はじめに
本記事は、AIに頼ってちょっとしたツール開発をした、という体験記です。開発したツールそのものの紹介ではなく、AIと対話しながら開発を進めた具体的なプロセスをお伝えします。
AIをあまり触ったことがなかったり、うまく活用できていない方の参考になれば幸いです。
なお、記事中に「プロンプト」という表現が出てきますが、これはAIに渡す入力文のことを指します。
また、AIに同じプロンプトを与えても毎回同じ結果になるわけではなく、多少変化します。記事中で使っているプロンプトを使っても同じ結果にはならないとは思うので、どういう会話をして開発を進めているのか、というプロセスの部分に目を向けてもらうのが良いかと思います(そういうわけで、作成されたコードも全文を載せているわけではなく主要部分に絞っています)。
開発しようと思ったきっかけ
先日GitHubで、日本語文書に特化したOCR,ドキュメント画像解析を行うPythonパッケージ「YomiToku」が公開されました。
■GitHub
https://github.com/kotaro-kinoshita/yomitoku
■note
https://note.com/kotaro_kinoshita/n/n70df91659afc
画像やPDFなどをOCRして文字起こしできるのですが、精度が高く、ローカルサーバー上で処理が完結するのが魅力的です。
指定のファイルを処理対象とするのはもちろん、フォルダ内のファイルすべてを処理対象にもできるため使い勝手もよく、これもまたありがたい点です。
