はじめに
この記事は前回の記事,唐揚げ?orトイプードル?機械学習で判別してみたのリベンジ記事です!
前回初投稿でお試しで書いたものが多くの方に見ていただけて嬉しい反面、雑な部分も多くあるので恥ずかしくなっているところです。(とは言え、1万viewもありがとうございます!!)
今回は畳み込みニューラルネットワーク(以下CNN)を用いて唐揚げとプードルの分類器を作成しました。
その後にGradCAMを用いてニューラルネットワークが何をみて判断しているのか可視化したので見ていただけたら嬉しいです。
目標は この画像を正しくプードルと認識できるような分類器を機械学習で作ること!!

1.畳み込みニューラルネットワークとは
CNNは一般的な順伝播型のニューラルネットワークとは違い、全結合層だけでなく畳み込み層(Convolution Layer)とプーリング層(Pooling Layer)から構成されるニューラルネットワークです。画像ピクセルを交換したり改良したり柔軟な対処ができ、パラメータの数が全結合層に比べて少ないことが特徴です。

1.1 畳み込み層について
畳み込み層では複数のフィルタを用いて2次元畳み込み演算を行いフィルタの数だけ特徴マップを作成しています。

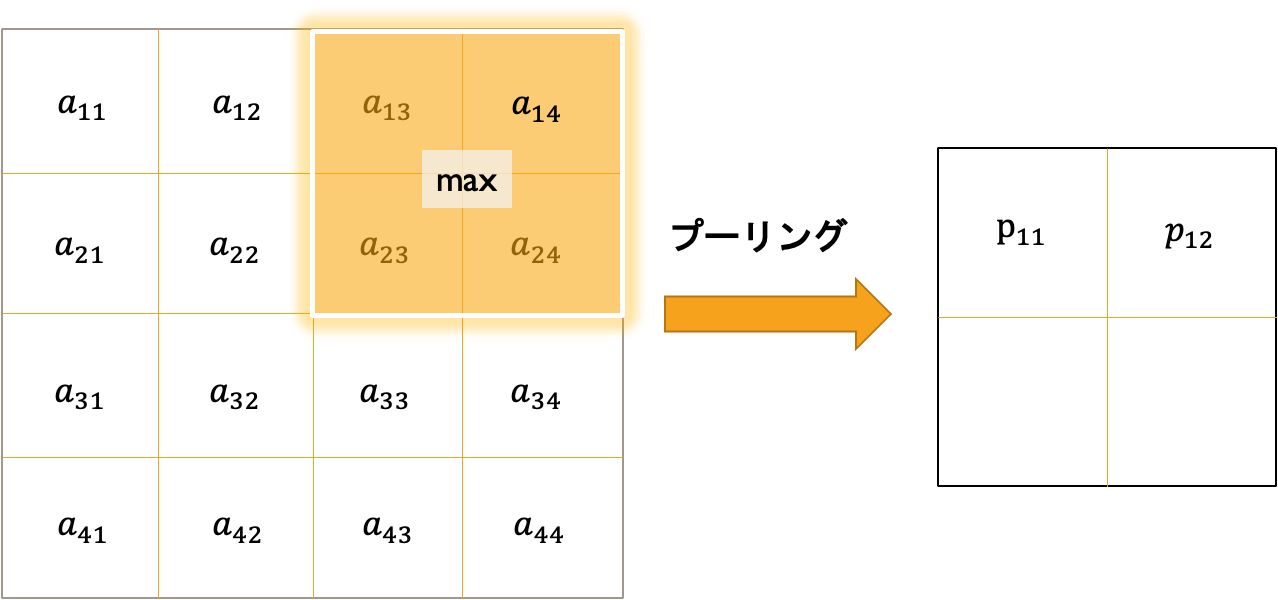
1.2 プーリング層について
プーリング層とは物体の些細な位置変化によって認識結果が変わらないようにする手法です。具体例を図にしてみました。ここでは最大プーリングを使用。



2.tensorflowで畳み込みニューラルネットワークの実装
2.1 必要なモジュールのインポート
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import cv2
import os
import glob
import pathlib
from tensorflow.keras.callbacks import EarlyStopping
import japanize_matplotlib
2.2 データセットの作成
まず画像パスから画像を読み込み返す関数を作成します。
def load_and_preprocess_image(path):
"""画像パスから画像を読み込み返す関数"""
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.cast(image,tf.float32) / 255.0 #ピクセルに0〜255にデータがあるので0〜1の範囲にする
return image
def preprocess(example_i,example_l,size=(64,64),mode='train'):
"""訓練時:画像をランダムに変形、テスト時:画像を整形して返す関数"""
image = example_i
label = example_l
if mode == 'train':
image_cropped = tf.image.random_crop(image,size=(150,150,3))
image_resized = tf.image.resize(image_cropped,size = size)
image_flip = tf.image.random_flip_left_right(image_resized)
return (image_flip, tf.cast(label,tf.int32))
else:
image_cropped = tf.image.crop_to_bounding_box(
image,offset_height=34,offset_width=14,
target_height=150,target_width=150)
image_resized = tf.image.resize(image_cropped,size=size)
return (image_resized, tf.cast(label,tf.int32))
次に実際にtrainデータセットの作成を行います。ラベリングが難しかったので唐揚げのフォルダ、プードルのフォルダを作って別々でデータセットを作り、結合しました。
#データセットの作成 唐揚げ
