はじめに
アニメ顔の検出器としてlbpcascade_animefaceが広く利用されています。

しかし、lbpcascade_animefaceは基本的に正面に近い姿勢の顔しか認識できないため、横向きなどの顔を認識することが困難です。
一方、(実写の)顔画像認識はDeepLearningにより高精度化が進んでいます。

顔画像認識技術の進化をアニメ顔検出にも取り入れたいところですが、それには大量のアノテーション(学習データ作成)が必要であり、すぐに実現することはできません。
そこで本記事では、Domain Adaptationという手法を利用して、アニメ画像に対するアノテーションなしで、高精度なアニメ顔検出を実現する方法を紹介します。
以下の画像が本記事の手法によるアニメ顔検出の結果の一例です。

本記事で利用したソースコードは以下のGitHubリポジトリで公開しています。
まだ整備できていないので簡単に利用することはできないかもですが、参考にしてみてください。
https://github.com/kanosawa/anime-face-faster-rcnn-da.pytorch
Domain Adaptation
まずはDomain Adaptationについて簡単に説明します。
本記事の手法はAdversarial Discriminative Domain Adaptationの論文を参考にしていますので、この論文の図を引用して説明します。
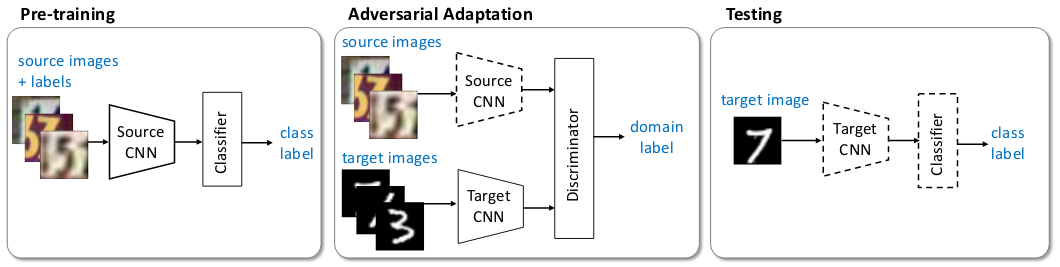
図中にsource imagesとtarget imagesという2種類の画像群が載っています。
source imagesはラベル付けされた画像群であり、target imagesはラベル付けされていない画像群です。
この論文の問題設定は、「source imagesで学習したClassifierをtarget imagesの識別に利用できるようにする」ことです。
以下で、図の3つの過程についてそれぞれ説明します。
Pre-trainingは一般的な識別器の学習過程と同じです。
Source CNNで画像(source images)の特徴を抽出し、Classifierにその特徴を入力して、識別結果を出力します。
Adversarial Adaptationでは、Source CNNの重みを固定し、Target CNNとDiscriminatorを学習します。
Target CNNはSouce CNN同様、画像(target images)の特徴を抽出します。
Discriminatorは入力された特徴が、source imagesのものかtarget imagesのものかを判定します。