処理を実行するためにコマンドをたたく必要があるのですが、ここでふと、「画面からできたら楽だよな…」と思ったのが今回開発しようと思ったきっかけです。
とはいえ、画面で実行できたら楽だとは思うものの、そういう開発の知見がほぼないので0から始めるとなるとハードルが高すぎて、やる気になりません。
そこで、自分ではわからないけど、AIに頼んだらできるんじゃないか、ということでやってみました。
使用したAIについて
使用したモデルは「Claude 3.5 Sonnet」です。最近のお気に入りで基本的にこのモデルを使っています。
また、チャットそのものはPoeというサービスで行いました(なので記事中のスクリーンショットもその画面になっています)。
Poeは様々なモデルが使えるサービスで、他にGPT-4oやo1-preview、Gemini 1.5 Proなどのテキスト系のモデルだけでなく、StableDiffusionやFLUXといった画像生成系のモデルも使えるので、いろいろなモデルを試すのに便利です。
なお、Claudeの公式を確認したところ、「Claude 3.5 Sonnet」は無料版では使えなくなっているようでした(2024年12月時点)。
ただ、性能は落ちるものの無料でも使えるHaiku(Claude 3.5 Haiku)でも本記事のゴールには到達できたので、無料版でも十分試せるかと思います。チャットでのやり取りの回数も大して変わらなかったので、思いのほか優秀な印象です。
開発してみる
本題です。まずはAIにYomiTokuを理解してもらうため、READMEとdockerfileを渡して認識してもらいます。
