前書き - 人工知能と脳科学 -
最近のAI (Artificial Intelligence) の進歩はすさまじいですね。特に、深層学習 (Deep Learning) はTensorFlow, Chainerなどのライブラリの普及もあり、一般的に広く使用され、知られる概念になりました。
ところで、Deep Learningの歴史を簡単に紐解いてみると、はじめは脳の計算原理を実装しようとする試み、つまりニューラルネットワーク (Neural Network) の研究からスタートしました。人の脳は100億ともいわれる数の神経細胞からできています。それらは解剖学的に分かれた領域に位置し、それぞれの脳領域は特定の計算を行っています。各脳領域は互いにコミュニケーションを取り合い、行動選択に関わる情報を処理しています。
こうした脳科学の知見は、ニューラルネットワークの研究をインスパイアしてきました。例をあげると、複数層のニューラルネットの学習にはかかせない**バックプロパゲーション (Backpropagation)や、過学習を防ぐためのドロップアウト (Dropout)**が有名かもしれません。それぞれ、脳の情報処理は双方向的である、神経細胞の発火頻度はポワソン分布に従う、という脳科学の研究結果からヒントを得て生まれたものでした。
ところが、現在はどうでしょうか。
脳科学って役に立ってますか。
てか脳科学って今何やってるんですか。
人工知能は、囲碁の世界チャンピオンを倒したり(1Silver et al., 2016)ポーカーのプロを倒したり (2Moravcik et al., 2017)と華々しい活躍をしています。アルゴリズムは一般ピープルの理解を優に超えるほど複雑になり、その多くは決して現実の脳の計算原理を反映しているとは言えません。むしろ、こうした例が示すのは、「人工知能は人間の脳を越えるかもしれない」、つまりシンギュラリティの可能性です。そうした時代に、「劣っている」人間や動物の脳の計算原理を研究することに、何か意味があるのでしょうか。
この疑問に、真正面から取り組んだ論文(総説)が去年の7月に発表されました。"3Neuroscience-Inspired Artificial Intelligence"(神経科学にインスパイアされた人工知能)というタイトルで、Neuronという神経科学の偉い雑誌に載っています。第一著者は、Demis Hassabis、ご存知の方も多いかもしれませんが、DeepMindの創設者です。彼はAlpha Goをはじめとする革新的な人工知能の研究に従事する世界的な人工知能学者ですが、実は、記憶や想像をつかさどる脳領域である海馬の研究で博士号を持っている、一流の脳科学者でもあります。すばらしい総説で、特に人工知能に浮かれている世の中に広く知れ渡ってほしい内容なのですが、残念ながらopen accessではないので、かいつまんで内容を紹介したいと思います。
実は現在でも、まだ脳科学の知見は役に立っている
論文ではまずThe Present、現在、という章で、脳科学の知見が比較的最近の人工知能の発展に生かされた例を4つ紹介しています。
- Attention(注意)
- Episodic Memory(エピソード記憶)
- Working Memory(ワーキングメモリー)
- Continual Learning(継続学習)
それぞれ、簡単に見ていきたいと思います。
Attention(注意)
脳はモジュール構造です。視覚をつかさどる領域、運動をつかさどる領域、感情をつかさどる領域などが機能ごとに分かれて存在しており、互いにコミュニケーションを取りながら、認知や行動といった高度な働きを可能にしています。決して、一個のニューラルネットみたいなものがどんっとあるわけではありません。
わかりやすい例がAttention(注意)です。

はい、この瞬間みなさんの脳の情報処理の大部分はえるたそに持っていかれました。これを読んでいるみなさんの目にはpixel by pixelの画像情報がオンラインで入力されていますが、上の写真を見た瞬間、みなさんの脳は情報処理パワーの大部分を、視界の中のごく一部分であるえるたそに割いたのです。
このように、脳は全ての入力情報を平等には扱いません。自分にとって大切な入力を優先的に処理し、そうでないものの処理を犠牲にする仕組みを、**Attention(注意)**と呼びます。
