はじめに
ITに興味が湧き、初めは書籍、progateで学びましたが、もっと本格的に勉強したいことからプログラミングスクールに通うことにしました。
Aidemy Premium Planで画像認識を学び、
10種類の犬種を判別するアプリを作ってみました。
犬種はドーベルマン、フレンチブルドッグ、グレートデン、ポメラニアン、シーズー、シベリアンハスキー、ブラッドハウンド、パピヨン、パグ、スタンダードシュナウザーの10種類にしました。
目次
・1.Stanford Dogs Datesetから必要な画像を取得
・2.モデルの定義、学習
・3.改善
・4.最後に
1.Stanford Dogs Datesetから必要な画像を取得
画像のダウンロード
Stanford Dogs Dateset からImagesをダウンロードします。
デスクトップ等好きな場所に保存をし、フォルダの解凍を行います。
解凍には「Lhaplus」を使用しました。
フォルダ内には120の犬種がありますが、今回は10種類なので新しく10種類のフォルダを作成しました。
そのフォルダをgoogleのmy-driveへアップロードします。
my-driveとGoogleColaboratoryを接続する
先ほどmy-driveにアップロードしたフォルダをGoogleColaboratoryで使用するには、my-driveとGoogleColaboratoryを接続する必要があります。
下記コードをGoogleColaboratory上で実行します。
from google.colab import drive
drive.mount('/content/drive')
準備完了です。次はモデルを作成します。
2.モデルの定義、学習
インポート
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from sklearn.model_selection import train_test_split
# 画像サイズの決定
image_size = 100
画像の取得
# フォルダの取得
path_Doberman = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/Doberman') if not filename.startswith('.')]
path_Frenchbulldog = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/French_bulldog') if not filename.startswith('.')]
path_GreatDane = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/Great_Dane') if not filename.startswith('.')]
path_Pomeranian = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/Pomeranian') if not filename.startswith('.')]
path_ShihTzu = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/ShihTzu') if not filename.startswith('.')]
path_Siberianhusky = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/Siberian_husky') if not filename.startswith('.')]
path_bloodhound = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/bloodhound') if not filename.startswith('.')]
path_papillon = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/papillon') if not filename.startswith('.')]
path_pug = [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/pug') if not filename.startswith('.')]
path_standardschnauzer= [filename for filename in os.listdir('/content/drive/MyDrive/Colab Notebooks/images3/standard_schnauzer') if not filename.startswith('.')]
img_Doberman = []
img_Frenchbulldog = []
img_GreatDane = []
img_Pomeranian = []
img_ShihTzu = []
img_Siberianhusky = []
img_bloodhound = []
img_papillon = []
img_pug = []
img_standardschnauzer= []
# 画像の読み込み
for i in range(len(path_Doberman)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/Doberman/'+ path_Doberman[i])
img = cv2.resize(img,(image_size,image_size))
img_Doberman.append(img)
for i in range(len(path_Frenchbulldog)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/French_bulldog/'+ path_Frenchbulldog[i])
img = cv2.resize(img,(image_size,image_size))
img_Frenchbulldog.append(img)
for i in range(len(path_GreatDane)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/Great_Dane/'+ path_GreatDane[i])
img = cv2.resize(img,(image_size,image_size))
img_GreatDane.append(img)
for i in range(len(path_Pomeranian)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/Pomeranian/'+ path_Pomeranian[i])
img = cv2.resize(img,(image_size,image_size))
img_Pomeranian.append(img)
for i in range(len(path_ShihTzu)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/ShihTzu/'+ path_ShihTzu[i])
img = cv2.resize(img,(image_size,image_size))
img_ShihTzu.append(img)
for i in range(len(path_Siberianhusky)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/Siberian_husky/'+ path_Siberianhusky[i])
img = cv2.resize(img,(image_size,image_size))
img_Siberianhusky.append(img)
for i in range(len(path_bloodhound)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/bloodhound/'+ path_bloodhound[i])
img = cv2.resize(img,(image_size,image_size))
img_bloodhound.append(img)
for i in range(len(path_papillon)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/papillon/'+ path_papillon[i])
img = cv2.resize(img,(image_size,image_size))
