はじめに
EC2において、AWS基盤側(仮想サーバーホスト、ハードウェア等)の問題が発生した際に、皆さんは対処してますか。
例え対処しなくても、AWS側が最終的には仮想サーバーホスト再振り分けをするみたいです。
ただ、サービスのダウンタイムを減らすためにも利用者側で先に対処するべきです。
今回のゴール
AWS基盤側の問題を検知し、利用者側で対処することです。
具体的には、あるCloudWatchのメトリクスをトリガー起点に、CloudWatchアラームのアクションを実行させることです。
作業手順
これから行う流れとしては、下記のとおりです。
「EC2構築」 → 「CloudWatchアラーム作成」 → 「確認」
入力あるいはクリック箇所は赤枠でできる限り示します。
EC2コンソールから、Launch instances選択
Nameを入力
KeyPairは必要に応じて選択

Network設定も必要に応じて設定
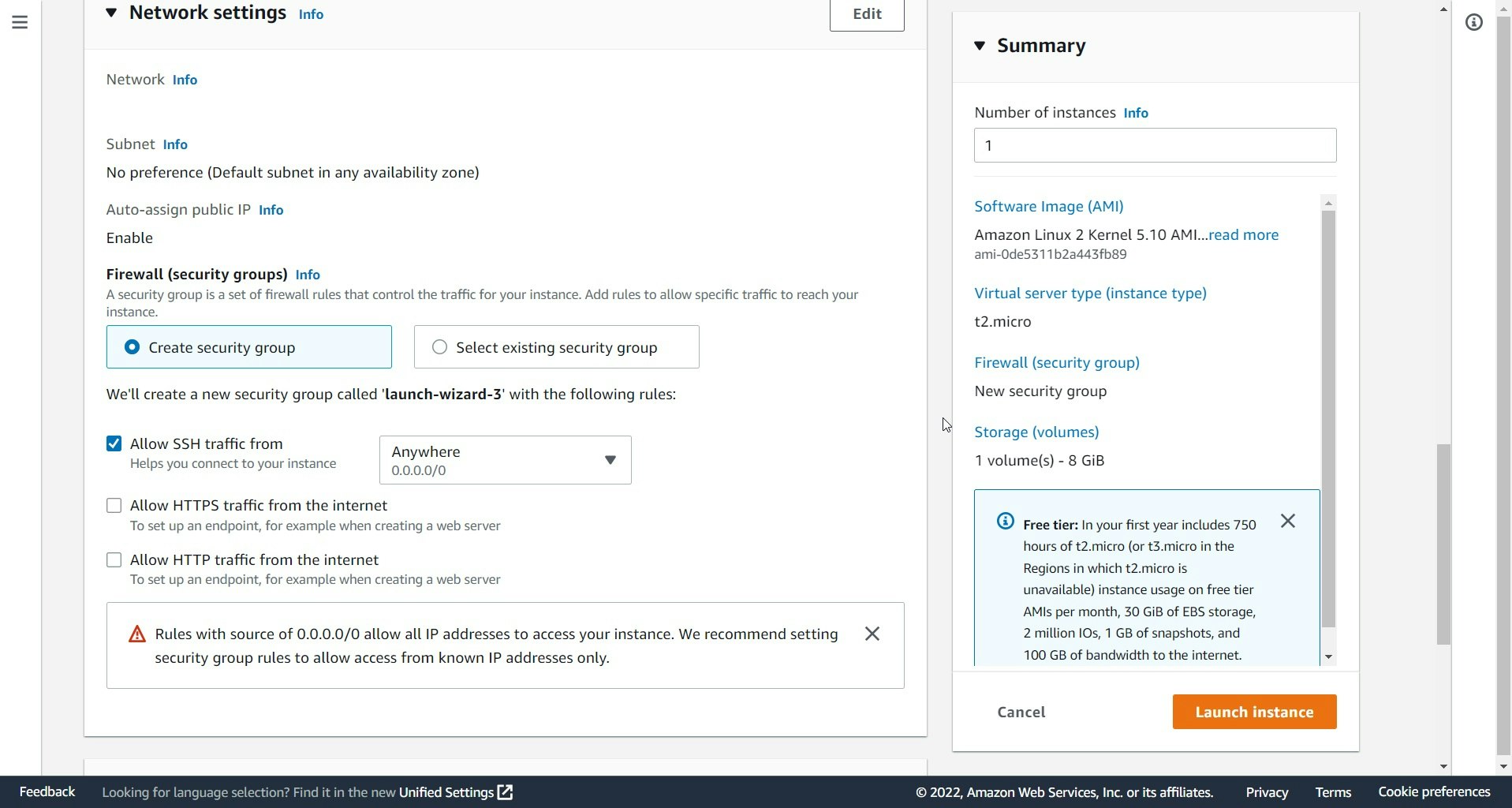