実は比較的最近まで、画像認識では鉄板となっている**CNN (Convolutional Neural Network)**であっても、入力ピクセルの全てを平等に扱っていました。4Mnih et al., 2014は、脳と目の仕組みに習い、ステップごとに入力画像の一部を取り出し、ネットワーク内の表象を更新し、次の場所のサンプリングする、というネットワークを作りました。こうしたアルゴリズムは、既存のCNNよりもより高い物体認識のスコアを出すだけでなく、効率的な計算によって計算コストも大幅に削減できることがわかりました。余計な物体や画像のノイズを無視し、大切な情報だけに集中する結果、よいパフォーマンスが出せるようになったのです。
Episodic Memory(エピソード記憶)
記憶と一言で言っても、分類がたくさんあります。
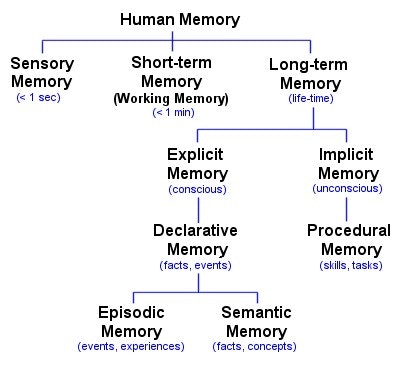
(出典: http://www.human-memory.net/types.html)
Episodic Memory(エピソード記憶)とは、人間の記憶 (Human Memory)のうち、長い期間覚えている記憶 (Long-Term Memory)のうち、意識的に思い出せる記憶 (Explicit Memory)、つまり事実や出来事に関する記憶 (Declarative Memory)のうち、出来事や経験を表す記憶 (Episodic Memory)のことです。大事なのはこの太字のところだけです(すみません…)。
なんでわざわざこんな分類するんだ脳科学者は暇なのか……と怒られる方もいるかもしれませんが、それは脳科学的にエピソード記憶は特別だからです。"one-shot" encodingとも呼ばれるのですが、この記憶はたった一度の出来事、経験で、前後の文脈を踏まえた形で一瞬で定着します。例えばこんな経験です。

こういうことが人生で一度あると、もう死ぬまで忘れない、ってか忘れられないですね。これがエピソード記憶です。英単語などは何度やっても忘れるにも関わらず、こうした強烈な経験が一発で脳に刻まれるのは、同じ「記憶」といえど異なった脳の神経回路が使われていることが予想されます。実際、エピソード記憶は内側側頭葉 (Medial Temporal Lobe)という、海馬 (Hippocampus) を含む特別な記憶の脳領域が担っているとされています。
このエピソード記憶を有効に人工知能に取り組んだ例が、**DQN (Deep Q-Network)です。DeepMind発のブレイクスルーを起こした人工知能で、特徴となっているのは深層学習(Deep Learning) + 強化学習(Reinforcement Learning)**という組み合わせです。Atari 2600 video gamesというインベーダーなどの古典的なビデオゲームを、画像のピクセル情報のみをインプットに0から学習していき、人間を越えるパフォーマンスを出した話 (5Mnih et al., 2015)は有名ですが、そのパフォーマンスの1つのカギは、"experience-replay"という、ネットワークがトレーニングデータの一部を保管し、オフラインで繰り返し再生することで、過去の成功と失敗を学びなおす仕組みにあります。この仕組みにより、人工知能はデータをより効率的に使い、学習することができます。この記憶を繰り返し再生する仕組みは、人間の場合睡眠中に特に起きます。
人の場合、脳の中で記憶が繰り返し再生されることで長期にわたって保存されるのですが、もちろんその利点は**Episodic control(エピソード的コントロール)**にあります。要は、新しい状況を目の前にしたとき、過去の似た状況を参照し、次の行動の手掛かりにすることです。DQNは「エピソード記憶」を持っているので、例えば取り組んでいるビデオゲームで新しい場面に直面した時、過去の似た状況を参照し、次の一手を選択することができます。
具体的には、トレーニングの中で経験してきた場面 (states)と、その場面で可能な行動 (action)を取った時に対応する最大の報酬値 (Q-value)を、記憶としてDQNは持っています。新しい場面に直面した時、過去の近い場面 (k-means)で可能な行動の選択肢それぞれのQ-valueを計算し、最も利益の大きいと思われる行動をします。DQNが示したように、こうしたエピソード記憶的なものを持つ人工知能には、既存の人工知能をはるかに超えたパフォーマンスが期待できます。
Working Memory(ワーキングメモリー)
ワーキングメモリーは1分持たない短い記憶です。
この論文で紹介されている、脳科学が最近の人工知能研究をインスパイアした例、4つ挙げていますが、最後の1つ覚えていますか?