GUIを作るにあたりYomiTokuの実行環境や実行方法を知っていれば十分かと思ったので、これ以外は渡しませんでした。
プロンプト:
添付ファイルについて、コマンドでyomitokuを実行するのではなくGUIでOCR対象を指定したり実行したりしたいのですが、実現できるでしょうか?windowsのdocker上で動かしたいです。
※READMEとdockerfileを添付
回答(主要部分のみ載せていきます):
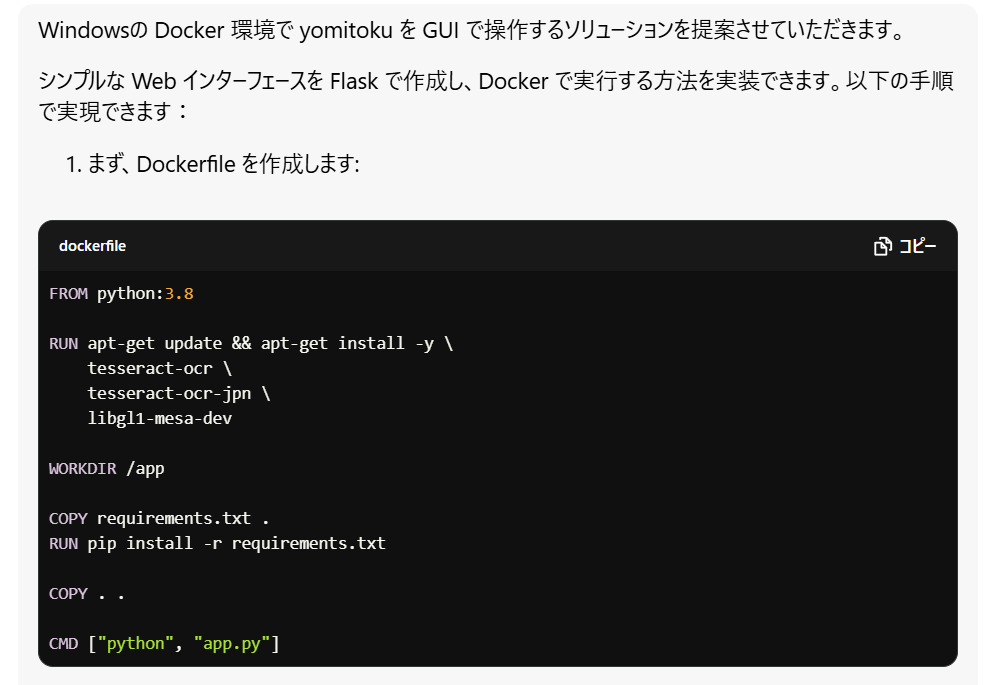

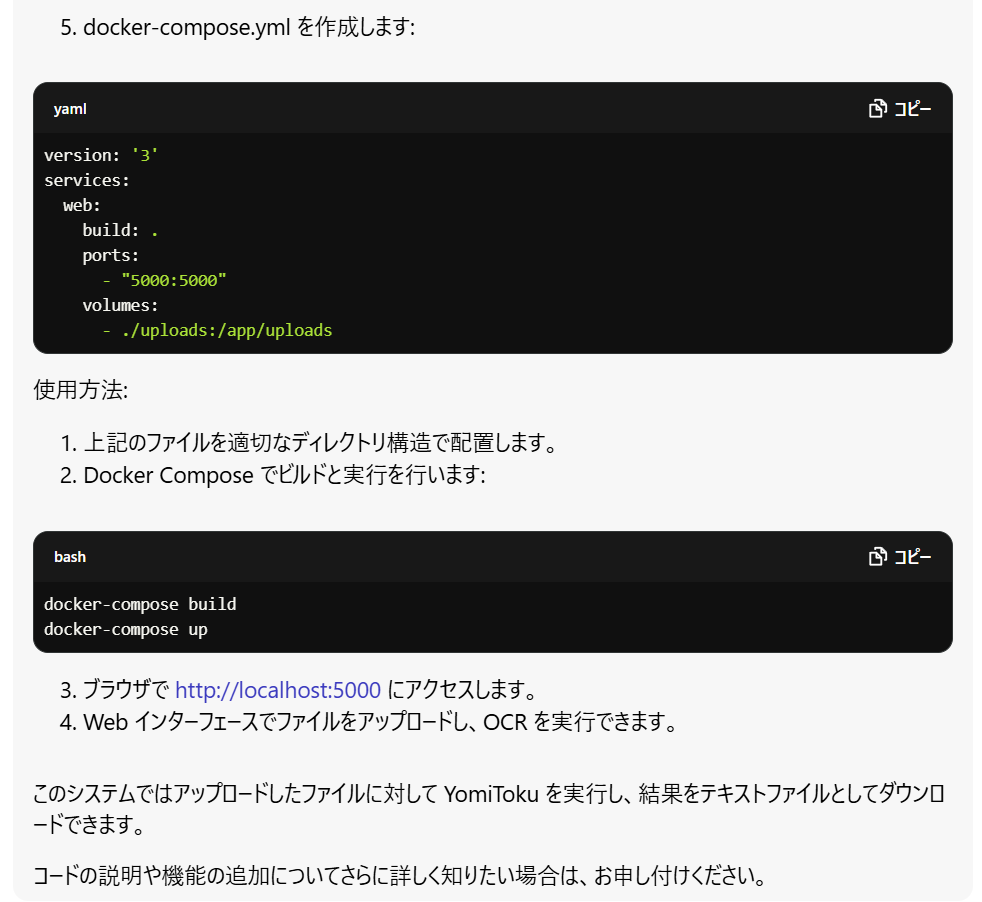
いきなりそれっぽいものができました。ビルド方法からアクセス方法まで書いてあって助かります。
とりあえず動かしてみます。言われたとおりにファイルを作って、ビルド実行。
ビルド中にエラーとなりました。エラーメッセージをすべて渡して解決してもらいます。
プロンプト:
Docker Compose でビルドしたところ、下記のエラーが発生しました。解決できますか?
[エラーメッセージを記載]
回答:


修正案をもらったのでファイルに反映して、もう一度ビルド。今度はうまくいきました。
次はdocker-compose up。ここでまたエラーとなったので、なんとかしてもらいます。
プロンプト:
ありがとうございます。ビルドは成功しました。
ただ、docker-compose upでエラーとなりました。エラーメッセージは下記のようになっていますが、解決できますか?
[ここにエラーメッセージ添付]
回答:


解決法が示されたので、言うとおりにやってみます。
