はじめに
去年くらいからベクトル検索が一層注目を浴びているように感じます。LLMの流行に引っ張られてRAG等の用途でも使われることになったのが大きいのでしょう。
筆者もEmbedding Modelを使ってベクトルDB検索を行うことが多々ありますが、検索精度に関してはnDCGやRecall@kなどの指標で定量評価を行うところまでなかなか至らないこともあります。
そんな重い腰を上げる前に、まずは傾向を把握することができる(かもしれない)方法として可視化を試してたいと思います。
AWSではAmazon Titan Embeddings G1-Textという埋め込みモデルがBedrockで利用可能なため、今回はこちらを用いてやってみます。また可視化ツールとしてはTensorBoard Projectorを用いますがそのホストにSagemaker Notebook Instanceを用います。
概要
やること

可視化のイメージ

手順
事前作業:Bedrockを有効化
今回は埋め込みモデル Titan Embeddings G1 - Text を利用します。
当該のモデルがBedrockで利用可能になっていない場合は、Bedrockの「モデルアクセス」から有効化をしておいてください。また以下手順ではバージニアリージョンを前提として話を進めます。
Sagemakerでノートブックインスタンスを起動する
まずは作業用のノートブックインスタンスを起動していきます。
Sagemakerにアクセスし、「ノートブック」⇒「ノートブックインスタンス」をクリックします。
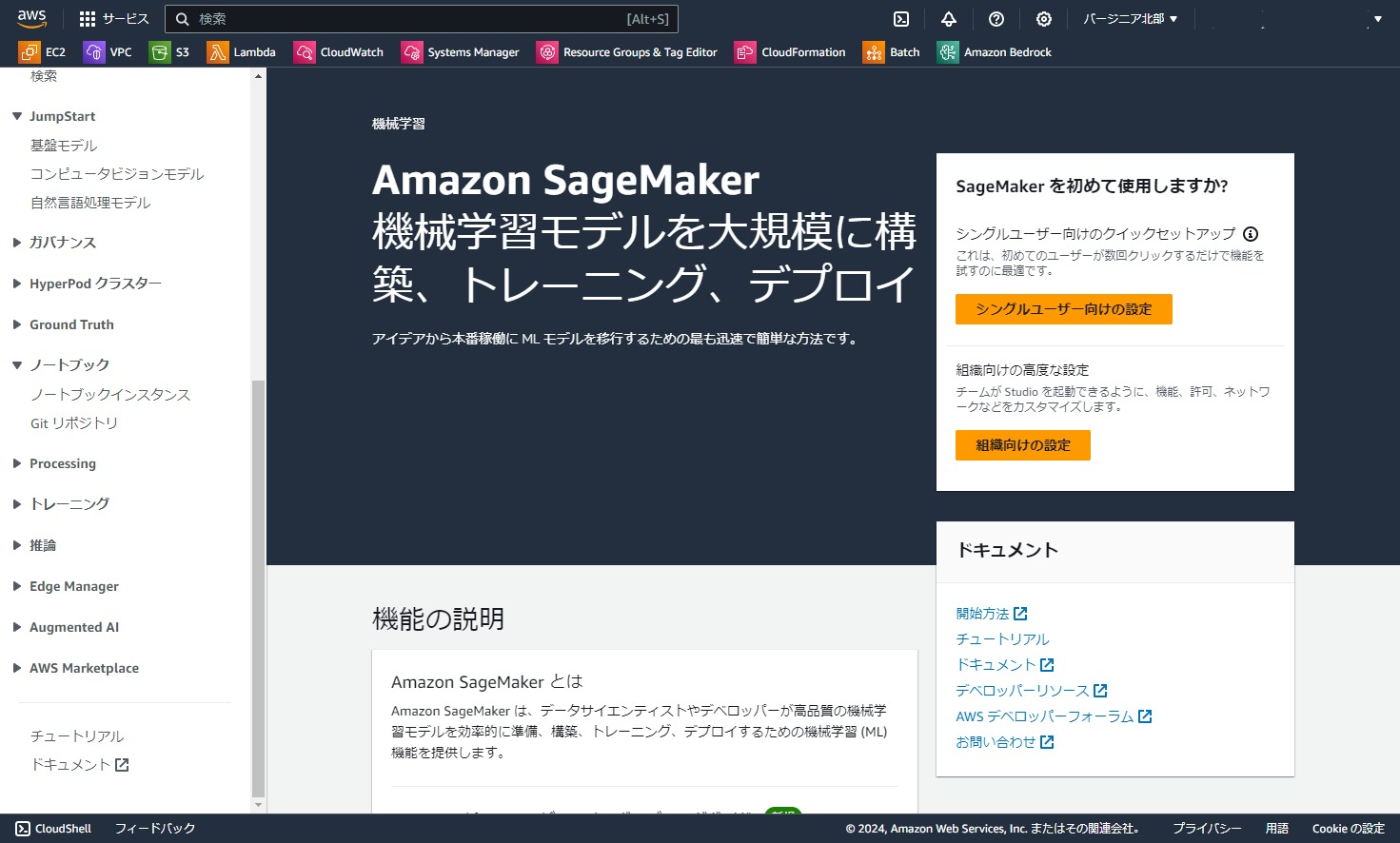
「ノートブックインスタンスの作成」をクリック。
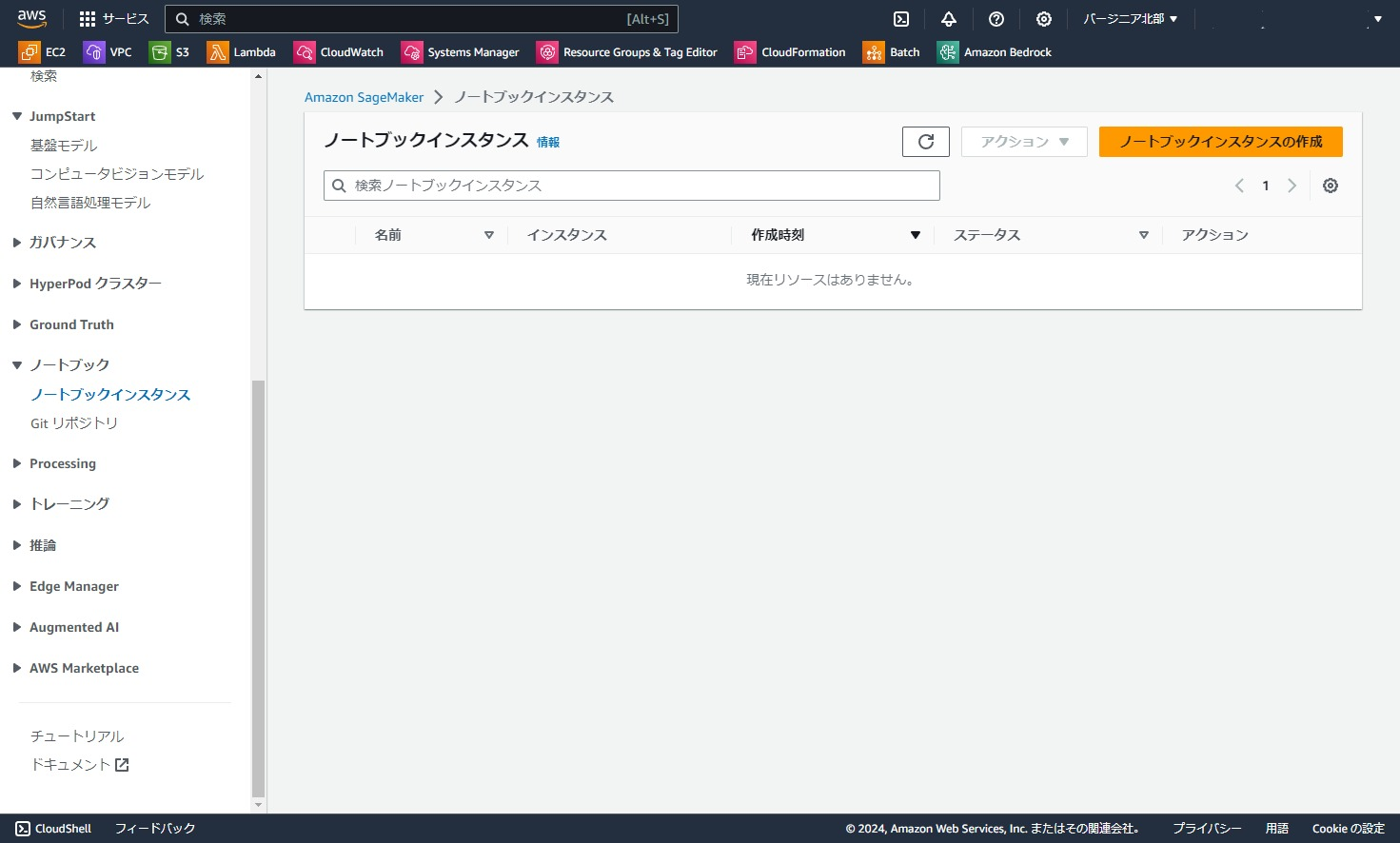
今回は動けばいいので、「ノートブックインスタンス名」だけ記入して他はデフォルト設定を利用します。
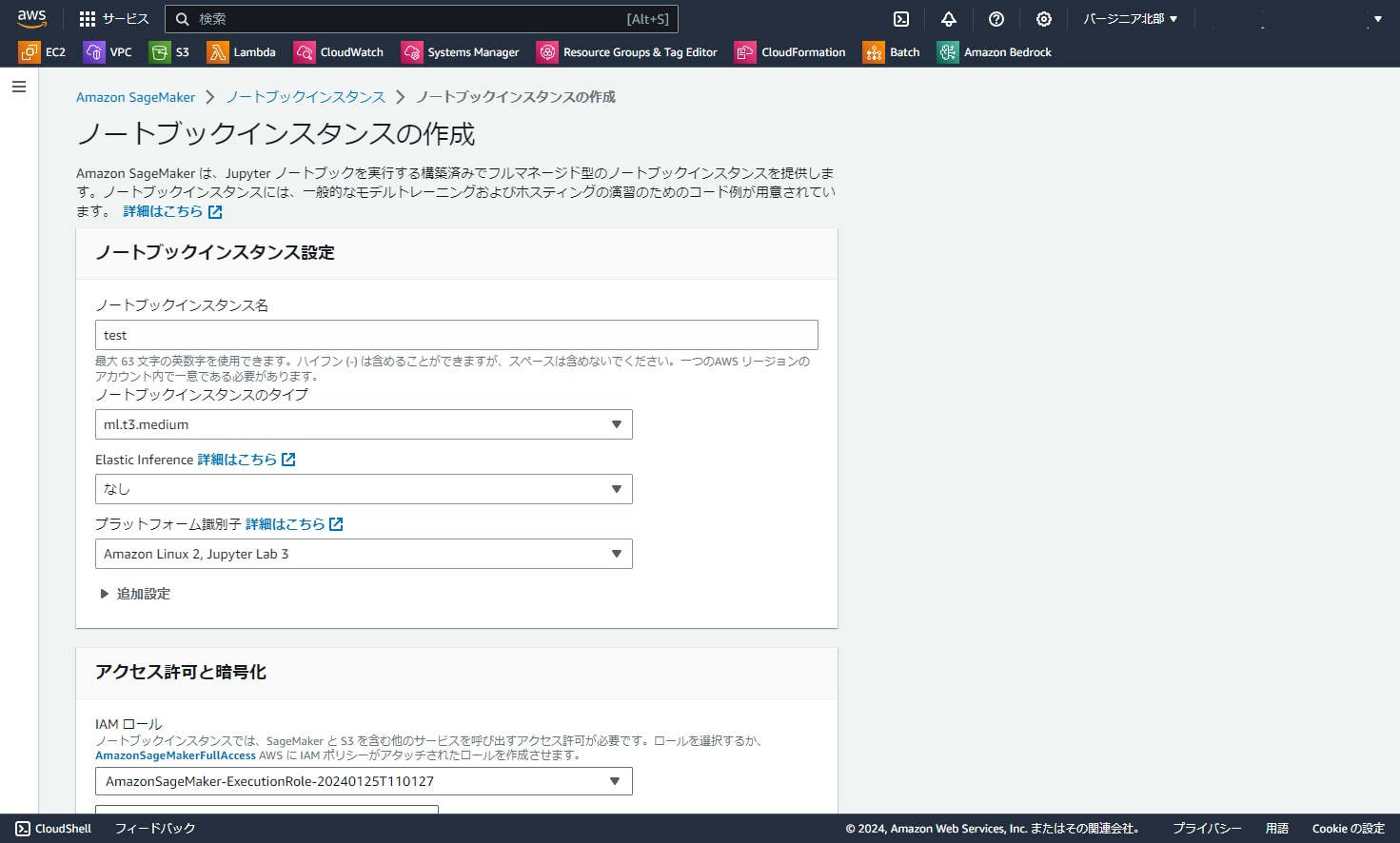
IAMロールは、プルダウンから「新しいロールの作成」を選択し、表示された推奨設定で新規作成したものを選択しました。
その他の設定もデフォルトで「ノートブックインスタンスの作成」をクリックします。

