Claude 3.7 Sonnet 概要
2025年2月25日に Claude 3.7 Sonnet が発表されました。まずは、このモデルについて理解を深めるために Claude を開発する Anthropic の発表記事を抜粋して読んでみましょう。以下は機械翻訳したものです。
私たちは他の市場に出回っている推論モデル(reasoning model)とは異なる哲学で Claude 3.7 Sonnet を開発しました。人間が素早い反応と深い思考の両方に単一の脳を使用するように、私たちは推論が完全に別のモデルではなく、先端モデルの統合された能力であるべきだと考えています。この統合されたアプローチはまた、ユーザーにとってよりシームレスな体験を生み出します。
たしかに直感的に感じるところにも近く、日常会話を行うときと仕事で考える時やコーディングをするときでは思考の深さが異なることは多々あるように思います。また、Anthropic は以下のように続けています。
Claude 3.7 Sonnet はこの哲学をいくつかの方法で体現しています。まず、Claude 3.7 Sonnet は通常の LLM と推論モデル(reasoning model)が一体となっています。モデルに通常通り回答させたい場合と、回答前により長く考えさせたい場合を選択できます。標準モードでは、Claude 3.7 Sonnet は Claude 3.5 Sonnet のアップグレード版を表しています。拡張思考モード(extended thinking mode)では、回答前に自己反省を行い、数学、物理学、指示に従う能力、コーディング、その他多くのタスクでのパフォーマンスを向上させます。
Claude 3.7 Sonnet はハイブリッド推論モデルとして、直感的な思考(標準モード)と段階的な思考(拡張思考モード)を使い分けて利用できることが大きな特徴でしょう。発表記事では AI のコード生成のベンチマークで飛躍的に性能が向上していることも触れられています。
また、同日に AWS の Amazon Bedrock からも Claude 3.7 Sonnet が利用可能になりました。以下にモデルアクセスの有効化の方法やマネジメントコンソールのプレイグラウンドでお試しする方法が紹介されています。Claude 3.5 Sonnet から据え置きの価格で利用できることも嬉しいですね。
日本語の医療分野について評価してみた
ヘルスケア業界では日々多くの業務をこなされている医療従事者の業務を補助するため、病院内での退院時サマリーの作成補助などのユースケースで生成AI の実証が進んでいます。一方で、汎用的な LLM が医療の分野で適切な回答ができるかや、さらに日本語を正しく理解できるか気になるという方は見えるかと思います。
利用するベンチマーク
前回の JMED-LLM を Amazon Bedrock ( Claude 3.5 Sonnet, Claude 3 Haiku ) で評価してみた では Amazon Bedrock を利用して Claude の評価を行いました。今回も JMED-LLM のベンチマークから質問応答タスクと文書分類タスクを利用して Claude 3.7 Sonnet が日本語の医療用語をどこまで理解できるかを評価してみたいと思います。JMED-LLM の詳細は以下をご確認ください。
実装してみる
基本は GitHub の JMED-LLM のリポジトリのコードをベースに書き換えていきます。Amazon Bedrock から Claude 3.7 Sonnet の拡張思考モード(extended thinking mode)を利用して評価していきます。
まずは config を修正します。
task_names: ["jmmlu_med", "crade", "rrtnm", "smdis", "mrner_disease", "mrner_medicine", "nrner", "jcsts"]
seed: 42
max_new_tokens: 512
trust_remote_code: False
- model_type: "huggingface" # "huggingface", "openai", "bedrock"
+ model_type: "bedrock" # "huggingface", "openai", "bedrock"
openai_api_key: False
- pretrained_model_name_or_path: "llm-jp/llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0"
+ pretrained_model_name_or_path: "us.anthropic.claude-3-7-sonnet-20250219-v1:0"
- save_file_name: "llm-jp-13b-instruct-full-dolly-ichikara_004_001_single-oasst-oasst2-v2.0"
+ save_file_name: "claude-3-7-sonnet-20250219-v1-0-extended-thinking"
dataset_dir: "datasets"
output_dir: "results"
use_system_role: True