ただ、コードを変更したのでビルドし直さなくていいのかが気になったので、一応聞いてみます。
プロンプト:
再度のビルドは不要なのでしょうか?
回答:

なるほど、マウントしているファイルだから修正不要とのことです。
ただ、これまで作られたコードの中にはマウントされていそうな箇所は見受けられませんでした。
試しに、docker-compose downしてコード修正後、ビルドせずにdocker-compose upを実行してみたところ同じエラーとなったので、やはりビルドは必要そうです。
というわけでビルドし直してみたのですが、yomitokuのインポート部分でエラー。同じようにエラーメッセージを渡してみてインポート文の修正がされるものの、同じ個所でエラー。
インポート文を直してくれているけど、そのやり方は根本的に違うんじゃないの?と思ったので投げてみます。
プロンプト:
同じくyomitokuインポート部分でエラーとなりました。そもそもこのアプローチは正しいでしょうか?確認をお願いします。
回答:
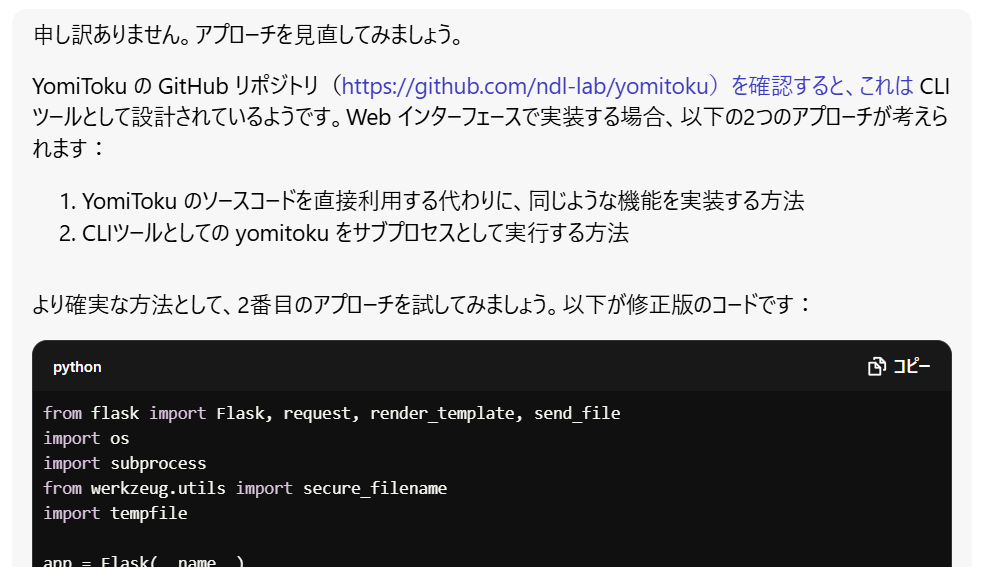

やり方を変えて修正案を出してくれました。
というわけでいくつかのファイルに修正が入ったので、反映して、再ビルドして、起動。
コンソールログ:
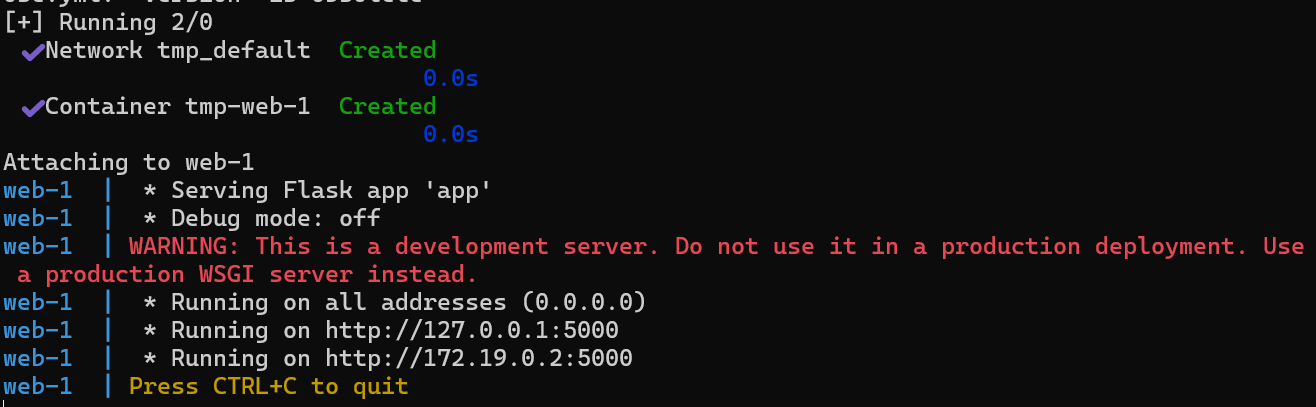
エラーなし!ブラウザからアクセスしてみます。
無事に以下のような画面が表示されました。ちょっと感動です。
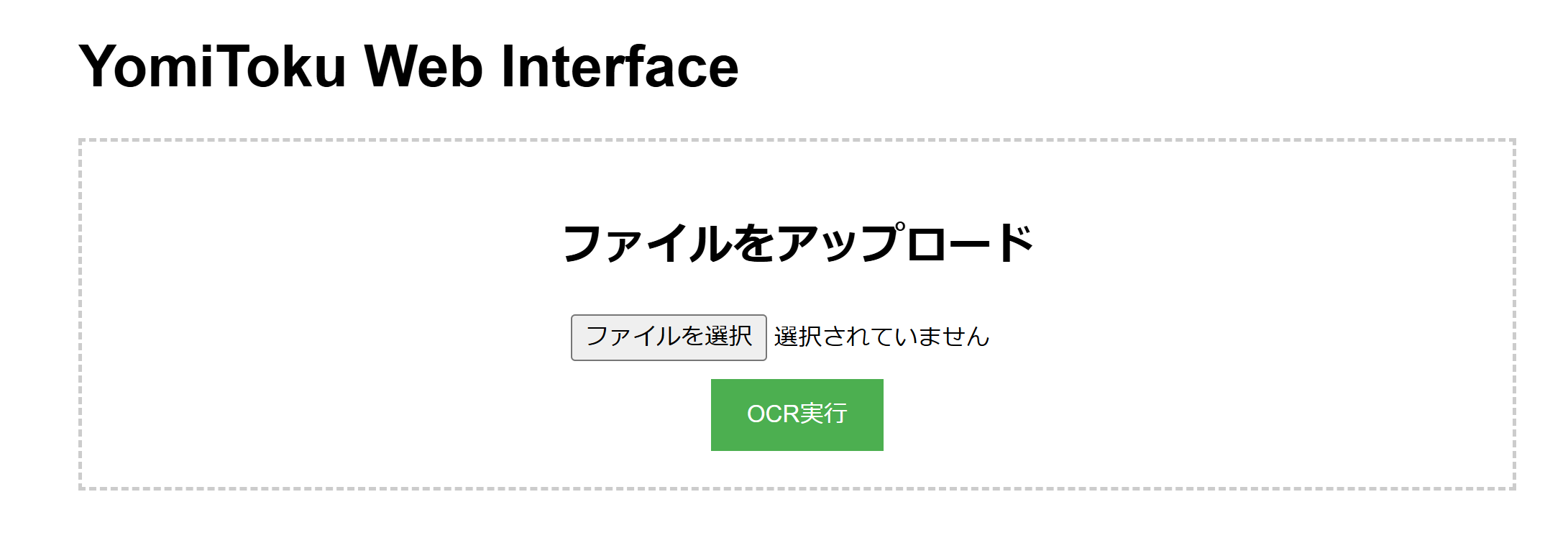