インスタンスの作成は完了です。

IAMロールにBedrockのInvoke権限を追加する
先ほど作成されたIAMロールに対して、Bedrock基盤モデルへのアクセス権限を付与します。
今回はテスト用ですぐ消すのでインラインポリシーで権限を追加します。
IAMで先ほど作成されたロールを開きます。
「許可を追加」⇒「インラインポリシーを作成」をクリックします。

サービスのプルダウンで「Bedrock」を選択します。

今回は基盤モデルのTitanを叩くだけなので、アクション欄はInvokeModelだけ許可にします。
次にリソース欄の「foundation-model」の「ARNを追加」をクリックします。
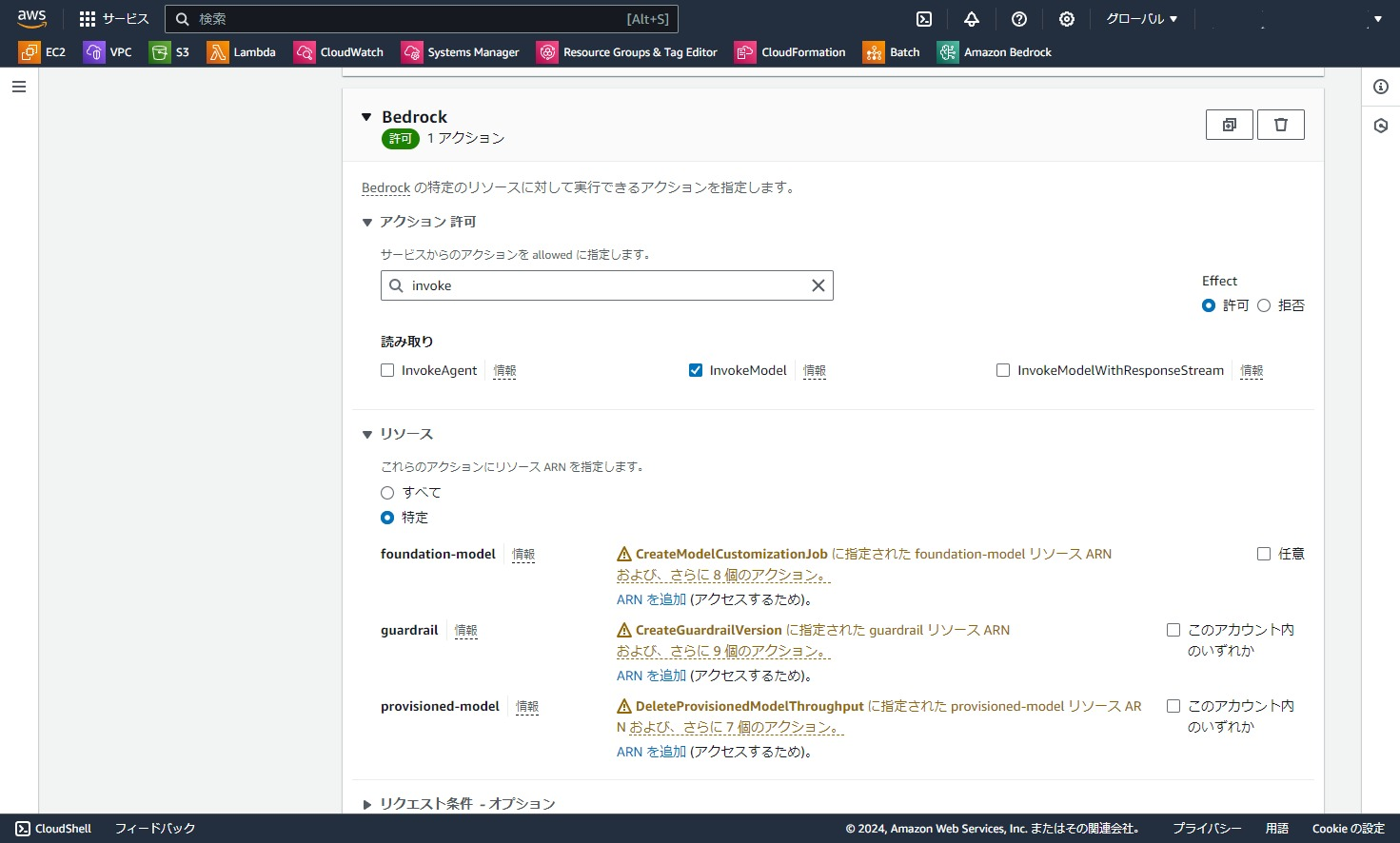
リージョンは任意のリージョン、Resourceにはamazon.titan-embed-text-v1を指定して、「ARNを追加」をクリックします。

