5−18 K-Meansノード[モデル作成タブ]

1.ノードの目的
クラスターモデルを作成します。クラスタ数(k)を指定する必要があります。
顧客行動や設備挙動から類似グループを作成します。
2.解説動画(60秒)
3.クイックスタート
顧客の属性と部門別購入金額でクラスターモデルを作ります。
*サンプルデータ(CSV)は[5.参考情報]からダウンロードできます。
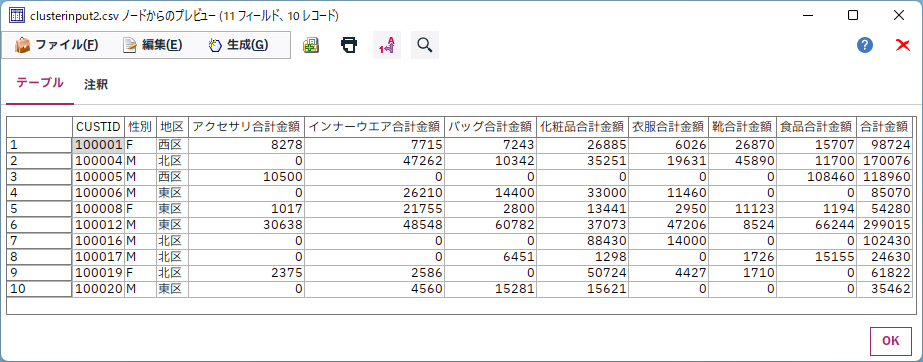
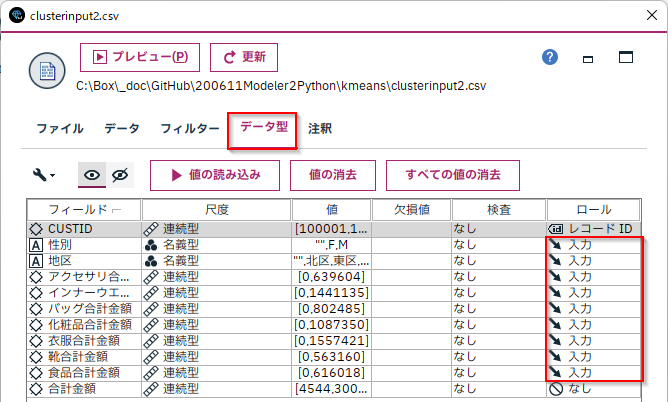
[可変長ファイル]ノードを編集します。[データ型]タブでクラスタモデルに投入するフィールドを確定します。性別から食品の9つのフィールドを[入力]しにます。
[可変長ファイル]ノードから[K-Means]ノードに接続します。
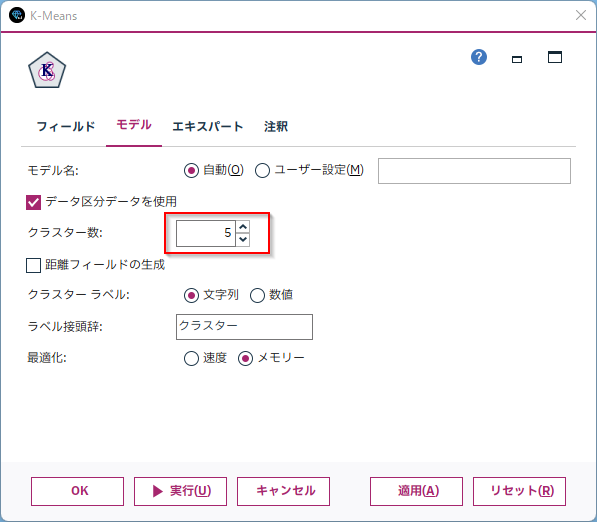