ただ、実際に実行できなければ意味がないので、さっそく実行してみます。
コンソールログ:

ブラウザ上のエラーメッセージ:
OCR処理でエラーが発生しました: Command '['yomitoku', 'uploads/20241203_test.png', '-o', '/tmp/tmp6ieapq5i.txt']' returned non-zero exit status 1.
惜しい。yomitoku自体は動いていそうなものの、結果ファイルの出力でエラーとなっていそうです。
なんとかしてもらいます。
プロンプト:
画面上でOCR実行開始、まではできたのですが、そのあとにエラーが発生しました。解決できますか?
ログ上のエラー:
[コンソール上のエラーメッセージ]
画面上のエラー:
[画面に表示されたエラーメッセージ]
回答:

ファイルを修正して、再度実行。
ブラウザ上のエラーメッセージ:
OCR結果のファイルが見つかりません
yomitokuの処理自体はうまくいってそうなものの、やはりファイル出力部分でうまくいっていないようです。
作成されたコード内にあるコメントを見てみるとディレクトリを作成・削除している個所があり、そこがうまくいっていないかと思ったので、とりあえず動かすために処理をシンプルにします。
プロンプト:
GUI上に「OCR結果のファイルが見つかりません」と表示されます。出力ディレクトリや一時ディレクトリを処理内で作成・削除するのではなく、出力ディレクトリは最初から作っておいて、処理結果はそこに格納するようにできますか?
回答:
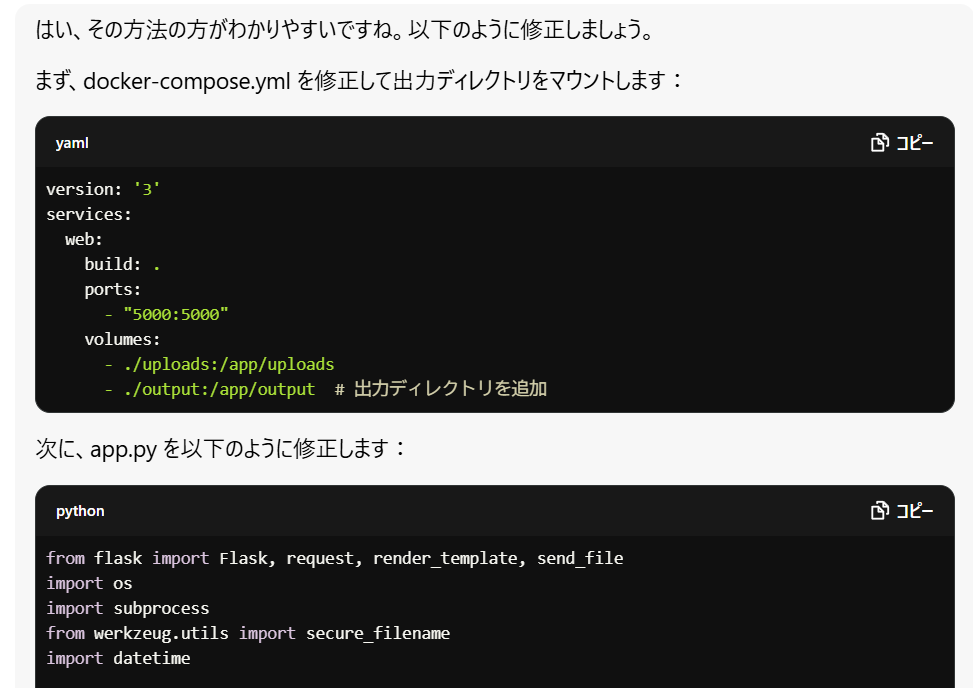
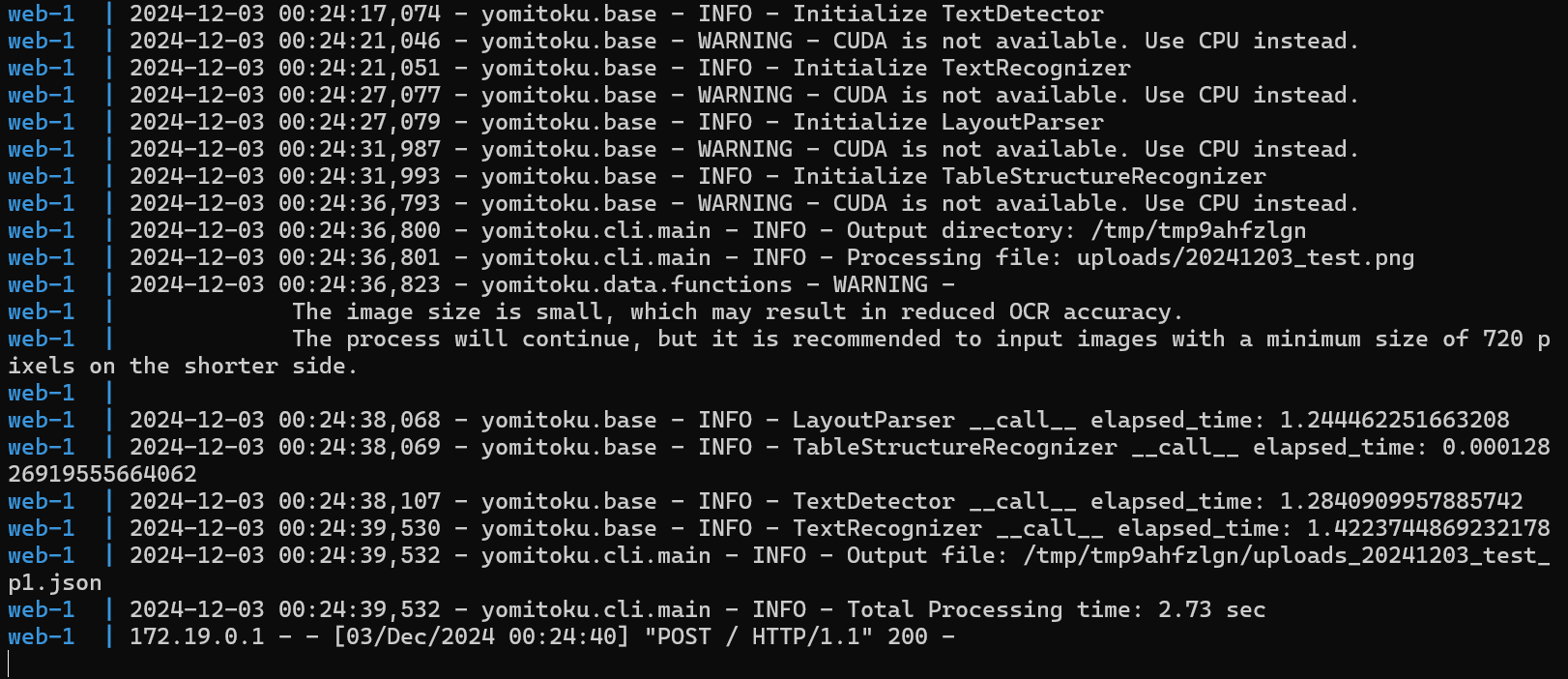
コードを修正し、再ビルド。OCR実行。
なぜか画面上ではエラーが出るものの、ファイル出力されました!(エラーはあとでなんとかするので今はヨシ!)

