処理系は完全に初心者なので間違っている所を指摘して頂けると嬉しいです。
はじめに
Pythonのfor文って遅いですよね。
競技プログラミングでPythonを使う際、実行時間を意識するときはより速いPyPyで提出しています。
この遅い原因はPythonの実装のどこから来るものなのでしょうか?
簡単に挙げられる例としてスクリプト言語、動的型付け言語、GILがあるからなどでしょうか。
この中で単純なfor文と関係してきそうなのは前の2つです。
一行ずつ実行するならfor文の中のコードは毎回コンパイルされて実行されていると考えるのは自然だと思います。
しかし、あまりにも効率が悪いのでfor文は初めに一括でコンパイルされてキャッシュされていそうです。
そう考えるとスクリプト言語はfor文にあまり影響を与えていなさそうですが、あくまで憶測なので実際にコードを追わないとわからないです。
次に、動的型付け言語だと何故遅くなるのか。これはコードの実行の度に型チェックをする必要があるからです。
例えば文字列型と数値型の足し算をしようとしたときにエラーを出さなければならず、この為に毎回型チェックが必要になります。
for文の中でも例外ではなく、実行されたコードに毎回型チェックが入るとオーバーヘッドが大きくなりそうです。
ただ、やはり実際にソースコードの各処理がどれだけ時間を割いているといった情報が欲しいと思いました。
そこで今回はPythonの一般的な処理系であるCPythonをfor文の観点から調査してみました。
またCPythonはC言語で実装されているのでC言語のfor文の速度と比較しました。
Version
- Python 3.11.0a0
- gcc version 9.3.0
今回の比較に使うコードと速度
$10^8$回 s+=1をするだけの単純なコードです。
def main():
s = 0
for _ in range(100000000):
s += 1
if __name__ == "__main__":
main()
int main() {
int s = 0;
for (int i=0;i<100000000;i++) {
s += 1;
}
}
Pythonはソースコードから--enable-optimizationsをONにしてビルド、C言語はソースコードを-O0で最適化を使わずコンパイルしました。
ここでPythonだけ最適化をしていると思うかもしれませんが、これは処理系だけでソースコードの最適化をしているわけではないので問題ないです。普段使っているPythonも最適化してビルドされています。(gccを最適化してビルドするのと似ている)
これらの速度を計ってみました。
| Python | C言語 |
|---|---|
| 0m5.115s | 0m0.363s |
Pythonは5.11s, C言語は0.36sと10倍以上の差が付きました。
やはりPythonのforはC言語と比べて非常に遅いです。ではこの違いがどこから来ているのかを調べていこうと思います。
いきなりPythonから入る前に、C言語のforの挙動を見ていきます。
C言語でのfor文中の処理が増える時の挙動
まず始めに、どのような場合に処理時間がかかるのでしょうか?
これは当たり前ですが、単純に処理内容が増えるとその分時間がかかります。
CPUへの命令が増えれば当然重くなります。
では、s+=1が10個に増えると実行時間はどうなるでしょうか。
ちょっとぐらいコードが割り増しされてもそこまで実行時間に影響はないと思いますか?
