要約
LLMを使って
これを
こうします
はじめに
今回はBedrockの利用ユースケース案の簡単な検証です。
冒頭示したように、Glue Data CatalogにはGlueでETLジョブを走らせるためのデータスキーマが登録されています。各カラムには名前とデータタイプのほかにコメントを格納できます。コメント自体は機能に何ら影響は与えません。メモ書きです。
あまり意識することはないかもしれませんが、AthenaなどS3をソースにテーブル作成する際には、バックグラウンドで自動的にData Catalog テーブルが作成されます。今回対象としているテーブルもその一つで、先日以下の記事でAthenaを利用する際に作られたテーブルです。このほかにもELBのログ分析のためAthenaを使ったことがある人もそのテーブルが作られているはずです。
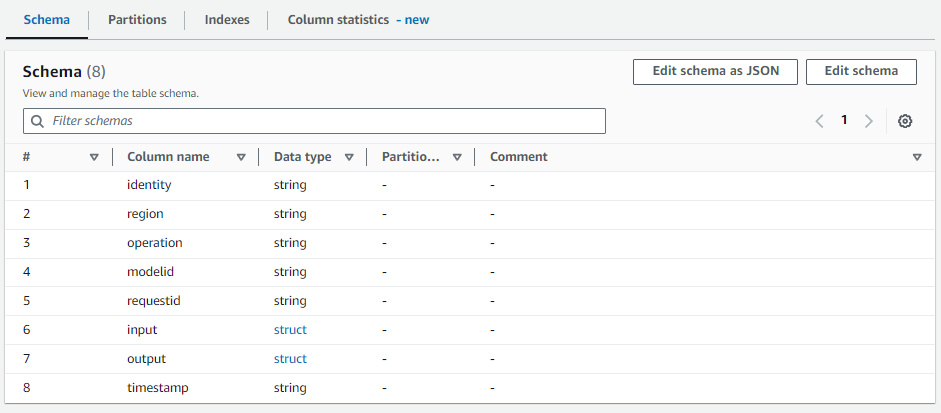
このテーブル自体は何てことないテーブルですし、この前作られたばかりなので各カラムが何を示しているか私にはすぐわかります。記事を読んでくれた人にも多分分かります。しかし、数か月後の自分がこのテーブルを見た時、input, outputが何を意味しているか、すぐに思いつかないかもしれません。初見の他人がみればなおさらです。
そこでLLMにデータカラムが何のデータなのか、コメント付けをさせてみようというのが今回の記事です。データカタログの運用・管理の自動化、人間の負荷軽減に使えるのではないかなと思ったので検証してみます。
手順
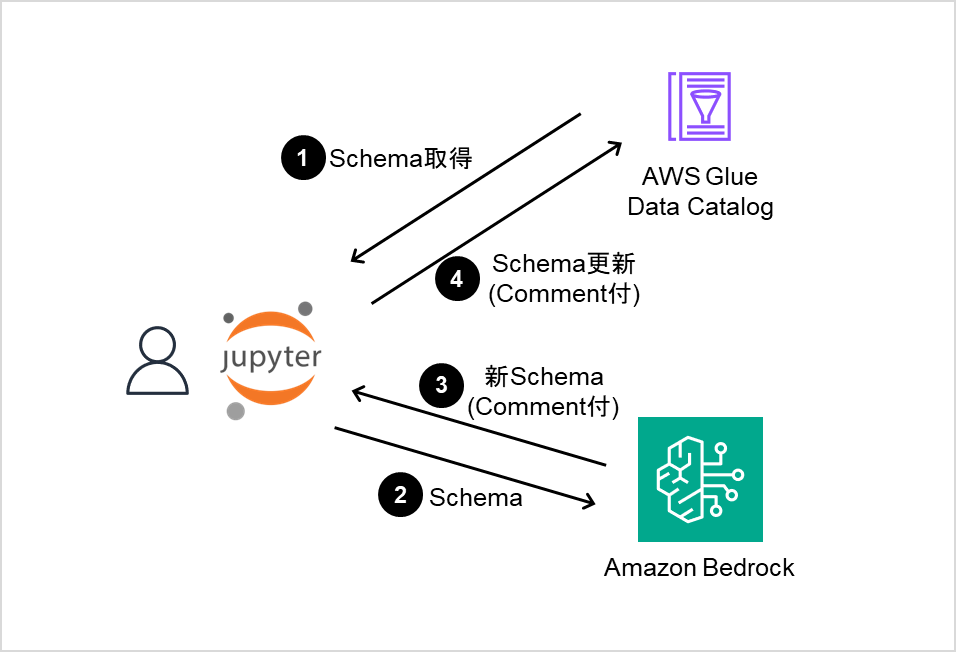
今回のざっくりとした構成は以下の通りとなります。
ローカルのboto3からGlue Data CatalogとBedrockを利用して全ての操作を行います。
ライブラリインストール
今回は以下のライブラリを使いました。実行環境にインストールしておきます。
pip install boto3 litellm
スキーマの取得
まずはDataCatalogからテーブルのスキーマを取得します。
ローカルのPython環境で認証を通します。
import os
os.environ["AWS_ACCESS_KEY_ID"] = "" # Access key
os.environ["AWS_SECRET_ACCESS_KEY"] = "" # Secret access key
os.environ["AWS_REGION_NAME"] = "us-east-1" # Region
boto3 clientを使ってテーブル一覧を取得してます。今回はbedrockデータベース内のテーブルを対象にしています。
import boto3
client = boto3.client('glue', region_name = 'us-east-1')
db_name = "bedrock"
response = client.get_tables(
DatabaseName=db_name,
)
以下はレスポンスの抜粋です。
TableList.StorageDescriptor.Columnsがテーブルスキーマの本体です。
{
"TableList": [
{
"Name": "bedrock_logs",
"DatabaseName": "bedrock",
"CreateTime": "",
"UpdateTime": "",
"Retention": 0,
"StorageDescriptor": {
"Columns": [
{
"Name": "identity",
"Type": "string",
"Comment": ""