kara_imgdir_path = pathlib.Path('../../karapu/karaage/')
kara_file_list = sorted([str(path) for path in kara_imgdir_path.glob('*.jpg')])
kara_ds_path = tf.data.Dataset.from_tensor_slices(kara_file_list)
kara_image_ds = kara_ds_path.map(load_and_preprocess_image)
kara_image_labels = [1]*377 #唐揚げはラベル1
kara_label_ds = tf.data.Dataset.from_tensor_slices(tf.cast(kara_image_labels, tf.int64))
#ラベルと画像のデータの結合
kara_image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))
#データセットの作成プードル
pu_imgdir_path = pathlib.Path('../../karapu/poodle/')
pu_file_list = sorted([str(path) for path in pu_imgdir_path.glob('*.jpg')])
pu_ds_path = tf.data.Dataset.from_tensor_slices(pu_file_list)
pu_image_ds = pu_ds_path.map(load_and_preprocess_image)
pu_image_labels = [0]*402 #プードルはラベル0
pu_label_ds = tf.data.Dataset.from_tensor_slices(tf.cast(pu_image_labels, tf.int64))
pu_image_label_ds = tf.data.Dataset.zip((pu_image_ds, pu_label_ds))
#唐揚げとプードルの結合
ds = kara_image_label_ds.concatenate(pu_image_label_ds)
#シャッフル
ds_images_labels = ds.shuffle(779)
#trainとvalidにデータを分ける(train,valid)=(679, 100)
tf.random.set_seed(1)
ds_images_labels = ds_images_labels.shuffle(1000,reshuffle_each_iteration=False)
train = ds_images_labels.take(679)
valid = ds_images_labels.skip(679)
BATCH_SIZE = 32
BUFFER_SIZE = 779
IMAGE_SIZE = (128,128)
steps_per_epoch = np.ceil(779/BATCH_SIZE) #画像数/バッチ数
#dsが(img, label)のタプルのため、lambdaに二つ引数を渡す。
ds_train = ds_images_labels.map(lambda x,i:preprocess(x,i,size=IMAGE_SIZE,mode='train'))
ds_train = ds_train.shuffle(buffer_size=BUFFER_SIZE).repeat()
ds_train = ds_train.batch(BATCH_SIZE)
ds_valid = valid.map(lambda x,i:preprocess(x,i,size=IMAGE_SIZE,mode='train'))
ds_valid = ds_valid.batch(BATCH_SIZE)
これでやっとデータの準備ができました。次から学習に進んでいきます。
2.3 モデルの作成
from tensorflow.keras.callbacks import EarlyStopping)でEarlyStoppingを決めておきます。モニターはvalidのlossでいいでしょう。