この学習によって、target imagesをTarget CNNに入力して得られる特徴が、source imagesをSource CNNに入力して得られる特徴と近い分布を持つことになります。
Testingでは、Target CNNでtarget imageの特徴を抽出し、Classifierで識別結果を出力します。
Adversarial Adaptationによって、source imagesで学習したClassifierがtarget imagesに対しても有効になっており、target imagesにはラベル付けしていないにもかかわらず、target imagesの識別が可能になります。
以上がDomain Adaptationの説明です。
Domain Adaptationのアニメ顔検出への適用
続いて、Domain Adaptationをアニメ顔検出に適用します。
モデルアーキテクチャを以下の図に示します。
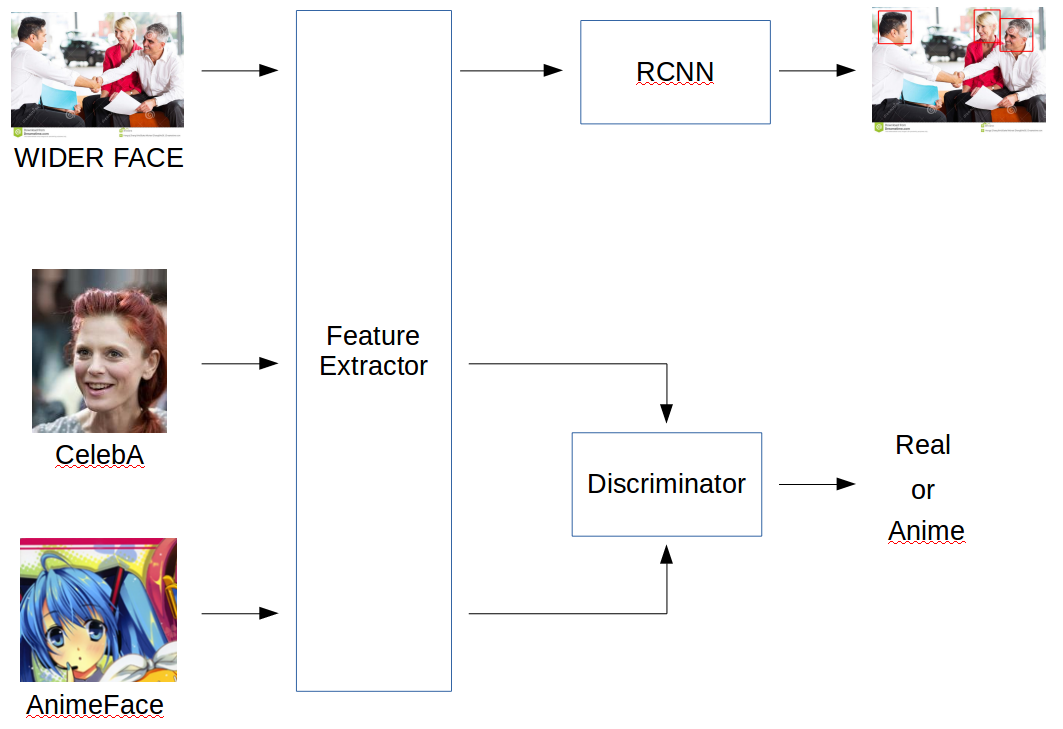
図がすべてを物語っている気がするので、データセットの説明だけしたいと思います。
WIDER FACEは顔認識(実写)用のデータセットです。
CelebAは実写顔画像を集めたデータセットです。
AnimeFace Characterはアニメ顔画像を集めたデータセットです。
なお、現状のアーキテクチャが最適かは微妙です。
WIDER FACEからも実写顔画像の特徴はとれるのでCelebAは不要じゃないかとか、いろいろ改良の余地はありそうです。
比較
lbpcascade_animefaceの認識結果と比較を行います。
左がlbpcascade_animeface、右が本記事の手法です。



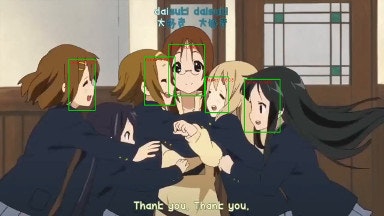


本記事の手法は横顔でもうまく認識できてますね。
ただ、じゃあlbpcascade_animefaceに取って代われるかというと、実はそんなことはなくて、正面顔はlbpcascade_animefaceの方がロバストに認識できますし、本記事の手法はアップの顔をほとんど認識できません。
Domain Adaptation全般に言えることだと思いますが、なにがなんでもアノテーション無しでやるんだということではなくて、手持ちのデータとか時間とかと相談しながら、既存の手法とうまく組み合わせて使うのが良さそうです。
おわりに
本記事ではDomain Adaptationの技術を使って、アノテーションなしでアニメ顔検出を行う方法を紹介しました。
引き続き、アーキテクチャやパラメータの調整、lbpcascade_animefaceとの組み合わせなどによって実用化を目指していきたいと思います。