設定が完了したので「次へ」をクリックします。
適当にポリシー名を設定して、「ポリシーの作成」をクリックします。

IAMロールの設定は以上です。
Jupyter LabからBedrockを呼び出し、テキストをベクトル化する
ここからいよいよ本題の作業です。
ノートブックの起動
先ほど作成したノートブックインスタンスの「Jupyter Labを開く」をクリックします。

Jupyter Labの画面が開きました。ここではNotbook欄にあるconda_pytorch_p310というノートブックを開きます。(ノートブックは何でもよいですが別のものを選択した場合はpytorchのインストールが必要になります)

ライブラリのインストール
以下を実行し、必要なライブラリをインストールします。(ログが見たいときは--quietオプションは外してください)
%pip install --upgrade --quiet boto3 langchain tensorboard
接続テスト
以下を実行することでBedrockのTitan Embeddingが利用できるか確認します。
今回はLangChainのBedrockEmbeddingsを使ってベクトル化しています。
from langchain_community.embeddings import BedrockEmbeddings
embeddings = BedrockEmbeddings(region_name="us-east-1")
vec = embeddings.embed_documents(
["This is a content of the document", "This is another document"]
)
print(vec)
実行の結果、以下のように2つの入力テキストに対応する2つのベクトルが表示されれば接続テストはOKです。

ちなみにベクトルは1536次元です。

ベクトル化実行
接続テストが終わったので、今回用に作ったダミーデータをベクトル化していきます。
実際の作業では適宜、ご自身のデータに読み替えてください。
ダミーデータの説明
今回使うダミーデータを説明しておきます。
Wikipediaから果物・野菜・お菓子を数件ずつ参照して作ったデータです。
列はtitle、descriptionからなっており、titleはWikipediaの記事名、descriptionはWikipedia記事の冒頭の節のみ抽出しています。titleはラベルに用い、descriptionがEmbeddingの対象です。
以下表が実データです。赤枠が果物、緑枠が野菜、青枠がお菓子となっています。(スイカとメロンは果物ということにしてください)
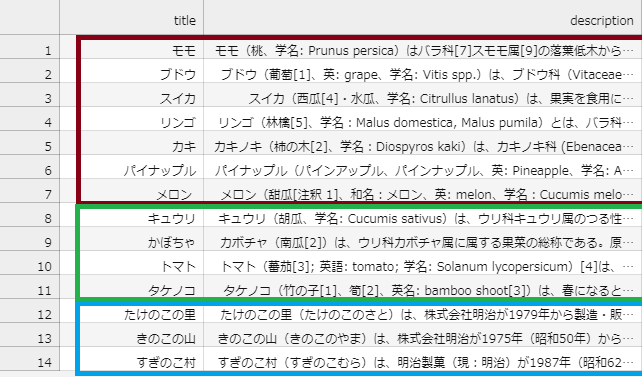
なおファイルフォーマットはTSVで、ファイル名はdata.tsvです。
ダミーデータのベクトル化
ダミーデータファイルdata.tsvをアップロードします。ローカルにあるファイルであれば、ドラッグ&ドロップでアップロードが可能です。

