はじめに
CUDA8 になり漸く C++11 対応が入ったので、C言語と共用のpthreadやcudaStreamではなく相当するC++11標準ライブラリを使いたいというのが、この記事のモチベーションです。今回はCUDA7RCのときの公式ブログ記事をベースにやってみます。
$ nvcc ./stream_test.cu -o ./stream_legacy
$ nvvp ./stream_legacy
以上のコマンドで、nvccで実行ファイルにコンパイルして、EclipseっぽいUIのNVVPでプロファイルできます。初めてNVVPを使ったので、最初の設定でArguments: Profile all processes となっていれば Profile child processes に変更しないと、いつまでもプロファイル終わらないのでハマりました。下の settings から設定直して上の Run > Generate Timeline で動かします。
詳細は飛ばして、雑に公式ブログの話をまとめると
- cudaStream_t や pthread_t を使ってマルチストリーム、スレッド処理をするときはnvcc のオプション
--default-stream per-threadでコンパイルする - pthread_tを使うときはスレッド毎にメモリ確保やカーネル関数を呼び出して、
cudaStreamSynchronize(cudaStream_t stream)する関数をpthread_createに渡す
以上がマルチストリーム・スレッド処理のお約束のようです。それでは、C++11の <future> や <thread> 標準ライブラリを使って書き換えてみます
C++11 future でマルチストリーム処理
勉強不足なので、元のcudaStreamを使った例より書きやすくなったということも無い気がします。もしかするとstd::promise に例外か返り値を入れる方針で書くと綺麗にできるかもしれません。今回のC++11 future を使ったコード例は以下です。
# include <array>
# include <future>
# include "cuda_check.hpp"
const int N = 1 << 20;
__global__ void kernel(float *x, int n) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
int main() {
const int num_streams = 8;
std::future<cudaError_t> fs[num_streams];
float* data[num_streams];
for (int i = 0; i < num_streams; i++) {
fs[i] = std::async(
