はじめに
ある先生から「おもしろい動画があるから見てみて」と紹介してもらったハンス・ロスリングのTEDの動画は、私がデータの可視化やシミュレーションに興味を持つきっかけとなり、私にとって大きな影響がありました。
「ファクトフルネス」はベストセラーにもなったので、知っている人も多いのではないかと思います。
動画で紹介されている動く散布図はモーションチャートと呼ばれていて、データ可視化のソフトウェアで対応しているものもあります。最近、私はデータの可視化にPower BIを使うことが多いのですが、Power BIでモーションチャートを作ることができることを知ったので、delikaとPower BIで動画の冒頭で登場する平均寿命と出生率のモーションチャートを作ってみようと思いました。
データセット
TEDの動画の11:35あたりで世界銀行のデータ公開についての言及があります。
そしてアメリカ政府は主張なしに社会に有用な事実を提供する最善の努力をしてきました。インターネットで世界からデータを無料で得られるようにしたのです。感謝します。世界銀行とは正反対です。政府のお金、税金を使って集めたデータをちょっとした利益を得ようと売っているのです。非常に非効率的なグーデンベルグ式のやり方で。(拍手)
この講演のあった2009年から状況は改善して、現在は世界銀行もデータをオープンにしていく取り組みをされているようです。
世界銀行の情報公開「オープンな開発」とは
世界銀行は、業務の透明性と説明責任を向上するため、様々なツールを使った「オープンな開発」を推進しています。世銀が積み上げてきた約8000の開発指標や1万件以上の調査研究等を無料公開し、貧困層を含むより多くの人々の開発への参加を促すことにより、これまで以上に効果的で透明性の高い支援を目指しています。また、南々協力を通じた途上国間の知識交流を促進し、革新的手法の拡散を目指しています。
平均寿命、出生率、人口のデータ(世界銀行)
世界銀行のWebサイトから平均寿命、出生率、人口のデータをXML形式でダウンロードします。
平均寿命、出生率、人口のデータをXMLからCSVに変換
ダウンロードしたXMLをPythonでCSVに変換します。以下は平均寿命のXMLを処理するコードです。出生率や人口のXMLを処理する際はXMLのファイル名と出力先のCSVのファイル名を変更します。
import pandas as pd
import xml.etree.ElementTree as ET
tree = ET.parse("API_SP.DYN.LE00.IN_DS2_en_xml_v2_4694542.xml")
root = tree.getroot()
records = []
for record in root.find("data").iter("record"):
r = {"country_name": None, "country_code": None, "year": None, "value": None}
for field in record.iter("field"):
if field.attrib["name"] == "Country or Area":
r["country_name"] = field.text
r["country_code"] = field.attrib["key"]
elif field.attrib["name"] == "Year":
r["year"] = field.text
elif field.attrib["name"] == "Value":
r["value"] = field.text
records.append(r)
df = pd.DataFrame.from_dict(records)
df.to_csv("life_expectancy.csv", index=False)
地域分類のデータ
国がどの地域に分類されているかのデータを作成します。World Bank Country and Lending Groupsからcurrent classification by income in XLSX formatをダウンロードして、以下のコードで地域分類のデータのみを抽出してCSVに出力します。
import pandas as pd
df = pd.read_excel("CLASS.xlsx", sheet_name=1)
df = df.rename(columns={"GroupCode": "group_code",
"GroupName": "group_name",
"CountryCode": "country_code",
"CountryName": "country_name"})
df = df[(df["group_name"] == "East Asia & Pacific") |
(df["group_name"] == "Europe & Central Asia") |
(df["group_name"] == "Latin America & Caribbean") |
(df["group_name"] == "Middle East & North Africa") |
(df["group_name"] == "North America") |
(df["group_name"] == "South Asia") |
(df["group_name"] == "Sub-Saharan Africa")]
df.to_csv("country_classification.csv", index=False)
平均寿命、出生率、人口、地域分類のデータをdelikaで統合
変換したCSVをdelikaのデータセットに登録します。登録した後、delikaで以下のようにクエリーを実行してデータを統合します。
SELECT
l.country_name,
l.country_code,
l.year,
l.value as life_expectancy,
f.value as fertility_rate,
p.value as polulation,
c.group_name
FROM
[kaorumori/qiita-ac-2022/life_expectancy.csv] l,
[kaorumori/qiita-ac-2022/fertility_rate.csv] f,
[kaorumori/qiita-ac-2022/population.csv] p,
[kaorumori/qiita-ac-2022/country_classification.csv] c
WHERE
l.country_code = f.country_code
AND l.year = f.year
AND l.country_code = p.country_code
AND l.year = p.year
AND l.country_code = c.country_code
クエリーの実行が完了したらResultタブで結果を確認します。

平均寿命、出生率、人口という別々の統計をひとつに統合することができました。正常に処理されていれば結果をダウンロードします。ダウンロードしたCSVにはヘッダーが含まれていないので、以下のヘッダーを追加しておきます。
"country_name","country_code","year","life_expectancy","fertility_rate","population","group_name"
データ可視化
Power BIでモーションチャートを作成
作成したCSVファイルをPower BIで読み込み、散布図を以下のように作成します。
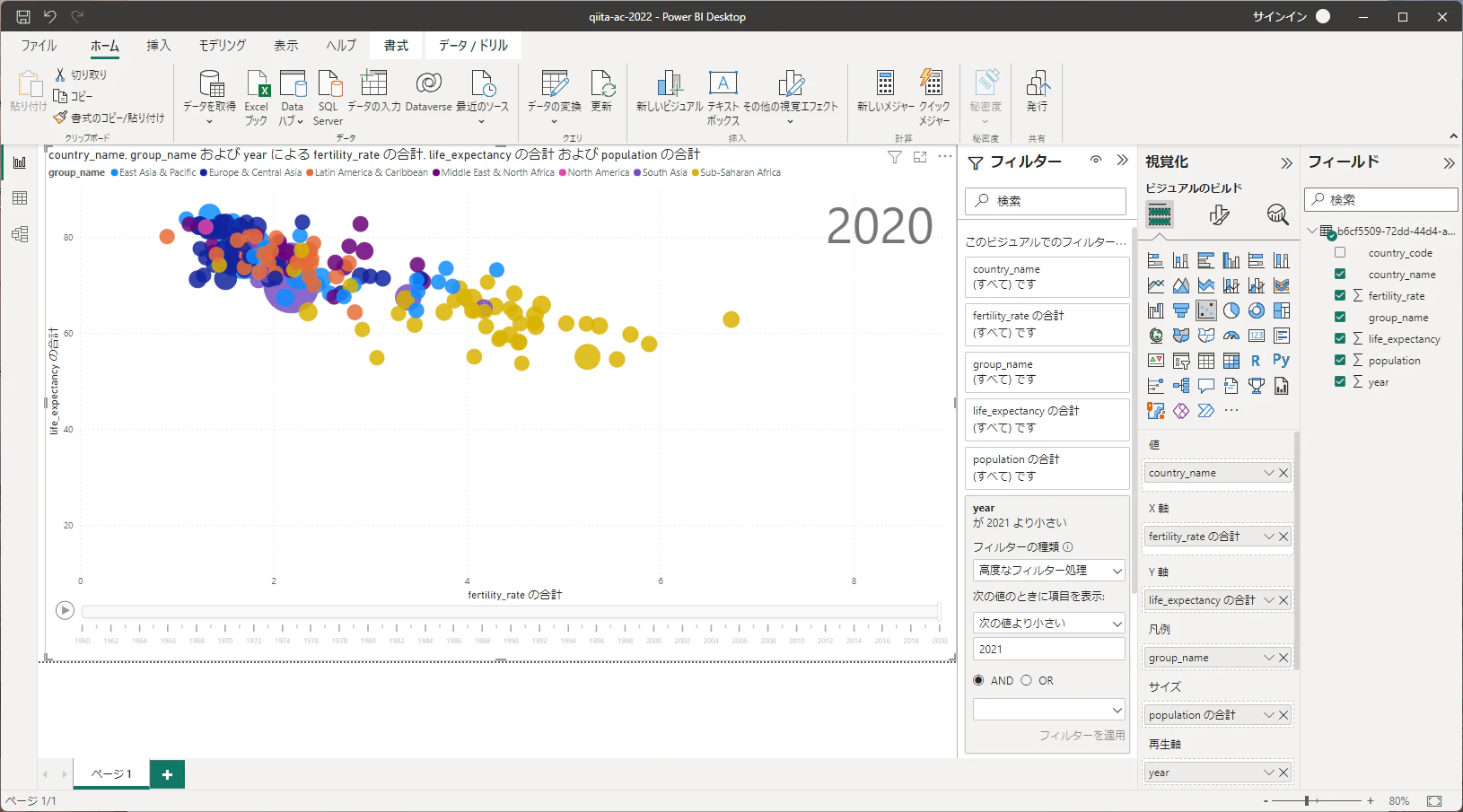
X軸に出生率、Y軸に平均寿命、散布図の点のサイズを国の人口規模に応じたものにして、地域分類で塗り分けます。設定項目は以下のようになります。
| 設定項目 | 入力 |
|---|---|
| 値 | country_name |
| X軸 | fertility_rate の合計 |
| Y軸 | life_expectancy の合計 |
| 凡例 | group_name |
| サイズ | population の合計 |
| 再生軸 | year |
2021年のデータは散布図に表示されないため、このビジュアルでのフィルターでyearの次の値より小さいに2021を指定してフィルターを適用をクリックします。
モーションチャートを再生
ここまでの操作でモーションチャートを再生することができるようになりました。
このデータの解釈や見方については、この記事の冒頭で紹介したTEDの動画を参照してもらえればと思います。
おわりに
私にとって印象深かった平均寿命と出生率のモーションチャートを、ずいぶんと時間がたってから自分でも作ってみました。
今回はdelikaからクエリーの実行結果をダウンロードしてPower BIに読み込みましたが、Power BIのコネクターを利用してdelikaと接続することもできるようです。