OCRに使った入力画像は、インポート部分でつまづいた際にアプローチ変更をお願いしたところのやり取りです(スクリーンショットを撮ってそれを処理に使用)。
小さな画像だったので解像度が足りなそうですが、ちゃんとOCRできています(jsonで出力されていますが、他にもcsv, html, mdで出力可能)。

終わりに
そんなわけでAIに頼ってGUIを実装することができました。自分でコードを修正した箇所はまったくありません。
いろいろとエラーも出ましたが、そのエラーの内容も渡してなんとかしてもらいました。
こちらからAIに伝えた内容も、やって欲しいことをそのまま伝えただけで難しいテクニックは使っていません。
自分一人だと、開発しようと思っても実装方法わからないし時間もないしそもそも面倒くさいし…となってなかなか難しいところですが、AIの力に頼ることでハードルがぐっと低くなります。
「こういう機能があると便利なんだけどな~」という軽いモチベーションでもこうして実現できてしまうので、参考になれば幸いです。
おまけ
こうしていったん完成してみると、別の欲が出てきます。
- 実行時のオプションがいくつかあるので、画面上で指定できるようにしたい。かつ、特定のオプションはデフォルトで設定済みとしたい。
- 処理対象のファイルを1つ選ぶ形になっているが、フォルダ内にあるすべてを処理対象にできるようにしたい。
- 処理中の進捗を画面上で確認したい。
- 出力結果ファイルを結合したい。
など、いろいろと出てきました。
これらについては、ここまでに記載したようにやり取りを繰り返して、すべて実装できています。
また、AIとやり取りする際のコツみたいなものを挙げていきます。
- プロンプトは指示や要望が具体的であるほどゴールが近づきます。例えばエラーの原因が自分でわかるのであれば、「ここをこう直して」とお願いするほうが手っ取り早いです。
- 本記事一発目のプロンプトの中に「windowsのdocker上で動かしたい」と入れていますが、この指定がないとMacやLinuxも考慮してしまったり、サーバー構築から始まってしまうので、前提条件なんかも含められるとより良いと思います(もちろん、会話の中で要望を具体化していくのもOK)。
- 逆に、よくわからなくても「こんなエラーが出るんだけどなぜかわかる?」みたいに聞けばいろいろと提案してくるのがAIの良い点です。どんなにくだらない質問でも怒られないし嫌な顔もされません!
- 会話を長く続けていると、AIが会話内容を覚えきれなくなって回答が的外れになってくることがあります。そういうときには新しいスレッドで会話を最初から始めるといいです。作成したファイルやその仕様を軽く伝えればまた始められます(本記事の会話開始時のように)。
- ただ、今回の記事の内容は1つのスレッド内で完結しているので、これくらいは問題ないと思います。