std::launch::async, [=]() mutable
{
CUDA_CHECK(cudaMalloc(&data[i], N * sizeof(float)));
// launch one worker kernel per stream
kernel<<<1, 64, 0>>>(data[i], N);
CUDA_CHECK(cudaPeekAtLastError());
return cudaSuccess;
});
// launch a dummy kernel on the default stream
kernel<<<1, 1>>>(0, 0);
CUDA_CHECK(cudaPeekAtLastError());
}
for (auto&f: fs) {
CUDA_CHECK(f.get());
}
cudaDeviceReset();
}
NVVPでプロファイルすると、cudaStreamを使っていたときは出てこなかったcudaMallocと、num_stream個のthreadができていてオーバーヘッドになっています。
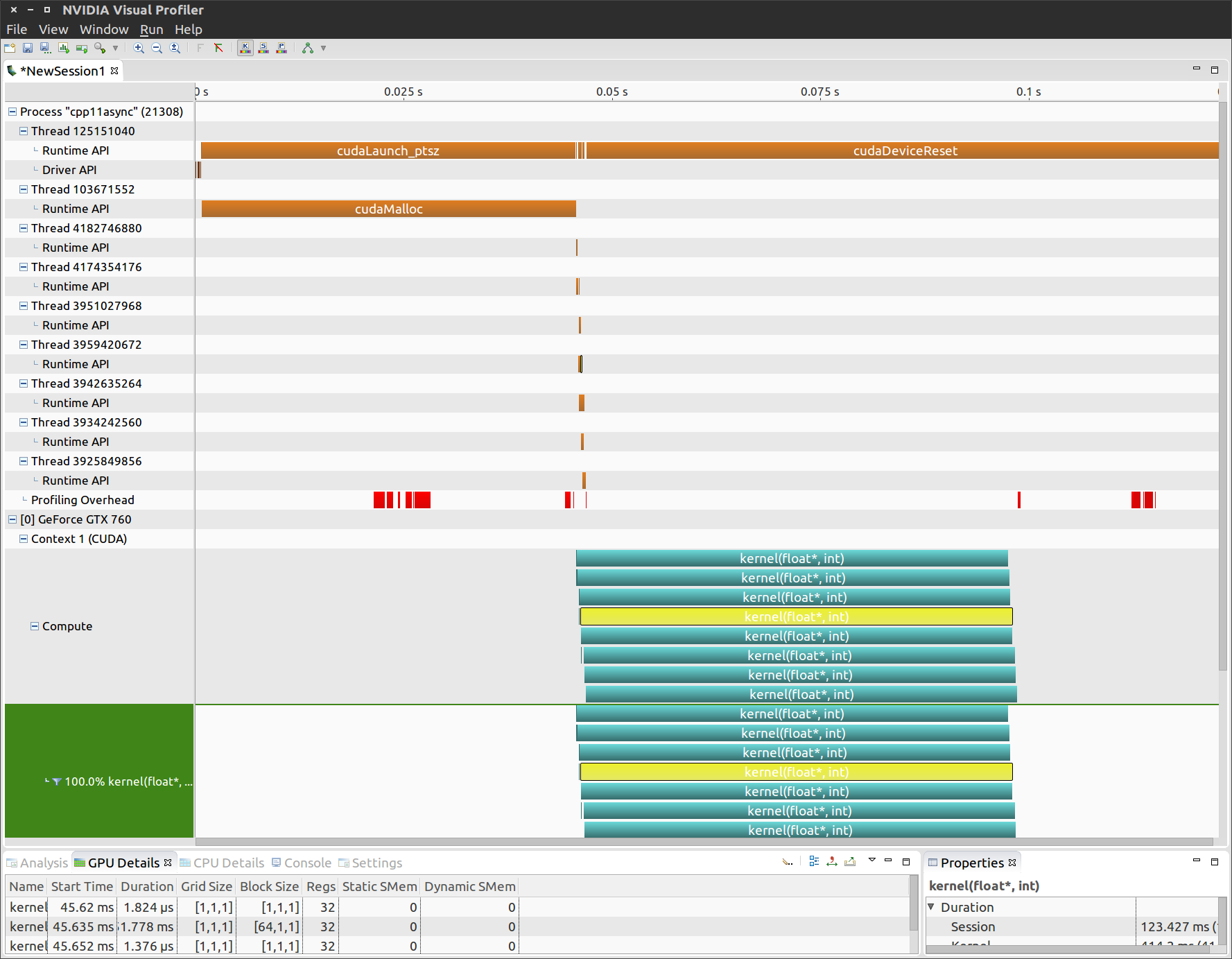
ただ次のように std::launch::deferredとcudaStream_tを使うと (さらに煩雑だけど)、threadは作られない上に遅延実行もできるので、よりstream感の強い使い方ができる??
int main() {
const int num_streams = 8;
cudaStream_t streams[num_streams];
std::future<cudaError_t> fs[num_streams];
float* data[num_streams];
for (int i = 0; i < num_streams; i++) {
// こちらはこのforループ内では実行されない
fs[i] = std::async(
std::launch::deferred, [=]() mutable
{
CUDA_CHECK(cudaStreamCreate(&streams[i]));
CUDA_CHECK(cudaMalloc(&data[i], N * sizeof(float)));
kernel<<<1, 64, 0, streams[i]>>>(data[i], N);
CUDA_CHECK(cudaPeekAtLastError());
return cudaSuccess;
});
// こちらは上のコードより先にこのforループ内で実行される
kernel<<<1, 1>>>(0, 0);
CUDA_CHECK(cudaPeekAtLastError());
}
for (auto&f: fs) {
// ここではじめて deferred されたラムダ式を実行
CUDA_CHECK(f.get());
}
cudaDeviceReset();
