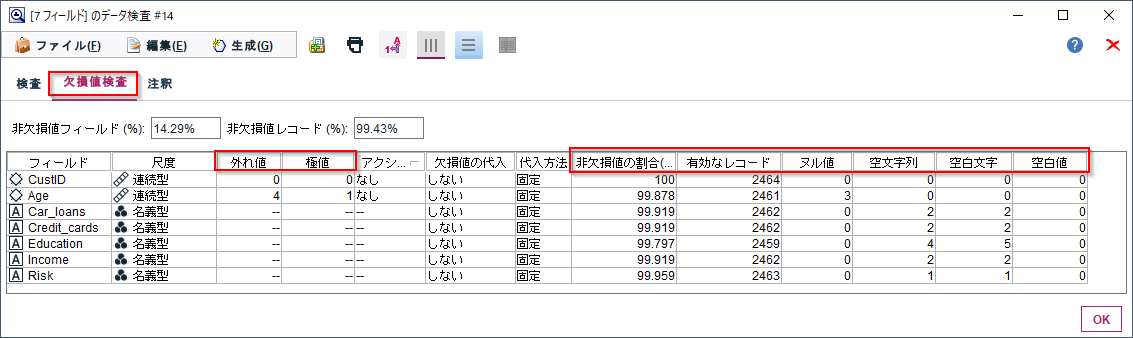
ここでは、連続型については外れ値(3シグマ以上)、極値(5シグマ以上)の件数、ヌル値の件数が出ます。
また、カテゴリ型では、空文字(’’)、空白文字(’ ’)の件数が出ます。なお、空白を別途定義している場合はその件数も出ます。
そして、ヌル値、空文字(’’)、空白文字(’ ’)を除いたレコード数の「有効なレコ―ド」数と「非欠損値の割合」(有効レコード数/全体の件数)が表示されます。
やはり欠損値の状況が一覧で分かりやすく理解できます。
なおこのタブには、今回は取り上げませんが、外れ値や欠損値を補完することもできる機能もついています。
1p.①データ検査 pandas版
設定
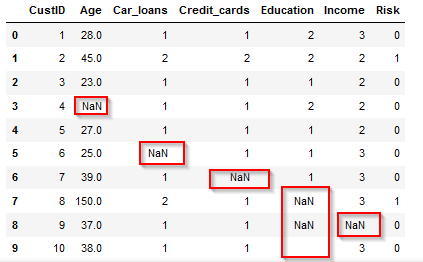
まず、カテゴリ型のデータをCategory型でCSVを読み込みます。
df = pd.read_csv('credit_risk_missing.csv',dtype = {'CustID':'int', 'Age':'float', 'Car_loans':'category','Credit_cards':'category',
'Education':'category','Income':'category','Risk':'category'}
pandasではカテゴリ型もNaNで表示されました。空白文字(9行目のEducation)は空白で表示されます。
- 参考:pandasでデータを読み込むときに気を付けること(dtypeの指定) - Qiita
グラフ表示
まず、複数のグラフを表示するためにnotebookの出力域を拡大します。
%%javascript
IPython.OutputArea.auto_scroll_threshold = 9999;
- 参考:ipython-notebook — ipythonノートブック出力ウィンドウのサイズを変更します
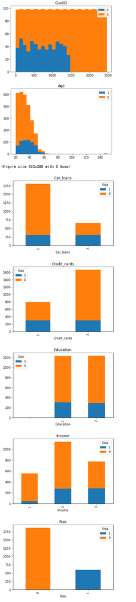
連続型のデータはヒストグラム、カテゴリ型のデータは度数の棒グラフを目的変数のRiskの値を元に色分けして表示します。
df[col].dtype.nameでCatagory型や連続型を判定しています。
連続型はたくさんの型がありうるので正規表現re.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']をつかって判定しています。
棒グラフとヒストグラムの書き方は以下の記事も参考にしてください。
import re
targetcol='Risk'
for col in df.columns:
if df[col].dtype.name=='category':
dfcross=pd.crosstab(df[col],df[targetcol])
dfcross=dfcross.reindex(['1','0'],axis="columns")
dfcross.plot.bar(stacked=True,title=col)
elif re.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']:
nums=[]
targets=df[targetcol].cat.categories.sort_values (ascending=False)
for i,target in enumerate(targets):
nums.append(df.query(targetcol+'==\'{0}\''.format(target))[col])
plt.title(col)
plt.hist(nums,bins=25, stacked=True,label=targets.astype('str'))
plt.legend()
plt.figure()
- 参考:python - Check if dataframe column is Categorical - Stack Overflow
- 参考:Python で文字列から数字を削除する | Delft スタック
列の要約
連続型変数については最小、最大、平均値、標準偏差はdescribe()で計算できます。
df.describe()
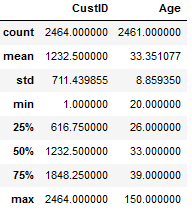
Modelerと違って4分位のパーセンタイル値がでるのは便利です。ただし、歪度は別途計算する必要があります。
歪度はskew()で計算します。カテゴリ型の列についても、値としてはほとんど参考にはなりませんが、計算されています。
df.skew()

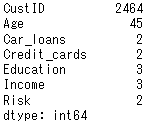
カテゴリ型変数についてカテゴリ数を計算してみます。連続型の変数についてもカウントされています。Modelerは空文字をカテゴリとしてカウントしていますが、nunique()は空文字はNullとして無視していますので、Modelerのカテゴリ数とは異なります。後程欠損値のところで詳しく解説します。
df.nunique()
- 参考:pandasで歪度(Skewness)と尖度(Kurtosis)を計算 - Qiita
外れ値、極値
Modelerでは外れ値を3シグマ以上、極値を5シグマ以上で計算しているので同様に計算します。数値列だけが対象になるのでre.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']で判定しています。
件数は式.sum()で計算しています。
数値列だけが対象になるので、データフレームの件数は可変です。そのため、Seriesオブジェクトをつくってからappendしています。
