事前準備
以下のコマンドで、ライブラリをインストールしてください
go get -u github.com/PuerkitoBio/goquery
使い方
やり方の手順として以下の手順でやります。
- URL情報の抽出
- プログラムを書く
- 実行
URL情報の抽出
まず、スクレイピングしたいURLを決める必要があります。
今回は、Amazonの本検索でISBMの検索をしたときに一番最初に来たデータからタイトルを抽出するようにします。
日経Linux 2020 7月のISBMは4910071930709のため4910071930709で検索します。
ブラウザのF12などをおして、デベロッパツールでタイトル部分のHTML情報を調べましょう
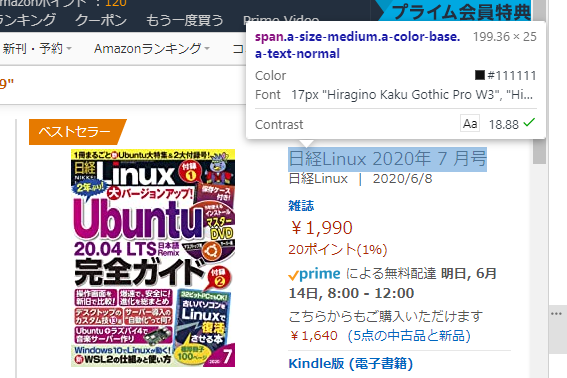
上記図を見ますと、タイトルの部分の情報で使われているCSSの情報は**.a-size-medium.a-color-base.a-text-normal**ということがわかります。
これをキーワードに検索をかけましょう
Goのコードを書く
以下のように記載します。
main.go
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
)
func main() {
isbm := "4910071930709"
url := "https://www.amazon.co.jp/s?k=" + isbm + "&i=stripbooks"
doc, err := goquery.NewDocument(url)
if err != nil {
fmt.Println(err.Error())
}
doc.Find(".a-size-medium.a-color-base.a-text-normal").Each(func(i int, s *goquery.Selection) {
if i == 0 {
fmt.Println(s.Text())
}
})
}
プログラムの順序を簡単に説明しますと以下の順序になります。
- スクレイピング対象のURLを決める
- URLからデータを持ってくる
- 「.a-size-medium.a-color-base.a-text-normal」クラスのデータを抽出する
- 一番初めに抽出したデータ内のテキストのみ出力する
実行結果
実行すると以下のような結果が得られます。
$ go run main.go
日経Linux(リナックス) 2020年7月号
なお、などの使用されている、**href=**の結果を取得したいときは、
urldata := s.Attr("href")
などと記載すると取得することができます。