次のコードの速度を測ってみました。
int main() {
int s = 0;
for (int i=0;i<100000000;i++) {
s += 1;
s += 1;
s += 1;
s += 1;
s += 1;
s += 1;
s += 1;
s += 1;
s += 1;
s += 1;
}
}
結果は0m3.410sと約10倍近い時間になってしまいました。
これは$10^8$回のfor文の中でs+=1が9個増えたので、C言語からみた命令は$9 \times 10^8$個も増加していることになります。
つまり、大きいfor文の中で処理が増えるとそれに応じて処理時間がかかるということです。
ここでPythonの処理系はCPythonでC言語で実装されているので、Pythonのfor文はC言語のループに変換されていそうです。
ただ足し算をするだけでも、そのループ内でPython独特の処理が入ってくると、非常に重くなりそうです。
それでは次にPythonの処理系を見ていきましょう。
s+=1の数を10倍に増やしたから実行時間が10倍になったわけではないです。
正確な実行時間を計算で求めるにはアセンブリを見て、各命令に必要なクロック数などを調べる必要があります。
Pythonの処理系について
Pythonのソースコードを追う前に、簡単に処理の流れを説明します。
Pythonの実行の流れは以下のようになっています。
仮想マシン <- バイトコード(中間言語) <- (コンパイラ) <- Pythonのソースコード
まずPythonのソースコードをコンパイルしてバイトコードと呼ばれる中間言語に変換します。
中間言語は実行環境によらないコードで、それを仮想マシン(VM)が読み込み実行します。
ここで動的に機械語が生成されることはありません。
Pythonはバイトコードを一行ずつ実行するのでバイトコードインタープリタと呼ばれています。
では次に、実際にmain関数のバイトコードを見ていきます。
main関数のバイトコード
main関数内のバイトコードは以下になります。
2 0 LOAD_CONST 1 (0)
2 STORE_FAST 0 (s)
3 4 LOAD_GLOBAL 0 (range)
6 LOAD_CONST 2 (100000000)
8 CALL_FUNCTION 1
10 GET_ITER
>> 12 FOR_ITER 12 (to 26)
14 STORE_FAST 1 (_)
4 16 LOAD_FAST 0 (s)
18 LOAD_CONST 3 (1)
20 INPLACE_ADD
22 STORE_FAST 0 (s)
24 JUMP_ABSOLUTE 12
>> 26 LOAD_CONST 0 (None)
28 RETURN_VALUE
アセンブリコードみたいな印象を受けますね。
これはプロセッサによらず同じになり、仮想マシンで読みこむ段階で実行されます。
仮想マシンはスタックベースで実装されています。例えば1+2を計算したい時は1,2をスタックにPUSHして、足し算命令で2個POP、それを足して結果をPUSHするイメージです。
もう少し詳しい説明を知りたい方は次の記事を参考にしてみてください。
https://kaityo256.github.io/python_zero/howtowork/index.html
今回は実行時間の話なので最も関係があるFor文の部分だけ簡単に解説します。
まずループ部分を抜粋します。
>> 12 FOR_ITER 12 (to 26)
14 STORE_FAST 1 (_)
4 16 LOAD_FAST 0 (s)
18 LOAD_CONST 3 (1)
20 INPLACE_ADD
22 STORE_FAST 0 (s)
24 JUMP_ABSOLUTE 12
24番のコードで12番へのJUMP命令があるのでここがループ部分です。
12, 14番は変数_にrangeの次の値を代入する部分。
FOR_ITERで次の値をPUSHして、STORE_FASTで変数_に代入しています。
16~22番はs+=1の処理部分。
LOAD_FAST, LOAD_CONSTで変数sと定数1をPUSH、そしてINPLACE_ADDで2個POPして足して結果をPUSH、STORE_FASTで変数sに保存しています。
そして24番で12へジャンプします。
この一連の流れがC言語で実装された仮想マシンで$10^8$回実行されるというわけです。
仮想マシンでの実行のイメージコードは次のようになります。
for (int i=0;i<100000000;i++) {
exec(FOR_ITER);
exec(STORE_FAST);
exec(LOAD_FAST);
exec(LOAD_CONST);
exec(INPLACE_ADD);
exec(STORE_FAST);
exec(JUMP_ABSOLUTE);
}
実際にはこれよりも処理が多くなるのですが、この時点でs+=1と比べると重くなりそうです。
プロファイリングをしてみた
バイトコードを実行する部分の実装を見ていきたいのですが、その前にCPythonのどの関数にどれだけの処理時間がかかったのかを知りたいです。
この情報がないと、どこに時間が割かれているのかがわかりません。
そこで、CPythonのプロファイリングをしようと思います。
プロファイリングとはコード実行の所要時間、関数の呼び出し回数などを測定することです。重たい関数を特定することができます。
CPythonをプロファイリングする手順は次のようになります。
- CPythonをクローンする。
-
./configure --enable-profilingでビルドする。 - MakefileのOPT変数で初期値では-O3となっているので-O0に変える。
-
makeでビルドする。 - ビルドしたPythonでコードを実行すると、プロファイリング結果が出力される。
-
gprof ./python | ~/.local/bin/gprof2dot | dot -Tpng -o output.pngでコールグラフ作成。
ポイントはプロファイリングは最適化をすると正常に動かなくなってしまうのでOFFにしているところです。
--with-pydebugオプションをONにしてビルドしても-O0になるのですが、これだと測定に余計なデバック用の機能もインストールされてしまうのでMakefileを直接変更します。
ただ、本来使うPythonは最適化している状態なのでこの測定結果は目安でしかないと思います。
また最適化なしのPythonでは21秒ほどかかりました。
さて、その結果をコールグラフと呼ばれるもので表したのが次になります。
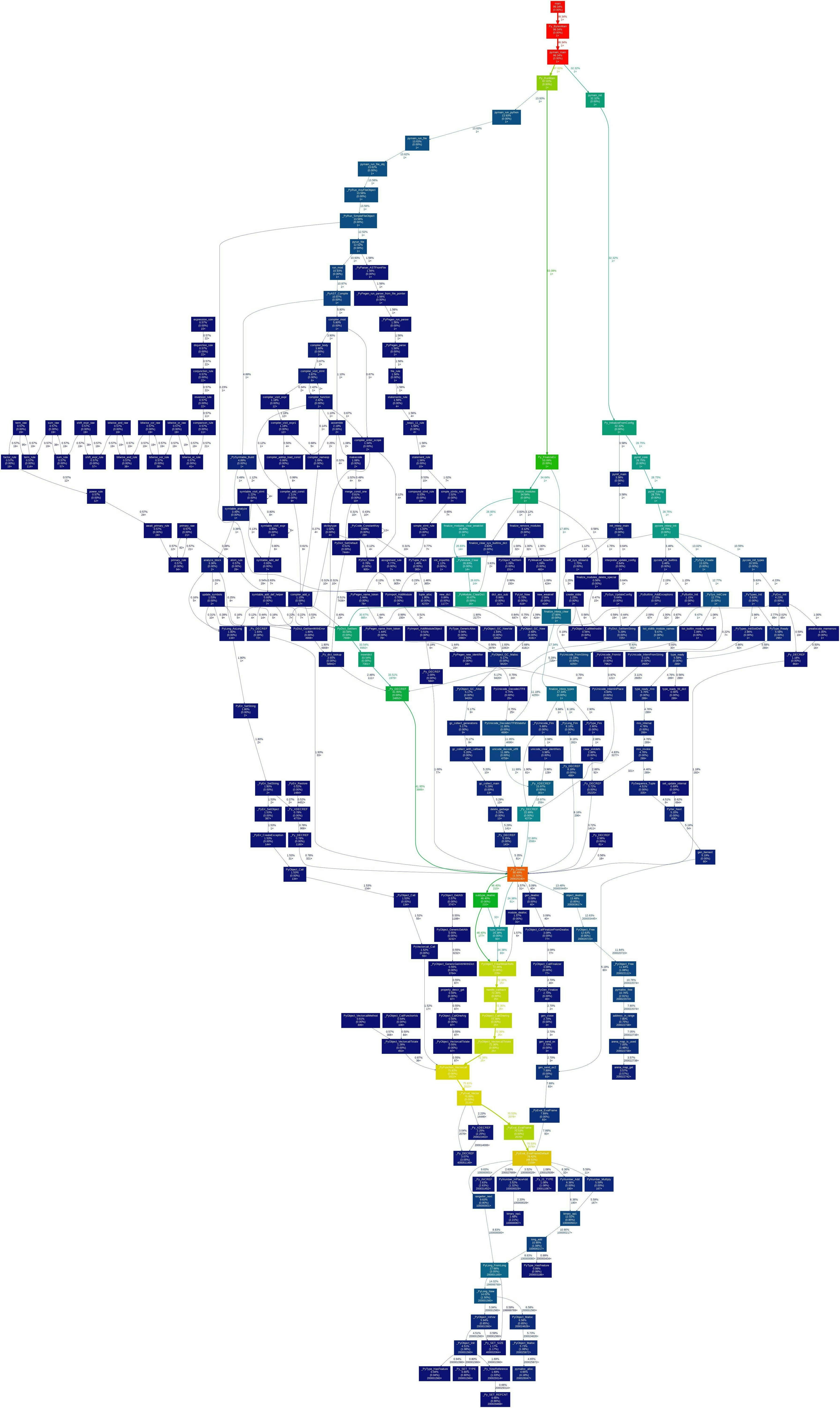
長方形の図形が関数、矢印が関数の呼び出し関係を表しています。
といっても小さすぎて見えないので上の赤い長方形あたりをアップにしてみます。
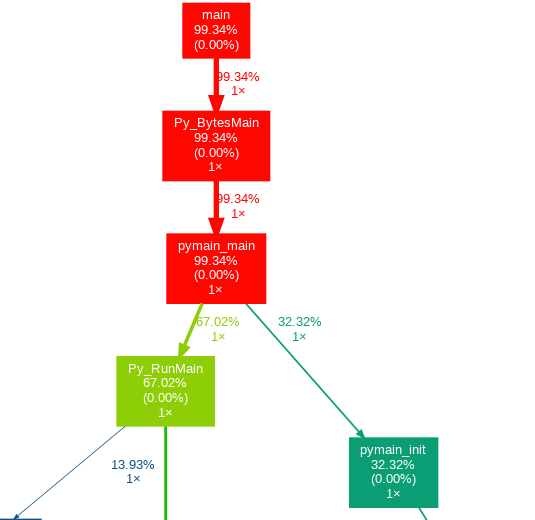
見やすくなりました。
トップはmain関数で、そこからPy_BytesMainを呼び出しています。
C言語なのでしっかりmain関数からスタートしていますね。
Py_BytesMainの長方形をみると、上から名前、子の関数を含めた全体に対する実行時間の割合、その関数内の処理の全体に対する実行時間の割合、呼び出された回数となっています。
つまり、子の関数を含めると全体の99.34%、その関数自体の処理には0%の時間がかかっていて1回だけ呼ばれたことになります。
子の関数を含めた割合が高いと色が暖色になり、その関数自体の割合が高いと重い処理であることが分かります。
main関数が100%にならないのは恐らく誤差ではないかと思います。
仮想マシンの処理を追う
プロファイリングのやり方が分かったところで重たそうな処理を見ていきましょう。
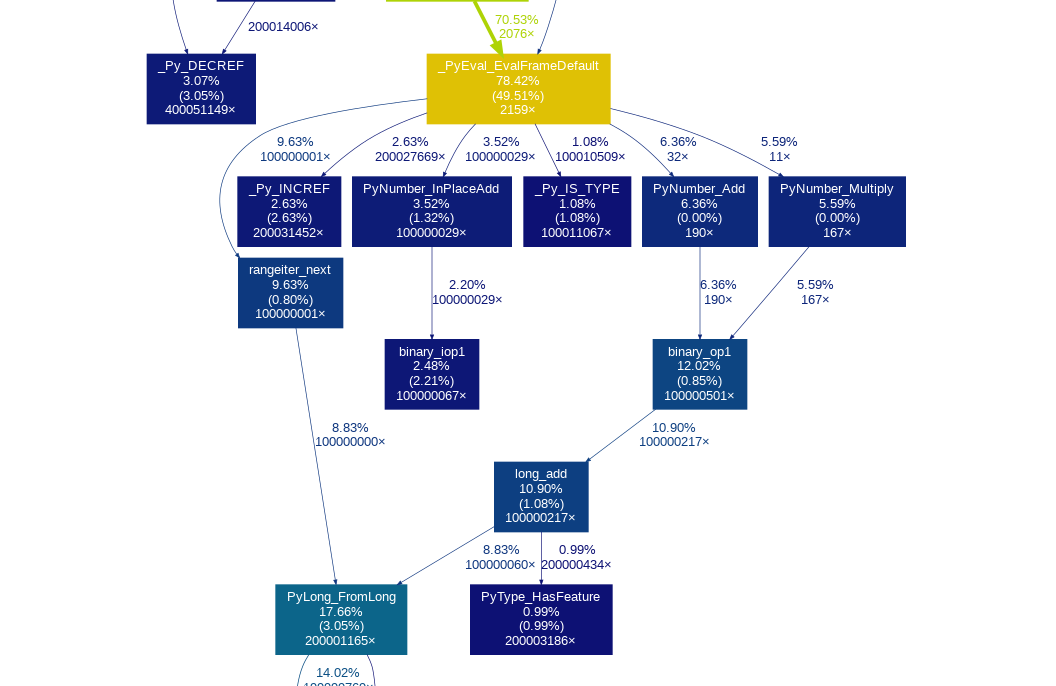
数ある中で_PyEval_EvalFrameDefault関数が最も重い処理でした。
上の画像の中では黄色い色をした長方形です。
子の関数を含めると約80%,自分自身だけでも50%も時間を割いています。
この関数が何をしているのか、それは仮想マシンのコア部分でバイトコードを読みこんでそれを実行します。
コードの概要は以下のようになります。
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyThreadState *tstate, PyFrameObject *f, int throwflag) {
//...
for (;;) {
//...
dispatch_opcode:
switch (opcode) {
case TARGET(LOAD_FAST): {
PyObject *value = GETLOCAL(oparg);
if (value == NULL) {
format_exc_check_arg(tstate, PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_localsplusnames,
oparg));
goto error;
}
Py_INCREF(value);
PUSH(value);
DISPATCH();
}
// ...
}
}
// ...
}
バイトコードの条件分岐とループの部分だけを抜き出しています。
switchによる条件分岐で1個しか抜き出していないのですが、実際は100を超える命令があります。
この関数から呼び出された子の関数をみると、_Py_INCREFや_PyNumber_inPlaceAddは$10^8$回より多く実行されています。
これはPythonのfor文で$10^8$回s+=1をしているからでしょう。
C言語でs+=1をするだけのコードと比較すると、実行時間が大幅に伸びるであろうことが予想出来ます。
では大雑把に重そうな原因が分かったところで、具体的にどのような処理をしているのかを見ていきます。
バイトコードのループ部分の処理のうち、LOAD_FAST, INPLACE_ADDの2つだけにします。
LOAD_FAST
まずLOAD_FASTは上のコードの概要に書いてある通りで、多くのマクロ文や関数が使用されています。
if文は例外処理なのでとりあえず除外して、一部のマクロや関数を次にまとめます。
# define GETLOCAL(i) (localsplus[i])
# define Py_INCREF(op) _Py_INCREF(_PyObject_CAST(op))
static inline void _Py_INCREF(PyObject *op)
{
// debug関係のコードは省略
op->ob_refcnt++;
}
# define BASIC_PUSH(v) (*stack_pointer++ = (v))
# define PUSH(v) BASIC_PUSH(v)
PyObject *value = GETLOCAL(oparg);
Py_INCREF(value);
PUSH(value);
DISPATCH();
まずLOAD_FASTは変数から値を取得してスタックをPUSHする命令です。
それを踏まえた上で流れは、まずGETLOCALでローカル変数の取得します。
Py_INCREFで参照カウントを増やし、PUSHします。
最後にDISPATCHで次の命令に移ります。
_Py_INCREFはコールグラフを見ると$2 \times 10^8$以上実行されて、全体の2.5%ほど使用されています。
処理内容はop->ob_refcnt++;だけなのですが、やはり何回も実行されるので0%にはならないのでしょう。
マクロの処理は_PyEval_EvalFrameDefault関数自身のパーセントに含まれています。
一つ一つは軽そうですが、これらが積み重なって50%程になっているのでしょう。
INPLACE_ADD
次にINPLACE_ADDをみていきます。
case TARGET(INPLACE_ADD): {
PyObject *right = POP();
PyObject *left = TOP();
PyObject *sum;
if (PyUnicode_CheckExact(left) && PyUnicode_CheckExact(right)) {
sum = unicode_concatenate(tstate, left, right, f, next_instr);
/* unicode_concatenate consumed the ref to left */
}
else {
sum = PyNumber_InPlaceAdd(left, right);
Py_DECREF(left);
}
Py_DECREF(right);
SET_TOP(sum);
if (sum == NULL)
goto error;
DISPATCH();
}
ぱっと見てLOAD_FASTより重そうです。
ここに使われてるマクロや関数を一部まとめます。
# define BASIC_POP() (*--stack_pointer)
# define POP() BASIC_POP()
# define TOP() (stack_pointer[-1])
# define SET_TOP(v) (stack_pointer[-1] = (v))
# define _PyObject_CAST(op) ((PyObject*)(op))
# define _PyObject_CAST_CONST(op) ((const PyObject*)(op))
# define Py_IS_TYPE(ob, type) _Py_IS_TYPE(_PyObject_CAST_CONST(ob), type)
# define PyUnicode_CheckExact(op) Py_IS_TYPE(op, &PyUnicode_Type)
static inline int _Py_IS_TYPE(const PyObject *ob, const PyTypeObject *type) {
// bpo-44378: Don't use Py_TYPE() since Py_TYPE() requires a non-const
// object.
return ob->ob_type == type;
}
INPLACE_ADDはPythonのs+=1の演算する部分の命令です。
流れはPOPとTOPでスタックから2つの値を取り出し、演算してスタックの一番上に結果をセット、そして次の命令に移るといった感じです。
ポイントは型チェックと足し算の処理です。
型チェック
まず型チェックの話で、if文でPyUnicode_CheckExactがあります。
これはオブジェクトがstrかどうかをチェックしています。
2つともstrなら文字列の結合の処理をするようになっています。
はい、Pythonが遅い原因と言われる一つの要因の型チェックがでてきました。
ただ、処理を見ると比較演算をしてるだけでかなりシンプルですね。
コールグラフの_Py_IS_TYPEをみると、しっかり$10^8$回以上呼び出されていますが1%程度と控えめです。他にもif文の速度や別の関数でも型チェック、キャストが入ってたりするのですが、動的型付け言語であることが速度の最大のネックとまでは言えないのではと思いました。
勿論遅い原因の一つなのですが、それよりは仮想マシンの実行全体の方が重そうに感じます。
足し算
次に足し算を見ていくのですが、こちらは複雑なのでコードは載せないです。
代わりに簡単にコールグラフを確認します。
PyNumber_InPlaceAdd, binary_iop1, binary_op1, loag_add, PyLong_FromLong...と多くの関数が関係しています。
ただ足し算をするだけでも色々絡んで複雑になっていますね。
PyLong_FromLongはlong型からpythonの数値オブジェクトを生成する関数で、これが子関数を含めて20%近く占めています。
rangeとaddで2*10^8回以上実行されていることがわかります。
ここまで重たいのはメモリのオブジェクトの初期化やメモリの動的確保に時間がかかっているからでしょう。
演算するたびに新規オブジェクトを作成するのは何故か気になったのですが、多倍長整数が関係しているのでしょうか?詳しいことはわかりませんでした。
残りの20%は?
メモリの開放処理に10%ちょいぐらい、他は分散している感じでした。
さいごに
Pythonの処理系からforの実装と速度を見ることで、重い原因は主に仮想マシンであることが分かりました。
具体的な処理はスタック関係の処理、型チェック、数値演算、メモリの確保、開放...などと多くありました。
実装と実行時間の詳細を確認したことで、説明だけ読んでいた時よりも遥かにモヤモヤが取れた気がします。
では、PyPyや同じく仮想マシンを使うjava, javascriptなどは何故早いのかということですが、これはJITを使って実行時に最適化をしているからです。
この話は時間がある時にかきたいな~と考えています。(そもそもJITをよくわかっていない...)
他にもCythonやnumbaなどの高速化手法も調べたいです。
ここまで読んで頂きありがとうございました。
参考