
初めに
本記事 『ゼロから始めるシステム障害対応フロー』 の内容について
タイトルの「ゼロから始める」には二つの意味があります。プロダクトのリリースを間近に迎える中、チーム内での障害対応体制の枠組みがなかったこと。そして体制づくりを担当することとなった私の知識・知見が(ほぼ)ゼロだったこと。この二つです。
この状態から、リリース前〜リリース後の約2月間でなんとか形にすることができました。本記事ではその過程でぶつかった問題とそれに対する課題、それらにどう対応したのか、何を学んだのか、の紹介。
そして、障害対応体制の策定・構築や改善の流れの中で私が起こした失敗から、人としてリーダーとして何を心がけなければいけなかったのかの反省を共有させてもらいたいと思います。
本記事は以下の構成です。
0. 始まり
※ スクラムチームでの話。スクラムチームの登場人物は以下の三つ
- PO:プロダクトオーナー(PdMに近い。Whatを決める)
- SM:スクラムマスター(プロセスを改善・POの支援やスクラムの普及)
-
Dev:開発者(WhatをどうやるのかのHowを決める)
- 当時の私は開発者でした
ある日、仮想オフィス上で上司とプロダクトオーナー(PO)に、あるタスクをやってもらえないか?と声をかけて頂きました(フルリモート)。実はこの時、私は入社ホヤホヤ(4ヶ月くらい)、かつエンジニアになって1年半でした。
そんな自分に何やら少し重要そうなタスクを任せてもらえるっぽい空気感を察知し、期待と不安が入り混じった気持ちになったことを覚えています。
上司・PO:「障害対応フローを作ってもらえないでしょうか?」
(対応フローとの事でしたが、結果的に体制確立や改善も行うことに)
私:「?????????それは、なんですか!?」
私にとって、全くの未知の領域に近い分野でした。ただ、この辺りはログ周りのタスクを通して監視・DevOps周辺に興味を持ち始めた時期で、以下のリンクの内容など勉強している時期でした。
そんなこともあり、上司には興味がある・プライベートで学習をしている・今後もそういったタスクはやってみたいといったアピールもしていました。その流れで『オライリー 入門 監視』をお勧めしていただき読んだりしていました。なので、お声がけして頂いた時は「種まきが実ったなー、やったー!!」と思ったことも覚えています。
とはいえ、システム障害対応体制を確立するには知識・知見・経験もない状態でした。
1. まずは教科書通りに作ろう

『私がかなたを見渡せたのだとしたら、それはひとえに巨人の肩の上に乗っていたからです』
-アイザック・ニュートン-
早速タイトルと違反する内容かも知れませんが、愚直にゼロから作る必要はないと思っています。既に偉大な先人が、多くのベストプラクティスを世の中に出してくれています。さらにその解は一つだけではなく、時代背景・状況・組織やチームの体制、という文脈でその時それぞれの最適解が存在し、わたしたちはその中から自由に学び選択することが出来ます。ただ、自由過ぎて迷うこともありましたし、自分達にマッチするのかは考慮し盲目的に従うことは避けなければいけませんでした。
とはいえ、どれを参考にすればいいのかすらも分からない本当の無知でした。以下で言うところの「無知の第二段階」の状態です。
無知の6段階レベル
- 無知の第一段階
・本当の無知。自分が無知だと「知らないこと」- 無知の第二段階
・自分が知らないということを「知っていること」- 無知の第三段階
・自分が知らないことを知り、知らないことが「何であるか」を「知ること」- 無知の第四段階
・以上のことをすべて知り、「向上する」ための「行動」を欲するが、「どうすべきか」 「わからない」こと。- 無知の第五段階
・自分が知らないことを知り、それについて「何をすべきか」知っているが、「行動できない」こと。- 無知の最高段階
・自分が知らないことを知り、それについて何をすべきか知り、「行動する」という、望ましい無知。
「自分が知らないことが何であるか?」を定義できないことにはネクストアクションも決定できません。現状認識から始めないと適切な行動を選択できません。POとも意見出しもしましたが、そこはお互い無知同士。押し黙るか唸るのみ。お互い仮説持ってきましょう、ということでそれぞれ調べてからブレストを行う流れとしました。
そこでめちゃくちゃ参考になったのが以下の動画です。こちらの動画は「システム障害対応の教科書」の著者である木村 誠明(きむら ともあき)さんが本書籍を直接解説してくださっている動画です(本当に助かりました・・・)。この書籍を中心に障害対応体制の策定を行なっていくことになります。
POも全く同じ動画を見ており、それを元にブレストの準備を行なってくれており、認識合わせが非常に楽でした。この点に関してはラッキーでした。

従来の監視・障害対応とはどの様な概念なのか?そしてそれらが現代において、どの様な点で限界を迎えているのか?それに対し、現在はどの様に対応しているのか?
全体像の中の自分達の立ち位置を大まかに捉えることができたので、現状認識に大きく役立ちました。並行して、ここで得た知識が世間一般的な共通認識と大きな乖離がないか?個別最適なソリューションと一般的普遍的なソリューションはどれか??などもさらっと確認しました。個別最適な解が、自分達の組織にマッチするかは慎重に考える必要があったからです。
以降は、初期の資料や体制になります。現在は大幅に変わった点もありますが、敢えて不完全なものを乗せています。以降の改善は、私たちの組織のルール、チーム体制の影響などが反映された個別最適事項なためです。決して、資料(去年の11月に作ったもの。現在は2024/02)を作り直すのが面倒だったからではありません!!

上記の書籍をもとに、大体この順番で作った様に思います。多分もっと適切な順番があったと思います。当時は暗中模索だったため、実感を得てから次に見えた場所へ進むしかない状態でした。
それでも無知同士の仮説でしかないためここで作ったものをたたき台とし、社内外問わず色んな方に相談しました。常に誰かにフィードバックしてもらいながら作っていくことになります。POはある程度の叩き台が出来上がってからは、離脱して頂きました。リリース前ということもあり、他にも無数にタスクがあったためです。
POと作った最初の資料は結果的に大幅に変更することにはなったのですが、そのたたき台があったからこそ何とか走り始めることができました。完全である必要は全くなかったです。使えば自ずと問題は明らかになるし、なによりチームのみんながより良いあり方を提案してくれるだろうと信頼していました。集合知が重要だと思っています。

この辺りは、基本的に「システム障害対応の教科書」と「SRE サイトリライアビリティエンジニアリング」の両書籍をフル活用フル引用し、ミックスし、徐々にチームにフィットする形に変えていくことになります。
書籍を参考にインシデントコマンダー制度を導入しました。情報の集約点・及び内部(開発チーム)と外部(開発チーム以外)との唯一のインターフェースとなります。選択と集中、責務の明確化です。単一責任原則・疎結合高凝集あたりの原則とのアナロジーを感じ、エンジニアとしては気持ちいい体制だなと思いました。
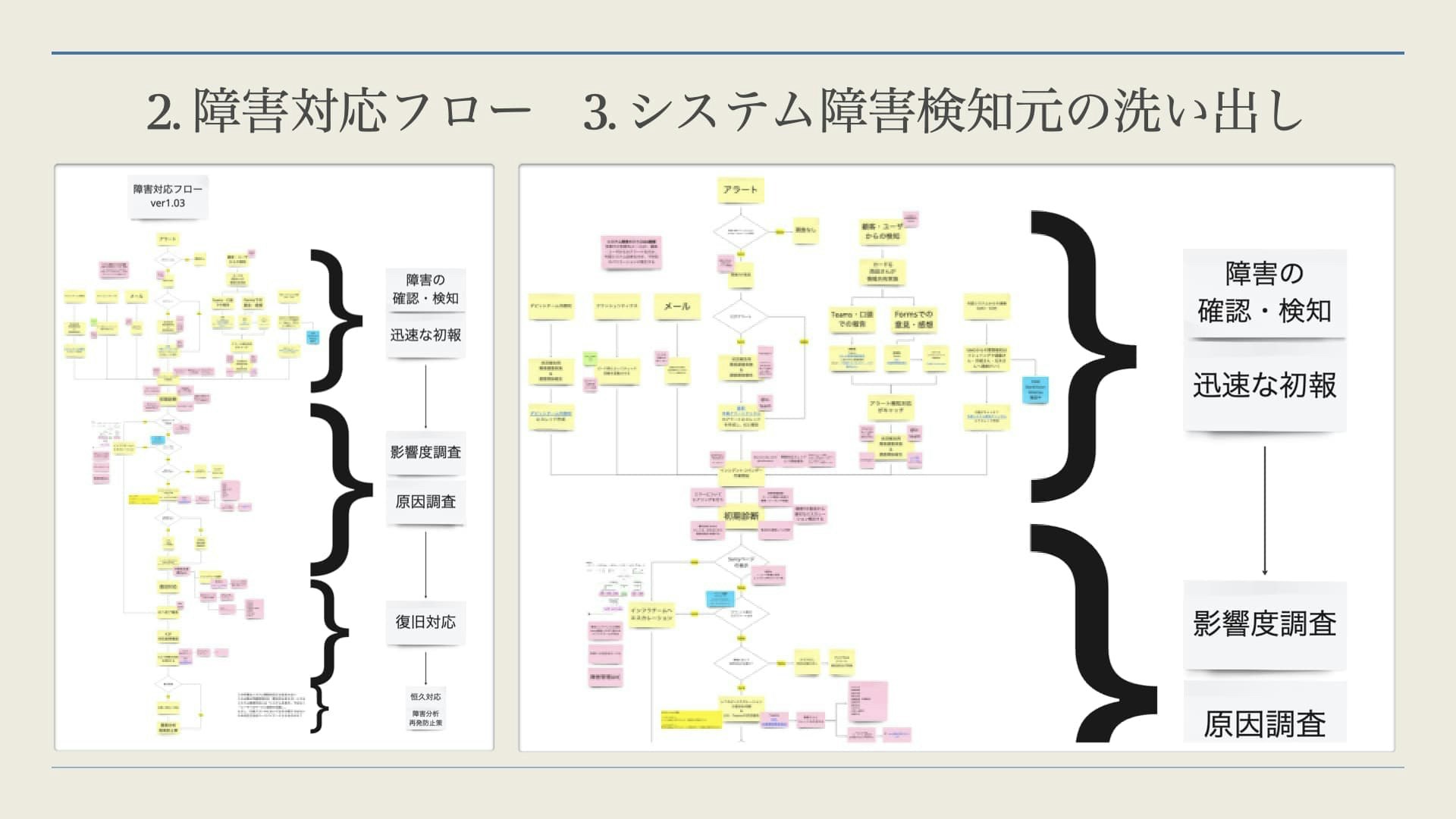
システム障害の検知チャンネルには何があるのか?システム障害が発生したらどうするのか?そもそもシステム障害が発生したらどこに通知が来るのか?各段階で何に注意しながらどの様な行動を行うのか?
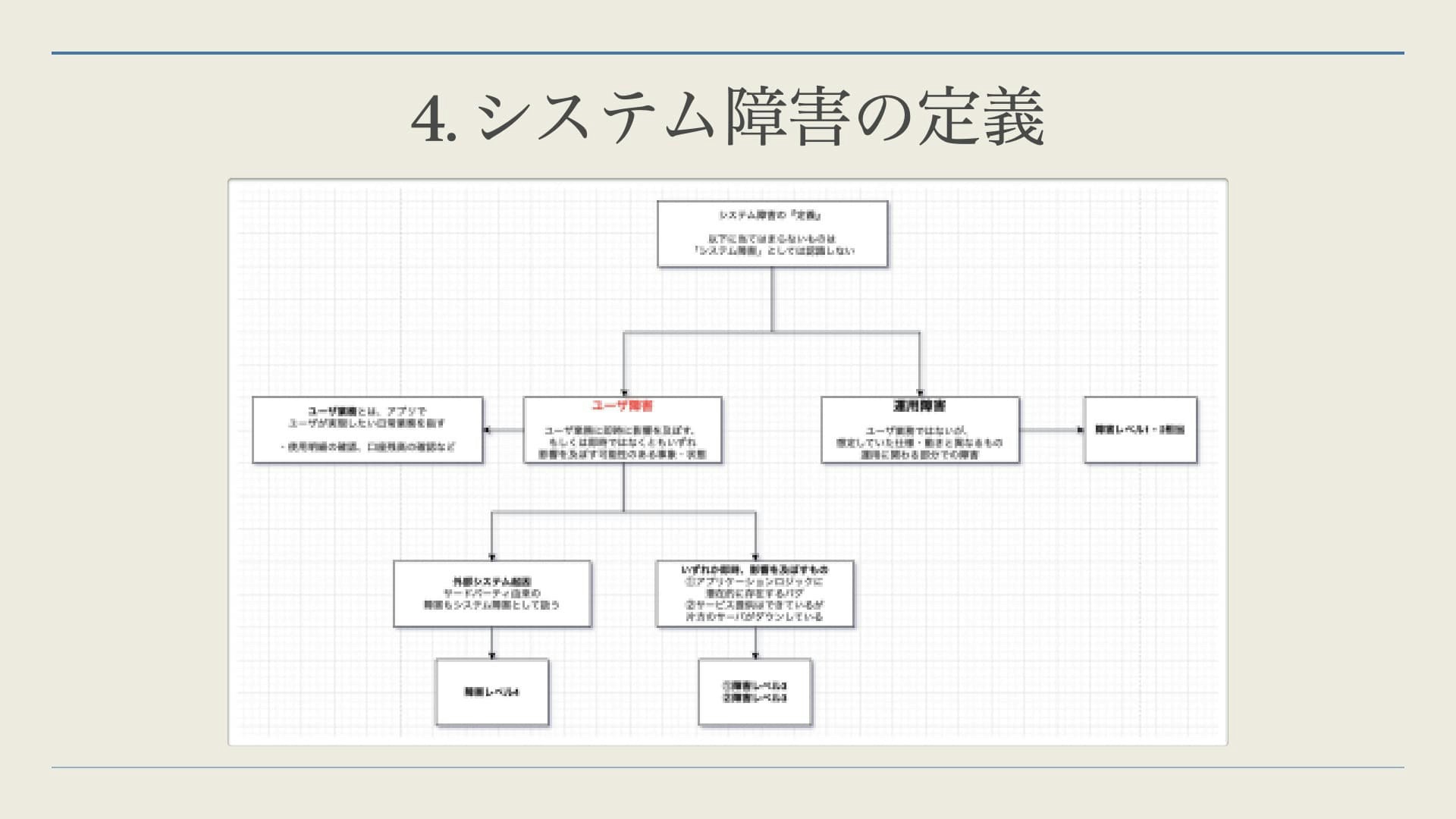
そもそもシステム障害とはなんなのか?障害が発生したら上記で作った様なフローに沿って行動するわけですが、トリガーとなる「障害」の定義を行う必要がありました。人によって認識が異なるのであれば、チームとして統一された対応ができません。
管理者にとっては障害であるのにメンバーにとってそうでない場合、対応すべき障害が放置される様な状態を発生させかねないからです。

同様に、障害レベルの定義も必要です。障害度によって最優先すべきアクションが異なるので、明確な基準が必要でした。また、銀行という事業であるため社会的な対応も含めたメトリクスの作成が必要でした。その他、ここではユーザに影響があるかどうか?も観点として分割しています。

そもそもの検知体制はインフラチームが既に用意してくれていたので、自分の仕事はそれらをどう管理するのか?どの様に活用し運用するのか?を決定することでした。
また、障害の記録をどの様な形で保存するのか?も重要で、障害対応時の背景・決定事項・対応方針の共有において必須です。また、それらは重要な知見蓄積に繋がると思います。
2. 各部署とのコラボレーションは必須

チームメンバーの力を借りて集合知でブラッシュアップしていく。これだけでは不足です。我が社にはより詳しい先達が何人もいらっしゃるのです。ご意見・フィードバックをもらわない手はありません!
ここにあるのは、ほんの一部です。頂いたご意見を私がまとめていたメモです。
本当にありがたい意見しかなかなく、ものすごく勉強になりました。

基本的に一つ一つミーティングを設定して頂きました。インフラチームは他事業も兼任している中、上司が仲介して下さる形でお時間いただきました。また、インフラチームの方々は、Discord上で開発チームの動きを見てくださっており、ときおり助言をチャットしてくださいました。ありがたさの極みでした。
ステークホルダーには業務課・役員・社長も含まれます。その場では、
- さまざまな意見・注意点・助言
- 困ってることの解決策の提案
- 開発チームだけでは決められない意思決定
などが迅速に行われました。
POメインで共同しながら、ステークホルダーとコミュニケーションを行いました。自分が思っていた保守的な業界に見られる重さや閉鎖性が皆無だったのが有り難かったことを覚えています。
また、上記でも書きましたがチームメンバーとのディスカッションも頻繁に行われ、どんどん改善が進みました。ディスカッションは言わば反論異論の連続です。認知的負荷が高く、時間も食います。今思えばもう少し効率的なやり方を考えるべきだったなと思います。タイムボックスの設定やディスカッションの達成目的・成功条件の絞り込みや明確化すべきでした。
とはいえ、ディスカッションの結果、よりよい改善案を見つけ出す(対立昇華:アウフヘーベン)ことができましたし、その過程で相互理解が進んだり勉強になったことも多く非常に有意義でした。
3. 実運用で重要なことはトライ&エラー

早く作って、使って、問題点をあぶり出し、改善策を決め、試し、見直す。この繰り返しを短いスパンで実施する。最初から完全なものは出来やしないと思っていました。投げやりなわけではありません。人間が作るものに欠点がない方がおかしいという考えです。

実際にプロダクトがリリースされる前に、行員の方々の協力のもとで試験を実施していました。プロトタイプであった初期の対応フローでは問題が多々あり、大きな変更が必要なことが判明しました。特に、上記で作った対応フローです。正直な話、使い物になりませんでした。。。。

問題点続出と記述しましたが、想定内だったので何も心配していませんでした。何とかなるだろうし何とかする、と思っていたからです。
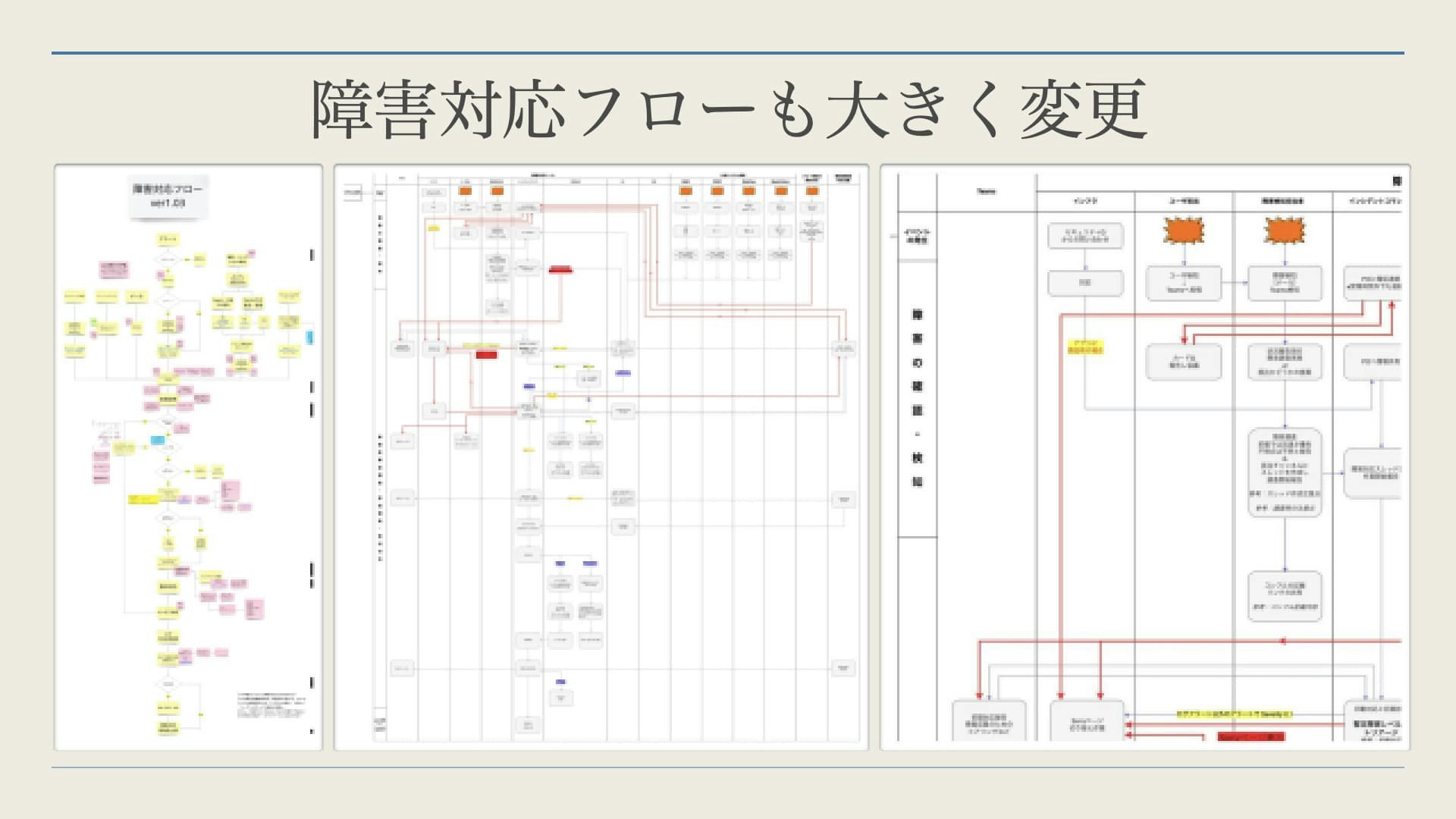
初期の障害対応フローはブレストしたものを拡張したものでした。
- 各要素のマトリクスがなく全体像が把握しづらい
- 段階・障害レベルなどに沿った行動もわかりづらい
- 時系列の表現も不十分
- 関係部署の網羅性がない
- 状況ごとの分岐の網羅性がない
- 付箋が多く、認知負荷が高い。初見の人間が読む気にならない
それらを解消すべく新しいものを作成しました。ただし、こちらは詳細度が高くなってしまったので硬いドキュメントになってしまいました。細かな変更を反映させる必要ができてしまったのです。
対応フローのコアを抽出し抽象化する必要があるものの、誰でもこれを見れば対応に困らないという目的のためには抽象化は悪手です。とはいえ、メンテナンスコストも無視できないので何とかしたいと思っていますが放置しています。一度出来上がれば、変更する機会が激減するからです。その段階になったら修正しようと思っています。
ただし、抽象化も行たいと思っています。抽象化し一般化すれば他プロダクトでも転用できるかもしれませんし、抽象化の過程で穴が見つかるはずだからです。プロダクトの信頼性を保つためにも是非やりたいところです。
プロダクトの信頼性・安全性のためには、障害を起こさないことも重要ですが全てを防止することはできません。よって発生した障害を迅速に収束させる必要があります。予防と事後対応の二本柱を心がけていきたいと思います。
4. オブザーバビリティの重要性

上記で、以下の様に記述しました。
従来の監視・障害対応とはどの様な概念なのか?そしてそれらが現代において、どの様な点で限界を迎えているのか?それに対し、現在はどの様に対応しているのか?
その答えの一つが「オブザーバビリティ」であると認識しています。また、オブザーバビリティは「予防」に大きく貢献するものと思っています。

とはいえ、そのオブザーバビリティとは監視を土台としています。まずは監視ができていないことには実現できません。監視もよく解っていなかったので勉強しました。

監視の問題点は「受け身」なことです。リアルタイム性に欠けるのです。

監視の問題点である「受け身であること」とは、人間で例えると熱が出てからしか異常をキャッチできない様なものです。熱が出たら病院に行ったり数日休まなくてはいけません。対してオブザーバビリティとは、熱が出る予兆をキャッチし、未然に熱発を防ぐためのアクションを行うために必要な「環境・状態・仕組み」のことです。

オブザーバビリティと従来の監視の間に「Application Performance Manegement」という概念が存在しますが、オブザーバビリティはこちらも包含します。
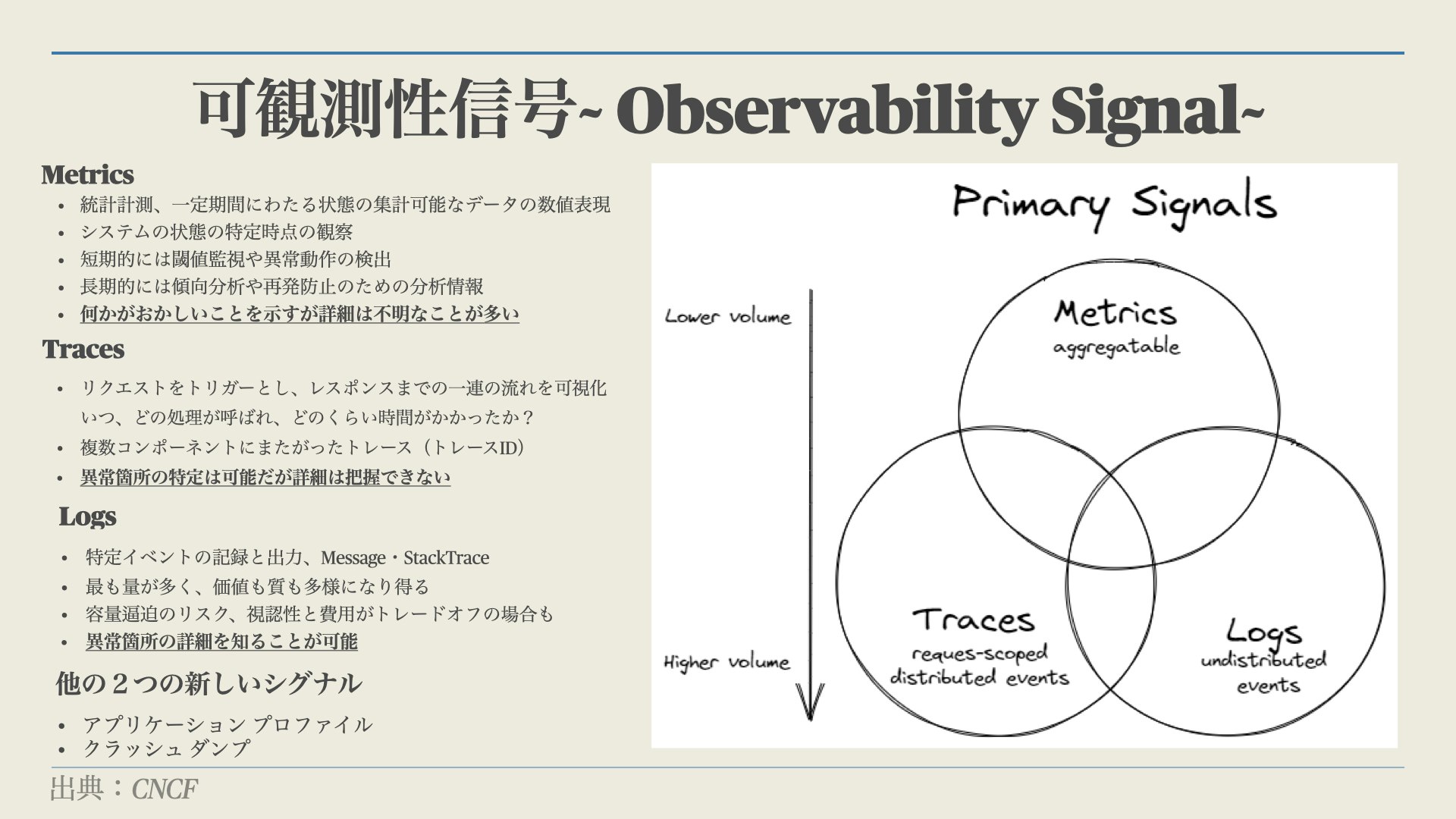
参照サイト:Observability Signals
ここまで紹介したオブザーバビリティですが、実は現状ほとんど導入できていません。不完全でも行えるような環境は存在しているのですが、運用管理ができていない状態です。この辺りは是正が必要なのですが、現状の優先順位を考えた結果どうしても後回しになっています。悔しいです。
また、インフラ観点のみならずUXモニタリングツール(Firebase や Xcode Metrics)を用いたフロントエンド領域観点も必要です。リアルタイムでユーザ体験を把握したいからです。とはいえ、ROIが高いのかも検討しなくてはいけないのですが知見不足もあり、手を付けておりません。今後の課題としては、ROIを判断できるレベルまでのキャッチアップ・そして実践しながら改善していく心構えが必要ですね。
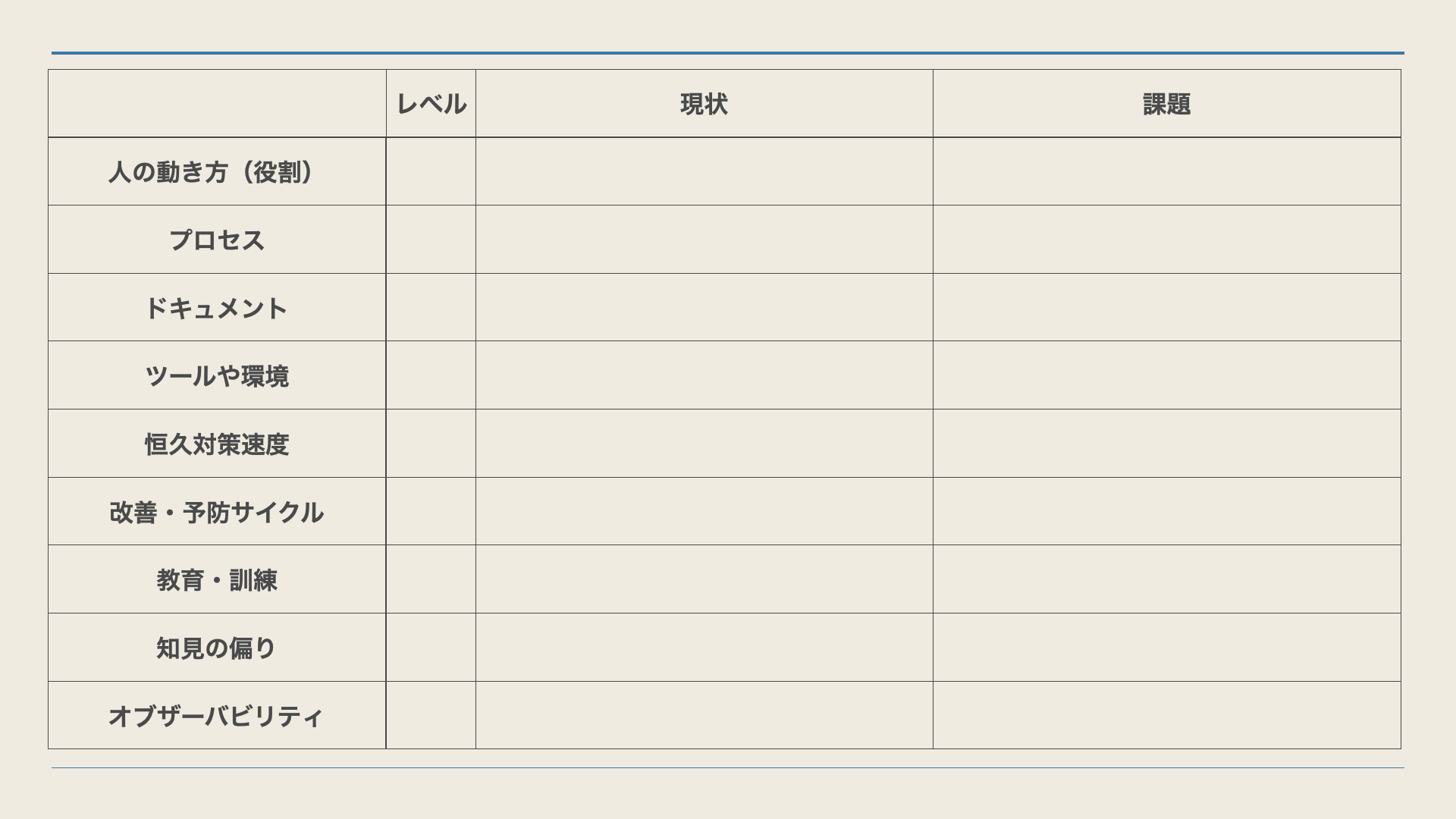
5. 障害対応能力のアセスメント

この辺りは基本的に「システム障害対応の教科書」をほぼ使用させてもらいました。
Level 1
- 障害対応能力レベル
- 組織で対応せず個人頼み。 行き当たりばったりで改善も行われない
Level 2
- チームで安定対応できており、品質もある程度担保。ただし、マンパワーによる
- 部分も多く自動化工程がすくないため、 維持管理コストも高いため陳腐化しやすい。
- システム変化に追随するのが難しい
Level 3
- 各担当者が高度に情報的連結し、 意思決定が迅速。 ドキュメントなどの変更管理
- プロセスは自動化を前提とし、改善作業やその他の作業が手作業を排し自動化に向いている
この認識をもとに自分達のチームが今どのレベルなのかを各指標ごとに判定してみました。一度してからは行っていないので、チーム全体で取り組んでみたいなと思います。
上司に現状評価を報告した際に言われたことがあります。
「レベル3の先にあるものを目指してください。それは.....」
Level 4
- FW化。モデリングが可能で他プロダクトでも転用が可能
- 本質的に必須な部分の抽象化ができている事に加え、チームに最適化させるのではなくFWにチームを最適化させることを見据える
上記の「障害対応フローも大きく変更」にて以下の様に書きました。
対応フローのコアを抽出し抽象化する必要があるものの、誰でもこれを見れば対応を困らないという目的のためには抽象化は悪手です。
ただし、抽象化も行たいと思っています。抽象化し一般化すれば他プロダクトでも転用できるかもしれませんし、抽象化の過程で穴が見つかるはずだからです。プロダクトの信頼性を保つためにも是非やりたいところです。
同じ様なことを課題として考えていたのですが、上司は一歩先を言っていました。
「今のチーム体制における最善ではなく、あるべき姿をモデリングとして表現・導出し、それができるチームに体制を改革するべき」と私は受け取りました。順序が逆だったなと思うと同時に、近視眼的になっていたと感じました。
問題の原因は、構造(チーム体制)の中にあるのではなく、そもそも構造(チーム体制)そのものにあるという視点ですね。私はこれをメタ認知と呼んでいます。自分達が置かれた状態を客観的に理解し、正しく現状を把握する必要があります。ですが、自身が問題の渦中にいるとなかなかメタ認知できないものです。
力を抜いて、問題から一旦離れること。構造そのものが俯瞰できる位置まで精神を離す。心がけようと思います。
6. ここまでのまとめ
1. まずは教科書通りに
- なにもかも自分で作り上げる意味はない、巨人の肩に乗ろう
- さっさと作ってプロタイプ作ってアウトプットしたらいい
2. 実運用で重要なことはアジャイル
- イテレーションを素早く回して、 ブラッシュアップしまくる
- 自力で90%から99%にする労力は、 0%→90%と比較するとでかくてコスパ悪い
3. 関係者とのコラボレーションは必須
- さまざまな視点でバイアスや思い込みを排除できる
- 考えもしなかった、認識できていなかった問題に気付く
4. オブザーバビリティの重要性
- 障害の予防、発生に対する素早い収束
- ユーザとビジネスへのネガティブインパクトを最小に
5. 障害対応能力のアセスメント
- 現状を正しく認識することは非常に重要
- 現状認識を誤れば、その後の意思決定は無意味になりかねない
- 問題は構造の中ではなく、構造そのものにあることを忘れない
- メタ認知できるように問題に入り込みすぎない
また、障害対応フロー作成時点で取り組んでいなかったのですが、後々になってポストモーテムも導入しました。
ポストモーテムは一般的に以下の目的があります。
- 障害の根本原因の特定
- 再発防止策の策定
- 組織・チーム全体で共有し、学習する
この辺りは別記事としてまとめたいと思います。
7. 失敗談:人間・リーダーとしてのあり方
ここからは自分語りも含めた失敗談になります。
今回携わることができた「システム障害対応フローの策定」は自分一人の頭の中で作り上げられるものではありませんでした。周囲の方にご助力していただいた結果でしかありません。
最初は何から検討したらいいのかも解らず、POと一緒にブレストしたり、お互い自分なりに勉強したり、何もない中から少しづつ、土台を作っていく作業をおこなっていきました。そんな中で、少しづつ形が見えてきて自分なりの理想論やこだわりが見えてくるようになると、ある問題が顔を出してきました。
それは、自分の考え方や価値観に『とらわれる』ことです。理想やこだわりを持つことは良いことだと思います。ただし、それにとらわれ執着してはいけません。感情や考え方を自分で拘束してしまい、自由な発想や別角度からの視点を失ってしまいました。ひどくなれば、周囲の人間の意見も取り入れることができなくなります。
そして、非常に厄介なのが自分は正しいことをしているのに周囲の人は何故わかってくれないんだ、という思いを抱いてしまうことです。さらに、もう一つ。これまた厄介なのですが、それを『自分で自覚できないという』つまり『メタ認知できない』点です。
協力会社の方とある日、障害対応時のある役割について議論することがありました。
一対一で約2時間、話し合いました。端的に言うと、
- お相手「あなたの理解は間違っている。この役割の責務はここまでとするべきだ」
- 私「いいえ、ここは柔軟に対応できるよう責務を変更するべきだ」
といった趣旨です。結果、2時間後に私は自分の間違いを理解しました。その時感じたのは、申し訳なさと自己嫌悪です。自分の意見が正しいという認識にとらわれ執着し、相手の意見は間違っているという先入観を持って議論していたことに気付いたからです。恥すら感じました。相手の時間も無駄にさせてしまいましたし。
後日、(株)COTENが運営するポッドキャスト「COTEN RADIO」のMCであり(株)COTEN代表の深井龍之介さんの発言を聞いて、当時の自分の心理状態をはっきりと理解することができました。
メインMC樋口さん:
「対話や相互理解において最も重要なことは何ですか?」
深井さん:
「相手を馬鹿にしないことですね」
自分は相手を馬鹿にしてたんだと気付かされました。
以前から自分の問題点に自覚はありました。このままではいけないと。ですが、ここまではっきりと解像度高く自分の認識を理解できておりませんでした。あの時の自己嫌悪や恥と、ここでの言葉に気付かされたことによって私は一歩成長できたと感じました。
それでもまた同じ様な失敗をします。この後に私はスクラムマスターになるのですが、同じことを繰り返しました。恥ずかしながら私はすぐには変われないようです。今はより成長できていると感じますが、きっと残っているきっとまた繰り返すと思わなくてはなりません。
以前から人間としてどうあるべきか?という問いを持っており、その答えを出すべく色々と勉強してきました。人文学や哲学などの学問を学ぶことは、その答えを知るための良いアプローチだと思っています。
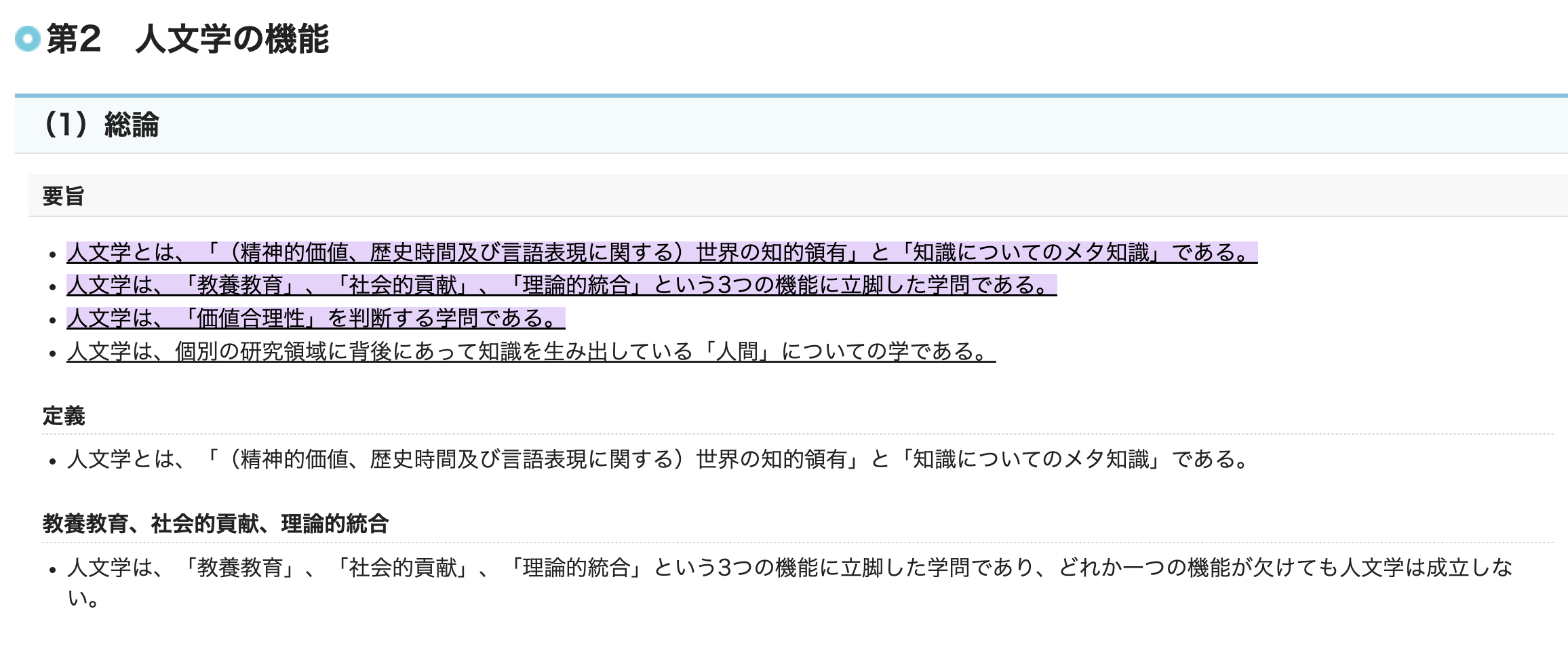
文部科学省:学術研究推進部会 人文学及び社会科学の振興に関する委員会(第11回) 配付資料 > 資料2 「人文学及び社会科学の振興に関する委員会」における主な意見(案)より
この中に以下の様な記述があります。
「価値合理性」の判断
人文学の仕事は、「価値の尺度」について判断することにあると考える。即ち、一定の「価値の尺度」を前提にして、その尺度に基づいて優劣を判断していくのではなく、「価値の尺度」そのものが本当に正しいのかどうかの論議を行い、判断をしていくこと、これが人文学、とりわけ哲学の仕事であると考える。
このような役割を人文学が果たすために、人文学の研究者は、社会や過去の古今東西の様々な考え方や色々な価値観の在り方を学び、自分の価値観、自分の帰属する社会の価値観を相対化している。また、異なる文化や過去の中に、自分たちと異なる価値観を発見し、学び、自分にフィードバックして自分の価値観、自分の帰属する社会の価値観を練り直していくのである。
そして、医学博士/随筆家・永井隆さんの書籍 「ロザリオの鎖」 には以下の文章があります。
──小学生に──
「もし物差の目盛の正しくないことを知らずに物の長さをはかるならば、あなたはいつも、まちがった値を正しいものと信ずることになるし、その値を友だちに知らせると、友だちにも、うそを信じさせることになります」
青空文庫:ロザリオの鎖より
以前から、この文章を読み自身の価値観を盲信する危険性を理解していたのに、いざその場になれば出来ないものです。ここでいう危険性とは
- 対話・相互理解の阻害する
- チームメンバーからの信頼を失う
- チームの多様性を殺す
- チームの心理的安全性を壊す
- チームのプロセスゲインを損なう
- チームの自律性を奪う
結果として
- プロダクトの質を落としユーザのUXを低下させる
- 企業に対する信頼の喪失
- ビジネス的な損害の発生
などを指します。当時は Java エンジニアでしたが、わたしは今スクラムマスターです。スクラムガイドには、以下の記述があります。
スクラムマスターは、スクラムチームと、より⼤きな組織に奉仕する真のリーダーである。
2020 スクラムガイドより
リーダーとして、この危険性を認識することは非常に重要だと考えています。
最近読んだ中国の古典である「貞観政要(じょうがんせいよう)」に、明君と暗君の違いについて以下のような記述があります。
君の明らかなる所以の者は、兼聴すればなり。その暗き所以の者は、偏信すればなり
明君の明君たる所以は、広く臣下の意見に耳を傾けることである。また、暗君の暗君たるゆえんは、お気に入りの臣下の言葉だけしか信じないことである。といった意味です。私は、お気に入りの人どころか自分の意見しか聞かなかった暗君の中の暗君だったのだと思わされました。
ここでの失敗を忘れずに今後も精進していかなければなりません。そして、自分に反論・異論をしてくれるメンバーとの信頼関係を失ってはいけないとも思いました。今後も自分が同じ間違いを起こさないとは、全く思えないからです。自分の過ちを指摘してくれる人、正してくれる人を失ったら本当に終わりだと思います。もし、その時がきたら、リーダーとしての器や能力が自分には無いと周りに評価されたということになります。
貞観政要とは?
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜中国で生まれた世界最高と言われるリーダー論・帝王学の古典。
唐(六一八~九〇七)の第二代皇帝、太宗・李世民と、その臣下たちの言行録。
この貞観(今で言う平成や令和)の時代は、長い中国の歴史で四回しかなかったとされる盛世、すなわち、国内が平和に治まり繁栄した時代のひとつといわれている。「政要」とは、政治の要諦を意味する。『貞観政要』とは貞観時代の政治のポイントをまとめた書物であり、そこには、貞観という稀に見る平和な時代を築いたリーダーと、そのフォロワーたちの姿が鮮明に記録されている。
のちの次代の皇帝たち、例えばモンゴル帝国の第五代皇帝クビライ、清の第六代皇帝乾隆帝、日本でいえば徳川家康や北条政子、そして明治天皇も帝王学を学ぶために愛読したといわれる。
リーダーとしてどうあるべきか悩んでる方には、ぜひお勧めしたいです。
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
最後に:筆者とデジタルバリューについて
本記事の筆者は、石川県金沢市に本店を置く地方銀行株式会社北國銀行(ほっこくぎんこう: The Hokkoku Bank, Ltd.)が、2019(平成31年)11月に設立したシステム開発会社である株式会社デジタルバリューに籍を置くものです。北國フィナンシャルホールディングスの一員として、日々業務に取り組んでおります。
私は、2023年4月にデジタルバリューへ入社し、2024年2月現在ジョインしているプロジェクトではバックエンド開発の他、スクラムマスターとしてスクラム開発体制の改善、QA・SRE的な観点から品質管理体制・障害対応および管理体制などの、各種体制整備などをしております。
入社してまだ10ヶ月、エンジニア歴2年4ヶ月と未熟な自分でもかなり幅広い業務に携わることができております。読み進めていく中で感じていただけたと思いますが、保守的な業界に見られる閉鎖的な空気や伝統的なだけの無意味な制度などはありません。むしろ、時代に沿った体制や制度が導入されている様に感じます。更に、やる気とキャッチアップする気があれば、チャンス・役割・責務を頂けます。
風通しが良く、心理的安全性が確保されており、立場役割に縛られることなく横断的に業務に取り組むことができています。面接時、代表である岩間さんに要望され私も望んだ「越境精神に基づいた行動」を十全に行うことができています。
とはいえ、銀行ですから堅い部分はあるべきこととして存在します。が、それも適切に再評価し必要であれば残すし、変更する余地があるならば変える。といった柔軟な取り組みをしていると認識しています。「銀行 SLO」で検索していただければ一行目に以下の検索結果が表示されるはずです。
以下記事に詳細があります。御一読頂ければ、より風土や文化が伝わるかと思います。もし興味を持っていただければ幸いです。
アジャイル思考でBaaSの提供へ
北國FHDは現在、システムによるサービスレベルの評価基準(SLO)においては、現金の供給・資金決済に影響があり代替手段がないシステムを最重要システムに位置付け、そこでの目標稼働率を99.95%に設定している(図3)。金融システムのSLOは99.99%が常識とされているにも関わらずだ。
引用元:北國フィナンシャルHD、アジャイル思考で顧客と銀行のために全力で取り組む
北國銀行 システム部部長 岩間 正樹 氏、「アジャイル経営カンファレンス」から
ここまでお読みいただきありがとうございました!!
入社したてのJavaエンジニアが、アプリリリース間近に迫る中で全く知見のない状態からシステム障害対応体制を作りました。その過程でぶつかった問題とそれに対する課題、それらにどう対応したのか、何を学んだのか。そして、障害対応体制の策定・構築や改善の流れの中で私が起こした失敗から、人としてリーダーとして何を心がけなければいけなかったのか?の反省についてのお話でした。
もしよければいいねお願いします!
筆者のTwitterアカウントです。
感想などお伝えしていただくと泣いて喜びます。
https://x.com/yoshitaro_yoyo