df1 = pd.DataFrame(index=[], columns=['外れ値','極値'])
for col in df.columns:
if re.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']:
limit_low3=df[col].mean()-df[col].std()*3
limit_high3=df[col].mean()+df[col].std()*3
limit_low5=df[col].mean()-df[col].std()*5
limit_high5=df[col].mean()+df[col].std()*5
hazurechi=((df[col] <limit_low3)|(df[col] >limit_high3)).sum()
kyokuchi=((df[col] <limit_low5)|(df[col] >limit_high5)).sum()
df1=df1.append(pd.Series([hazurechi-kyokuchi,kyokuchi],index=df1.columns,name=col))
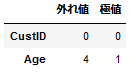
- 参考:Python初心者向け:四分位数/標準偏差を用いた外れ値の除外 | happy analysis
- 参考:Pandasにて条件にあったカウント(count)を行う方法【value_countsの使い方など】 | ウルトラフリーダム
- 参考:Pythonで、空のDataFrameにindexとセットで1行追加する | ITを使っていこう
欠損値
欠損値はisnull().sum()で数えることができます。
df.isnull().sum()

しかしながら、Modelerとは欠損値の考え方が違っているのでカウント数が異なります。
- Modelerはデータが存在しない場合、連続値についてはNULL値としてカウントし、カテゴリ型については空文字としてカウントします。pandas(というかnumpy)は空文字もNULLとして扱います。
- Modelerは’ ’のような空白文字は欠損値として扱います。pandasはデータとして扱います。
上のModelerの仕様と同じようにpandasで欠損値を計算するには以下のようになります。
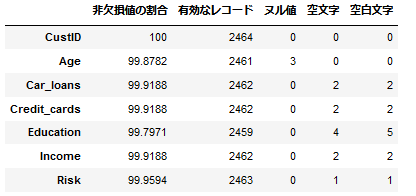
空白文字はdf[col].str.match(r'^ +$'))).sum()というように正規表現でカウントしています。
# 欠損値2
colnames=['非欠損値の割合','有効なレコード','ヌル値','空文字','空白文字']
dfcol=pd.DataFrame(index=df.columns,columns=colnames)
# ヌル
for i,col in enumerate(dfcol.index):
if df[col].dtype.name=='category':
dfcol.iloc[i,colnames.index('ヌル値')]=0
elif re.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']:
dfcol.iloc[i,colnames.index('ヌル値')]=df[col].isnull().sum()
# 空文字列
for i,col in enumerate(dfcol.index):
if df[col].dtype.name=='category':
dfcol.iloc[i,colnames.index('空文字')]=df[col].isnull().sum()
elif re.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']:
dfcol.iloc[i,colnames.index('空文字')]=0
# 空白文字
for i,col in enumerate(dfcol.index):
if df[col].dtype.name=='category':
dfcol.iloc[i,colnames.index('空白文字')]=((df[col].str.match(r'^ +$'))).sum()+dfcol.iloc[i,colnames.index('空文字')]
elif re.sub(r'[0-9]+', '', df[col].dtype.name) in ['int','float']:
dfcol.iloc[i,colnames.index('空白文字')]=0
# 有効なレコード
dfcol['有効なレコード']=len(df)-(dfcol['ヌル値']+dfcol['空白文字'])
dfcol['非欠損値の割合']=dfcol['有効なレコード']/len(df)*100```
5. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/blob/master/dataaudit/dataaudit.str?raw=true
notebook
https://github.com/hkwd/200611Modeler2Python/tree/master/dataaudit/dataaudit.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/credit_risk_missing.csv
■テスト環境
Modeler 18.3
Windows 10 64bit
Python 3.8.10
pandas 1.0.5
6. 参考情報
データ検査ノード