},
{
"Name": "region",
"Type": "string",
"Comment": ""
},
{
"Name": "operation",
"Type": "string",
"Comment": ""
},
{
"Name": "modelid",
"Type": "string",
"Comment": ""
},
{
"Name": "requestid",
"Type": "string",
"Comment": ""
},
{
"Name": "input",
"Type": "struct<inputTokenCount:int>",
"Comment": ""
},
{
"Name": "output",
"Type": "struct<outputTokenCount:int>",
"Comment": ""
},
{
"Name": "timestamp",
"Type": "string",
"Comment": ""
}
],
"Location": "s3://bedrock-test-20230000/AWSLogs/000000000000/BedrockModelInvocationLogs",
"InputFormat": "com.amazon.ionhiveserde.formats.IonInputFormat",
"OutputFormat": "com.amazon.ionhiveserde.formats.IonOutputFormat",
"Compressed": False,
"NumberOfBuckets": 0,
"SortColumns": [],
"StoredAsSubDirectories": False
},
"CreatedBy": "arn:aws:iam::000000000000:user/username",
"IsRegisteredWithLakeFormation": False,
"CatalogId": "000000000000",
"VersionId": "7"
}
]
}
今回はbedrock_logsというテーブルを対象とするので、テーブルリストから単体のテーブル部分を抽出しておきます。
tbl_name = "bedrock_logs"
for tb in response["TableList"]:
if tb["Name"] == tbl_name:
table = tb
Bedrockでカラムコメント作成
litellmを使ってBedrockのCalude 3 Sonnetにカラムコメントを作成させます。特にlitellmである必要はないのでboto3がいい人はboto3.client("bedrock")を使ってください。
{info}で与えているのは取得したテーブルの情報全量(スキーマ含む)、{schema}で与えているのはテーブルスキーマ部分のみです。雑に与えています。
import litellm
prompt = """
あなたは優秀なデータエンジニアです。
与えられるテーブル定義を見て、各ColumnのCommentフィールドに日本語で説明文を入れることが仕事です。
<schema>タグに与えられた値を加工してCommentフィールドを埋めたJSONを出力してください。
またテーブルの補足情報を<info></info>に与えるので参考情報としてください。
<info>
{info}
</info>
<schema>
{schema}
</schema>
""".format(schema=table["StorageDescriptor"]["Columns"], info=table)
print("入力: \n", prompt)
resp = litellm.completion(
model = "bedrock/anthropic.claude-3-sonnet-20240229-v1:0",
messages = [{"role": "user", "content": [{"type": "text", "text": prompt}]}],
stream = False,
max_tokens=4096
)
print("出力: \n", resp.choices[0].message.content)
出力は以下の通りです。
[
{
"Name": "identity",
"Type": "string",
"Comment": "顧客IDまたはデータ主体を一意に識別する値"
},
{
"Name": "region",
"Type": "string",
"Comment": "モデルがデプロイされているAWSリージョン"
},
{
"Name": "operation",
"Type": "string",
"Comment": "呼び出されたAmazon Bedrock の操作名"
},
{
"Name": "modelid",
"Type": "string",
"Comment": "呼び出されたモデルのID"
},
{
"Name": "requestid",
"Type": "string",
"Comment": "呼び出しリクエストの一意のID"
},
{
"Name": "input",
"Type": "struct<inputTokenCount:int>",
"Comment": "モデル入力の構造体。inputTokenCountはモデル入力のトークン数。"
},
{
"Name": "output",
"Type": "struct<outputTokenCount:int>",
"Comment": "モデル出力の構造体。outputTokenCountはモデル出力のトークン数。"
},
{
"Name": "timestamp",
"Type": "string",
"Comment": "モデル呼び出し時のタイムスタンプ"
}
]
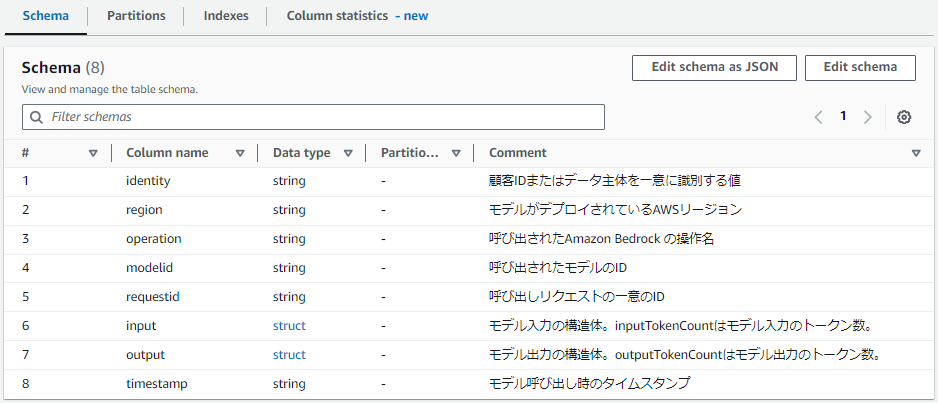
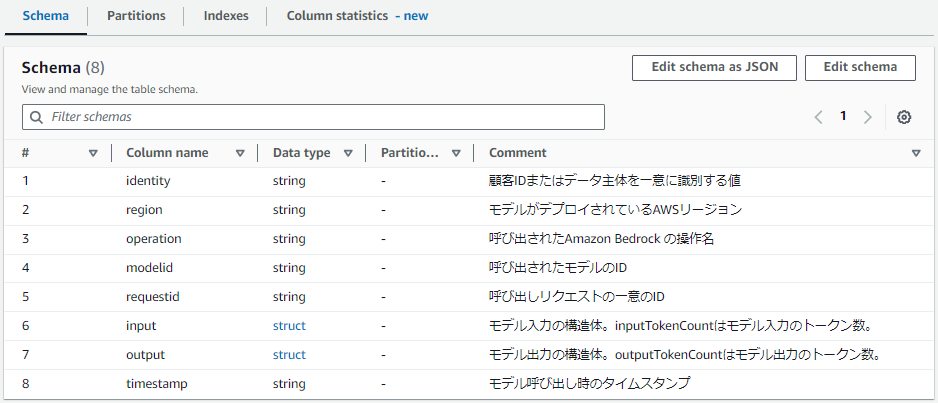
いかがでしょうか。個人的にはまあまあいい感じだと思います。恐らく筆者が手動でつけても似たようなコメントになるでしょう。強いて言うなら一つ目の顧客IDまたはデータ主体を一意に識別する値は、IAMエンティティとしてくれればもっとよかったですが、おおむね問題なさそうです。
見てわかる通り、regionが「AWSリージョン」であることやoperationが「呼び出されたAmazon Bedrock の操作名」であることがLLMには認識できています。これはTableListの中に含まれていたS3のLocationやbedrock_logsというテーブル名とBedrockがAWSのサービスであるという事前知識からLLMが推測している内容です。
LLMがより高度なコメント付けを行うには、Column statisticsの情報を一緒に与えたり、S3のLocationパス配下からサンプルデータを一つとってきてファイル内容を渡したりしてみてもいいかもしれません。
Schemaの更新
LLMが作成したスキーマを更新するだけですが、実行します。
import re
import json
# テキストのコードブロック内だけ抽出する
def extract_code_blocks(text: string):
code_blocks = re.findall(r'```(?:.*?)\n(.*?)\n```', text, re.DOTALL)
return code_blocks
# LLMの出力をdictionaryにする
def read_content(d: dict):
try:
return json.loads(d)
except json.decoder.JSONDecodeError as e:
return json.loads(extract_code_blocks(d)[0])
# 更新
response = client.update_table(
CatalogId=table["CatalogId"],
DatabaseName=table["DatabaseName"],
TableInput={
"Name": table["Name"],
"StorageDescriptor": {
"Columns": read_content(resp.choices[0].message.content)["Columns"]
}
}
)
print(response)
read_contentはLLMのテキスト出力を辞書型に直しているだけです。時々、LLMの出力がJSON単体だけでなく「以下にJSONを出力します```json \n 」のように始めてしまうことがあるので、json.loadsできないときはコードブロック内の文字列だけ抽出するようにしています。
スキーマの更新は単純で、スキーマ取得時と同じ辞書型にしてclient.update_tableを使うだけです。
これにて冒頭の画像のようにClaude 3の考えたコメントがGlue Data Catalogのテーブルスキーマに反映されました。
実務上は人がつけたコメントかLLMがつけたコメントか分かるように[Commented by Calude]のような注釈を入れたり、既についているコメントは上書きしないというルールが必要になってくると思います。
おわりに
今回は検証、というよりユースケース提案みたいな形になりましたが、ちょっと思いついたことAWSのサービスを使って試してみました。
今回は余力がなくてテーブル名、データソース、カラム名、スキーマしかLLMに渡していませんでしたが、生データや統計情報を渡すことで、より正確でより情報量の多いコメントを出力できるのではないかと思います。
また、カタログ作成をトリガーにしてLambde+Bedrockでコメントを自動設定したり、Agents for Amazon Bedrockなどを使って高度化もできそうな気がします。
データカタログに限らず、基盤のマネジメントタスクにLLMを活用していくユースケースは沢山あると思うので、また気になることはやっていきたいです。
蛇足ポエム
ポエム色が強くなりますが、LLMの活用が進むにつれ、あらゆる場所で自然文の重要度が増していると思います。
特にAgentやFunction Caliingといった、LLMが次のアクションを推論から導く仕組み(=ReAct)が充実してきているので、データカタログ・データマネジメントの重要性は拍車をかけて上がっているように思います。要はLLM様が見て用途や仕様を判断できる情報をデータ定義にも残しておけよ、ということです。もとより人間のために必要だったものですが、LLMのためにもなるようになってきました。
データカタログの作成や管理は人間がやれればそれが一番確実ですが、データマネジメントは規模に応じて非常に労力のいる仕事だと思うので、こういった仕組みでLLMに力を発揮させる土壌を整えていくことが重要かなと思っています。