はじめに
先日、GoogleのGemmaがSageMaker JumpStartで使えるようになったとXで見かけました。
Gemmaは7Bモデルと2Bモデルが公開されており、LLMとしては比較的軽量なモデルです。高価なGPUが用意できない場合やエッジコンピューティングでの利用も可能なため、個人的に気になっているモデルです。
ということで実際にSageMaker JumpStartでGemmaをデプロイし、推論を試すところまでやってみました。
件のポスト↓
SageMaker Jumpstartとは
SageMaker JumpStartは、公式説明では以下のようになっています。
機械学習 (ML) のハブとして、基盤モデル、組み込みアルゴリズム、および数回のクリックでデプロイできる事前構築済みの機械学習ソリューション
SageMaker Studioというプラットフォーム上からGUIで事前モデルをデプロイ、ファインチューニングが可能で、モデル実行のための環境準備という手間を省くことができます。
また払い出される推論エンドポイントからリクエストが可能なため、推論用の環境管理も意識する必要がなく、運用負荷も軽減されることでしょう。
今回は使いませんが、AutoScalingやShadowTestingといった機能もあり、検証用途から本番運用へスムーズに移行できるようで、MLOps的なソリューションとなっています。
利用可能なモデル
テキスト生成や画像生成などの多数のモデルが利用可能となっています。
利用可能なモデルは以下のページから確認可能です。
Amazon SageMaker JumpStart の開始方法
※ただし、今回利用するGemmaや先日追加されたCyberAgentLMなどは上記ページで検索してもヒットしませんでした。
※追記3/12
以下のページではGemmaはヒットしました。
Built-in Algorithms with pre-trained Model Table — sagemaker 2.212.0 documentation
手順
今回の実施概要

構成としては上図のような形となります(IGWやNATGW等は省略)。
まずはSageMaker StuidoでGemmaをデプロイしてエンドポイントを払出し、その後EC2からPythonでアクセスします。
VPC内のリソースについては、特別なことはしていないので手順の中では言及しません。最後にPythonでリクエストできることを確認するのみです。
メインはSageMaker Studioによるデプロイ手順です。
Sagemeker Studioの作成
まずはJumpStartを使う為のSagemeker Studioを作成します。
SageMaker Studioは、ドメインという単位の中にユーザが存在していますので、まずはドメインが必要です。
SageMakerを開きます。

左メニューから「ドメイン」をクリックし、「ドメインの作成」ボタンをクリックします。

今回はプライベートサブネットからのアクセス制御を行いたかったので、「組織向けの設定」を選択しました。
簡易的な利用であれば「シングルユーザ向けの設定」で問題ないと思います。

「ドメイン名」を任意に記入します。

今回は「IAM経由でログイン」を選択しました。

「+ユーザを追加」から自分用のユーザ名を任意で設定します。
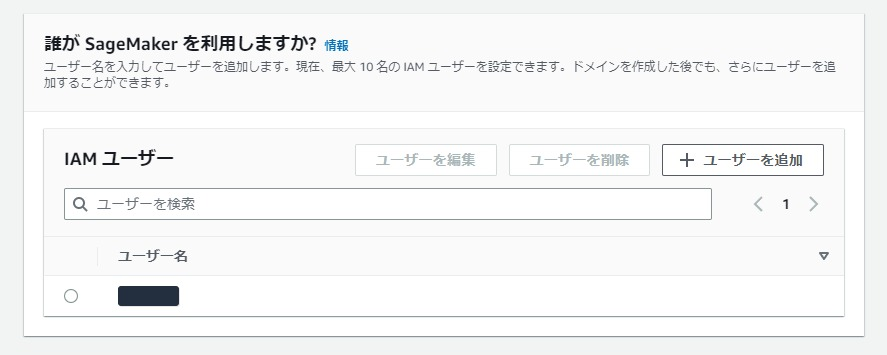
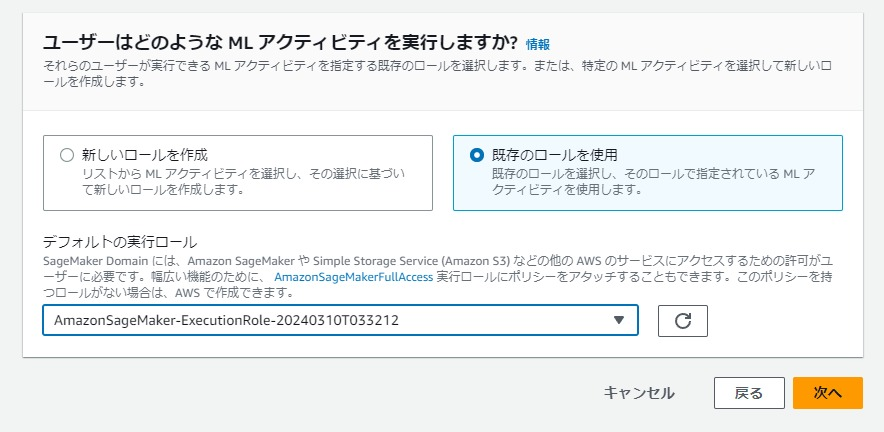
つい先日作ったIAMロールがあったので「既存ロールを使用」から選択しました。
初回利用の場合は「新しいロールを作成」を選択すると推奨ロールが作られるので便利です。
「SageMaker Studio」を選択します。基本的にはClassicを選ぶ必要はないでしょう。

