概要
2025年のはじめ、転送設定APIが公開されました。これはAPIで転送設定を作成や更新ができるようにするものとなります。また、対応コネクタは少ししかないですが、順次拡大されていきます。
また、コード管理もできるようにterraform providerがリリースされています。
https://registry.terraform.io/providers/trocco-io/trocco/latest/docs
これらを設定する上であったほうが良さそうな前提知識について解説します。転送元先でパターンが沢山あるので、この記事では転送元mysqlから転送先bigqueryとs3 to bigqueryに対象を絞ります。
難しいポイントその1: 設定項目自体多すぎ問題て設定が作りきれない問題
terraformを試す前に詳細APIを叩いてみます。
GUIで作成した転送設定の詳細APIを叩いてみます。
curl -H "Authorization: Token *****" https://trocco.io/api/job_definitions/{id} | jq .
レスポンス例と説明
{
"id": <id>,
"name": "qiita用 mysql to bigquery",
"description": "",
"is_runnable_concurrently": false,
"retry_limit": 0,
"input_option_type": "mysql",
"input_option": {
"mysql_input_option": {
"input_option_columns": [
{
"name": "id",
"type": "long"
},
{
"name": "name",
"type": "string"
},
{
"name": "email",
"type": "string"
},
{
"name": "created_at",
"type": "timestamp"
}
],
"database": "test_database",
"query": "select * from example_table;",
"incremental_loading_enabled": false,
"fetch_rows": 10000,
"connect_timeout": 300,
"socket_timeout": 1800,
"default_time_zone": "",
"use_legacy_datetime_code": false,
"mysql_connection_id": <id>
}
},
"filter_columns": [
{
"name": "id",
"src": "id",
"type": "long",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
},
{
"name": "name",
"src": "name",
"type": "string",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
},
{
"name": "email",
"src": "email",
"type": "string",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
},
{
"name": "created_at",
"src": "created_at",
"type": "timestamp",
"default": "",
"format": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
}
],
"output_option_type": "bigquery",
"output_option": {
"bigquery_output_option": {
"dataset": "test_dataset",
"table": "example_destination_table",
"auto_create_dataset": false,
"open_timeout_sec": 300,
"timeout_sec": 300,
"send_timeout_sec": 300,
"read_timeout_sec": 300,
"retries": 5,
"mode": "append",
"location": "US",
"template_table": "",
"bigquery_connection_id": <id>,
"before_load": "",
"bigquery_output_option_column_options": [],
"bigquery_output_option_clustering_fields": [],
"bigquery_output_option_merge_keys": []
}
}
}
設定項目が多いということがわかります。これでもSTEP2のフィルターやマスキングなどの設定を省略していますが、それらの情報が増えると設定項目はまだ多くなると予想されます。
設定がそもそも多いのでSTEP1, STEP2と別画面で転送設定を登録するようなGUIだと思います。そもそも項目は多いのです。それをAPI化、terraformで管理しようとしているので、それは当然の結果となります。これをterraformで管理しようにもresourceを作るのがひと苦労という感じだと思います。