custom_chat_template: False # "{% for message in messages %}{% if message['role'] == 'user' %}{{ '\\n\\n### 指示:\\n' + message['content'] }}{% elif message['role'] == 'system' %}{{ '以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。' }}{% elif message['role'] == 'assistant' %}{{ '\\n\\n### 応答:\\n' + message['content'] + eos_token }}{% endif %}{% if loop.last and add_generation_prompt %}{{ '\\n\\n### 応答:\\n' }}{% endif %}{% endfor %}"
quant_type: "none" # "none", "8bit", "4bit"
generator_kwargs:
top_p: 1.0
# do_sample: False
# repetition_penalty: 1.0
続いて、Converse API でのモデルの呼び出し部分のソースコードを一部修正します。
拡張思考モードの利用はadditionalModelRequestFieldsの中で有効化することができます。また、budget_tokensで思考時に利用するトークン数のターゲット値を設定することができます。この値に関して AWS ドキュメントでは最小は 1024、 Anthropic の推奨は 4000トークン以上との記載があります。以下の修正後の実装ではこの値を 4096 に設定しています。利用トークン数あたりの従量課金であるため、ある程度の目安を指定できるのは開発者視点ではありがたいポイントですね。
inferenceConfig の設定には注意しましょう。maxTokensの値はbudget_tokensの値を考慮して、これより小さくならないようにしましょう。そして、拡張思考モードの利用時は top_p のパラメータの指定はできず、temperature は常に 1.0 である必要があります。
import json
from pathlib import Path
import openai
import pandas as pd
import torch
import boto3
from sklearn.metrics import accuracy_score, cohen_kappa_score
from tqdm import tqdm
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig)
from src.utils import (exact_f1_score, get_evaluation_messages,
get_first_uppercase_alphabet, get_list_from_string,
num_openai_tokens, partial_f1_score, set_seed)
def evaluate(cfg):
set_seed(cfg.seed)
if cfg.model_type == "huggingface":
tokenizer = AutoTokenizer.from_pretrained(cfg.pretrained_model_name_or_path, trust_remote_code=cfg.trust_remote_code)
if cfg.custom_chat_template:
tokenizer.chat_template = cfg.custom_chat_template
if cfg.quant_type == "none":
model = AutoModelForCausalLM.from_pretrained(cfg.pretrained_model_name_or_path, device_map="auto", trust_remote_code=cfg.trust_remote_code)
elif cfg.quant_type == "8bit":
model = AutoModelForCausalLM.from_pretrained(
cfg.pretrained_model_name_or_path,
device_map="auto",
trust_remote_code=cfg.trust_remote_code,
quantization_config=BitsAndBytesConfig(load_in_8bit=True)
)
elif cfg.quant_type == "4bit":
model = AutoModelForCausalLM.from_pretrained(
cfg.pretrained_model_name_or_path,
device_map="auto",
trust_remote_code=cfg.trust_remote_code,
quantization_config=BitsAndBytesConfig(load_in_4bit=True)
)
model.eval()
elif cfg.model_type == "openai":
client = openai.OpenAI(api_key=cfg.openai_api_key)
elif cfg.model_type == "bedrock":
client = boto3.client("bedrock-runtime", region_name="ap-northeast-1")
inferenceConfig = {
- "topP": cfg.generator_kwargs["top_p"],
+ "temperature": 1,
- "maxTokens": cfg.max_new_tokens
+ "maxTokens": cfg.max_new_tokens + 4096
}
+ additionalModelRequestFields = {
+ "thinking": {
+ "type": "enabled",
+ "budget_tokens": 4096
+ }
+ }
with torch.inference_mode():
output_data = {}
output_data["model_name"] = cfg.pretrained_model_name_or_path
if cfg.model_type == "huggingface":
output_data["chat_template"] = tokenizer.chat_template
output_data["generator_kwargs"] = cfg.generator_kwargs
for task_name in tqdm(cfg.task_names, desc="Processing tasks"):
dataset_path = Path(cfg.dataset_dir).joinpath(f"{task_name}.csv")
dataset = pd.read_csv(dataset_path)
answer_list = dataset["answer"].tolist()
if task_name in ["jmmlu_med", "crade", "rrtnm", "smdis", "jcsts"]:
dataset["options"] = dataset.filter(regex="option[A-F]").apply(lambda x: x.dropna().tolist(), axis=1)
task_data = {}
response_results = []
for row in tqdm(dataset.itertuples(), desc=f"Processing {task_name} dataset", total=len(dataset)):
messages = get_evaluation_messages(row, task_name=task_name, use_system_role=cfg.use_system_role)
if cfg.model_type == "huggingface":
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
output_ids = model.generate(input_ids, max_new_tokens=cfg.max_new_tokens, **cfg.generator_kwargs)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
elif cfg.model_type == "openai":
input_token_len = num_openai_tokens(messages, model=cfg.pretrained_model_name_or_path)
max_tokens = input_token_len + cfg.max_new_tokens
response = client.chat.completions.create(
model=cfg.pretrained_model_name_or_path,
messages=messages,
seed=cfg.seed,
max_tokens=max_tokens,
**cfg.generator_kwargs
).choices[0].message.content
elif cfg.model_type == "bedrock":
system = [{"text":message["content"] for message in messages if message["role"] == "system"}]
messages = [{"role":"user", "content": [{"text" : message["content"] for message in messages if message["role"] == "user"}]}]
response = client.converse(
modelId = cfg.pretrained_model_name_or_path,
inferenceConfig = inferenceConfig,
+ additionalModelRequestFields = additionalModelRequestFields,
system = system,
messages = messages
- )["output"]["message"]["content"][0]["text"]
+ )
+ for block in response["output"]["message"]["content"]:
+ if "text" in block:
+ response = block["text"]
response_results.append(response)
if task_name in ["jmmlu_med", "crade", "rrtnm", "smdis", "jcsts"]:
predict_results = [get_first_uppercase_alphabet(predict) for predict in response_results]
if task_name in ["jmmlu_med", "crade", "rrtnm", "smdis", "jcsts"]:
score = accuracy_score(answer_list, predict_results)
task_data["accuracy"] = score
if task_name in ["jmmlu_med", "rrtnm", "smdis"]:
score = cohen_kappa_score(answer_list, predict_results)
task_data["kappa"] = score
if task_name in ["crade", "jcsts"]:
score = cohen_kappa_score(answer_list, predict_results, weights="linear")
task_data["kappa"] = score
elif task_name in ["mrner_disease", "mrner_medicine", "nrner"]:
answer_list = [get_list_from_string(answer) for answer in answer_list]
predict_results = [get_list_from_string(predict) for predict in response_results]
if task_name in ["mrner_disease", "mrner_medicine", "nrner"]:
score = exact_f1_score(answer_list, predict_results)
task_data["exact_f1"] = score
if task_name in ["mrner_disease", "mrner_medicine", "nrner"]:
score = partial_f1_score(answer_list, predict_results)
task_data["partial_f1"] = score
task_data["answer"] = answer_list
task_data["generated_text"] = response_results
task_data["predict"] = predict_results
output_data[task_name] = task_data
output_path = Path(cfg.output_dir).joinpath(f"{cfg.save_file_name}.json")
with open(output_path, "w", encoding="utf-8") as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
評価結果
それでは順番に各ベンチマークの評価結果を見ていきましょう。
質問応答タスク
まずは、質問応答のタスクの JMMLU-Med の結果です。JMMLU-Med(Japanese Massive Multitask Language Understanding in Medical domain)は、JMMLU から医療分野の問題のみを抽出し集約した質問応答タスクになります。Claude 3.5 Sonnet では 80% を切っていましたが、90% を超える精度を叩き出してきました。まだまだ改善の余地はあるスコアではりますが、大台にのってきた感じがありますね。

文書分類タスク
ここでは CRADE、RRTNM、SMDIS の文書分類タスクの結果を表示します。
CRAD(Case Report Adverse Drug Event)は、症例報告における薬品および症状から有害事象 (ADE) の可能性を分類するタスクです。

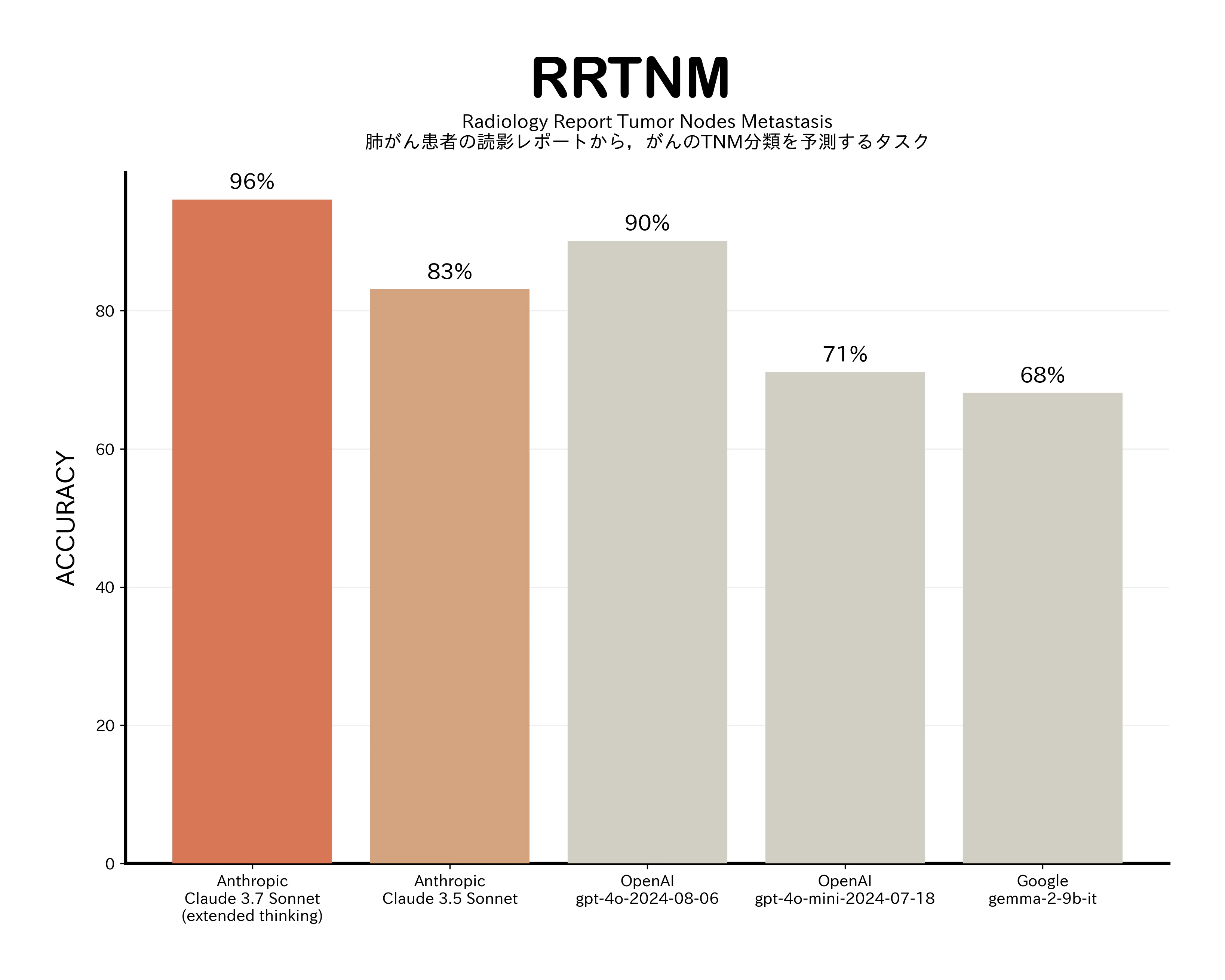
RRTNM(Radiology Report Tumor Nodes Metastasis)は、肺がん患者の読影レポートからがんのTNM分類を予測するタスクです。
SMDIS(Social Media Disease)は、模擬Tweetから投稿者または周囲の人々の病気や症状の有無を分類するタスクです。

以下リンク先のスライドでは JMED-LLM における各タスクごとに必要な専門知識レベルを4段階の★印で表現されています。
やはり専門知識を必要とする CLADE のベンチマークはどのモデルも苦戦しているように見えます。一方で、同じく★4の RRTNM ではモデルごとに差が出ていますが、Claude 3.7 Sonnet では 96%の精度を出しているのは興味深いですね。
まとめ
今回は日本語の医療分野のベンチマークである JMED-LLM を利用して Claude 3.7 Sonnet の拡張思考モードを評価しました。その結果、質問応答と文書分類のタスクで高いパフォーマンスを出し、いくつかのタスクでは 90% を超える精度も確認できました。
過去の Anthropic の記事では、思考に利用したトークン数だけ数学の文章題の試験(AIME 2024)の結果が良くなったという報告もあります。一方で、現実では思考で利用されるトークン数も従量課金でコストに直に影響してくるので、どれだけ思考を許すかという観点も重要になるかもしれませんね。
皆さんの今後の検証や検討の参考にしていただければ幸いです。それでは、また!
落穂拾い
実装で詰まったところ
検証の当初、Converse APIのリクエスト部分でresponse = client.converse(...)["output"]["message"]["content"][1]["text"]のようにしてClaudeの返答を受け取ろうとしていた。[0]ではなく[1]の理由としては、0番目にはreasoningTextとして思考の過程が返ってきて、その次に実際の出力テキストが返ってくると理解していた。しかし、検証コードを回すと途中でKeyError: 'text'で落ちる。それも、異なるタイミングで落ちる。なぜだろうと出力内容や仕様をAPI Referenceで確認すると思い当たるところが。

Anthropic のユーザガイドにも以下のような記述があった。つまり reasoninig の過程で safety system でフラグが立つと内容を暗号化してレスポンスを返すことがあるよということ。今回、医療データを扱っていたためおそらくこれに引っかかる部分があった様子。response の中身をきちんと確認して text を返すように実装を変えた。
Occasionally Claude’s internal reasoning will be flagged by our safety systems. When this occurs, we encrypt some or all of the thinking block and return it to you as a redacted_thinking block. These redacted thinking blocks are decrypted when passed back to the API, allowing Claude to continue its response without losing context.
文類似度タスクで精度が出なかった件
JMED-LLM には今回紹介しきれなかったタスクがある。その中でも2文の意味的類似度を判定するタスクの JCSTS では、思考拡張モードを利用すると Claude 3.5 Sonnet よりも精度が落ちたことが確認された。JCSTS は出題される2つの文章について、以下のA~Fの中から最も近いものを回答するタスクである。
A:二つの文は完全に同等で、意味が同じである。
B:二つの文はほぼ同等だが、いくつかの重要ではない詳細が異なる。
C:二つの文は大まかに同等だが、いくつかの重要な情報が異なっていたり欠けている。
D:二つの文は同等ではないが、いくつかの詳細を共有している。
E:二つの文は同等ではないが、同じトピックに関している。
F:二つの文は完全に似ていない。
問題は合計100問からなり、正解となる選択肢は次のように作問されている。A: 17問,B: 17問,C: 17問,D: 17問,E: 16問,F: 16問
ここで Claude 3.7 Sonnet の拡張思考モードでの回答をみると興味深いものが見えてくる。各選択肢の回答としての選択回数は次のようになったA: 2回,B: 25回,C: 30回,D: 16回,E: 22回,F: 5回。AやFの選択肢を回答として選ぶことは少なかった。これはA:二つの文は完全に同等で、意味が同じである。やF:二つの文は完全に似ていない。にあるような完全という表現の選択肢を避けているようにも見える。
これらは推測であるため、この点はもう少し考察が必要となる点であることには触れておきたい。
Claude 3.7 Sonnet のリージョン対応について
記事の執筆時点では Amazon Bedrock から利用可能な Claude 3.7 Sonnet は米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)のクロスリージョン推論を通じて利用ができる。日本の東京リージョンには対応していないため要件によっては注意が必要である。国内利用でニーズがある方はぜひ AWS にご相談いただければと思います。
GPT-4.5 も気になる
ちょうどこの記事を書き始めた2025年2月27日に OpenAI が GPT-4.5 を研究プレビューとして公開していた。前回の記事では GPT-4o も触りつつ検証をしたため、こちらも最新のモデルについて性能が気になるところではある。ただ、コストが GPT-4o の \$2.50/1M tokensから、GPT-4.5 では \$75.00/1M tokensとなったため、気軽に試すというのは少し難しそうなので必要性が出てきたらチャレンジしてみたい。
グラフのデザインを Anthropic に似せてみた
前回の記事の反省として、表形式での評価結果の出力だけだったためパッとみて評価の高いモデルがわかりにくかった。今回は、Claude 3.7 Sonnet と相談しながら評価結果をグラフ化するコードを作成した。 Anthropic が発表記事で出しているグラフ画像を入力として読み込ませて1発でそれらしい Python コードを出してきた点はやはりさすがだと感じた。フォントなども画像を入力に似たものを探せたので、実装で考えることが少なく体験として面白かった。