[K-Means]を接続して設定を確認し、実行します。「クラスター数」で指定した数にデータをクラスタリングします。ここではデフォルトの5のままとします。このクラスター数のことをkといいます。
[K-Means]を実行してテーブルを接続します。
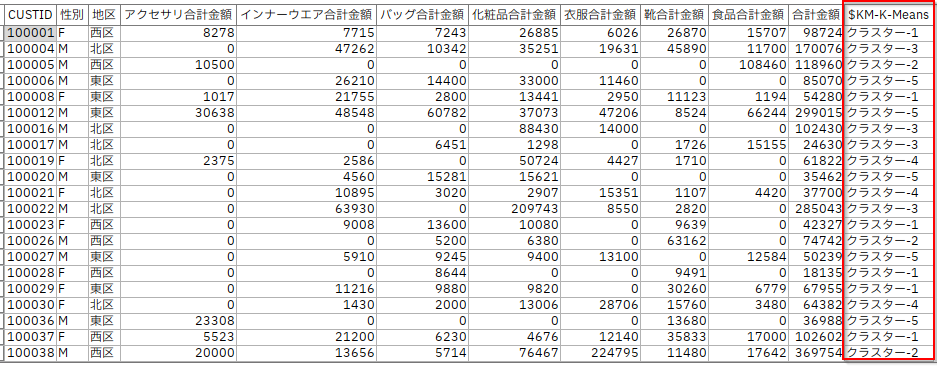
[テーブル]を実行します。クラスタ列が追加され、属性と購入の類似性で顧客を分類しています。
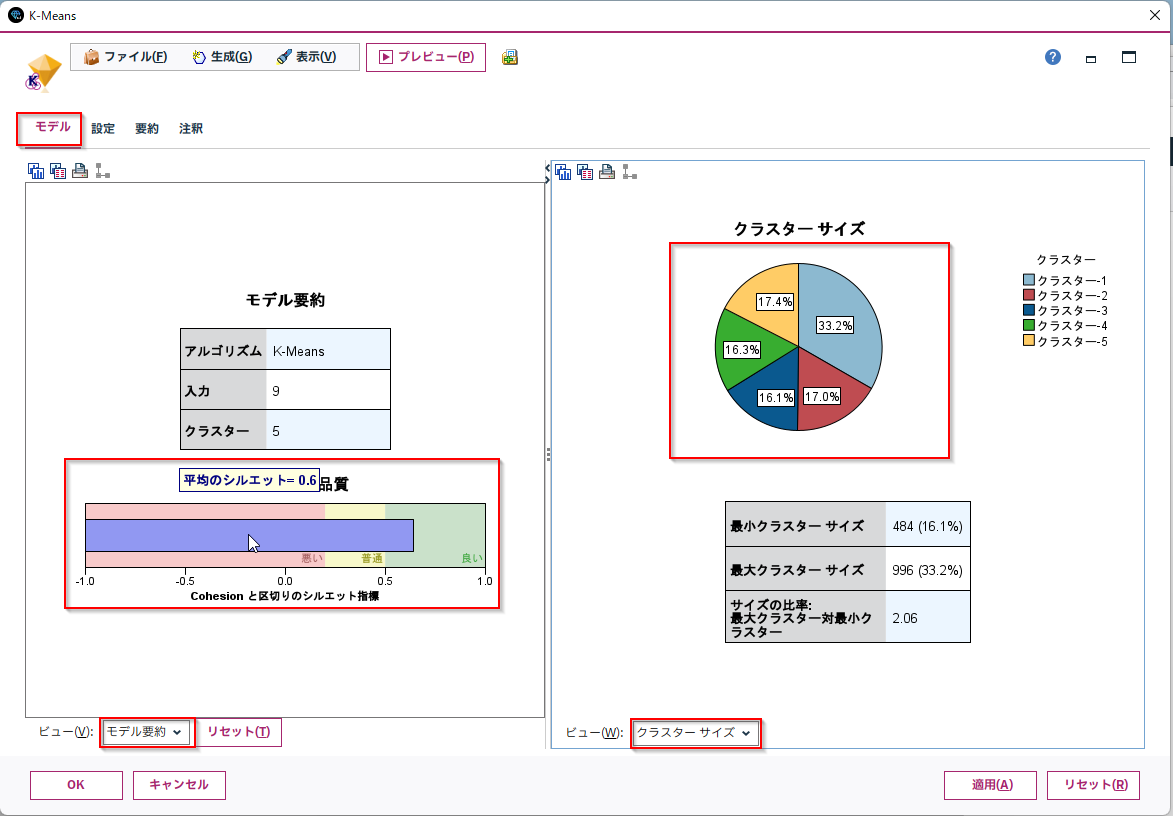
モデルをダブルクリックで開くと、モデルの性能指標やクラスター解釈のための情報を見ることができます。
「クラスターサイズ」ビューでは、分割したクラスターの大きさを確認できます。大きすぎるクラスターや小さすぎるクラスターがないかをチェックします。
「モデル要約」には、クラスター品質の指標であるシルエット係数の平均値が出ています。クラスター同士が十分に離れているかの指標になります。
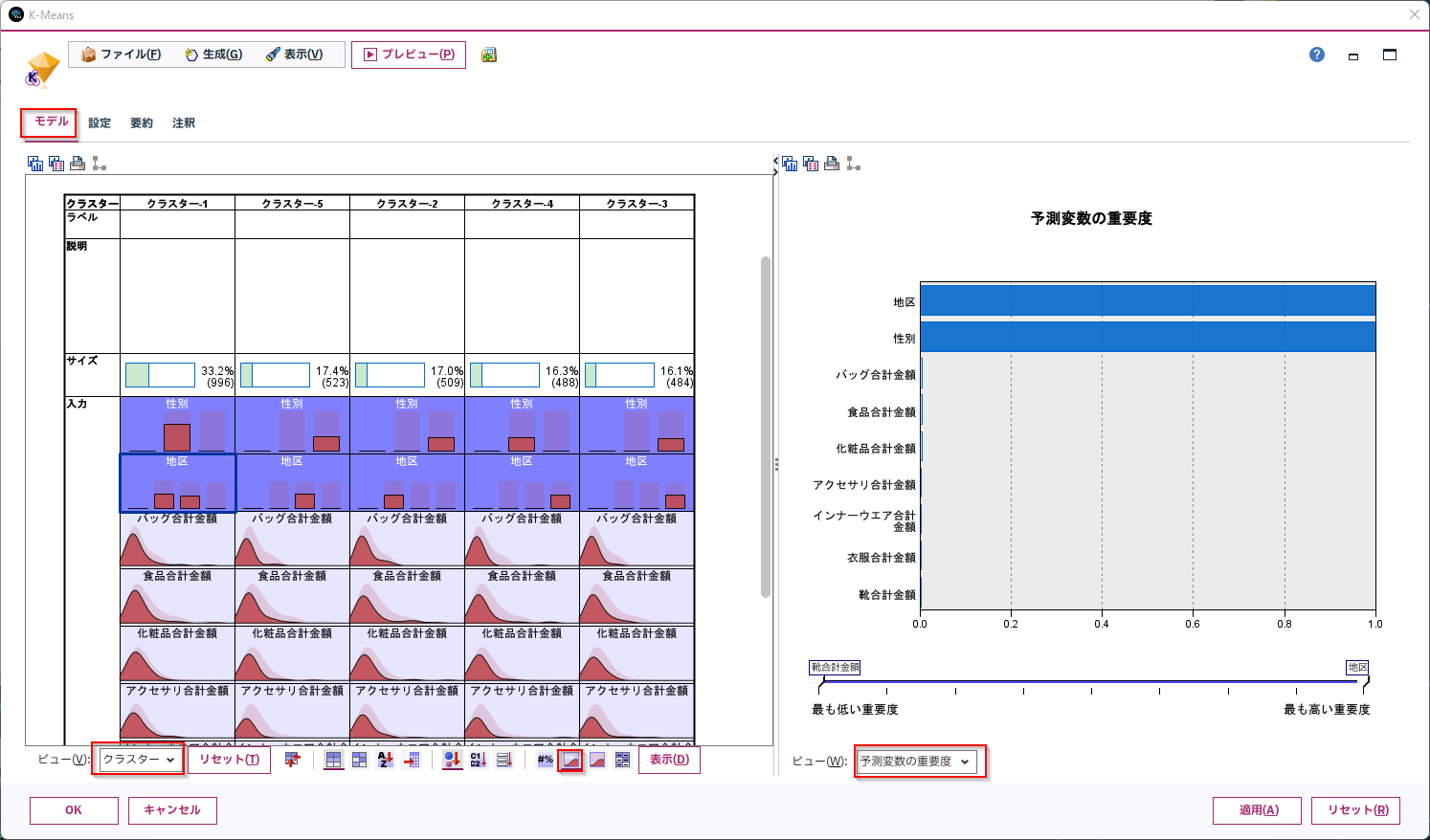
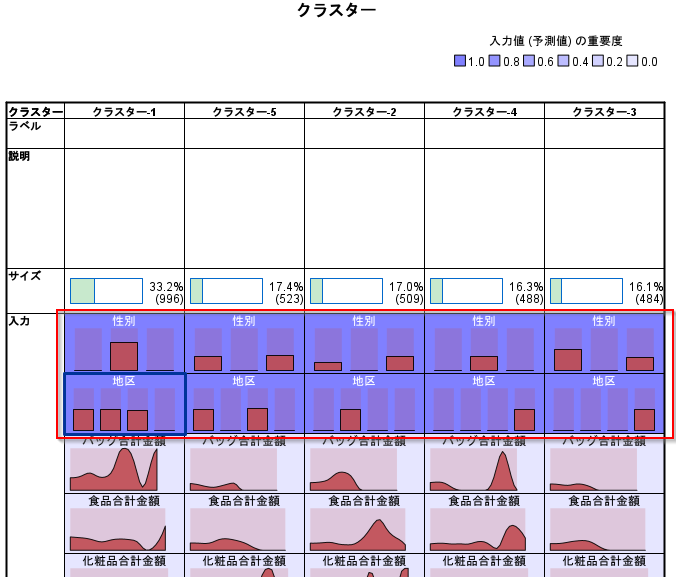
「クラスター」ビューでは、各クラスターでの変数の分布を確認できます。
「予測変数の重要度」ビューでは、クラスターを分割する際に影響の大きい変数を表示することができます。
この指標はpythonのライブラリーなどは見当たりませんでしたが、非常に便利な機能です。
- 参考
- シルエット分析 | technical-note
4.Tips
説明しやすいクラスターの作成と解釈
クラスター分析は異常検知のように小さなクラスターを探す場合を除くと、多くの場合、施策の出しわけに利用されます。人間が理解しやすく、施策が考えやすい特徴がでる特徴量を工夫します。
