様々な車のスペック情報をSPSS Modelerで分析して、どんなスペックが燃費に影響するかを分析してみたいと思います。
データと完成版サンプルストリームは以下のzipファイルに入っています。
https://github.com/hkwd/200603AutodataAnalysis/archive/master.zip
データ:cars_data_j.csv
ストリーム:燃費分析2.str
1. データ
UCI: Automobile Data Setを使います。
https://dataplatform.cloud.ibm.com/exchange/public/entry/view/9704374ab42cdd449b6112a0981dfbe1#
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
元データは英語だったので、日本語に翻訳したデータcars_data_j.csvを準備しました。
キャンバスにドラッグアンドドロップしておいてください。

右クリックして、データをプレビューします。

先頭10件のデータが表示されます。
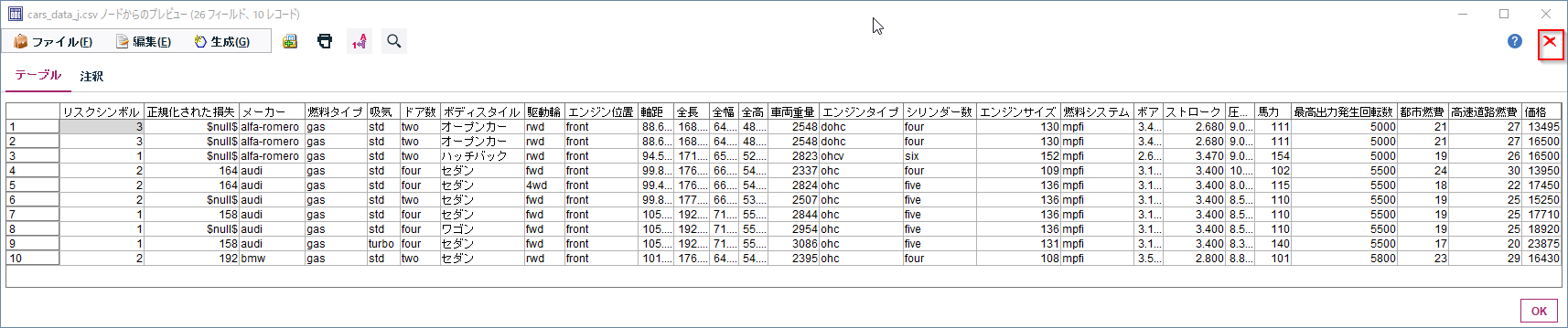
もともとが自動車保険のデータなので、リスクや損失などの情報が最初の2列にあります。
そのほか、メーカー名や燃料タイプ、エンジンの位置、などの車のスペック情報が続き、最後に都市燃費、高速道路燃費、価格があります。
今回はこの都市燃費と燃料タイプなどの車のスペックとの関係を分析したいと思います。
右上の赤い×ボタンで閉じてください。
2. 相関の高いデータ項目を探す。
都市燃費と関係がある車のスペックはどんなものがあるかを調べてみます。都市燃費はマイル/ガロンの数値データです。数値データ同士の関係を調べる指標の一つとして相関係数があります。相関係数は-1から1の値をとり、数値データ同士に線形の関係がある場合-1や1に近づきます。例えば年齢が高いと年収も高いというような関係は相関の高いデータです。
SPSSではいくつかの方法で相関係数を調べられますが、ここではデータ検査ノードを使って調べたいと思います。
フィールド設定のパレットからデータ型ノードを選び、cars_data_j.csvにつなぎ、ダブルクリックでプロパティを開きます。