後は、そのままデフォルトでLaunch instance選択
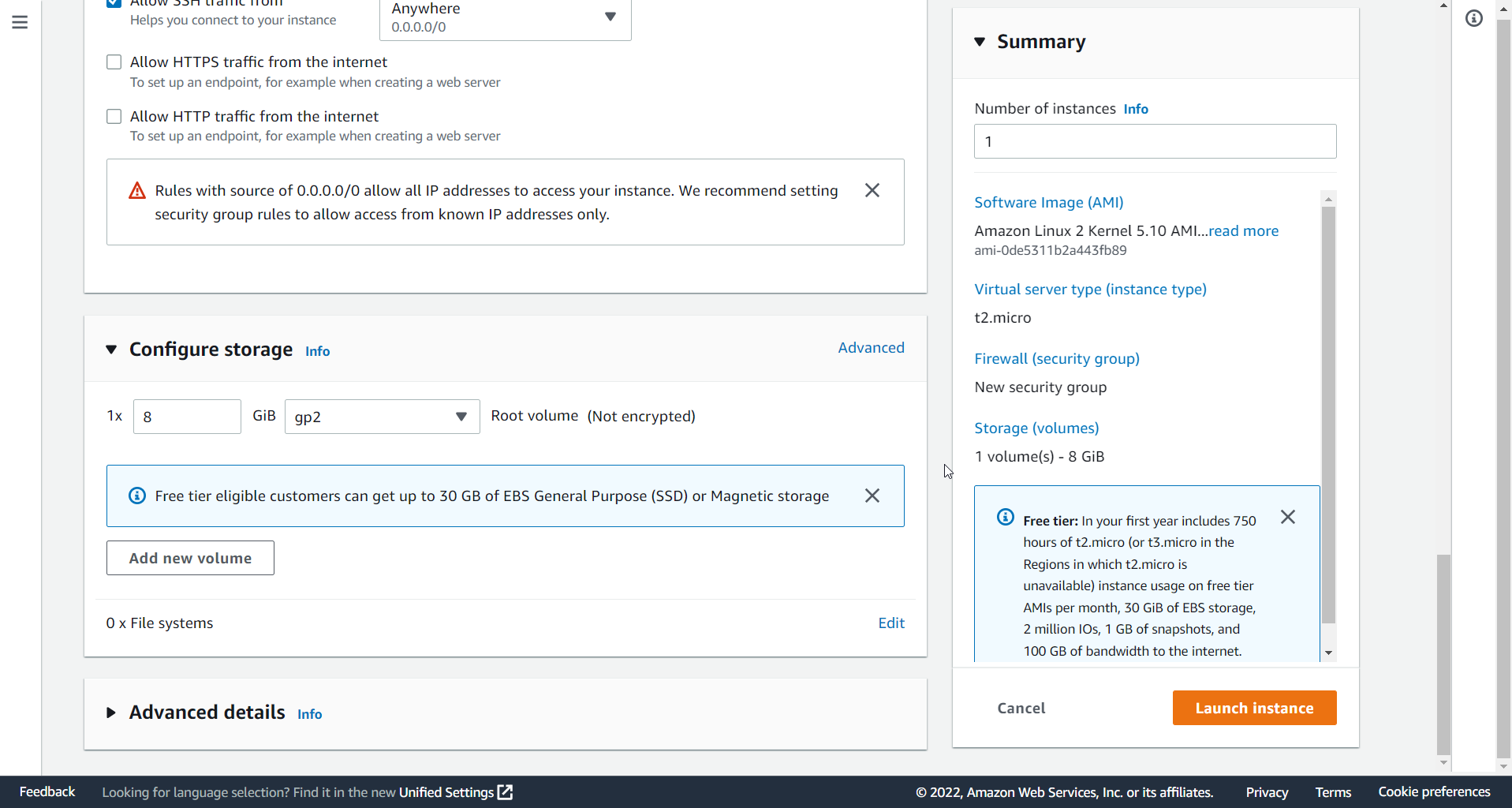
Pending
Running
ここまでがEC2構築です。次からは、CloudWatchアラーム作成方法です。
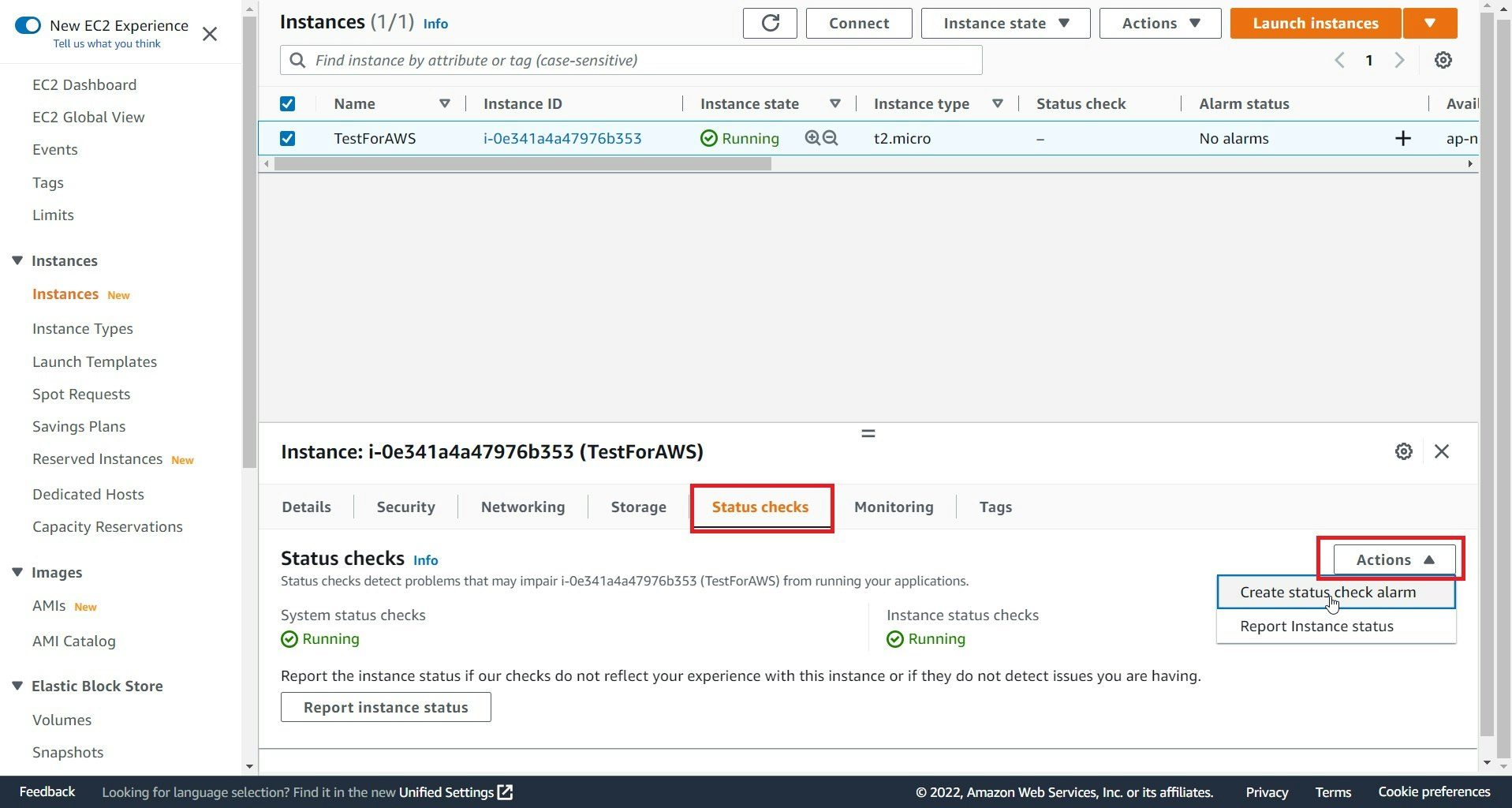
該当EC2選択 → Status checks選択 → Actions選択 → Create status check alarm選択