img_papillon.append(img)
for i in range(len(path_pug)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/pug/'+ path_pug[i])
img = cv2.resize(img,(image_size,image_size))
img_pug.append(img)
for i in range(len(path_standardschnauzer)):
img = cv2.imread('/content/drive/MyDrive/Colab Notebooks/images3/standard_schnauzer/'+ path_standardschnauzer[i])
img = cv2.resize(img,(image_size,image_size))
img_standardschnauzer.append(img)
X = np.array(img_Doberman + img_Frenchbulldog + img_GreatDane + img_Pomeranian + img_ShihTzu + img_Siberianhusky + img_bloodhound + img_papillon + img_pug + img_standardschnauzer)
y = np.array([0]*len(img_Doberman) + [1]*len(img_Frenchbulldog) + [2]*len(img_GreatDane) + [3]*len(img_Pomeranian) + [4]*len(img_ShihTzu) + [5]*len(img_Siberianhusky)
+ [6]*len(img_bloodhound) + [7]*len(img_papillon) + [8]*len(img_pug) + [9]*len(img_standardschnauzer) )
モデルの構築~学習
# データの分類
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42,stratify=y)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルの構築
input_tensor = Input(shape=(image_size,image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="sigmoid"))
top_model.add(Dropout(0.1))
top_model.add(Dense(64, activation="sigmoid"))
top_model.add(Dropout(0.1))
top_model.add(Dense(32, activation="sigmoid"))
top_model.add(Dropout(0.1))
top_model.add(Dense(10, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
#optimizer=optimizers.SGD(lr=1e-1, momentum=0.9),
optimizer=optimizers.Adam(),
metrics=['accuracy'])
# 学習
# model.fit(X_train, y_train, batch_size=32, epochs=1, validation_data=(X_test, y_test))
# グラフ用
history = model.fit(X_train, y_train, batch_size=32, epochs=10, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# モデルを保存
model.save("my_model.h5")
Epoch 9/10
40/40 [==============================] - 2s 52ms/step - loss: 1.2049 - accuracy: 0.6599 - val_loss: 1.3478 - val_accuracy: 0.5902
Epoch 10/10
40/40 [==============================] - 2s 52ms/step - loss: 1.1095 - accuracy: 0.6998 - val_loss: 1.2896 - val_accuracy: 0.6011
validation loss:1.289649248123169
validation accuracy:0.6010928750038147
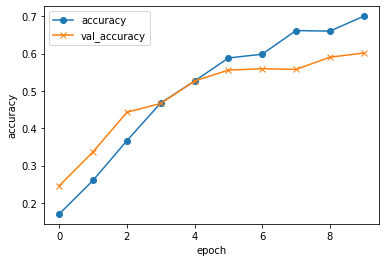
loss とは、0に近づくほど正解に近く、正解とどれくらい離れているかという数値です。
acc とは、1(100%)に近いほど正解に近い、正解率のことです。
val_loss と val_accはテストデータでの値です。
3.改善
上記のモデルの正解率は60%とあまり良くありませんでした。精度を上げる方法として、水増し等を用いて画像枚数を増やすことが挙げられます。
以下のコードを実行して水増しを行い、画像枚数を増やして学習させました。
import os
import glob
import numpy as np
from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
def draw_images(generator, x, dir_name, index):
# 出力ファイルの設定
save_name = 'extened-' + str(index)
g = generator.flow(x, batch_size=1, save_to_dir=output_dir, save_prefix=save_name, save_format='jpg')
# 1つの入力画像から何枚拡張するかを指定
# g.next()の回数分拡張される
for i in range(10):
bach = g.next()
if __name__ == '__main__':
# 出力先ディレクトリの設定(適宜変更)
output_dir = "/content/drive/MyDrive/Colab Notebooks/images3/standard_schnauzer/extended"
if not(os.path.exists(output_dir)):
os.mkdir(output_dir)
# 拡張する画像群の読み込み
images = glob.glob(os.path.join('/content/drive/MyDrive/Colab Notebooks/images3/standard_schnauzer', "*.jpg"))#ファイル名を指定
# 拡張する際の設定
generator = ImageDataGenerator(
rotation_range=90, # 90°まで回転
width_shift_range=0.1, # 水平方向にランダムでシフト
height_shift_range=0.1, # 垂直方向にランダムでシフト
channel_shift_range=50.0, # 色調をランダム変更
shear_range=0.39, # 斜め方向(pi/8まで)に引っ張る
horizontal_flip=True, # 垂直方向にランダムで反転
vertical_flip=True # 水平方向にランダムで反転
)
# 読み込んだ画像を順に拡張
for i in range(len(images)):
img = load_img(images[i])
# 画像を配列化して転置a
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
# 画像の拡張
draw_images(generator, x, output_dir, i)
以下コードを実行し、モデルの学習を行いました。
import os
import cv2
import tqdm
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from sklearn.model_selection import train_test_split
image_size = 100
img_Doberman = []
img_Frenchbulldog = []
img_GreatDane = []
img_Pomeranian = []
img_ShihTzu = []
img_Siberianhusky = []
img_bloodhound = []
img_papillon = []
img_pug = []
img_standardschnauzer= []
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/Doberman'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_Doberman.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/French_bulldog/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_Frenchbulldog.append(img)
for curDir, dirs, files in os.walk("/content/drive/MyDrive/Colab Notebooks/images3/Great_Dane/"):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_GreatDane.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/Pomeranian/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_Pomeranian.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/ShihTzu/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_ShihTzu.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/Siberian_husky/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_Siberianhusky.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/bloodhound/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_bloodhound.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/papillon/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_papillon.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/pug/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_pug.append(img)
for curDir, dirs, files in os.walk('/content/drive/MyDrive/Colab Notebooks/images3/standard_schnauzer/'):
print(curDir, dirs, files)
for i in tqdm.tqdm(range(len(files))):
file=files[i]
img=cv2.imread(os.path.join(curDir,file))
img = cv2.resize(img,(image_size,image_size))
img_standardschnauzer.append(img)
X = np.array(img_Doberman + img_Frenchbulldog + img_GreatDane + img_Pomeranian + img_ShihTzu + img_Siberianhusky + img_bloodhound + img_papillon + img_pug + img_standardschnauzer)
y = np.array([0]*len(img_Doberman) + [1]*len(img_Frenchbulldog) + [2]*len(img_GreatDane) + [3]*len(img_Pomeranian) + [4]*len(img_ShihTzu) + [5]*len(img_Siberianhusky)
+ [6]*len(img_bloodhound) + [7]*len(img_papillon) + [8]*len(img_pug) + [9]*len(img_standardschnauzer) )
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42,stratify=y)
# rand_index = np.random.permutation(np.arange(len(X)))
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
input_tensor = Input(shape=(image_size,image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="sigmoid"))
top_model.add(Dropout(0.1))
top_model.add(Dense(64, activation="sigmoid"))
top_model.add(Dropout(0.1))
top_model.add(Dense(32, activation="sigmoid"))
top_model.add(Dropout(0.1))
top_model.add(Dense(10, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
#optimizer=optimizers.SGD(lr=1e-1, momentum=0.9),
optimizer=optimizers.Adam(),
metrics=['accuracy'])
# 学習
# model.fit(X_train, y_train, batch_size=32, epochs=1, validation_data=(X_test, y_test))
# グラフ用
history = model.fit(X_train, y_train, batch_size=32, epochs=10, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# モデルを保存
model.save("my_model.h5")
(8397, 100, 100, 3)
(8397,)
(3599, 100, 100, 3)
(3599,)
Epoch 9/10
263/263 [==============================] - 13s 49ms/step - loss: 1.1344 - accuracy: 0.6052 - val_loss: 1.1568 - val_accuracy: 0.5949
Epoch 10/10
263/263 [==============================] - 12s 48ms/step - loss: 1.0829 - accuracy: 0.6255 - val_loss: 1.1571 - val_accuracy: 0.6046
validation loss:1.1570754051208496
validation accuracy:0.604612410068512
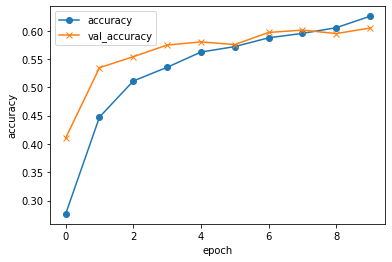
精度は60%と画像枚数を増やしても向上は見られませんでした。
4.最後に
初めは20%くらいだった精度を画像枚数を増やすことなく、「optimizer」や「lr」を変えることで向上させることができました。
それでも60%と十分な精度は得られず、画像枚数が原因ではないかと考え、水増しにより増やして改善を図りましたが、精度の向上は見られませんでした。
苦労した点は、精度向上と画像読込です。画像読込では「/」一つ抜けているだけで上手く読み込めず、どこにエラーがあるのかも詳しく表示されないので困りました。地道な作業と細かい箇所にも目を通すことの大切さを再認識しました。
今後は90%の精度を目指して、勉強を続け、知識を増やしていきたいと思います。
そしてなにより、Aidemyの素晴らしいチューターのサポートがあったからこそ最後まで楽しく作ることができたと思います。
アプリの作成だけでなく、指導方法等さまざまなことを学ばせていただきました。
三ヶ月間本当にありがとうございました!!!