以下のコードを実行します。ダミーデータを読み込み、Bedrockでベクトル化しています。
import csv
# ダミーデータを読み込み
with open('data.tsv', encoding='utf-8') as fi:
reader = csv.reader(fi,delimiter='\t')
# ヘッダ行をスキップ
next(reader)
# データを変数に格納
titles, descs = zip(*reader)
# Bedrockでベクトル化
embeddings = BedrockEmbeddings(region_name="us-east-1")
emb_data = embeddings.embed_documents(descs)
続けて以下のコードを実行します。TensorBoardのフォーマットでデータを出力します。実行すると、./runsというフォルダが作成されます。
import numpy as np
from torch.utils.tensorboard import SummaryWriter
# tensorboard用に変換
writer = SummaryWriter()
writer.add_embedding(np.array(emb_data), metadata=titles)
writer.close()
TensorBoardの起動
続けて以下のコマンドでTensorBoardを起動します。
!tensorboard --host 0.0.0.0 --logdir ./runs
最終的にノートブックは以下のような状態です。
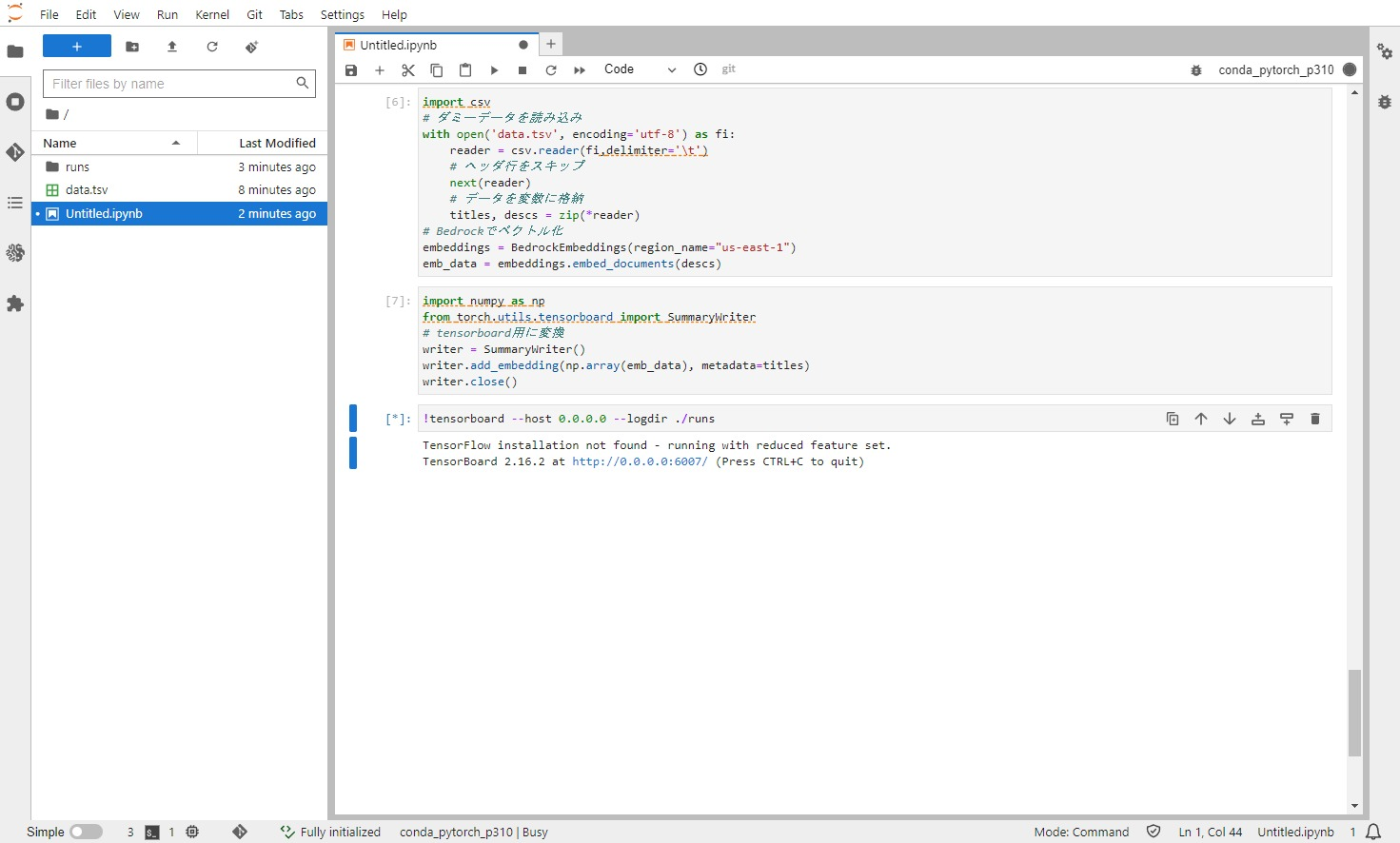
ここで表示されるポート番号を確認しておきます。今回は6007です。
TensorBoardの確認
TensorBoardへの接続
ブラウザでTensorBoardにアクセスします。
接続URLは{ノートブックインスタンスのドメイン}/proxy/{ポート番号}/です。
例えば、Jupyter LabのURLが
https://test-xxxx.notebook.us-east-1.sagemaker.aws/lab/
だった場合は
https://test-xxxx.notebook.us-east-1.sagemaker.aws/proxy/6007/
がTensorBoardのURLです。最後の/も忘れずに入力します。
URLを直接入力して接続すると以下のような画面が開きます。
右上のプルダウンで「PROJECTOR」に選択します。

