遅刻してごめんなさい!
ここでは、「負荷が高い」とはリソースが枯渇した、あるいは枯渇しそうな状態で、かつそれがシステムに影響を及ぼしている、あるいは影響を及ぼしうる状態を指します。
負荷の傾向を見る
snmpdが返す値や SHOW ENGINE INNODB STATUS などの値を見て負荷の傾向を見ましょう。
当社ではCloudforecastを使ってこれらの情報メトリクスとして収集しています。
メトリクスを常に計測しておき、通常の状態と異常な状態を可視化しておくことは非常に重要です。
CPUネックかIOネックか
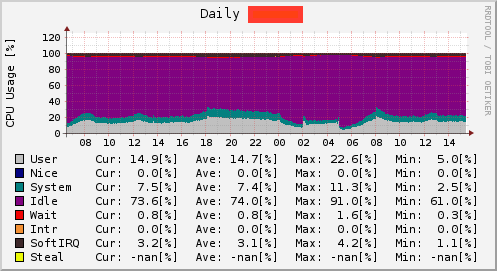
負荷の原因としてどのリソースが不足しているのかを見極めます
CPUが原因で詰まっているか、IOが原因で詰まっているか、という具合で大別できるのでまずそれを見ましょう。
CPUネックの場合はCPUを100%近く使いきっていることが多いです。
また、複数コアあって一部のコアを使い切っている場合も多いです。
CPU使用率が特定の数で張り付いていた場合、一部のCPUを使いきっている可能性を考えて良いでしょう。
IOが原因で詰まっている場合は多くの場合、CPU使用率のio waitが上がります。0%付近で安定するのが理想的な状態です。
SSDなど高速なストレージを使っている場合はio waitが殆ど上がらない場合もあります。
主にInnoDBを使っている場合はBuffer PoolへのRead/Writeの量を見るという手があります。
IOネックである場合に、Read/Writeのどちらがネックになっていそうか当たりをつけることができます。
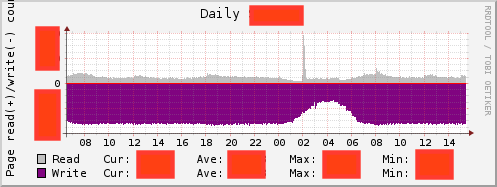
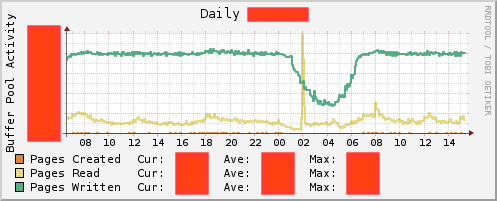
クエリの傾向
クエリの改善によって負荷の傾向を改善できる場合があります。
MySQL Handlersをみることでクエリの傾向をある程度推測することができます。
たとえば、Handler Read Rnd Nextが出ているとランダムリードが多いと言うことができるため、フルテーブルスキャンが発生している可能性があると言えるでしょう。
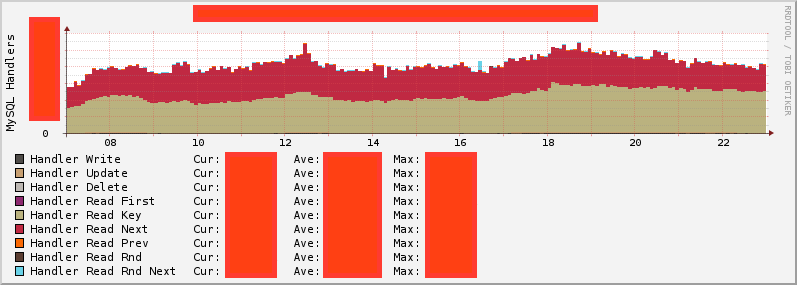
また、Slow Query Logを出しておいて、それを見るのも良いでしょう。
簡単に集計するにはMySQL付属のmysqldumpslowを使うと良いです。
mysqldumpslow -s t /var/lib/mysql/slow-query.log # 時間順
mysqldumpslow -s c /var/lib/mysql/slow-query.log # 回数順
slow query logだけでは、N+1問題を発見することは難しいため、より詳細な解析が必要になる場合があります。
その場合はpt-query-digestを使うと便利です。
ほか、常にslow query logを常にtailしてtmuxに流しておくと、問題解決に役立つ場合があります。
クエリの解析と改善
ボトルネックとなっていそうなクエリを発見したらそれを詳しく調べます。
EXPLAINを活用しましょう。
詳しい話はいろんなところでなされているのであえてここで詳しく触れる必要はないでしょう。
ざっくり、 Using filesort や Using temporary などが出たら要注意。
また、 TYPEが ALL になっている場合はフルテーブルスキャンとなっていますので危険です。
EXPLAINを見ながら、うまくINDEXを活用したり、Slaveで良いクエリはSlaveに追いやったり、不要なソートをなくすなど、クエリを改善します。
可能であればINDEXを追加するなどの対策も行って良いでしょう。(ただし、運用中のシステムの場合、システムの機能に影響を出さないようテーブルロックの時間に注意する必要があります。)
最初に戻る
改善を行ったら、負荷の傾向の変化を観察しましょう。
場合によっては裏目に出る場合もあります。また、システムの機能を破壊していないか、アプリケーションのエラーも監視するべきでしょう。
リソースに余裕ができたら対応完了です。やりましたね!
まとめ
かなりざっくりではありますが、MySQLの負荷が高くて困ったときにやることを書いてみました。
これらは一朝一夕で出来るものではありません。
普段からメトリクスやログを見て、ちょっとした問題でも詳しく調べてみる。といったことを心がけてみて、普段からこれらのエミュレートしておくと良いでしょう。