from tensorflow.keras.callbacks import EarlyStopping
es_cb = EarlyStopping(
monitor = 'val_loss',
patience = 10,
restore_best_weights = True)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32,(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Dropout(rate=0.5),
tf.keras.layers.Conv2D(64,(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Dropout(rate=0.5),
tf.keras.layers.Conv2D(128,(3,3),padding='same',activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(256,(3,3),padding='same',activation='relu'),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(1,activation=None)
])
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(ds_train,validation_data=ds_valid,
epochs=20,steps_per_epoch=steps_per_epoch,callbacks = es_cb,)
`model.summary()`でモデルの内容を確認します。
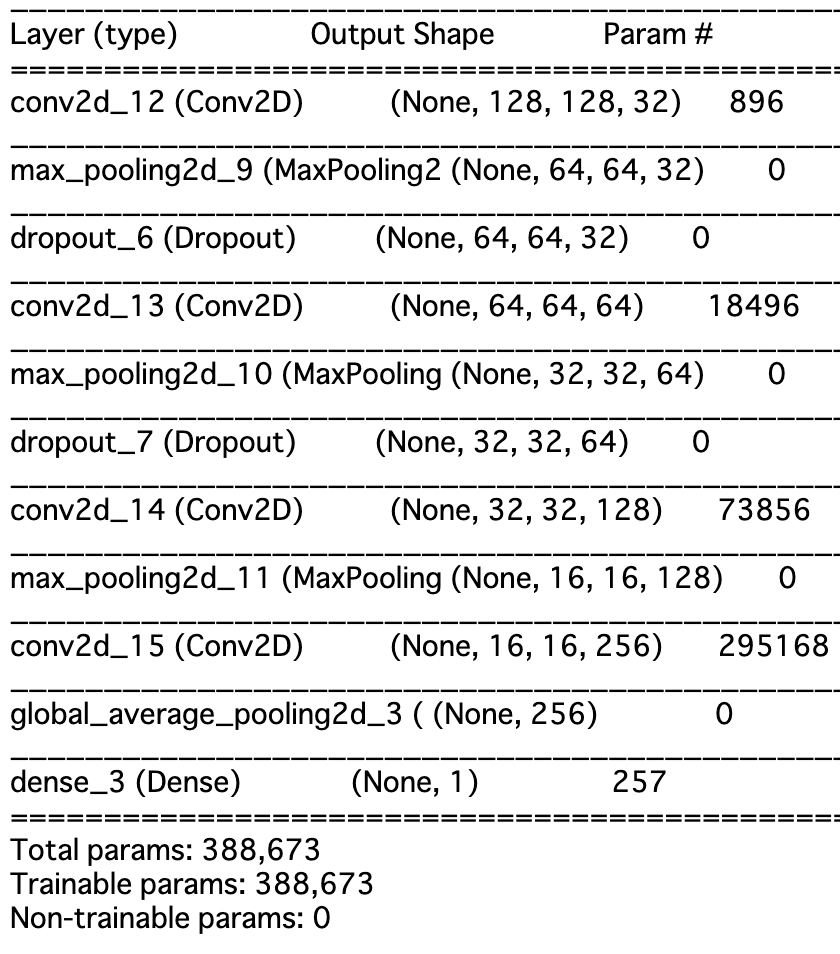
ふむふむ、パラメータたくさんあるなー、でも畳み込んだ結果なので全て全結合層だったらすごいことに...
最終的な出力はひとつで1に近ければ唐揚げに、0に近ければプードルに分類されます。
2.4 モデルの評価
lossと正解率、epochsのグラフを見てみましょう。

なかなかいい感じですね!ValidationがTrainにしっかりついていってます。これは期待できる。
テストデータ(27枚)正解率も 96.30%でした!
hist = history.history
x_arr = np.arange(len(hist['loss'])) + 1
fig = plt.figure(figsize=(12,4))
ax = fig.add_subplot(1,2,1)
ax.plot(x_arr, hist['loss'], '-o', label='Train loss')
ax.plot(x_arr, hist['val_loss'],'--<', label='Validation loss')
ax.legend(fontsize=15)
ax.set_xlabel('Epoch', size=15)
ax.set_ylabel('Loss', size=15)
ax = fig.add_subplot(1,2,2)
ax.plot(x_arr,hist['accuracy'],'-o',label='Train acc.')
ax.plot(x_arr,hist['val_accuracy'],'--<',label='Validation acc.')
ax.legend(fontsize=15)
ax.set_xlabel('Epoch',size=15)
ax.set_ylabel('accuracy',size=15)
plt.show()
#正解率の表示
ds_test = ds_test.map(lambda x,i:preprocess(x,i,size=IMAGE_SIZE,mode='eval')).batch(1)
test_results = model.evaluate(ds_test,verbose=1)
print('Test Acc: {:.2f}%'.format(test_results[1]*100))
それではテストデータの予測出力を見てみましょう!!