今回はVPCからの利用を想定しているので、「VPC」を選択し、VPCとサブネットを選択します。

ストレージはデフォルト設定です。

確認画面が表示されたら「送信」。

ドメインの作成とユーザの作成が完了しました。

JumpStartからGemmaをデプロイする
SageMakerのページから「Studio」を選択すると、右側にユーザプロファイルの選択が表示されるので、ユーザを選択して「Studioを開く」ボタンをクリックします。
SageMaker Studioの画面が開きます。

左メニューの「JumpStart」をクリックし、検索欄に希望のモデル名を入力します。
今回は「Gemma」です。利用可能なモデルが4つ表示されました。

今回はより小さい方のモデル「Gemma 2B Instruct」を利用します。
「Deploy」ボタンをクリック。

Deployの設定画面が表示されます。上から順に入力してきます
ライセンス同意にチェックを入れます。

エンドポイント情報を入力します。
エンドポイント名は自動入力のものを使います。インスタンスサイズは任意のサイズを使います。

なおGemma 2B Instructモデルでは、g5系のインスタンスサイズとp4d.24xlargeのみ選択可能でした。

Advanced Optionも設定します。ここではVPCとプライベートサブネットを入力し、
サブネットからのインバウンドを許可するセキュリティグループを選択しました。

「Deploy」をクリックします。
エンドポイント情報が表示され、しばらくするとStatus欄が「in-service」となります。
ここで表示されているARNは、IAMポリシーでリソース指定の許可を行うときに使う値なので、必要があればメモしておきましょう。

Studioからテストリクエストを送信する
まずはSageMaker Studioでテストリクエストを投げてみましょう。
エンドポイント画面で下側のタブ「Test inference」をクリックします。
デフォルトで用意されているリクエストを試すことができます。
「Send Request」をクリックします。

レスポンスが返ってきました。生のResponseがそのまま表示されます。実行できていますね。

別の場所から推論リクエストを投げるために「User Pyton SDK example code」を選択して、コピーしておきましょう。

EC2からテスト実行
では別の場所ということでEC2から推論を実行してみましょう。
IAMロールの設定
リクエストを投げる前に、EC2にSageMakerのエンドポイントアクセス権限を与える必要があります。
ここではEC2に以下のポリシーを持つIAMロールをアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"sagemaker:InvokeEndpointAsync",
"sagemaker:InvokeEndpoint"
],
"Resource": "arn:aws:sagemaker:ap-northeast-1:000000000000:endpoint/jumpstart-xxxxxxxxxx"
}
]
}
Actionとしては、sagemaker:InvokeEndpointだけあれば接続はできるはずです。
Resourceは、先ほど確認したエンドポイントのARNを設定します。
Pythonでリクエスト実行
詳細は割愛しますが、EC2上のPython実行環境に以下のファイルを作成します。
先ほどコピーしておいたPythonのコードを使います。
import json
import boto3
# user\n の後を変更
payload = {
"inputs": "<bos><start_of_turn>user\n果物の名前を3つ教えて<end_of_turn>\n<start_of_turn>model\n",
"parameters": {'max_new_tokens': 256},
}
newline, bold, unbold = "\n", "\033[1m", "\033[0m"
endpoint_name = "jumpstart-dft-hf-llm-gemma-2b-instr-20240311-143558"
def query_endpoint(payload):
client = boto3.client("runtime.sagemaker", region_name="ap-northeast-1")
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType="application/json", Body=json.dumps(payload).encode("utf-8")
)
model_predictions = json.loads(response["Body"].read())
generated_text = model_predictions[0]["generated_text"]
# ↓コメントアウト
# print(f"Input Text: {payload['inputs']}{newline}" f"Generated Text: {bold}{generated_text}{unbold}{newline}")
# ↓追加
print(generated_text)
query_endpoint(payload)
ほぼ元のコードをそのまま使っていますが、
payloadのuerプロンプトの部分を日本語に書き換えています。
また結果表示もデフォルトだと長ったらしいので、LLMの出力だけを表示するように変更しました。
作成したスクリプトを実行します。
$ python req_gemma.py
レスポンスが返ってきました。ちゃんと出力できていますね。
<bos><start_of_turn>user
果物の名前を3つ教えて<end_of_turn>
<start_of_turn>model
1. apple
2. banana
3. orange
ちなみに<start_of_turn>のようなタグは、Gemmaのプロンプトの書き方のようです。
Gemma | Prompt Engineering Guide
ということで、SageMaker Studio払い出したエンドポイントに対して、EC2からリクエストができる状態になりました。
まとめ
今回はSageMaker JumpStartを使ってGemmaの推論エンドポイントをデプロイしリクエスト実行まで試してみました。
同じことを一からEC2でやるともう少し面倒な手順を踏む必要があると思うので、ちょっと試したいというときには良いかもしれません。
SageMaker Studio上で「Train」とボタンがあるように、Fine-tuneも簡単にできるようなので、時間があるときに試してみたいと思います。(コストを調べてから。。)
補足
ちなみに今回のGemma 2Bはg5.xlargeがデプロイできる最小構成だったのですが、
このインスタンスサイズは現在値で東京リージョンだとUSD 1.459/h。
1ドル=150円換算なら、1日5,252円、30日156,572円です。
Gemma 2Bは軽量が売りのモデル(という個人認識)なので、EC2で自前デプロイすればもう少し抑えられそうな気もします。個人的には、単に推論用途で試してみたいだけならちょっと割高かなという感想です。GPU周りのめんどくさい設定やらホスト管理を考えなくて済むというメリットもあるのでこのコストを許容できるかは環境次第かと思います。また今回は試していませんが、Auto Scallingの設定が出来たり、Shadow Test機能などもあるので、本番運用を考えるときには候補に挙がってくるんでしょう。