TensorBoardのProjectorの画面が開き、プロットが表示されます。

TensorBoard Projectorの操作
Projectorを開くと、デフォルトではPCAで次元削減処理されたデータが3次元プロットで表示されています。次元削減アルゴリズムは画面左下のメニューから行うことができ、t-SNEなども選択可能です。
画面は左ドラッグすることでプロットの角度を変えたり、右ドラッグすることで全体を移動できます。

選択ツールで点を範囲選択すると、データのラベルが表示されます。

プロットの確認
3次元のプロットのスクショなので少しわかりにくいですが、ぱっと見で似た属性のものが近傍に配置されていることが分かります。
お菓子群は青色枠周辺に、野菜群は緑色枠周辺、果物群は赤色周辺にまとまっています。今回は投入したデータ数が極めて少ないということもありますがきれいに各文章の特徴で分けることが出来ているのが分かります。

また別の視点から見ると「スイカ・キュウリ・メロンが比較的近い=ウリ科共通?」「タケノコがちゃんとたけのこの里やきのこの山と近い」「トマトとかぼちゃ、りんごとパイナップルがそれぞれ近い」などが見て取れました。
Embeddingならでは感はあまり出ませんでしたが、意味的に近いものがきちんと近くに配置されている感じはしますね。
ちなみに、いずれかのデータ点を選択すると右ペインに距離が近いもの順で上から表示され、プロットの色も距離によってグラデーションになります。
以下の画像では「スイカ」を選択した結果、「キュウリ」「メロン」「トマト」の順に上から表示されています。距離はユークリッド距離とコサイン類似度が表示可能です。
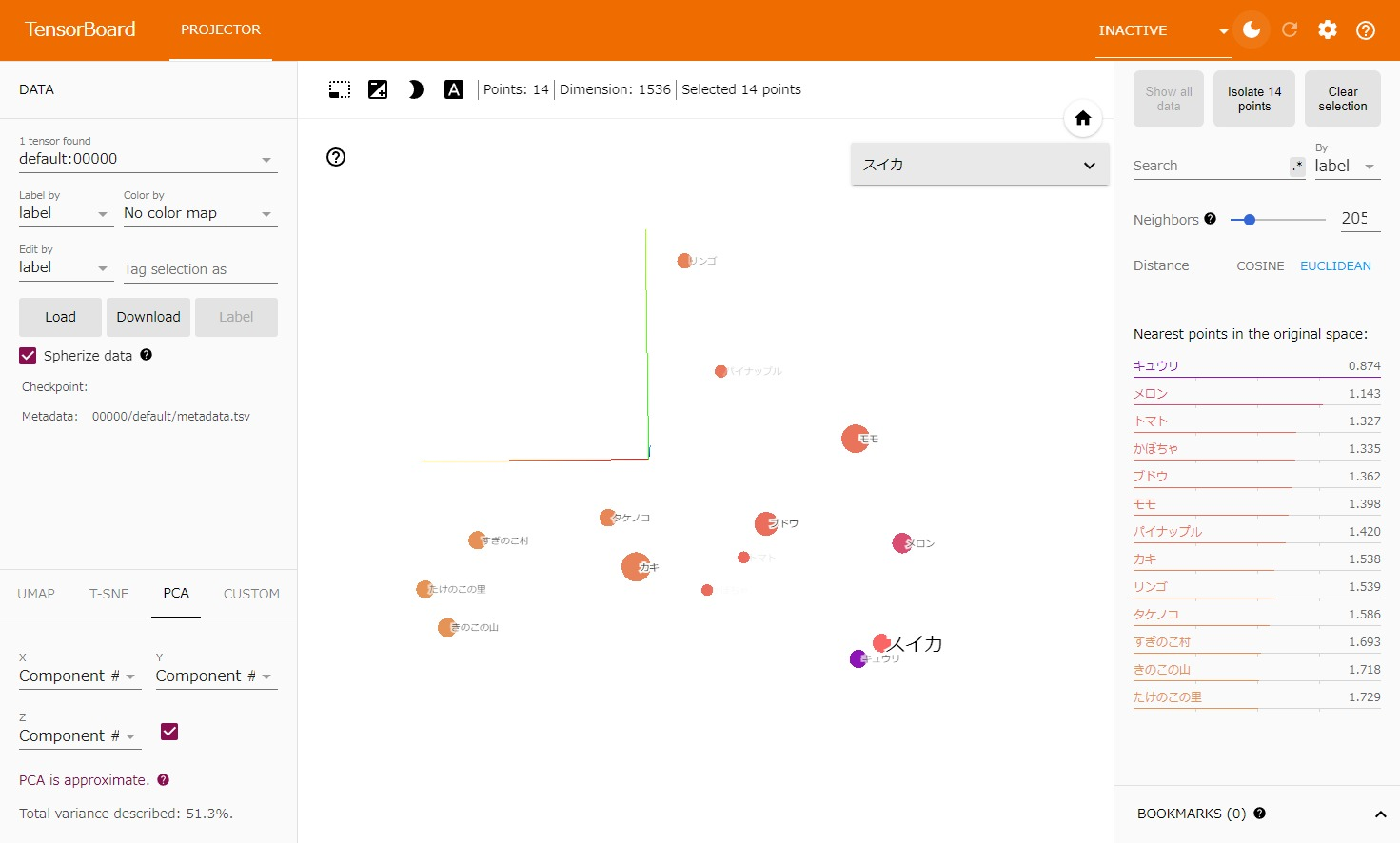
というわけで、Sagemaker NotebookでTensorBoardを使ってベクトルデータの可視化をすることができました。
補足
可視化情報は信用できるのか?
この記事の根底を覆すような話ですが、ベクトルを3次元表示したところ類似テキストが近傍にあったからといって、実際にベクトルサーチをした際にそのテキスト同士で上位に検索できる保証はありません。