値の読み込みボタンをクリックします。都市燃費のロールを対象としてください。設定ができたらOKボタンで閉じます。

出力パレットからデータ検査ノードを選びデータ型ノードに接続して、データ型ノードを選んだ状態で選択内容を実行ボタンを押してください。
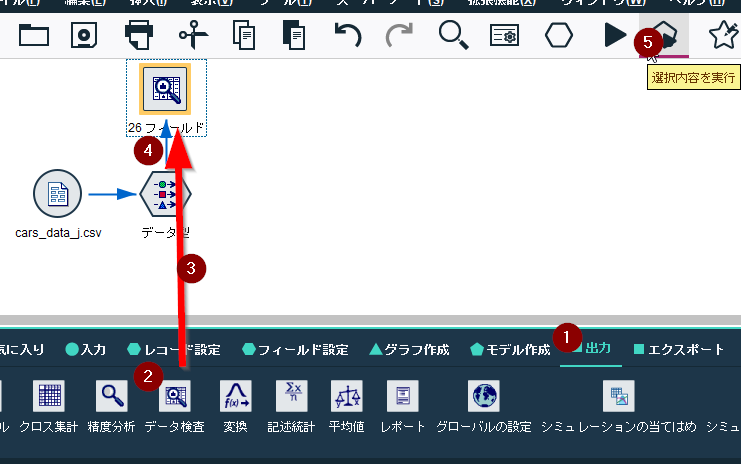
相関T有意確率を昇順でソートして、少し下にスクロールすると都市燃費と相関の高いフィールドが表示されます。
いちばん相関が高いのは高速道路燃費です。相関係数は0.972です。都市燃費のいい車は高速道路燃費もよいということです。ただ、これは当たり前すぎて意味があまりない項目です。
次に相関が高いのは馬力です。この相関係数は-0.823です。マイナスの値なので負の相関があります。馬力が下がると燃費が良くなるということになります。
次いで、車両重量、価格、全長などが相関が高い項目になります。
ここでは都市燃費と馬力の相関を散布図をつかって確認します。馬力のグラフをタブルクリックしてください。

確かに馬力が低いと燃費が良くなる傾向が見えます。
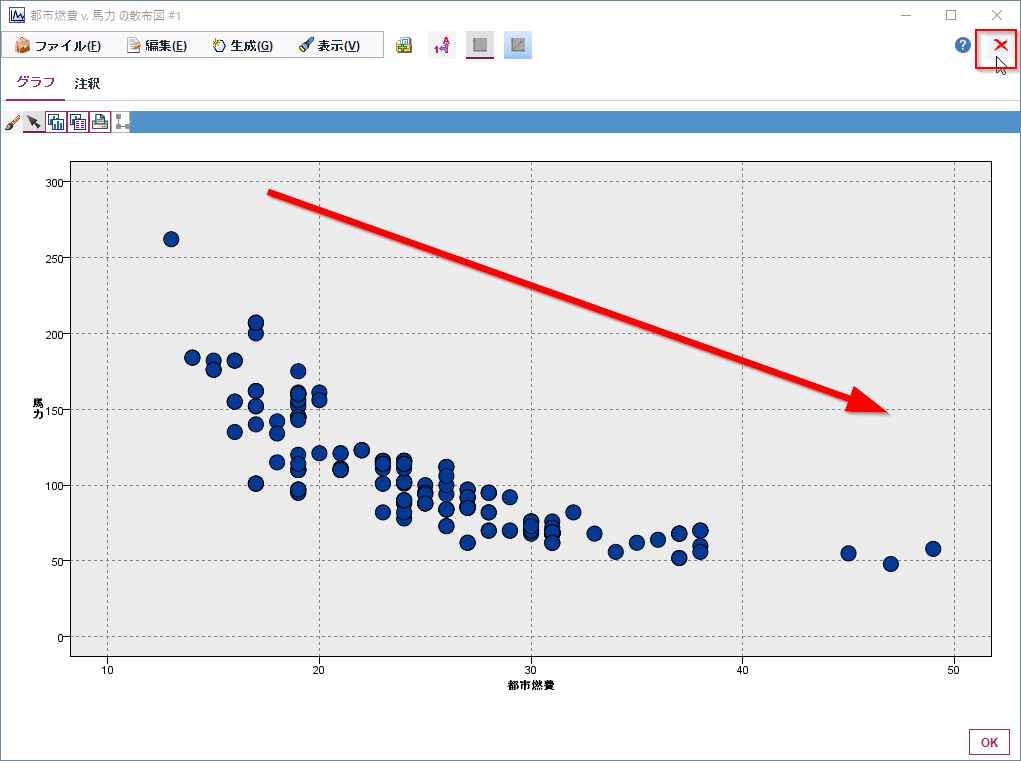
確認ができたら赤い×ボタンで閉じてください。
グラフの保存の確認には「いいえ」で閉じてください。