}
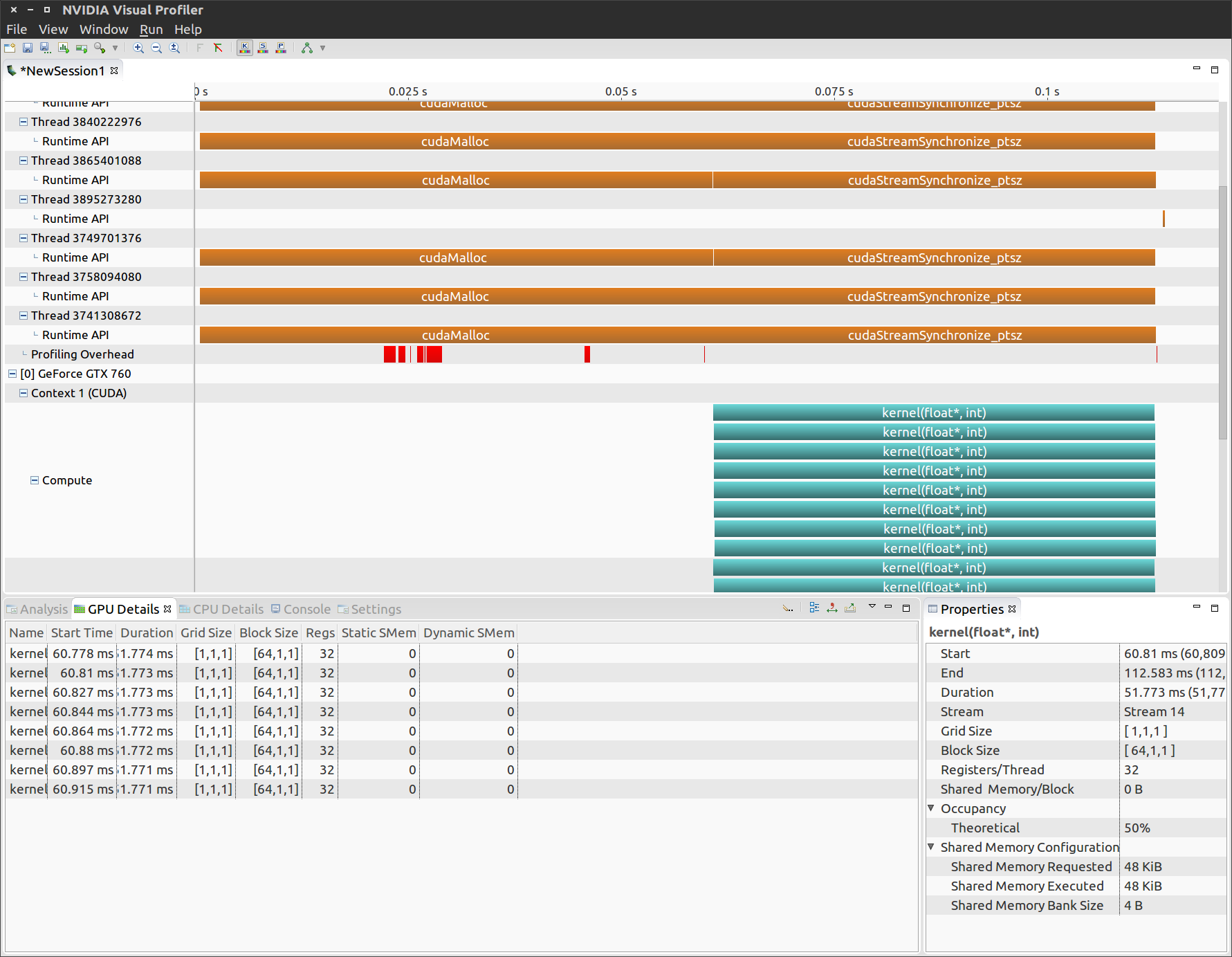
なお、上のコードと違って元のコードではforループ内の2つのカーネル関数は交互に実行されています。確認はNVVPの下側GPU Detailsを見るとわかります。
C++11 thread でマルチスレッド処理
単純に pthread を使っていた部分を置き換えました。コードが pthread 非依存になったのと戻り値を取得しやすくなったメリットがあります。
# include <future>
# include <thread>
# include <iostream>
# include "cuda_check.hpp"
const int N = 1 << 20;
__global__ void kernel(float *x, int n) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159,i));
}
}
std::string launch_kernel() {
float *data;
CUDA_CHECK(cudaMalloc(&data, N * sizeof(float)));
kernel<<<1, 64>>>(data, N);
CUDA_CHECK(cudaPeekAtLastError());
CUDA_CHECK(cudaStreamSynchronize(0));
return "ok";
}
int main() {
const int num_threads = 8;
std::future<std::string> fs[num_threads];
for (auto& f: fs) {
try {
std::packaged_task<std::string()> task(launch_kernel);
f = task.get_future();
std::thread(std::move(task)).detach();
} catch(std::exception& e) {
std::cerr << "Error creating thread: " << e.what() << std::endl;
}
}
for (auto& f: fs) {
try {
std::cout << f.get() << std::endl;
} catch(std::exception& e) {
std::cerr << "Error joining thread: " << e.what() << std::endl;
}
}
cudaDeviceReset();
}
ざっと見たところ、pthreadを使った元のコード例と比べてもオーバーヘッドが発生したようには見えません。この使い方は積極的に採用できそうです。
全コード
ここはこうするべきという指摘があればPRやコメントでもらえると助かります。