初期の傾向把握に使うのには適していると思いますが、当然ながらこれで「分析完了」とはならない点は注意が必要です。元のベクトルデータ1536次元を3次元に次元圧縮している都合、情報量としてはかなり落ちていますので、あくまで傾向を見るものとして捉える必要があります。
そもそも表現力をあげるために次元数を増やしているのに次元削減して可視化したところでナンセンスというのもあると思います。使い処を間違えないように気を付けましょう。
内なる声「ローカルでやればいいじゃん」
正直なところJupyterもTensorBoardも「ローカルでやればいいじゃん」と言われればそれまでなのですが(私自身そうしている)、色々な制約でAWSを使う必要があるときには参考にできるかと思います。
例えば、「プライベートサブネットにあるベクトルDBのデータをちょっと分析しておいて~」と上司に言われたときなんかには、さくっとノートブックインスタンスをVPC内に立ててベクトルデータをダンプして表示することが出来ます。
また、Sagemaker Studio Classicでも同じような手順で実現可能なので、複数人で共有しながらやりたい場合にはローカルでやるより高効率な可能性があります。
といった感じで、使うときは使うし、使わないときは使わないね、というレベルの話でした。
おわりに
Sagemaker Notebook InstanceでTensorBoard使ってる人が地味にすくなそうだったので記事を書いてみました。Sagemaker Notebook, Bedrock(Titan Embedding), TensorBoardはそれぞれを使うのは非常に楽なので割と低カロリーにできるのではないかなと思います。ベクトルデータの可視化が必要になった際はぜひ使ってみてほしいです。
Notebook Instanceでの/proxy/~~~によるアクセスは、結構便利です。解析結果をstreamlitなどの簡単サーバで立ち上げてブラウザアクセスしてもらうとか、TensorBoadと同じくモニタリング系ツールを立ち上げるとか、色々と用途がありますのでこちらも使えるときに使ってみてください。