・・・・・・
はい、Continual Learning(継続学習)ですね。てか私も忘れてました。このように、多くの事柄はワーキングメモリーに一時的に保管された後、忘れられていきます。こちらは脳の前頭葉 (Prefrontal Cortex)で処理されているようです。
ワーキングメモリーと人工知能の関係で最もよい例は、LSTM (Long-Short-Term Memory) (6Hochreiter and Schmidhuber, 1997) でしょう。LSTMではインプットの情報をある状態として、次に適切なアウトプットが必要になるまで保持しておく機能があります。もともとはこのSequence controlとMemory storageが一緒になっていたのですが、最近では人間の脳をまねて、DNC (Differential Neural Computer)のように、この2つを別のモジュールとして分離する動き(7Graves et al., 2016)もあるようです。
Continual Learning(継続学習)
最後の項目は、人の脳と現在の人工知能を分ける決定的な差です。
人は、基本的には一度覚えたことは、後で別のことを覚えたとしても、忘れることはありません。自動車を運転できるようになったからといって、自転車を運転できなくなる人はいません。
神経細胞同士が互いに接近し、情報を介する場のことをシナプス(Synapse)と呼びますが、その構造の一部であるスパイン (Spine)には記憶の神秘が詰まっています。学習によって記憶が生まれると、使用された神経回路のスパインが大きくなります。これは、シナプスを介して神経細胞同士の結びつきが強くなった証拠です。実際、このスパインを実験的に「消して」やると、今までタスクを記憶して、こなせていた動物がこなせなくなります (8Hayashi-Takagi et al., 2015)。
これを人工知能に応用したのが、EWC (Elastic Weight Consolidation) (9Kirkpatrick et al., 2017) という方法です。ニューラルネットにはたくさんのパラメーターがありますが、新しいタスクを学んでいるとき、以前のタスクで役割の大きかったユニットのウェイトを優先的に、あまり変化させないようにしてやります。そうすることでネットワークの複雑性を上げることなく、似たようなタスクであれば以前学習したときのパラメーターをある程度再利用することで、効率的な学習を可能にしています。
人工知能はまだ人間レベルの知能にたどり着いていない
論文の後半では、人間の脳だと難なくできるけれども、人工知能にとってはまだまだ難しい問題についてまとめられています。さらっと紹介します。
Intuitive Understanding of the Physical World(外界についての直感的な理解)
人間は幼児であっても、外界に関して直感的な理解をしています。

この絵を見たとき、手前に2人、奥に2人いて、手前のうちの1人が高いところにいる、という空間関係は、人間なら一瞬でわかります。人工知能にとっては、風景を個別の物体に分解し、互いの関係を推察することはまだ難しいです。
Efficient Learning(効率的な学習)
人間の学習能力は驚異的です。数少ない例と過去の記憶から、素早く新しい概念を学ぶことができます。人工知能、機械学習の教師あり学習には、大量のデータがいまだ必要です。
Transfer Learning (転移学習)
人は概念を一般化し、転移して新しい概念を理解することができます。

Re:Creators16話に出てくるこの方のように、戦闘用ロボットの動かし方がわかれば簡単に自動車の運転ができるようになる(らしい)のです。
AIにとって、そのような一般化や転移学習はまだまだ難しいです。論文では、脳科学の分野でも転移学習に関する研究が少ないことが指摘されています。つまり、人間や動物の脳が、どう物事を一般化し、他の似たようなタスクを転移した概念で効率的に学習しているのか、実はよくわかっていないのです。
Imagination and Planning(想像と計画)
人工知能はしばしば人間を驚かすパフォーマンスをします。囲碁の世界チャンピオンに勝ったり、ポーカーのプロを倒したり……。ところが、こうした人工知能は極めて"reactive"です。強化学習で、近い将来の報酬を最大化させるために、淡々とインプットからあるべきアウトプットの学習をします。
一方、人間の意思決定の多くは計画を伴います。将来の可能性を何通りも想像しながら(シミュレーション)、特定のルールに強く束縛されることなく、現在の行動を決定することが可能です。
人間のようなシミュレーションに基づいた柔軟な意思決定は、2つの点で人工知能に勝っています。1つ目は、少ないデータ(経験)からでもシミュレーション(想像)によって効率的に最適解にたどり着き得るということ。人工知能には、大量のデータを与えないと最適解は得られません。2つ目は、行動の決定をするルールを柔軟に変更できるという点です。強化学習で、もし各場面と、行動、報酬の関係が急に変わったらどうなるでしょうか。人工知能は、すぐには状況に合わせたパラメーターの更新はできません。
人工知能研究と脳科学の今後
脳科学によって明らかになる脳の仕組みは、人工知能の発展に大きく寄与することが、脳科学によってインスパイアされた実装例や、人工知能の課題を通して示されてきました。最後に個人的にちょっと面白かった、Virtual Brain Analyticsという概念について簡単に紹介したいと思います。
「脳は、脳を理解できるか」
人間は自分たちを理解しようとし、自分を自分たらしめる脳を理解しようとしています。ところが、人間に理解を授けるものは脳なので、脳科学とは、脳が脳を理解しようとする営みであると言えます。
これは、極めて難しい試みであるはずです。なぜなら、現在の科学技術の発展は、相対化という、自分と対象を切り離して観察するプロセスによって発展してきたからです。
脳科学者たちは、脳を相対化した形で研究対象にすべく、様々な実験・解析法を編み出してきました。この記事でちょろっと紹介した研究も、そうした努力のたまものです。
DeepMindのHassabisさんは、AI研究者にはそうした姿勢が今後より求められるとおっしゃっています。現在、AIの研究内容が複雑化し、多くの過程がブラックボックスの中にあります。一体全体、ネットワークがどんな計算をしているのか、インプットはどのように内部で表現されているのか、よくわからないけれども、でも結果がよければいいよね!、といったように。これは、AIの複雑さが脳の複雑さに近づいてきたことによって、当然起こりうる現象なのかもしれません。
そこで、脳科学者が、脳というブラックボックスの中で何が起きているのか調べるように、AI研究者もAIというブラックボックスの中で何が起きているのか、脳科学がつちかってきた実験計画法・解析手法を応用して、調べていくこと、つまりVirtual Brain Analytics(バーチャルな脳の解析)が、今後の人工知能研究の発展につながるのではないかと、Hassabisさんは述べています。
結論 - 脳科学は人工知能と共に発展していく -
Distilling intelligence into an algorithmic construct and comparing it to the human brain might yield insights into some of the deepest and the most enduring mysteries of the mind, such as the nature of creativity, dreams, and perhaps one day, even consciousness. (Hassabis et al., Neuron 2017)
知能をアルゴリズムの形に蒸留し、人間の脳と比べることで、心の最も深く、そして最も永久的な謎であるいくつかについて、重要な知見が得られるだろう。例えば、創造性や夢の本質がわかるかもしれない。そしていつの日か、意識についてさえも。(デミス・ハサビス他)
出典
- Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., van den Driessche, G.,
Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., et al. (2016).
Mastering the game of Go with deep neural networks and tree search. Nature
529, 484–489. - Moravcik, M., Schmid, M., Burch, N., Lisy´ , V., Morrill, D., Bard, N., Davis, T.,
Waugh, K., Johanson, M., and Bowling, M. (2017). DeepStack: expert-level
artificial intelligence in heads-up no-limit poker. Science 356, 508–513. - Hassabis D, Kumaran D, Summerfield C, Botvinick M (2017) Neuroscience-Inspired Artificial Intelligence. Neuron 95:245-258.
- Mnih, V., Heess, N., Graves, A., and Kavukcuoglu, K. (2014). Recurrent models
of visual attention. arXiv, arXiv:14066247. - Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A.A., Veness, J., Bellemare, M.G.,
Graves, A., Riedmiller, M., Fidjeland, A.K., Ostrovski, G., et al. (2015). Humanlevel
control through deep reinforcement learning. Nature 518, 529–533. - Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural
Comput. 9, 1735–1780. - Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwi
nska, A., Colmenarejo, S.G., Grefenstette, E., Ramalho, T., Agapiou, J.,
et al. (2016). Hybrid computing using a neural network with dynamic external
memory. Nature 538, 471–476. - Hayashi-Takagi, A., Yagishita, S., Nakamura, M., Shirai, F., Wu, Y.I.,
Loshbaugh, A.L., Kuhlman, B., Hahn, K.M., and Kasai, H. (2015). Labelling and optical erasure of synaptic memory traces in the motor cortex. Nature
525, 333–338. - Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu,
A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al. (2017).
Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad.
Sci. USA 114, 3521–3526.