今回のモデルでは性別2種と地区3種=6に分割できてしまい(正確には欠損値もあります)、最終的には男性の西区と東区はまとめられたので5(=k)に分割されました。しかし、購入の特徴はまったく反映できておらず、施策を考えにくいため、作り直します。
代表的な方法に比率や偏差を利用する方法があります。
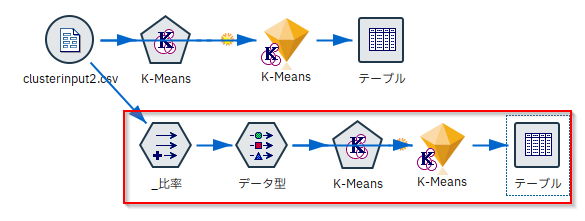
[フィールド作成]ノードで比率フィールドを作成します。
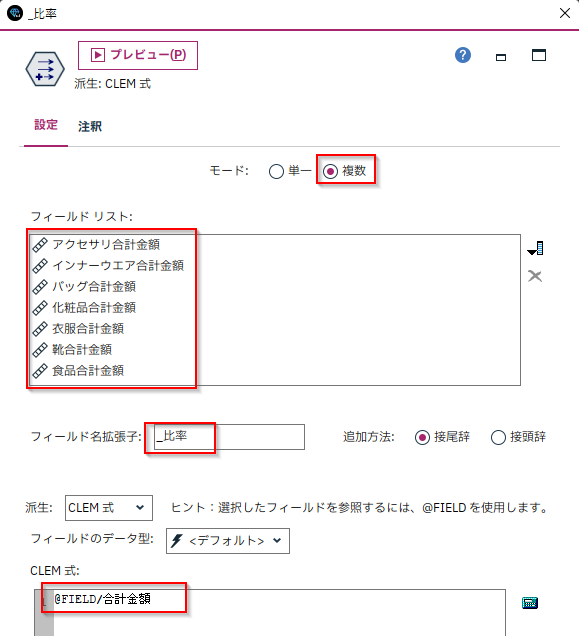
顧客毎の合計金額から部門別に按分した7つの比率フィールドが作られました。

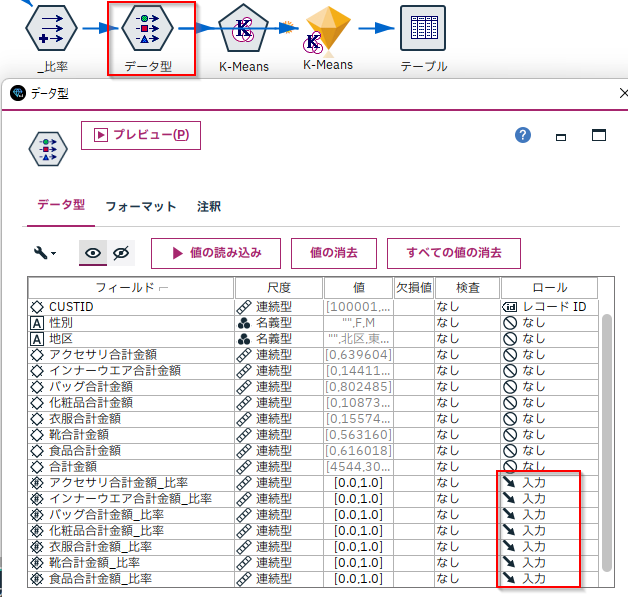
[データ型]ノードで比率フィールドをクラスターモデルの入力にします。
[K-Means]ノードを実行してモデルナゲットをダブルクリックします。
クラスタービューの「絶対分布」をみると各クラスターで商品購入比率の多い層の特徴が出ています。例えばクラスター4にはインナーウェアの購入比率が多い人が集まっています。
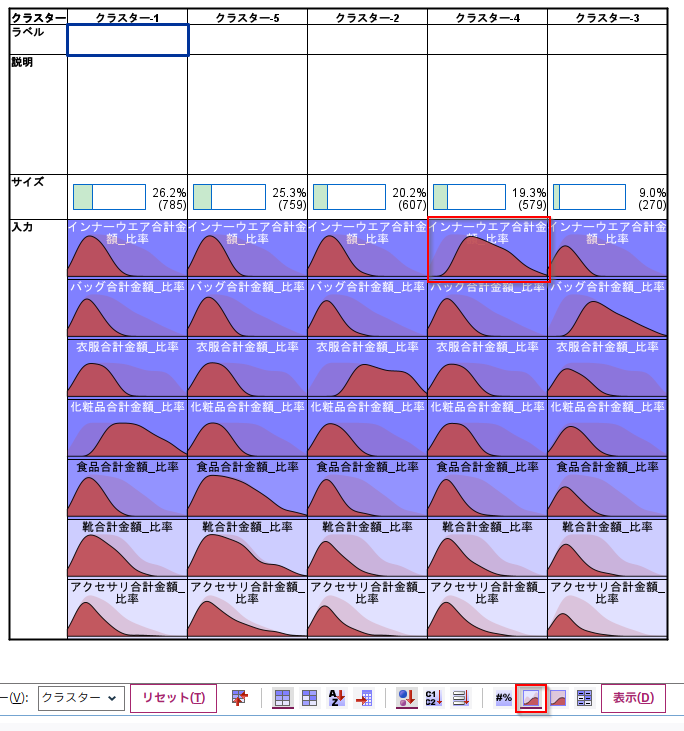
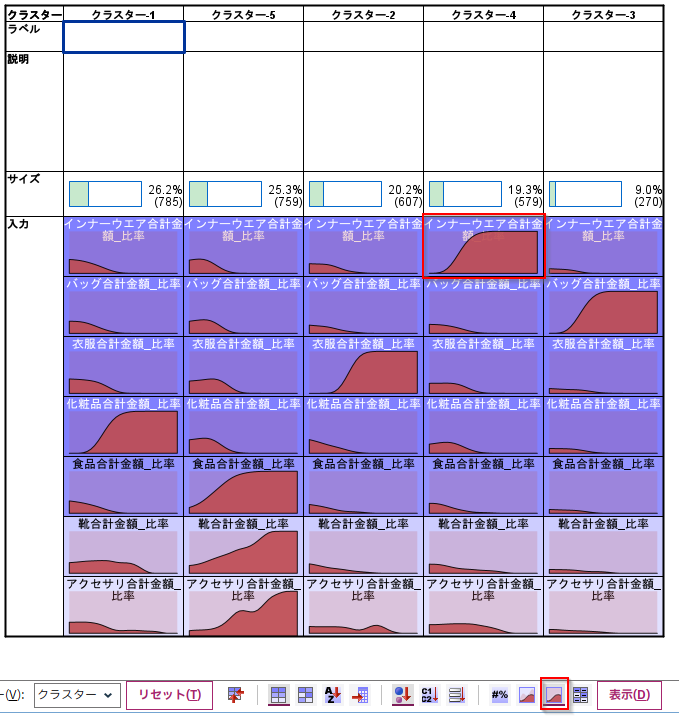
クラスタービューの「相対分布」をみるとこの特徴をより強調して確認することができます。
「相対分布」ではビニングした階級ごとにそのクラスターが占める割合が表示されます。この例だとインナーウェアの購入比率が5割を超える人たちは、クラスター4に100%集中しているということが読めます。
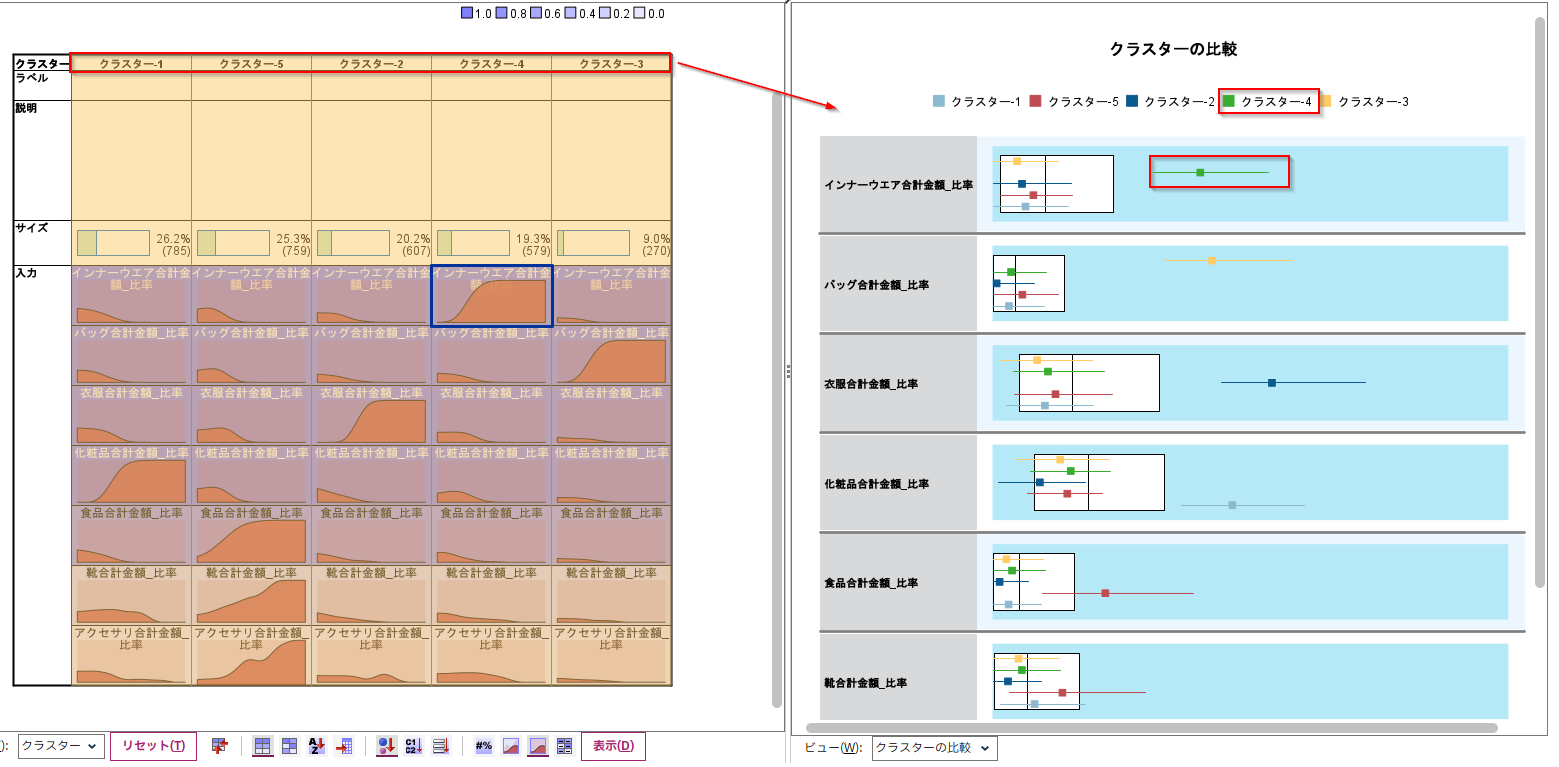
また、クラスタの比較の機能を使うと箱ひげ図で各クラスター間の値のばらつきも確認できます。
比較したいクラスター番号のセルを選択すると「クラスターの比較」ビューに選択したクラスターの箱ひげ図が表示されます。白抜きの箱ひげ図が全体の平均です。
ここからもクラスター4はインナーウェアの購入比率が高い人が集まっていることが読み取れます。
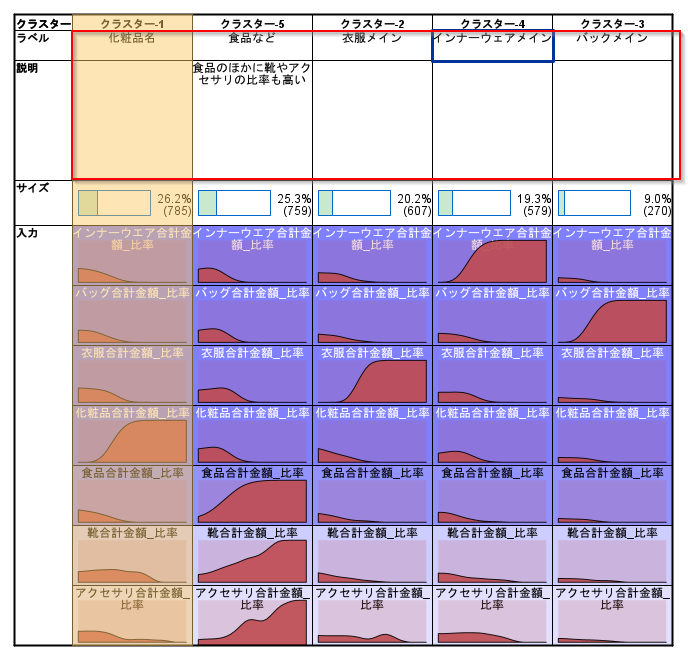
このようなビジュアライズ機能で、各クラスターの解釈を行いやすいことがModelerの特徴です。
各クラスターのラベルや説明をメモすることもできます。
自動事前処理
k-meansは、以下のような事前のデータ加工が必要です。
・スケールの影響を受けてしまうため、各データをスケ―リングする必要があります。
・フラグ型やカテゴリ型のデータは扱えませんので、数値へのエンコーディングが必要です。
・NULLも扱えませんので何らかの処理が必要です。
Modelerはこれらの処理を自動で行ってくれるので便利です。
ただし、欠損値はモデルの性能に影響がありますので、あらかじめ、「データ検査」ノードなどでどのくらいあるかは確認しておくことをお勧めします。
| 尺度 | スケーリング、ダミー変数化 | NULLの処理 |
|---|---|---|
| 連続型 | min-maxの0-1のスケーリング | 0.5で置換 |
| フラグ型 | 0,1へのダミー変数化 | 0.5で置換 |
| カテゴリ型 | one-hotで0,1へダミー変数化した上で重みをかける(デフォルトは√1/2) | 0.5で置換した上で重みをかける |
連続型のNULLを、0.5という固定値ではなく、平均値で埋めたいような場合には別途置換ノードなどで行う必要があります。
また、カテゴリ型は単純に0,1に変換するだけではなく重みをかけています。
これは、0,1にしてしまい。例えば、「北区」=1、「西区」=1という2つのフラグとした場合、この2つのデータのユークリッド距離が
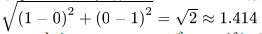
と1を超えてしまうためです。
そのために、√1/2の重みをかけて以下のように2つのデータ間の距離を1にしています。
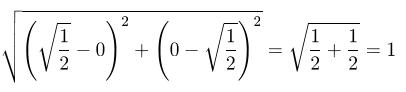
そのため0.70711というような数値になっています。
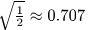
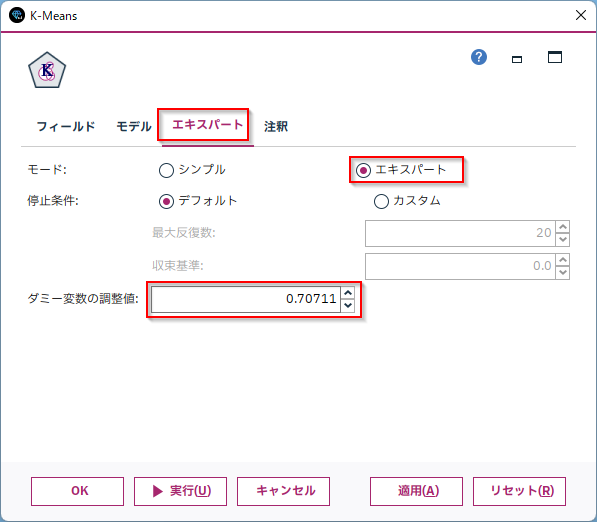
この重みは以下でカスタマイズすることもできます。カテゴリ変数がクラスタリングへ大きく影響しすぎる場合には、この値を小さくすると影響度を下げることができます。
5.参考情報
サンプルストリーム
利用データ
右クリックでリンク先を保存してください。
ノードのヘルプ
SPSS Modeler 逆引きストリーム集(データ加工)
SPSS Modeler ノードリファレンス目次