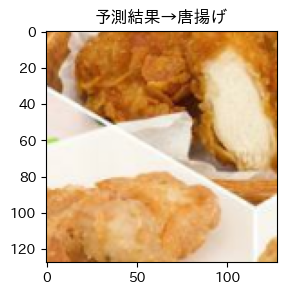








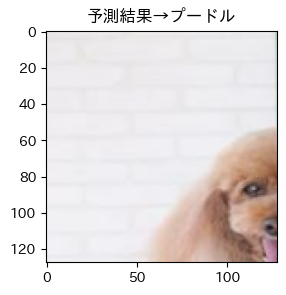
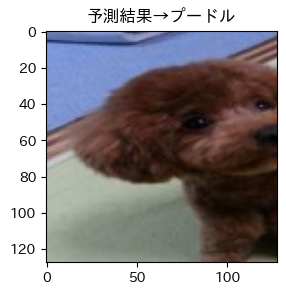
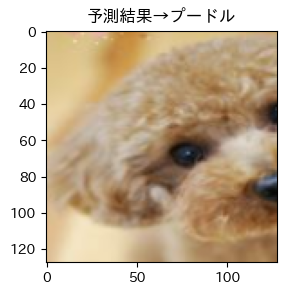
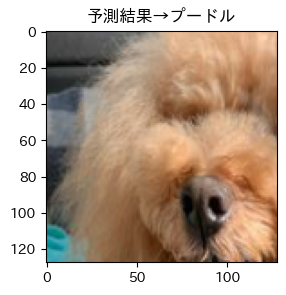
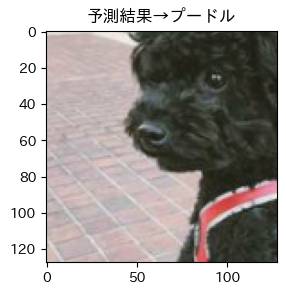
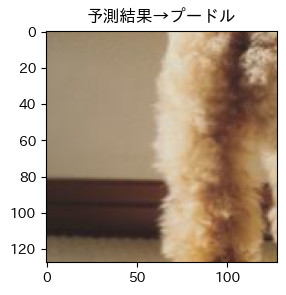

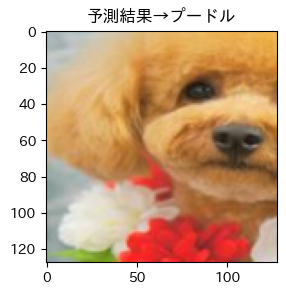
そして目標の画像は!?
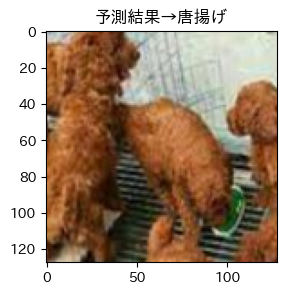
はい、唐揚げでした...
やはり同じような訓練画像が足りないのでしょうか、もっと集めたいと思います。ただ悔しいので最後にCNNが何をみてこの子達を唐揚げだと判断しているのかGradCAMで可視化して行きます!