解決方法のひとつとして以下を提唱します。

転送設定をGUIで作る -> terraform importする -> diffがでないようにする これでひとまずは作成のためのすべての項目を理解しなくてもterraformで管理できるようになります。とはいえ、作成時から管理したいという場合フィールドの理解が必須となります。
難しいポイントその2: 設定が何を示しているのかわからない問題
↑でmysql to bigqueryのペイロード例を書きましたが、いまいちわからんな、というカラムもあるかと思います。それについて解説したいと思います。
| key名 | これは何 |
|---|---|
| input_option.mysql_input_option.input_option_columns | GUIにはない項目だと思います。これはmysqlの場合、転送元mysqlは select * from hogehoge_Table; のようなクエリを書いて設定すると思います。GUIの場合、STEP2に遷移するタイミングで実際の * の部分がどんなカラムと型なのか、という情報を取得しています。しかしterraformやAPIでの管理の場合非同期処理できない点や、IaCしたいのに知らないところでデータが書き換わっているということを防ぐため、ユーザー自身で設定するような構成を取っています。 |
| filter_columns | STEP2のカラム定義の部分です。実際のETLでは元のカラムを先のどのカラムに転送するか、というような設定についてここのフィールドで実施します。 |
| filter_columns.json_expand_enabled | STEP2のカラム定義の部分です。jsonカラムの場合、jsonの中の一部だけ抽出して転送ということもサポートされています。この項目をtrueにすることで展開するかどうかが決定できます。 |
| filter_columns.json_expand_keep_base_column | STEP2のカラム定義の部分です。json_expand_enabledをtrueにしたからとはいえ、jsonそのものも送りたいというケースの場合、ここはtrueにします。 |
| filter_columns.json_expand_columns | STEP2のカラム定義の部分です。json_expand_enabledがtrueの場合、どういう項目を抽出するかを設定します |
| filter_columns.json_expand_columns.name | STEP2のカラム定義の部分です。どんなカラム名で転送するかを指定します。 |
| filter_columns.json_expand_columns.json_path | STEP2のカラム定義の部分です。jsonをどうたどるかを指定します。 person.id など |
| output_option.bigquery_output_option.bigquery_output_option_column_options | filter_columnsを定義している場合、なくても動くとははずですが、BQ側の型やフォーマットなど詳細に管理したい場合、このフィールドで設定します。 |
| output_option.bigquery_output_option.bigquery_output_option_column_options | filter_columnsを定義している場合、なくても動くとははずですが、BQ側の型やフォーマットなど詳細に管理したい場合、このフィールドで設定します。 |
↑はほんの一部の抜粋です。詳細はAPIドキュメントを参照するのが良さそうです。
難しいポイントその3: 転送元によって設定する項目が違う問題
ポイントその2で input_option.mysql_input_option.input_option_columns の項目の解説をしました。しかし例えば転送元s3の場合はそんなものありません。以下がs3 to mysqlの設定項目の例です
{
"id": <id>,
"name": "s3 to bigquery exmaple",
"description": "",
"is_runnable_concurrently": false,
"retry_limit": 0,
"resource_enhancement": "custom_spec",
"input_option_type": "s3",
"input_option": {
"s3_input_option": {
"csv_parser": {
"delimiter": ",",
"quote": "\"",
"escape": "\"",
"skip_header_lines": 1,
"null_string_enabled": false,
"null_string": "",
"trim_if_not_quoted": false,
"quotes_in_quoted_fields": "ACCEPT_ONLY_RFC4180_ESCAPED",
"comment_line_marker": "",
"allow_optional_columns": false,
"allow_extra_columns": false,
"max_quoted_size_limit": 131072,
"stop_on_invalid_record": true,
"default_time_zone": "UTC",