データ検査ノードも赤い×ボタンで閉じてください。

3. 単回帰分析
次に馬力と都市燃費の関係を線形の式で表現してみたいと思います。これは単回帰分析という手法です。
フィールド設定パレットからデータ型ノードを選び、先ほど置いたデータ型ノードの後ろに連結し、ダブルクリックしてプロパティを開いてください。

馬力以外と都市燃費以外のフィールドのロールを「なし」に設定してください。
これは馬力を説明変数、都市燃費を目的変数として設定することを意味しています。
設定ができたらOKで閉じてください。

モデル作成パレットから線形回帰ノードを選び、2個目のデータ型ノードに接続します。線形回帰ノードの名前が都市燃費になることを確認して、選択した状態で、選択内容を実行ボタンを押します。

黄色のナゲットが作成されますので、以下のように場所を少し動かして、これをダブルクリックして内容を確認します。

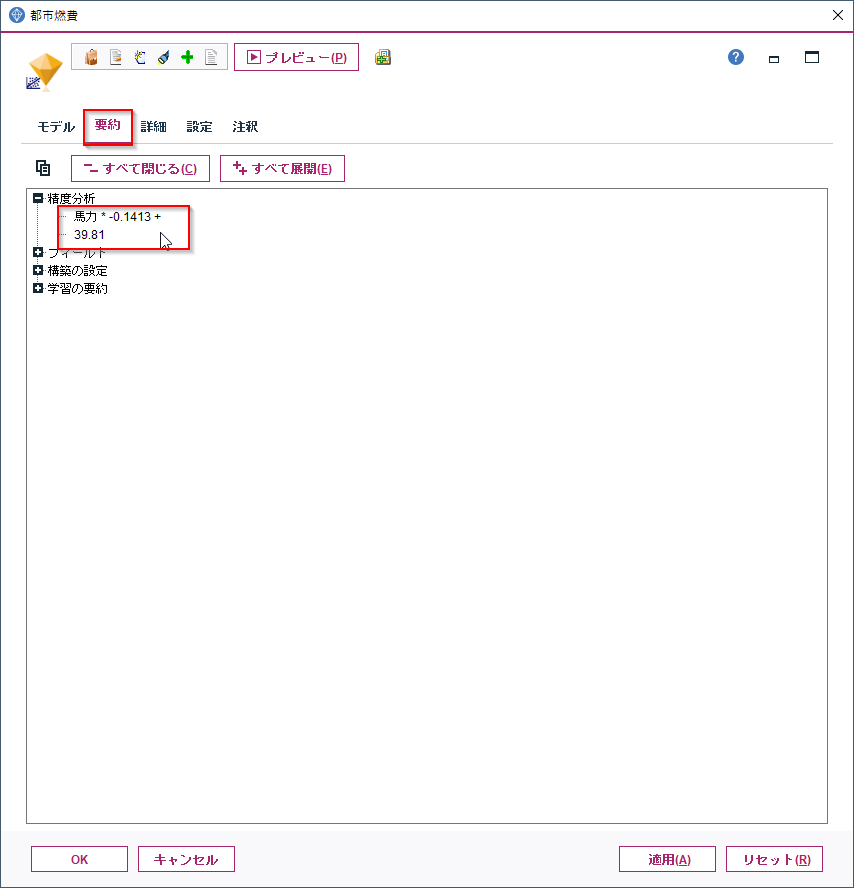
要約のタブを開くと、
「馬力*-0.1413+39.81」
という式ができています。これは切片が39.81で馬力が1上がるごとに燃費が-0.1413悪くなるということを示しています。
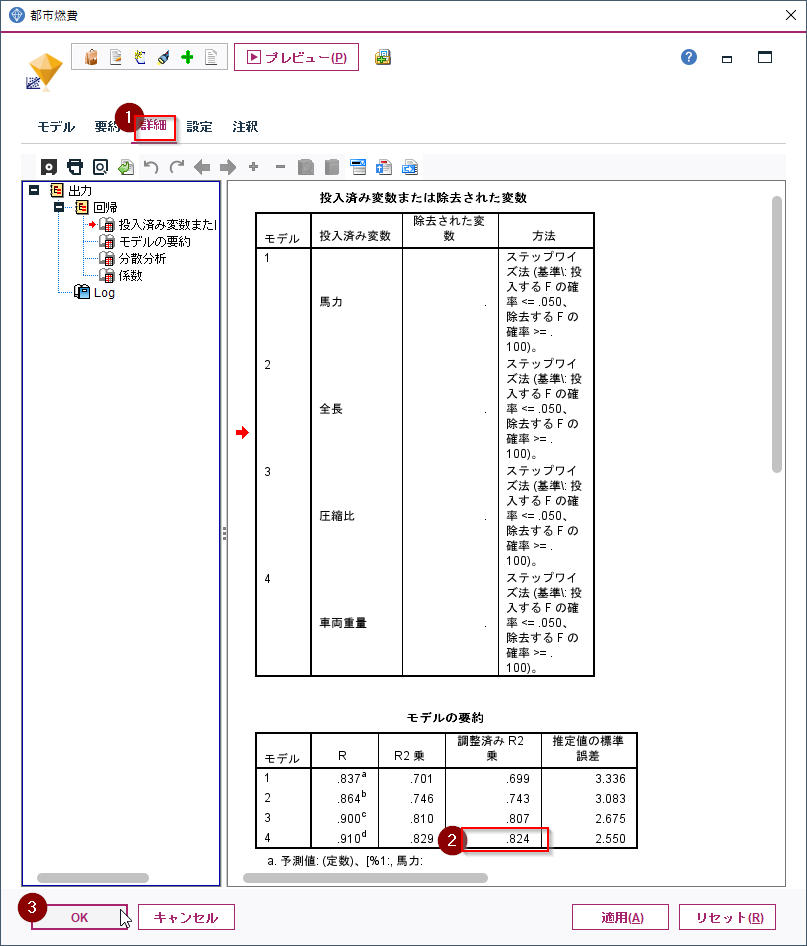
詳細のタブを開くと統計情報が表示されます。
調整済みR2乗という値が馬力で都市燃費をどのくらい説明できているかを表していて、回帰モデルの良さの指標になります。1に近いほどよく説明できることを意味しています。

確認したらOKで閉じて下さい。
出力パレットからテーブルノードを選び都市燃費のナゲットの後ろに接続して、選択内容を実行ボタンを押してください。

いちばん後ろの列に$E-都市燃費という列が追加されています。これが「馬力*-0.1413+39.81」という回帰式による計算結果です。「都市燃費」が実際の「都市燃費」です。ある程度似た値になっているのがわかると思います。

どのくらい当たっているのかを散布図をつかって確認してみます。
グラフ作成パレットから散布図ノードを選び都市燃費のナゲットに接続し、ダブルクリックでプロパティを開きます。

Xフィールドに都市燃費、Yフィールドに$E-都市燃費を設定し、実行ボタンを押してください。

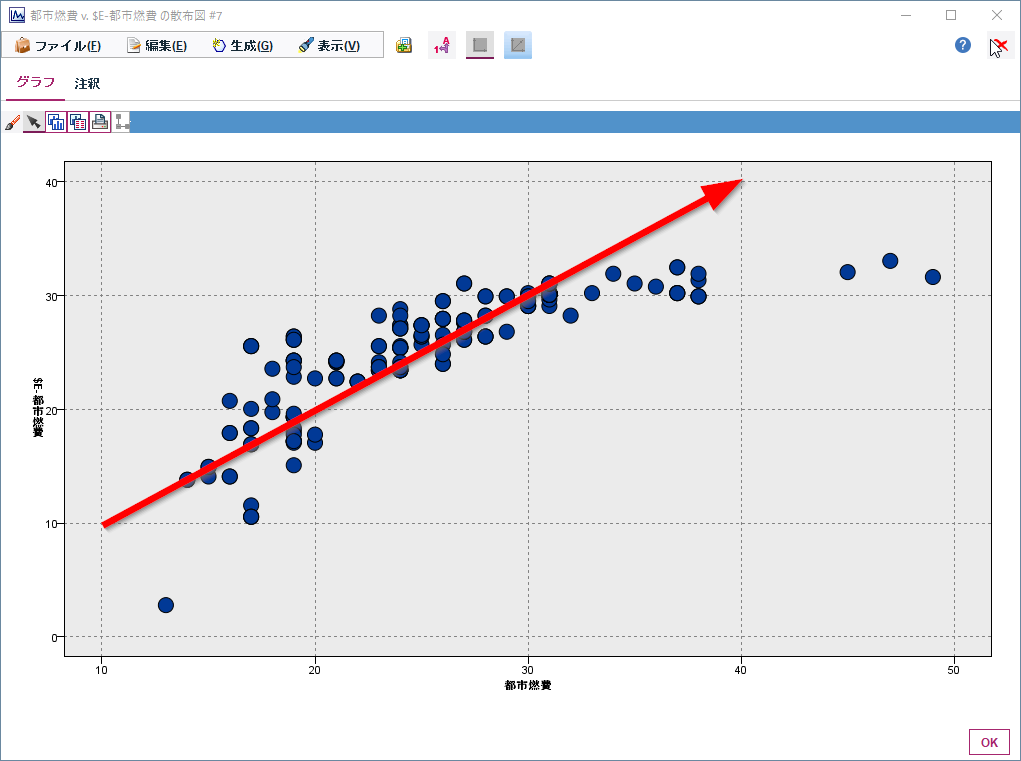
完全に回帰式で表現できていれば対角線上にプロットされることになります。都市燃費が10-30くらいの間は比較的当たっている一方で、30以上はあまり当たっていないことがわかります。
3. 重回帰分析
単回帰分析では馬力の値のみをつかって都市燃費を計算する式をつくりました。今度は他のフィールド(説明変数)も使って都市燃費を計算する式を作ってみたいと思います。複数の説明変数をつかった回帰分析を重回帰分析といいます。より多くの情報をつかって表現するので精度を高めることが期待できます。
二つあるデータ型ノードの最初のデータ型ノードをタブルクリックしてプロパティを開きます。

高速道路燃費のロールを「なし」に設定します。これは高速道路燃費から都市燃費が計算できてもあまり意味がないと考えるためです。ロールをなしにすると回帰の計算式に含めないことができます。設定ができたらOKで閉じてください。
モデル作成パレットから線形回帰ノードを選び、1個目のデータ型ノードに接続します。線形回帰ノードの名前が都市燃費になることを確認して、ダブルクリックでプロパティを開きます。

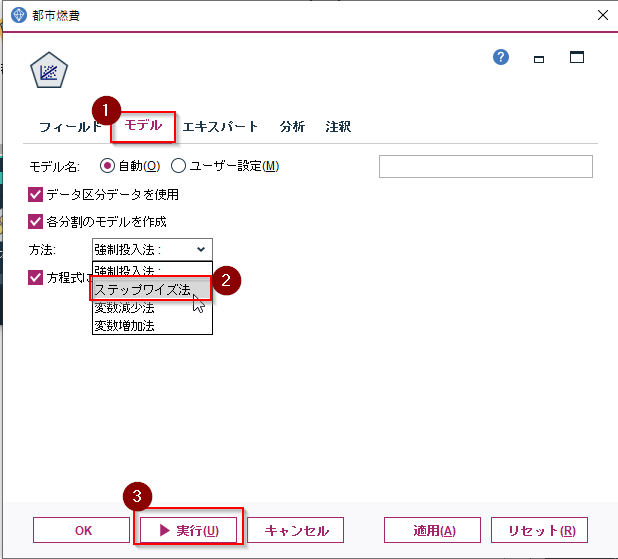
モデルタブで、方法に「ステップワイズ法」を選択します。これはたくさんの説明変数の中から有効性の高いものを自動選択してくれる方法になります。設定ができたら実行ボタンを押してください。
黄色のナゲットが作成されますので、これをダブルクリックして内容を確認します。
要約タブをクリックすると
全長 * -0.1283 +
車両重量 * -0.00478 +
圧縮比 * 0.5629 +
馬力 * -0.06316 +
60.72
という式が作成されています。今度は馬力以外にも全長や車両重量が増えても都市燃費が下がる一方で、圧縮比が増えると都市燃費が良くなるという式ができています。
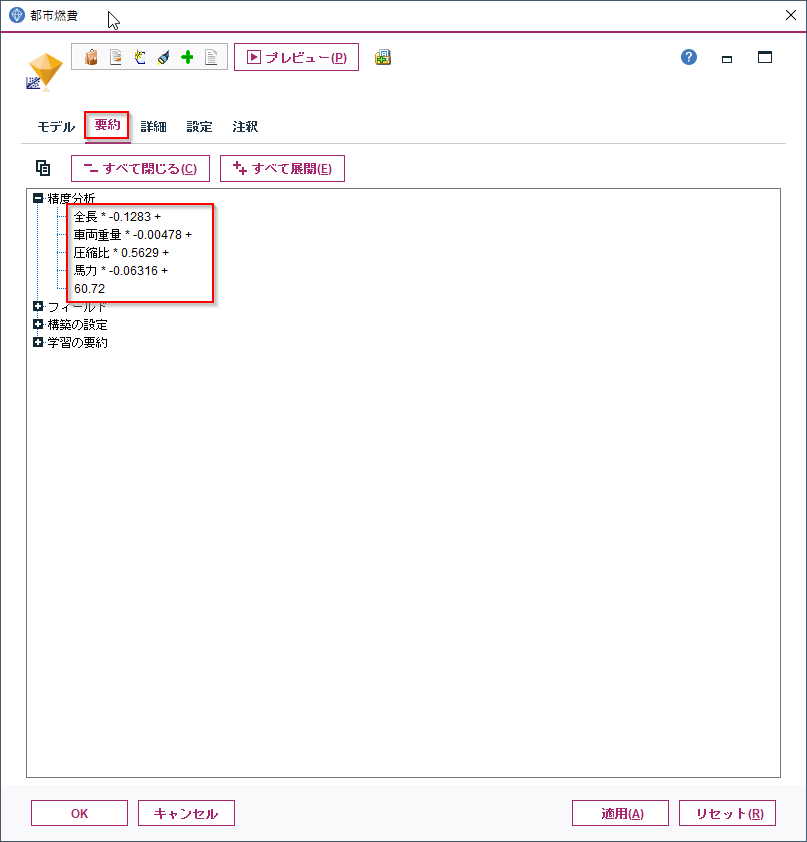
詳細タブに移ってください。今回内部的には4つのモデル(式)を作っていました。そして馬力、全長、圧縮比、車両重量の4つの説明変数をつかった式が採用されています。その調整済みR2乗は.824ですので、先ほどの単回帰の式よりも性能が向上していることがわかります。
確認ができたら赤い×ボタンで閉じてください。
先ほど作った都市燃費と$E-都市燃費を比べる散布図を右クリックしてコピーします。

キャンバスの空いているところで右クリックで貼り付けてください。
散布図を重回帰式をつくった新しい都市燃費のナゲットに接続し、選択内容を実行ボタンを押してください。

単回帰の式よりもよりあたりが良くなっていることが散布図からも分かります。

確認できたら、赤い×ボタンで閉じてください。
4. カテゴリー値との関係確認
ここまで車のスペックの馬力などの数値データと都市燃費の関係を見てきました。しかし、このデータにはメーカーや駆動輪などのカテゴリデータも存在しています。これらのカテゴリデータと都市燃費には関係があるのでしょうか。
それを簡単に見つける方法として、特徴量選択ノードが利用できます。
モデル作成パレットから、特徴量選択ノードを選び、一つ目のデータ型ノードと接続します。そして特徴量選択ノードが都市燃費という名前に変わったら、そのノードを選択してから、選択内容を実行ボタンを押してください。

黄色のナゲットが作成されますので、これをダブルクリックして内容を確認します。
駆動輪や燃料システム、シリンダー数などがカテゴリー値の中では重要な変数として選ばれていることがわかります。ちなみに重要として判断は分散分析という手法で行われています。駆動輪のカテゴリーであるFWD、RWD、4WDのカテゴリーで都市燃費の値の傾向に違いがみられることを発見しています。
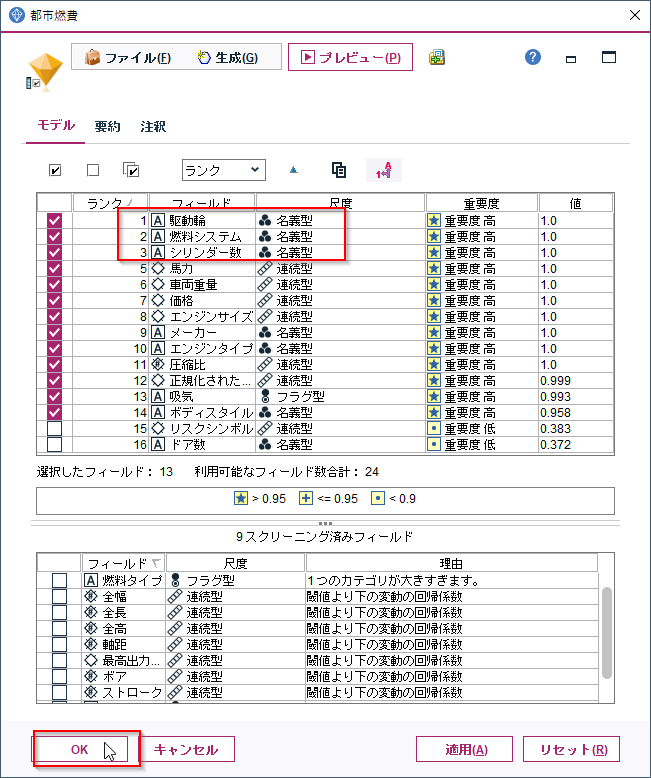
確認ができたらOKで閉じてください。
では、各駆動輪のカテゴリーで都市燃費どう異なっているのかをヒストグラムで確認してみます。
グラフ作成パレットから、ヒストグラムノードを選び、一つ目のデータ型ノードに接続します。そしてヒストグラムノードをタブルクリックしてプロパティを編集します。
フィールドに都市燃費、オーバーレイの色に駆動輪を設定し、実行ボタンを押してください。

確かに青のRWDは燃費が悪く、赤のFWDは燃費が良く、4WDはその中間であることがわかります。

4. カテゴリー値を含めた重回帰分析
ではこの駆動輪のデータもつかって、重回帰の式をつくってみます。回帰分析は原則的には数値データしか扱えませんので、カテゴリー値はダミー変数として0,1のデータに変換します。
フィールド作成パレットから、フラグ設定ノードを選び、1つ目のデータ型ノードに接続します。そして、ダブルクリックでプロパティを開きます。

セット型フィールドに駆動輪を選びます。すると利用可能なセット値に4wd,fwd,rwdが現れますので、ここから4wdとfwdを選び黄色のボタンを押して、「フラグ型フィールドを作成」のボックスに設定します。
それから真の値を1、偽の値を0に設定し、OKで閉じてください。

フラグ作成ノードを右クリックしてプレビューを見てみます。
駆動輪がfwdであれば駆動輪_fwdが1になり、駆動輪が4wdであれば駆動輪_4wdが1になり、駆動輪がrwdであれば駆動輪_fwdと駆動輪_4wdがどちらも0で設定されています。
これで駆動輪のカテゴリー値を数値として表現することができました。
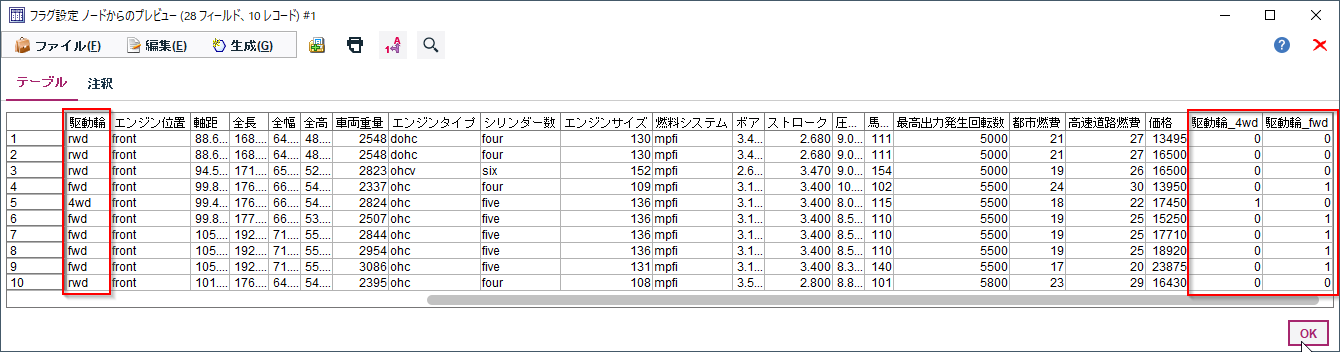
確認ができたらOKで閉じてください。
モデル作成パレットから線形回帰ノードを選び、フラグ設定ノードに接続します。線形回帰ノードの名前が都市燃費になることを確認して、ダブルクリックでプロパティを開きます。

モデルタブで、方法に「ステップワイズ法」を選択します。設定ができたら実行ボタンを押してください。
黄色のナゲットが作成されますので、これをダブルクリックして内容を確認します。

要約タブをクリックすると
全長 * -0.144 +
車両重量 * -0.003857 +
圧縮比 * 0.5213 +
馬力 * -0.07255 +
駆動輪_4wd * -2.285 +
62.6
という式が作成されています。先ほどの重回帰式に比較して、駆動輪が4wdの場合は都市燃費が2.285さがるという式ができています。

詳細タブに移ってください。今回内部的には5つのモデル(式)を作っていました。そして馬力、全長、圧縮比、車両重量、駆動輪_4wdの5つの説明変数をつかった式が採用されています。その調整済みR2乗は.829ですので、先ほどの重回帰の式(.824)よりも性能が若干ながら向上していることがわかります。

確認ができたら赤い×ボタンで閉じてください。
5. まとめ
今回は様々な車のスペック情報から馬力、全長、圧縮比、車両重量、駆動輪などが都市燃費に影響していて、それを線形の式で表現すると
全長 * -0.144 +
車両重量 * -0.003857 +
圧縮比 * 0.5213 +
馬力 * -0.07255 +
駆動輪_4wd * -2.285 +
62.6
になることがわかりました。
これにより、都市燃費が不明な車や設計段階の車でも、馬力などスペック情報からどのくらいの燃費になることを予測することもできるようになります。