3. GradCAMによる可視化
Grad-CAM (Gradient-weighted Class Activation Mapping)
はCNNベースの画像認識モデルに対してある入力とその予測に対して局所的な説明を与える手法です。
以下のようにヒートマップを与えてCNNがどこを重要視しているか可視化することができます。
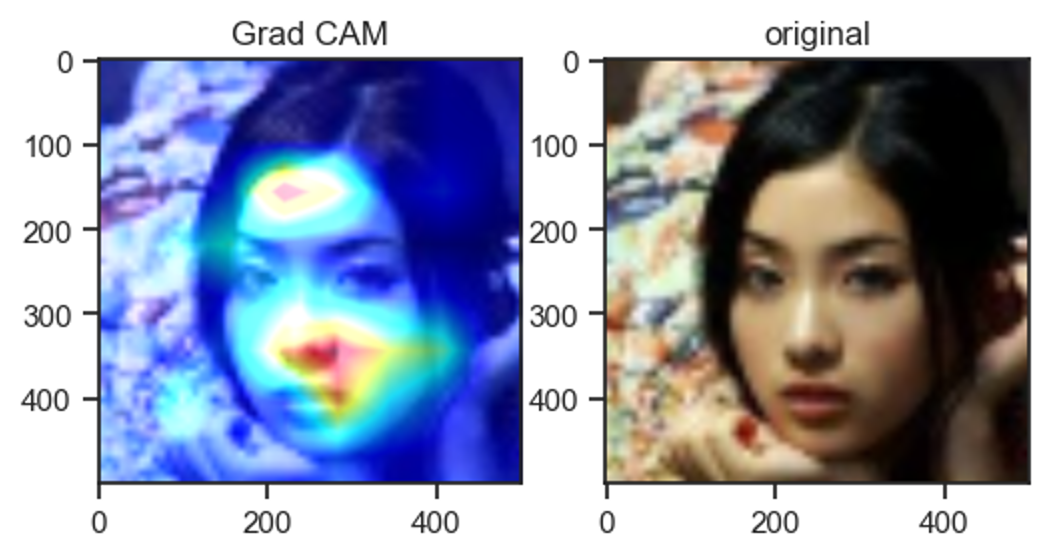
GradCAMの説明の前にGlobal Average PoolingとCAMの説明をして行きます。
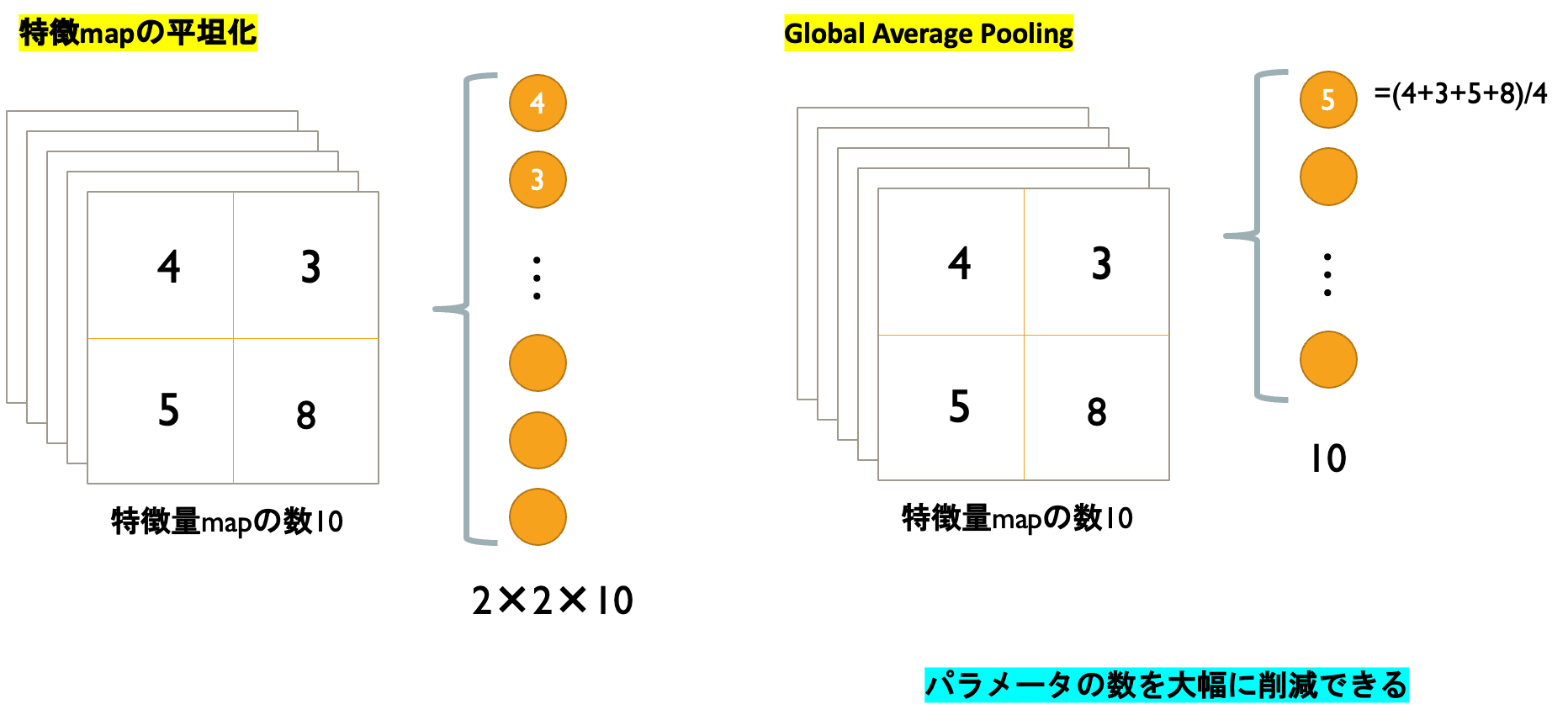
3.1 Global Average Pooling(GAP)
Global Average Poolingの特徴は普通の平坦化に比べて大幅にパラメータの数を削減できることにあります。
GAPを行うと特徴map各成分の平均がユニットの値になります。
次の例でも平坦化のパラメータ40個に対して、GAPは10個でかなりの削減です。
3.2 Class Activation Map (CAM)

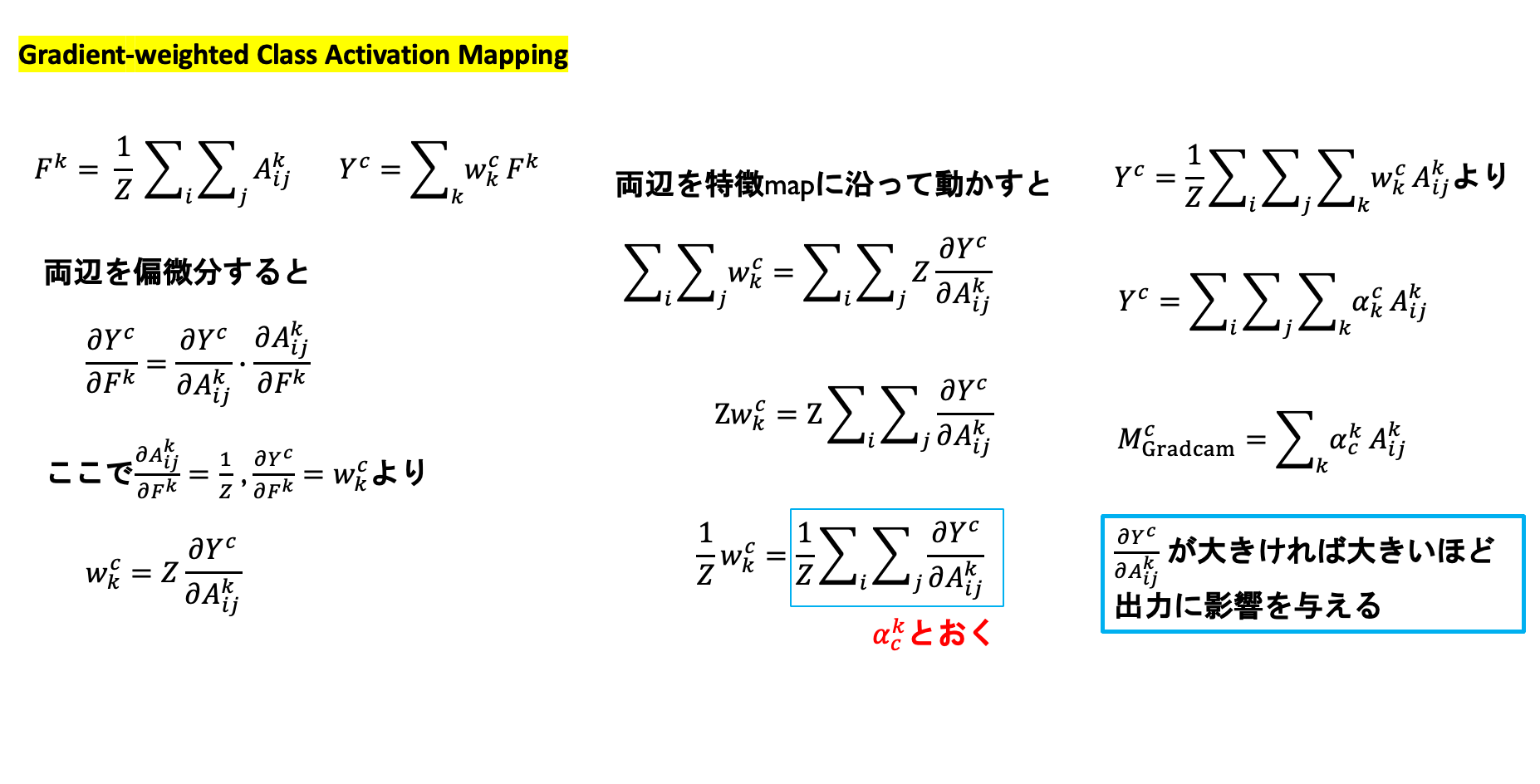
3.3 GradCAM
さてGradCAMとはGradient-weighted Class Activation Mappingの略でCAMを一般化したものです。
具体的には特徴mapの勾配からヒートマップを与えて可視化して行きます。
3.4 GradCAMの実装と可視化
def show_cam(i):
grad_model = tf.keras.models.Model([model.inputs], [model.get_layer('conv2d_15').output, model.output])