"default_date": "1970-01-01",
"newline": "LF",
"charset": "UTF-8",
"columns": [
{
"name": "id",
"type": "long",
"format": null,
"column_order": 0
},
{
"name": "name",
"type": "string",
"format": null,
"column_order": 1
},
{
"name": "age",
"type": "long",
"format": null,
"column_order": 2
},
{
"name": "description",
"type": "string",
"format": null,
"column_order": 3
}
]
},
"bucket": "trocco-test-kkatamot",
"path_prefix": "large",
"path_match_pattern": "",
"region": "ap-northeast-1",
"incremental_loading_enabled": false,
"is_skip_header_line": false,
"stop_when_file_not_found": false,
"s3_connection_id": <id>,
"decompression_type": "default"
}
},
"filter_columns": [
{
"name": "id",
"src": "id",
"type": "long",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
},
{
"name": "name",
"src": "name",
"type": "string",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
},
{
"name": "age",
"src": "age",
"type": "long",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
},
{
"name": "description",
"src": "description",
"type": "string",
"default": "",
"has_parser": true,
"json_expand_enabled": false,
"json_expand_keep_base_column": false,
"json_expand_columns": []
}
],
"output_option_type": "bigquery",
"output_option": {
"bigquery_output_option": {
"dataset": "kkatamot_test",
"table": "aaaaaa",
"auto_create_dataset": false,
"open_timeout_sec": 300,
"timeout_sec": 300,
"send_timeout_sec": 300,
"read_timeout_sec": 300,
"retries": 5,
"mode": "replace",
"location": "asia-northeast1",
"template_table": "",
"bigquery_connection_id": <id>,
"before_load": "",
"bigquery_output_option_column_options": [],
"bigquery_output_option_clustering_fields": [],
"bigquery_output_option_merge_keys": []
}
}
}

ちなみにcsv_parser以外もあります。jsonl_parserやjson_path_parser、ltsv_parserなどがあります。これは画面でいうところの以下の部分の設定となります(STEP2の入力オプション)。文字列から推測できるとは思いますが、入力元がファイルの場合、どういうフォーマットで解析してETLすべきかを設定します。mysqlでいうinput_option_columnsに相当する項目はcsv_parser配下のcolumnsという項目で指定できます。
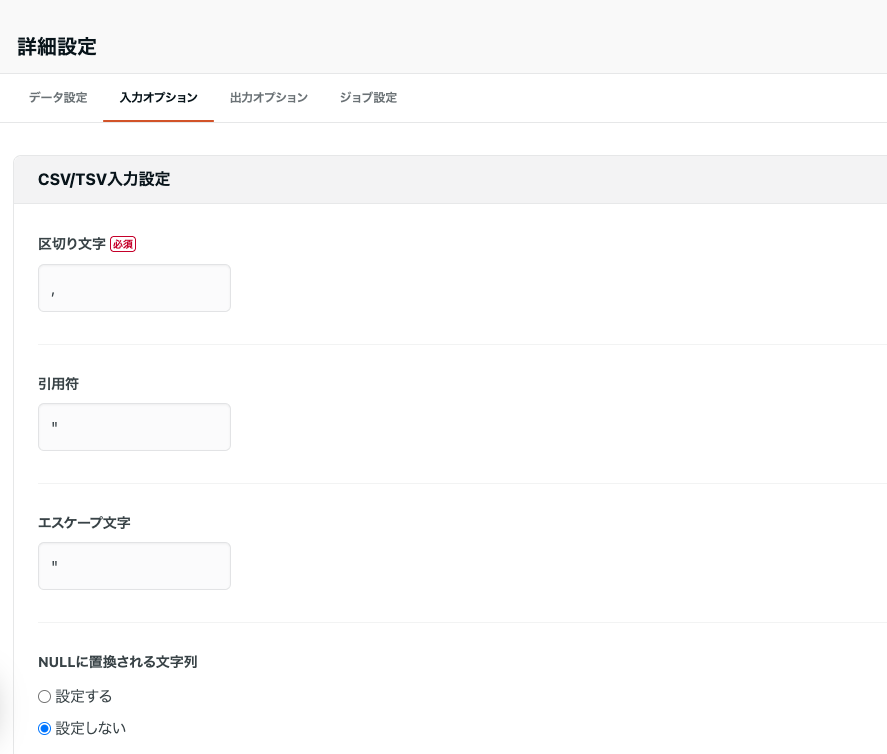
例外はいくかあるとは思いますが、以下の法則で設定項目が変わると想像することができます。
転送元がファイルベースなもの -> xx_parserでファイルフォーマットを指定してxxx_parser.columnsで入力のカラムを指定することになる
転送元がファイルベースではない場合 -> input_option_columnsで入力のカラムを指定することとなる
これも前述の通り本来GUIの場合自動で導出されていたものですが、terraformの場合、自ら指定するほうがIaCの観点からも良いと判断してこうなっています。
まとめ
- troccoの設定は項目が多くて、いきなり全部Terraformで書くのは大変です。 -> GUIで作ってterraform importするほうが結果として楽かもです
- データの転送元によって書き方が変わるので、その部分を理解しておくだけでも混乱せずに変更が用意かもしれません