はじめに
豊田高専で情報工学を学んでいる3年生の加藤愛斗です。先日、CyberAgentさん主催の 3days サーバーサイド × ML/DS向け 開発型インターンシップ ~広告自動生成コンペ "極"~ に参加させていただき、様々なことを学んだためその経験を共有できればと思います。
コンペ内容
概要
商品に対する広告コピーを機械学習によって生成し、その性能を競うコンペ
詳細
{
"request_id": "hogehoge",
"商品に関する情報": "NDAにより略"
}
という形式のリクエストが来ます。(コピーを生成する商品の情報としてどのようなものが送られてくるかは、NDAにより省略させていただきます。)
- 予め共有されたブラックリストにrequest_idが含まれている
⇒ コピーの生成を行わずにレスポンス
(本当は、コピーを生成する商品の情報に不適切なワードが含まれていたらコピー生成を行わないなどとするが、今回のコンペでは時間的にそこまで出来ないのでこのような仕様がとられた) - ブラックリストにrequest_idが含まれていない
⇒ 自分たちで生成した機械学習モデルにより、コピーの生成を行い、上位3つの結果をレスポンスする
要件
サーバーサイド
- 300~600RPSに耐えられること
- 構成・デプロイ先全て自分たちで考える
- コピー生成リクエストは4~8requests/min
- ML側の推論モデルはこれを参考に軽量化する
- ブラックリスト(2700万行)はインメモリではなくDBに置く
- 上記RPSを考慮してDB選定・設計を行う
ML/DSサイド
- コピー生成対象の商品情報を用いて、コピー生成を行うモデルを作成
- 生成したコピー結果に対してランキングをつけるスコアリングモデルの生成
- レスポンスは3つのため、複数生成したコピーのどれを返すかを決めるために使用する
両サイド
- A/Bテスト
- 振り分けロジックを任意のサーバーに実装する
- 生成モデル or スコアリングモデルのどちらかを2つ作成
- 分析に必要なログを残す
評価指標
- 適切にレスポンスを返せたか
- ブラックリスト判定
- 鯖落ちしないか
- アノテーション評価(コピー生成結果がどうか)
- 妥当性
- 流暢性
- 新規性
- ABテストの分析
チーム
各チーム4人(ML/DS: 3, Server: 1)で、合計4チームで競いました。(CyberAgentの書類審査,1次,2次面接を通ってきている方なので全参加者とても優秀な方で、良い刺激をいただきました。)