with tf.GradientTape() as tape:
conv_outputs, predictions = grad_model(tensor_list[i][0])
class_idx = np.argmax(predictions[0])
loss = predictions[:, class_idx]
output = conv_outputs[0]
grads = tape.gradient(loss, conv_outputs)[0]
gate_f = tf.cast(output > 0, 'float32')
gate_r = tf.cast(grads > 0, 'float32')
guided_grads = gate_f * gate_r * grads
# 重みを平均化して、レイヤーの出力に乗じる
weights = np.mean(guided_grads, axis=(0, 1))
cam = np.dot(output, weights)
# 画像を元画像と同じ大きさにスケーリング
cam = cv2.resize(cam, (500, 500), cv2.INTER_LINEAR)
image = cv2.resize(image_list[i][0],(500, 500),cv2.INTER_LINEAR)
# ReLUの代わり
cam = np.maximum(cam, 0)
# ヒートマップを計算
heatmap = cam / cam.max()
# モノクロ画像に疑似的に色をつける
jet_cam = cv2.applyColorMap(np.uint8(255.0*heatmap), cv2.COLORMAP_JET)
jet_cam = 0.7 * jet_cam / np.max(jet_cam)
jet_cam = np.float32(jet_cam) + np.float32(image)
# RGBに変換
rgb_cam = np.float32(cv2.cvtColor(jet_cam, cv2.COLOR_BGR2RGB))
# もとの画像に合成
output_arr = cv2.addWeighted(src1=image, alpha=1, src2=rgb_cam, beta=0.3, gamma=0)
fig = plt.figure(figsize=(6,10))
ax = fig.add_subplot(1,2,1)
ax.set_title('Grad CAM')
ax.imshow(rgb_cam)
ax = fig.add_subplot(1,2,2)
if preds[i] == 1:
ax.set_title('予測結果→唐揚げ')
else:
ax.set_title('予測結果→プードル')
ax.imshow(image)
唐揚げの可視化

プードルの可視化

GraadCAMで可視化した結果、唐揚げは全体的に、目と鼻に注目していることがわかりました!!
そして問題の画像は、

唐揚げの特徴である全体に注目していることがわかります。
4.最後に
CNNやGradCAMを学習して、画像認識の機械学習にも大変興味がわきました!!GradCAMを通してCNNが何を重要視しているか可視化することによって私の唐揚げプードルデータセットの改善方法も見えてきました。今後は訓練データで顔が見えていないプードルや複数匹いる画像なども学習させてみたいです。
プードルは絶対に食べさせません!!!
5.参考文献
Grad CAMの論文
Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization