学習中のPandasについて備忘をまとめた(適宜更新)
1.Seriesの作成
Pandasには2つのデータ構造があり、1次元データがSeries、2次元データがDataFrame。
Seriesはリスト、ディクショナリ、Numpyのndarrayから作成できる。
(1)リストから作成
list = [5, 1, 6, 4, 5, 1, 7, 10, 2, 7]
pd.Series(list)
# 0 5
# 1 1
# 2 6
# 3 4
# 4 5
# 5 1
# 6 7
# 7 10
# 8 2
# 9 7
# dtype: int64
# indexを指定
pd.Series(list,index=["a","b","c","a","b","c","a","b","c","a"])
# a 5
# b 1
# c 6
# a 4
# b 5
# c 1
# a 7
# b 10
# c 2
# a 7
# dtype: int64
(2)arrayから作成
numpyベクトルから作成する場合。
arr = np.array([10,22,55])
pd.Series(arr)

(参考)numpy行列から作成する場合はDataFrameを使う。
arr = np.array([[10,22,55]])
pd.DataFrame(arr) #Seriesは1次元なのでエラーが出る(DataFrameにする)

2.Seriesからデータ取得
(1)単純に取得
list = [5, 1, 6, 4, 5, 1, 7, 10, 2, 7]
list_1 = pd.Series(list,index=["a","b","c","a","b","c","a","b","c","a"])
list_1["a"]

インデックスがない場合
list = [5, 1, 6, 4, 5, 1, 7, 10, 2, 7]
list2 = pd.Series(list)
list2[1]
# 1
(2)条件から取得
list = [5, 1, 6, 4, 5, 1, 7, 10, 2, 7]
list_1 = pd.Series(list,index=["a","b","c","a","b","c","a","b","c","a"])
list1 > 2

SeriesはTrueの値のみ取得する性質を活かし、以下のように値を取得できる。
list_1[list_1>2]

3.DataFrameについて
(1)DataFrame作成
①リストから作成
list1 = [[5, 1, 6, 4, 5, 1, 7, 10, 2, 7],[9, 2, 5, 4, 2, 5, 5, 3, 6, 8]]
pd.DataFrame(list1,index=["row1","row2"],columns=["a","b","c","a","b","c","a","b","c","a"])
以下はindexとcolumnsに引数を与えているが、値を与えないと0から始まる連番となる。
(list1) 
②辞書型から作成
fruits_list = {"apple":[1,3,5,3,2],"orange":[3,4,2,2,3],"banana":[3,4,2,4,3]}
(fruits_list) 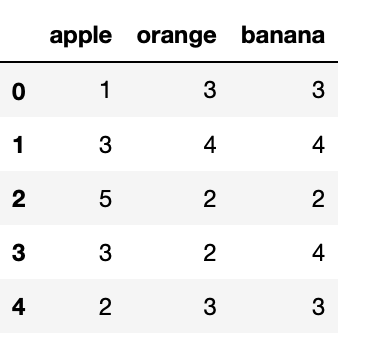
(2)行連結/縦方向と横方向
appendは、2つのDataFramemのclolumnが同一の場合に使える。
引数のignore_indexは、Trueにすると結合後のインデックスを振り直す。
list1 = [[5, 1, 6, 4, 5, 1, 7, 10, 2, 7],[9, 2, 5, 4, 2, 5, 5, 3, 6, 8]]
list1 = pd.DataFrame(list1,index=["row1","row2"],columns=["a","b","c","a","b","c","a","b","c","a"])
list2 = [[5, 2, 2, 3, 8, 5, 7, 10, 3, 10],[9, 1, 0, 8, 6, 1, 4, 5, 5, 6]]
list2 = pd.DataFrame(list2,index=["row1","row2"],columns=["a","b","c","a","b","c","a","b","c","a"])
list3 = list1.append(list2,ignore_index = True)
list3
(list3) 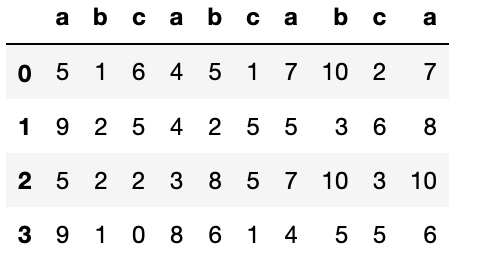
(3)行の削除
行の削除にはdropを使う。
引数のinplaceはTrueとすると実行結果を保存する。Falseにすると保存しない。
以下の例では2行目を削除してみた。
list3.drop(1,inplace=True)
(list3) 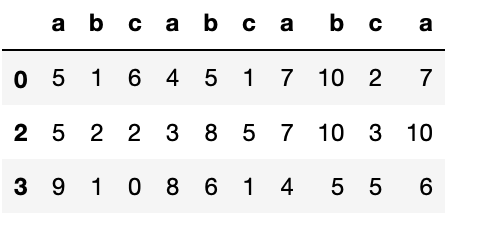
上記のインデックスは1がない状態であるが、これを0,1,2の連番とする場合は以下のようにする。
引数のinplaceはTrueとすると実行結果を保存する。Falseにすると保存しない。
引数のdropをTrueにすると元のインデックスは残らない(Falseにすると元のインデックスは表示される)
list3.reset_index(drop = True,inplace=True)
(4)列の削除
(list3)
list3のaのカラムを削除する。
列の削除の場合axis=1とする。(axisのデフォルトは0で、行の削除の場合を意味する)
引数のinplaceはTrueとすると実行結果を保存する。Falseにすると保存しない。
list3.drop("a",axis=1,inplace=True)
(5)インデックス名変更
xのカラムを新たに追加して、あわせてインデックスに設定する場合。
list3["x"] = pd.DataFrame(["red","yellow","blue"])
list3.set_index("x")
(list3) 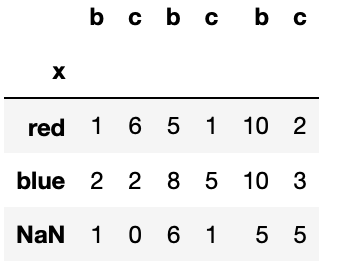
複数のインデックスを設定する場合は以下のようにする。
list3.set_index(["x","g"])
(6)ソート
ascendingは、Trueで昇順、Falseで降順。
①インデックスでソート
list3.sort_index(ascending=False,inplace =True)
②列名でソート
list3.sort_index(axis = 1,ascending=False,inplace=True)
③指定した列の値ソート
list3に新たにg列を加えてgの値でソートする。
list3["g"] = [4,20,4]
list3.sort_values("g",ascending=False)
(list3) 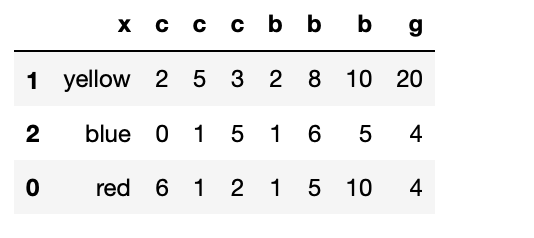
(7)データの取得
(list3) 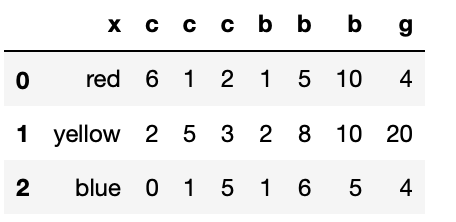
①ilocによる抽出
DataFrameから行・列の番号を指定して抽出する。
以下は列を全て抽出。
list3.iloc[0:1]
(list3) 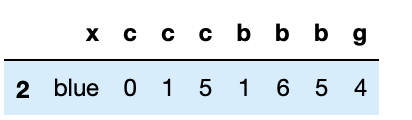
以下は列を一部指定して抽出、
list3.iloc[0:1,1:6]
(list3) 
②locによる抽出
DataFrameから行・列名を指定して抽出する(ilocとの違いはiclocは行番号、列番号)
c列全てを取り出す場合
list3.loc[0:,"c"]
(list3)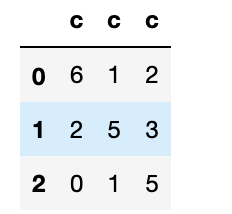
③条件を指定して取得
list3["g"]>5
# 0 False
# 1 True
# 2 False
# Name: g, dtype: bool
list3[list3["g"] > 5]
(list3) 
(8)データの読み込み
csvの場合以下のとおり
前提として、書き出しにおいて、何も設定しないとインデックスは勝手に連番が付加される。
読み込みにおいて、何も設定しないとインデックスは勝手に連番が付加される。
①インデックスをつけたまま書き出す
pd.read_csv(" ".csv)
②インデックスをつけずに書き出す
pd.to_csv(" ").csv,index=None
③インデックスをつけて良みこむ
pd.read_csv(" ")
④インデックスをつけずに良いこむ
pd.read_csv(" ",index_col=[0])
※上記から、①の後に③として読み込むと、読み込んだ際に自動的に付与されたインデックスと、書き出した際に自動的に付与されたインデックスが重複して読み込まれる。
※headerについては、書き出す際も読み込む際もheader=Noneでつけないことができる。
(9)データの結合
①apendを使う/縦方向/(Union(同じ列を持つもの同士を結合)
(list3) 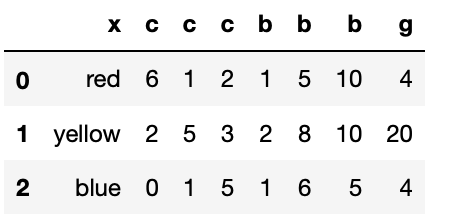
(list4) 
ignore_indexをTrueにすると新たにインデックスを振り直す
list5 = list3.append(list4,ignore_index=True)
list5
(list5) 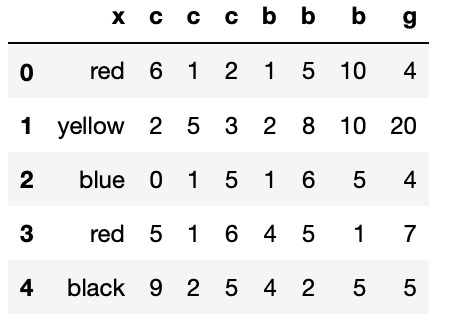
②concatを使う/縦方向/Union(同じ列を持つもの同士を結合)
上記と同じ結果となる。
list6 = pd.concat([list3,list4],ignore_index = True)
list6
(list6) 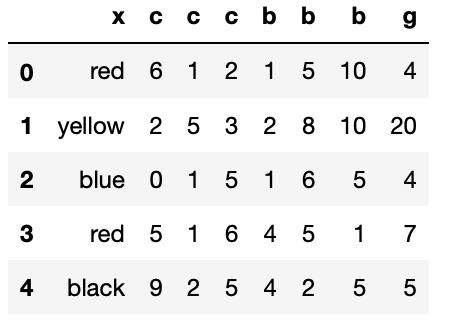
③concatを使う/横方向
concatで横方向に結合する場合、axis=1とする(axis=0はデフォルトで縦方向)
list6 = pd.concat([list3,list4],axis = 1)
list6
(list6) 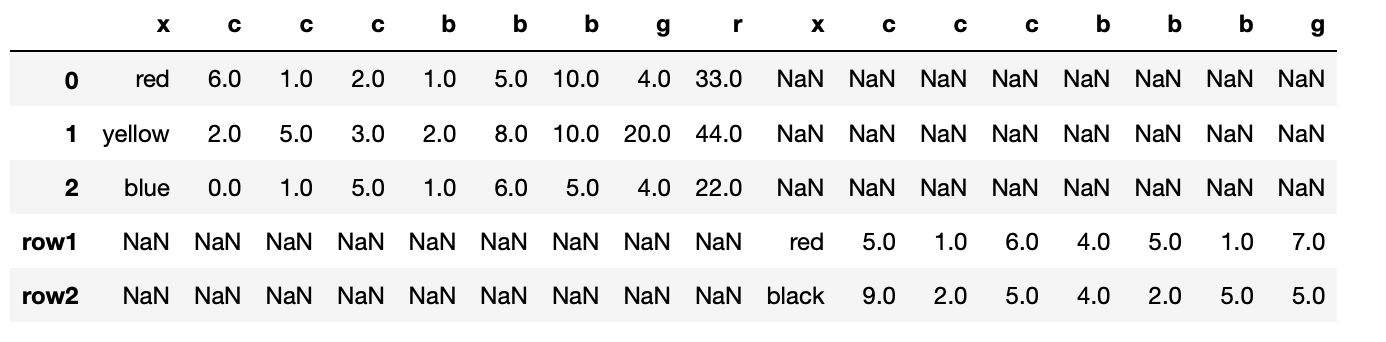
④merge(内部結合)を使う/Join(結合キーをベースに結合する)
内部結合とは両方のDataFrameに存在する項目を結合キーとして結合させる場合に、その項目の値が両方のDataFrameに一致する行のみを取得する方法。
onは結合するキーを意味する。howは結合方法。left_onは左側の結合する列またはインデックスの名前。right_onは右側の結合する列またはインデックスの名前(今回はleft_on,right_onは使わない)
同一でないcolumnsを持つDataFrameを結合する場合以下の通りとする。
(list10) 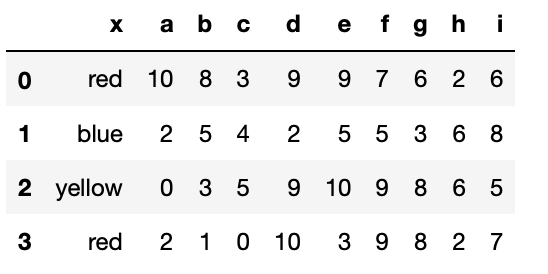
(list11) 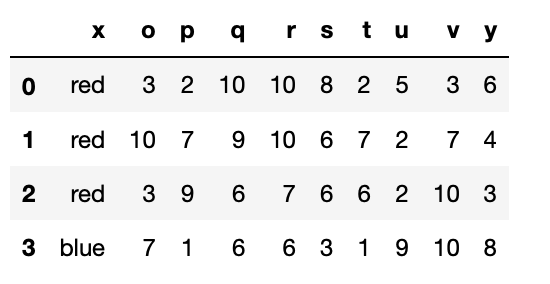
list12 = pd.merge(list10,list11,how = "inner",on="x")
list12
(list12) 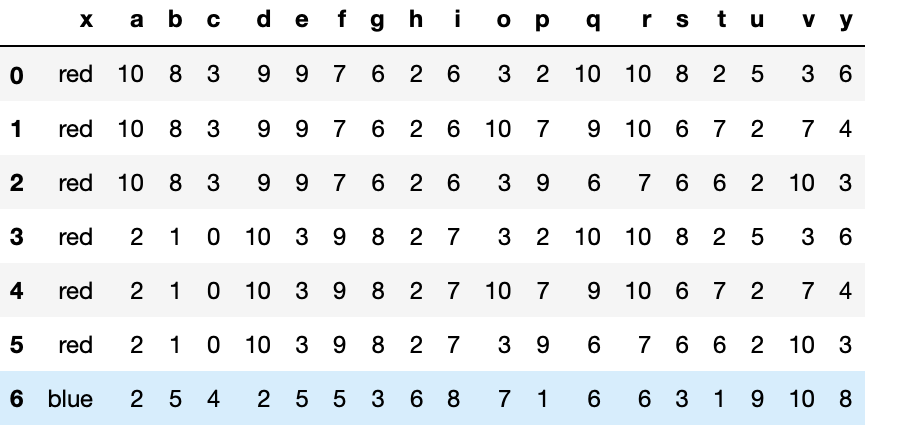
xのcolumnsをキーとして、そのうち共通の値をもつ行を結合する
list13 = pd.merge(list10,list11,how = "inner",on="x")
list13
⑤merge(左結合)を使う
左側のDataFrameに加え、特定した行のうち両方のDataFrameに存在する値が一致する行を取得する方法。
list13 = pd.merge(list10,list11,how="left",on="x")
list13
(list13) 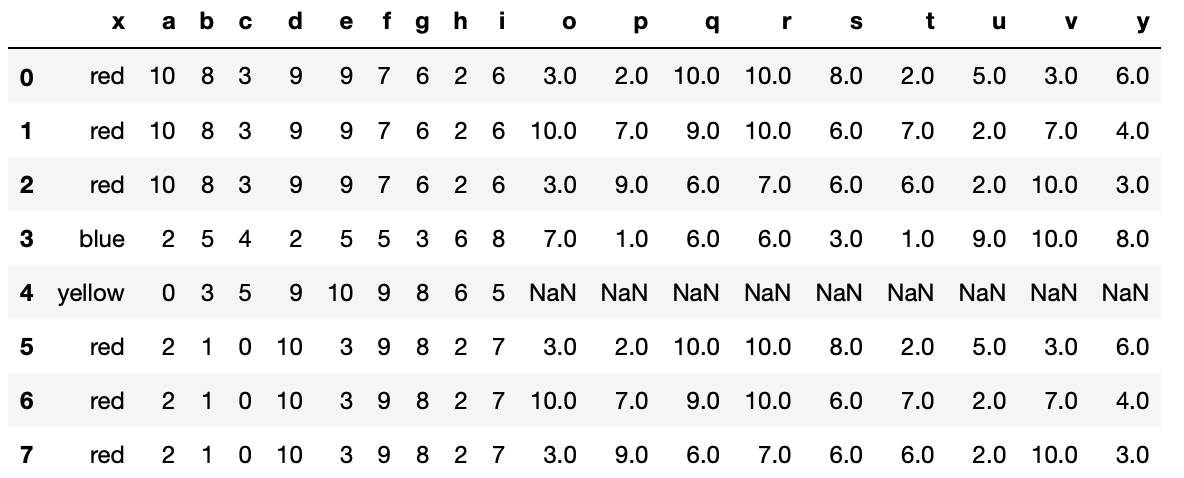
list11の特定の列のみを結合する場合は以下の通り(xをキーとして、xとy,vを結合する場合)
list13 = pd.merge(list10,list11[["x","y","v"]],how="left",on="x")
(10)pivot_tableを使う
list13をpivot_tableで編集する。
(list13)
valuesの引数に表示したい値を設定(デフォルトはNone)
また、aggfuncの引数はデフォルトはNoneで、sumを設定すると合計,meanを設定すると平均、sizeを設定するとNaNを含んだ数、countを設定するとNaNを含まない数を設定。
fill_value=0とすると、NaNを0に置き換える。
list13.pivot_table(values="g",index = "e",columns="x")
(pivot_1) 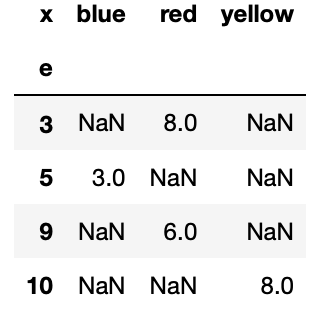
gの値の合計を出力する場合は以下の通り。
list13.pivot_table(values="g",index = "e",columns="x",aggfunc="sum")
(pivot_2) 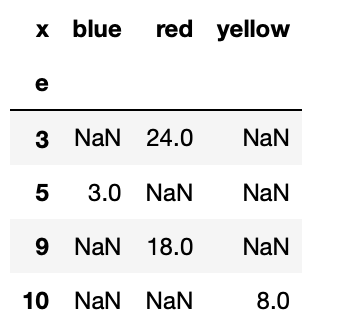
(11)groupbyについて
groupby は、同じ値を持つデータをまとめて共通の操作を行いたい時に使う。
平均値を出す場合はmean()、合計はsum()、個数はcount()を使う。
test = {"name":["suzuki","katou","katou","tanaka","suzuki","katou"],
"price":[200,200,100,100,100,300],
"count":[1,1,2,3,1,1],
"contry":["japan","japan","japan","korea","japan","japan"]
}
test = pd.DataFrame(test)
(test) 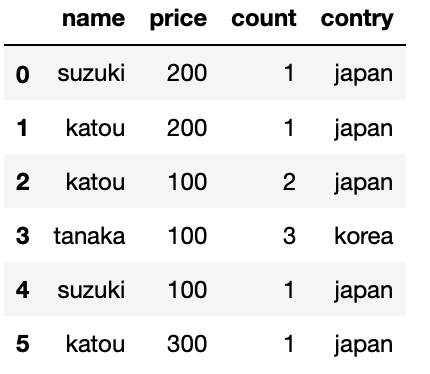
test.groupby("name").mean()
test
(test_group) 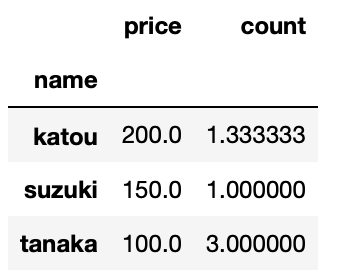
グループの指定に複数の label を指定する事も出来る。name と price の組み合わせで平均をとるには次のようにする。
test.groupby(["name","price"]).mean()
groupby を使うと、デフォルトでグループラベルが index になるため、index にしたく無い場合は as_index=Falseとする。
test.groupby(["name","price"],as_index = False).mean()
mean()のようにグループごとに値を求めて表を作るような操作を Aggregation と呼ぶ。このように GroupBy オブジェクトには Aggregation に使う関数が幾つか定義されているが、これらは agg() を使っても実装出来る。
test.groupby(["name","price"],as_index = False).agg["mean"]
複数の場合
test.groupby(["name","price"],as_index = False).agg["mean","max","min","median"]
(12)to_datetimeについて
to_datetime関数を使って文字列や数値と日付との変換できる。
この関数はある程度ならフォーマットを検知してくれる。
time_1 = "2020-5-15"
pd.to_datetime(time_1)
# Timestamp('2020-05-15 00:00:00')
time_2 = "20200515"
pd.to_datetime(time_2)
# Timestamp('2020-05-15 00:00:00')
time_3 = "2020/5/15"
pd.to_datetime(time_3)
# Timestamp('2020-05-15 00:00:00')
dtについて
また、datetime型になったフォーマットに、dt.strftime()で列を一括で任意のフォーマットの文字列に変換できる。
X
# 2017-11-01 12:24:00
# 2017-11-18 23:00:00
# 2017-12-05 05:05:00
# 2017-12-22 08:54:00
# 2018-01-08 14:20:00
# 2018-01-19 20:01:00
print(df['X'].dt.strftime('%Y年%m月%d日'))
# 0 2017年11月01日
# 1 2017年11月18日
# 2 2017年12月05日
# 3 2017年12月22日
# 4 2018年01月08日
# 5 2018年01月19日
# Name: X, dtype: object
なお、dt.yearで、datetime型の年の部分だけを取り出せる。
(13)カラム名を変更する
rename()メソッドの引数indexおよびcolumnsに、{元の値: 新しい値}のように辞書型で元の値と新しい値を指定する。
df_new = df.rename(columns={'A': 'a'}, index={'ONE': 'one'})
print(df_new)
# a B C
# one 11 12 13
# TWO 21 22 23
# THREE 31 32 33
print(df)
# A B C
# ONE 11 12 13
# TWO 21 22 23
# THREE 31 32 33
(14)whereについて
where()関数では第一引数に条件、第二引数に条件がFalseの要素に代入される値を指定できる。
df = pd.DataFrame({'A': [-2, -1, 0, 1, 2],
'B': [1, 2, 3, 4, 5],
# A B
# 0 -2 1
# 1 -1 2
# 2 0 3
# 3 1 4
# 4 2 5
df["C"] = 0
df["C"] = df["C"].where(df['B'] > 2, 'yes')
df
# ['yes' 'yes' '0' '0' '0']
(15)インデックスを連番に振り直す
df.reset_index(inplace = True)