リソース
- GCP ¥50,000-
私のチームがやったこと
リーダー決め
最年少(全参加者の中で)ながらチームリーダーを務めさせていただきました。
サーバー技術選定
- RPS600をさばく必要がある
- 高速 or/and 非同期のフレームワークを使用したい
- ML/DSサイドで作成したモデル(python)をのせる必要がある
- サーバー側も同じ言語に寄せたい
- 単純なAPI
- 軽量フレームワークで十分
⇒ FastAPI
(全チームバックエンドはFastAPIを使用していました)
サーバー構成
- サーバーを機能ごとに分ける or まとめる
- 機能: main, ML
- それぞれ必要なスペック・ワーカー数がかなり異なる
⇒ 分ける [main(blacklist判定), NLP-A, NLP-B] ←良い選択であった
- 環境構築
- デプロイ時のワーカー数は多数になる
- デプロイ時の環境構築の手間を省きたい
- local開発環境の差異による問題を埋めたい
⇒ Dockerを用いて作成
- デプロイ
- コンテナをまとめてデプロイしたい
⇒ Kubernetes ←反省(後述しますが、CloudRunなども調べた上で採択するべきだった)
- コンテナをまとめてデプロイしたい
(他チームは、CloudFunctionsとGCEを使用していたり、GCEのみだったりという感じでした。kubernetesは我々だけでした。← そりゃそう)
DB選定
- ブラックリストは2700万行
- 数値ではくUUIDのようなstr型なので二分探索はできない
- レスポンスをなるべく早く返したい = 低レイテンシ (RPS600に対応できるようにするため)
⇒ Google BigTable
(ほぼすべてのチームが BigTableを使っていた気がします。)
生成モデルの選定
- T5 (Text-To-Text Transfer Transformer)
- Encoder Decoder Model
- 今回のタスクではGPTは使えない(コピー生成方法はNDAにより詳しく記述していませんが、GPTは妥当ではないと我々は判断しました)
- Hugginfaceで手軽に使える
- sonoisia/t5-base-japanese
- 日本語コーパス(約100GB)を用いて事前学習を行ったT5 (Text-to-Text Transfer Transformer) モデル
- 転移学習のコードもある
- 事前学習済みのモデルを今回のデータでファインチューニング
スコアリングモデルの仕様検討
- A/Bテストはスコアリングモデルで分けることとなった(生成モデルを2つつくる時間がなかったため。予め話し合って決めたわけではなく、途中で流れで決まった。← ABテストの基礎知識を持つメンバーが誰もいなかったため)
- 機械学習モデル
- 筆者の理解が足りないため説明略
- TF-idf + コサイン類似度
- 筆者の理解が足りないため説明略
ABテスト
- 振り分けはmain serverで行う
- 50%の確率でA, 残りをB
- 難しいロジックは取ることが出来なかった
各々実装・作成
頑張りました。
結果
最終的な構成
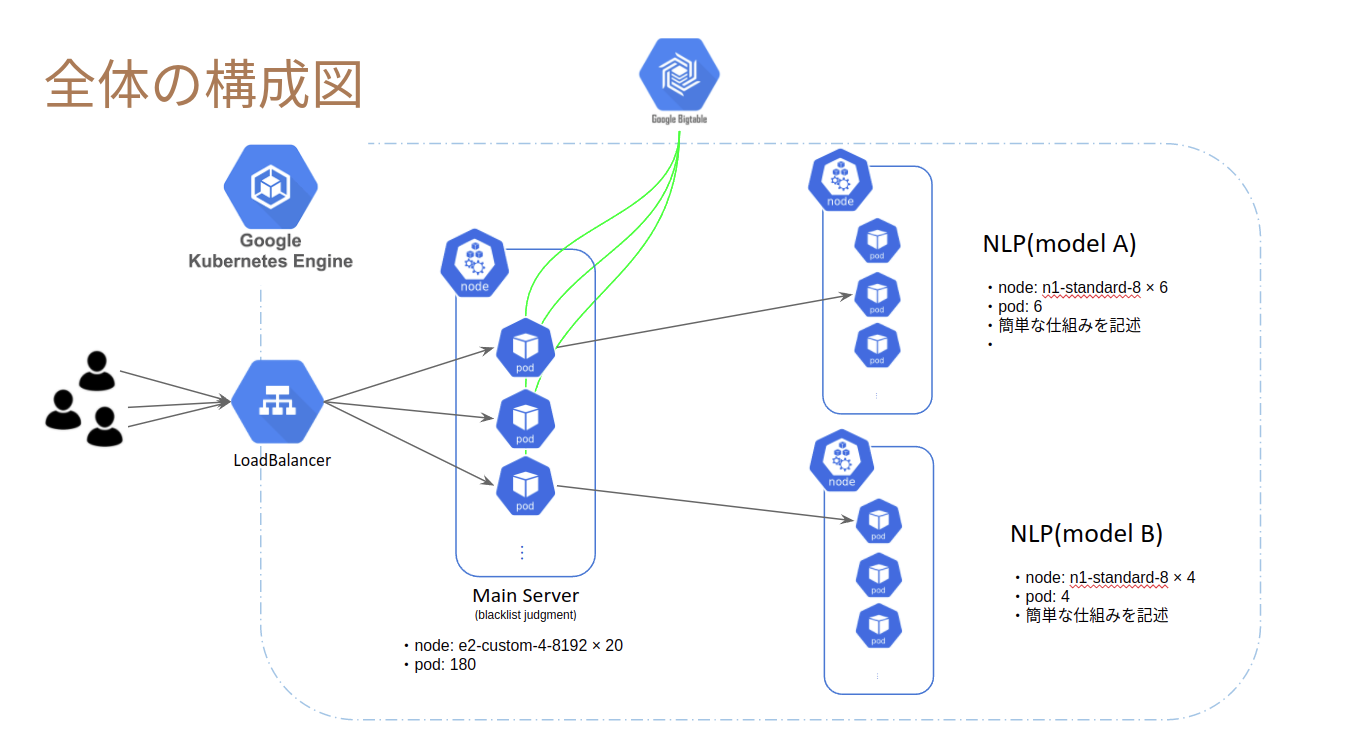
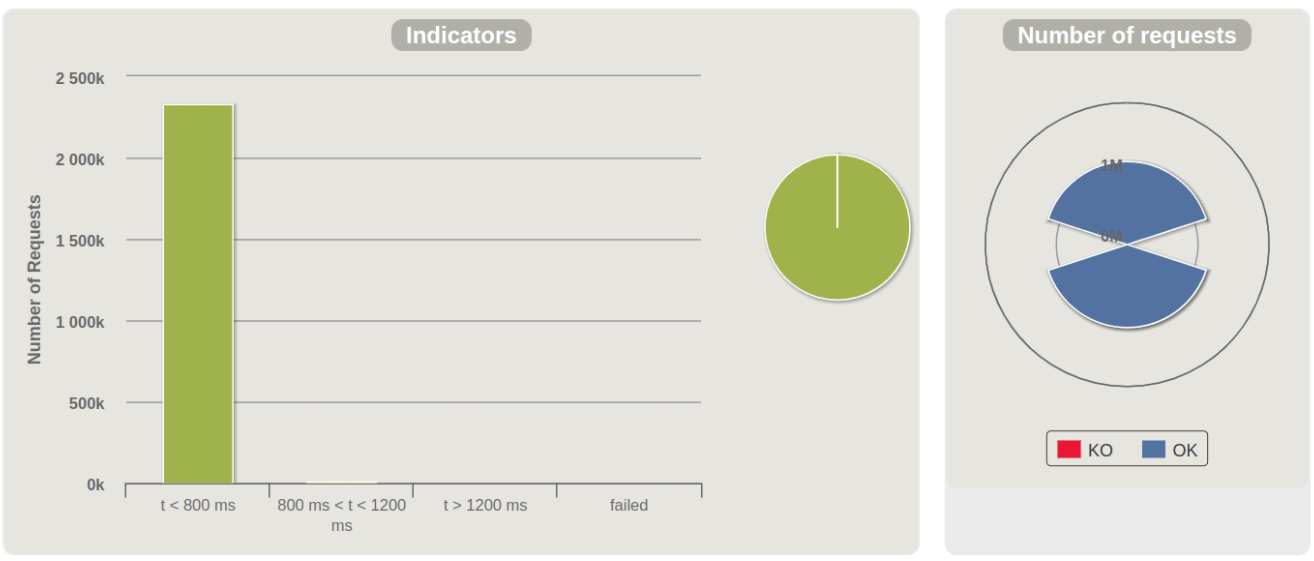
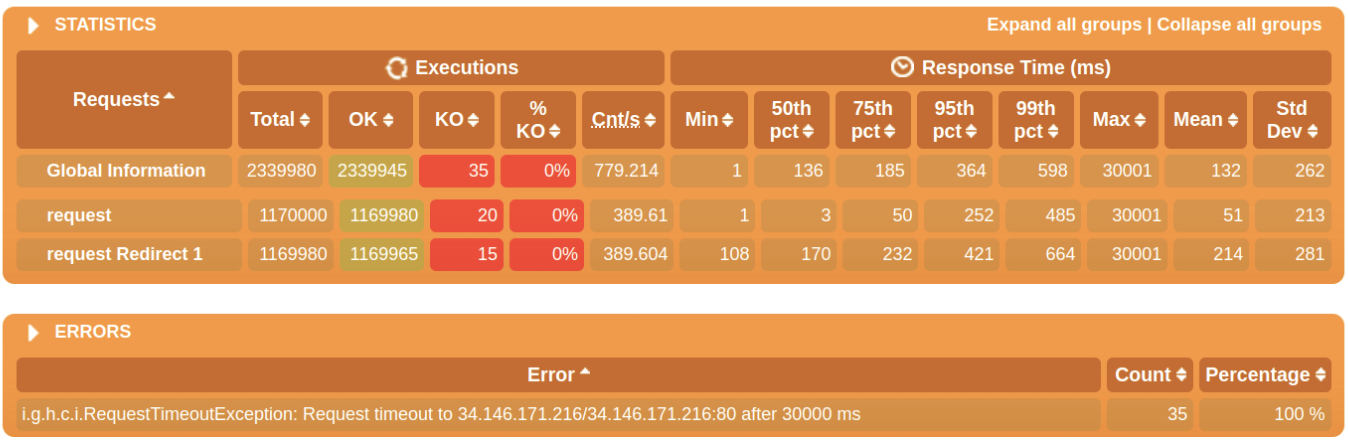
負荷テスト
- 100%正常にレスポンスを返せました。
Percentiles
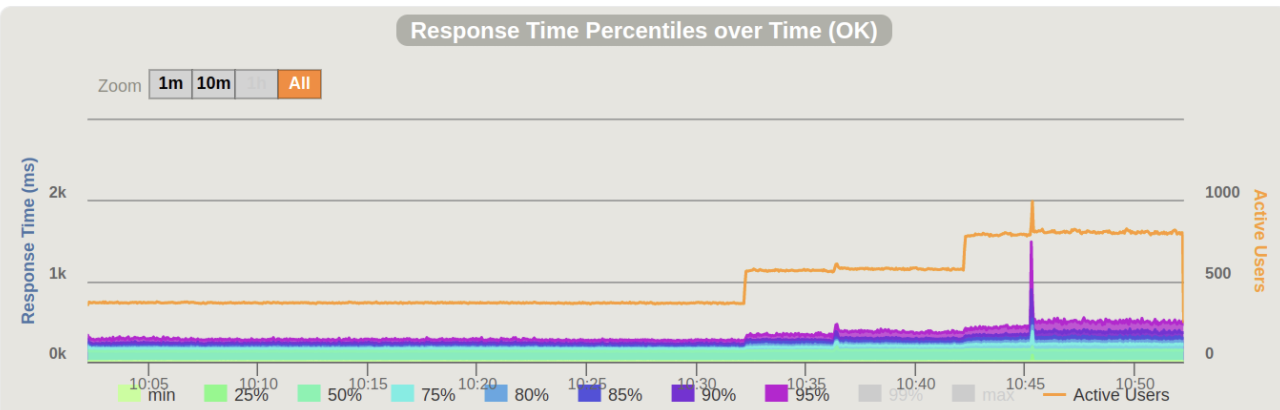
- ブラックリスト判定のレスポンスはほぼ500ms以下
- MLの推論は1sec以上かかるため、下記のpercentilesに含まれる
- BigTableのレイテンシの低さが活きている
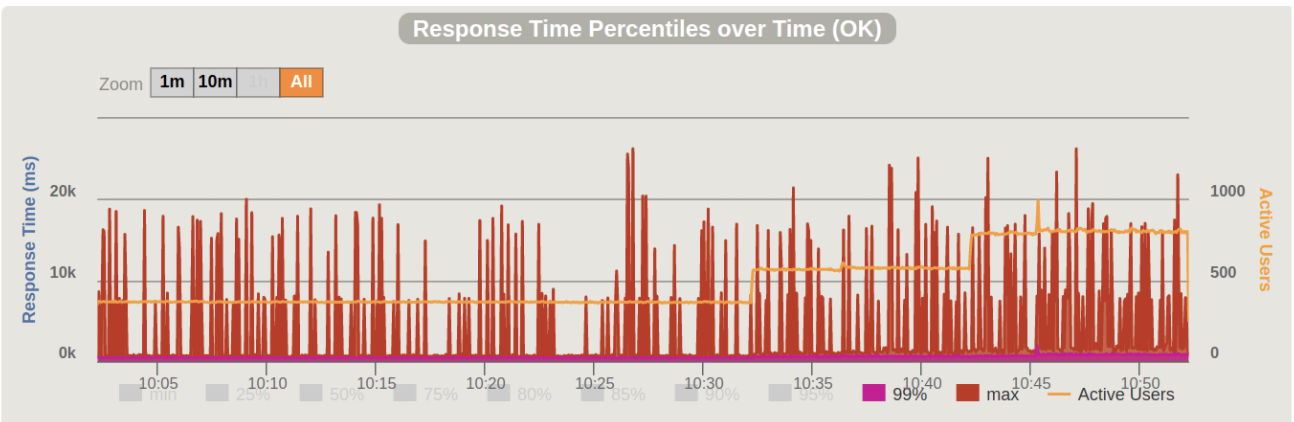
- それほど軽いモデルを作成できているわけではない
- MLサーバーのインスタンスはCPUのみだったため、GPUを使用できると改善できたかもしれない
- Dockerファイルの作成で詰まったためGPUの使用は断念した
生成モデル
- 結果はNDAにより略
考察
- 文法は正しい(流暢性Good)
- 訓練データをそのまま利用してコピーを作成している
反省
- 訓練データを分析してから学習するべきだった
- 単語の分布・偏りなど
- 広告のコピーということをもっと考慮
- キラーフレーズなど
- !や♡など
ABテスト
検証したいこと
評価指標:生成文の採用率
アノテーションデータ(リクエスト数*3)の集合でA,Bを比較
- Aモデル:機械学習モデルによるスコアリング
- Bモデル:元の文と生成文のTF-idfのコサイン類似度によるスコアリング
⇒ Aモデル、Bモデルで生成文の採用率に差がないことを帰無仮説としてt検定を行った。
結果
Aモデル:0.0816
Bモデル:0.1038
t = -2.7736
p-value:0.00556
⇒ 帰無仮説は棄却され、有意にBモデルの採用率が高い
個人的感想
(読み飛ばしてください。将来の自分のためにメモ書きです。)
最年少ながらチームリーダーを務めさせていただきましたが、ML側の知識不足で適切なタスク管理を行えませんでした。メンバーには迷惑をかけましたが、良いリーダーになるために必要なことを色々学ぶことが出来ました。
とても良いメンバーのチームで働けてとても楽しかったです。全員が全員を褒め合ったり、助け合ったり出来ていて非常に良い雰囲気でした。全員がはじめての経験のタスクが多く、色々なポイントでつまり、途中に「これ本当に完成するのかな?」と思ってしまうときもありましたが、全員が頑張った結果なんとか完成させることが出来ました。MLとサーバーのつなぎ込みが終わって、自分たちで負荷試験を見守った時間は、自分が作ったものが正常に動作しているワクワクと、チームででかい壁を乗り越えられた喜びは半端なかったです。とりあえず、このインターンに参加して、もっと頑張ろうという刺激を受けたり、インフラへの興味が湧いたりと、様々なメリットがあったので本当に良かったです。運営さん・メンバーに感謝です。
学んだこと
技術選定は慎重に
kubernetesを選んだ背景
今回は、インフラ構成から自分たちで考える必要がありました。インフラに詳しい人はおらず、RPS600がどれくらいなのか誰も検討がついていませんでしたが、とりあえず強いサーバーを建てなければいけないという感覚は全員が持っていました。そこで私が、複数台サーバーを立てるならば、Dockerで環境を立てておけばデプロイが楽なのではないかと提案し、その方向性で決まりました。次に、Dockerのコンテナを複数立ててまとめるサービスを決める必要がありました。この時点で既にインフラを担当するのは私となっていたので、ほぼ独断でkubernetesを採択しました。(インフラ経験者がチームにいなかったため、軽く確認は取りましたが他にいい案を知っている人はいない感じでした。) ここでの私のkubernetesに対する理解は、「コンテナをまとめていい感じにデプロイするサービスなんでしょ。リクエストに応じてコンテナを簡単に増やしたり出来るんでしょ。」という程度のものでした。一度もkubernetesを触ったことはありません。
そもそもDockerしらない [苦戦ポイント1]
業務で開発しているサービスがDockerで環境構築されているので、それのビルドやコンテナに入って少しコマンドを叩くなどのことは出来ました。逆にそれしか出来ないため、docker-composeを使用して、3つのサーバーをつなぐことですら苦労しました。
kubernetesの仕組み知らんけど?? [苦戦ポイント2]
なんとかして、docker-compose.ymlを書き上げて、それと同じ構成でkubernetesを用いてデプロイしようと取り組みます。
- 「ポッド」「コンテナ」「ノード」「Deployment」「Service」... と理解していない似た感じの単語が複数出てきて頭がパンク
- GKEとkubernetesの関連がよくわからん
- 色々コマンドがありますが、これはどっちのコマンド何だ?ってなってました
- docker imageをpushしておいて、それを元にコンテナが作成されることをこの時点で知る
- じゃあ、GCPのservice_account.jsonどうするんや??という疑問も出る
とりあえず無知すぎて大変でした。
ネットワーク周りがわからん [苦戦ポイント3]
コンテナ同士でどのようにネットワークが構築されているのかなどの知識がありませんでした。
適切なCPUがわからん [苦戦ポイント4]
600RPSさばくのにはどれほどのスペックのサーバーがいくつ必要なのかわかりませんでした。スレッドを増やすのか、ポッドを増やすのか、どのようにしたら効率が良いのかわかりませんでした。
反省
苦戦ポイント1, 2の状況で、kubernetesを選択してしまったことは失敗と言えます。今回のような短期間で成果を出さないいけないコンペでは、やったことのあるものor簡単なものを選択するべきでした。
コンテナをまとめていい感じにデプロイするサービスといえばkubernetesだと思っていたのですが、CloudRunというサービスもあるということをコンペの終盤で知りました。おそらく、CloudRunを使ったほうが圧倒的に簡単にデプロイ出来ていたと思います。時間のないコンペだからこそ、技術選定は丁寧に慎重に行ったほうが良いということを学びました。
自分が当たり前だと思っていることって案外当たり前じゃないよ
コンテナ同士のネットワークをどのようにつなぐか困ったときに、全てのポッドを外部公開するという手法も浮かんだのですが、何とか内部で収めて外部公開されているのは大元のLBだけにしたいという気持ちがありました。(セキュリティ観点と美しさの観点から。LBがhttpだからセキュリティもクソもないんですがそこはおいておいて。)そして、メンターさんのサポートを受けて何とか目標の構成でデプロイしました。最終発表の質疑応答の際に、ネットワークの構成に聞かれたので自分が作成したものをそのまま答えました。その後の懇親会でメンターさんとお話しているときに、「ネットワークの構成はしっかり作ってあるんだから、もっとアピールしたほうが良かった」というお言葉をいただきました。自分としては、不必要な外部公開をしないのは当たり前のことだと考えていたため、強くアピールしなかったのですが、メンターさん曰く「このようなコンペでは面倒だから外部公開する人が多いのに、そこをしっかり作っているのは高評価のポイント」だったそうです。
自分が当たり前と思って行っていることは、案外他人からすると凄い事の可能性もあります。他人から尊敬されるようなことを、自分の中では当たり前として行える人になりたいですね。
よいチームリーダーとは
別記(WIP)
最後に
このインターンから得られたことはものすごく大きく、本当に参加できてよかったと感じています!ここでの経験をこれからの成長につなげていきます!!
あとがき 〜学生エンジニアに伝えたいこと〜
「失敗から学べるやつが一番強い 失敗できるやつも強い 何もやらないやつはゴミ」
このインターンで僕は数々の失敗をしたし、それで迷惑もかけました。もちろん、失敗をしないことが一番良いことかもしれませんが、それはほぼすべての人には無理です。だからといって、失敗から逃げて何もしないことは一番良くないと考えています。
僕は以下のモットーを持って生活しようと心がけています。
- あるチャンスは絶対に掴む
- そのチャンスが成功しても失敗しても振り返り次に活かす
実は私はこのインターンの面接の前に、pixivさんのインターンの面接を受けており、そちらは見送りとなりました。しかしその経験・反省活かして(私は面接の最後に、面接がどうであったかフィードバックを貰うようにしています)、CyberAgentさんの面接を受けて採用いただきました。その結果、このような素晴らしい経験が出来、自分の大きな成長に繋がりました。大きな成長の前には無数の失敗が必要だと考えています。だからこそ、数々のチャンスを掴んで色々な経験をしたほうが良いと思います。
是非、このようなインターンなどのチャンスに積極的に応募していろいろな経験をしてください!