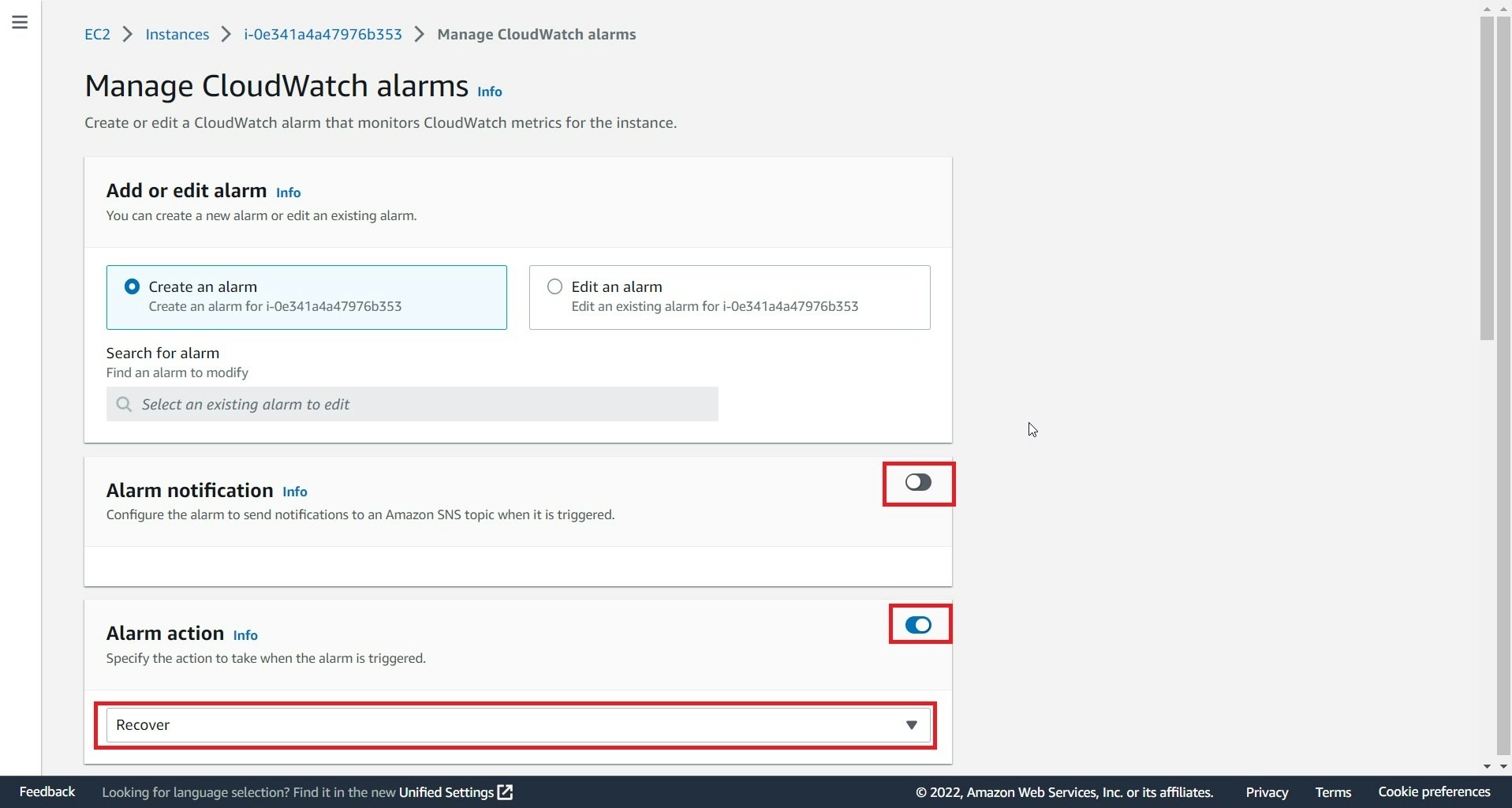
Alarm notificationはオフ(通知が必要な場合は設定おすすめ) → Alarm actionはオン → Recoverを選択
Alarm thresholds項目はStatus check failed:systemを選択
(上記のメトリクスがAWS基盤側の問題発生したもの)
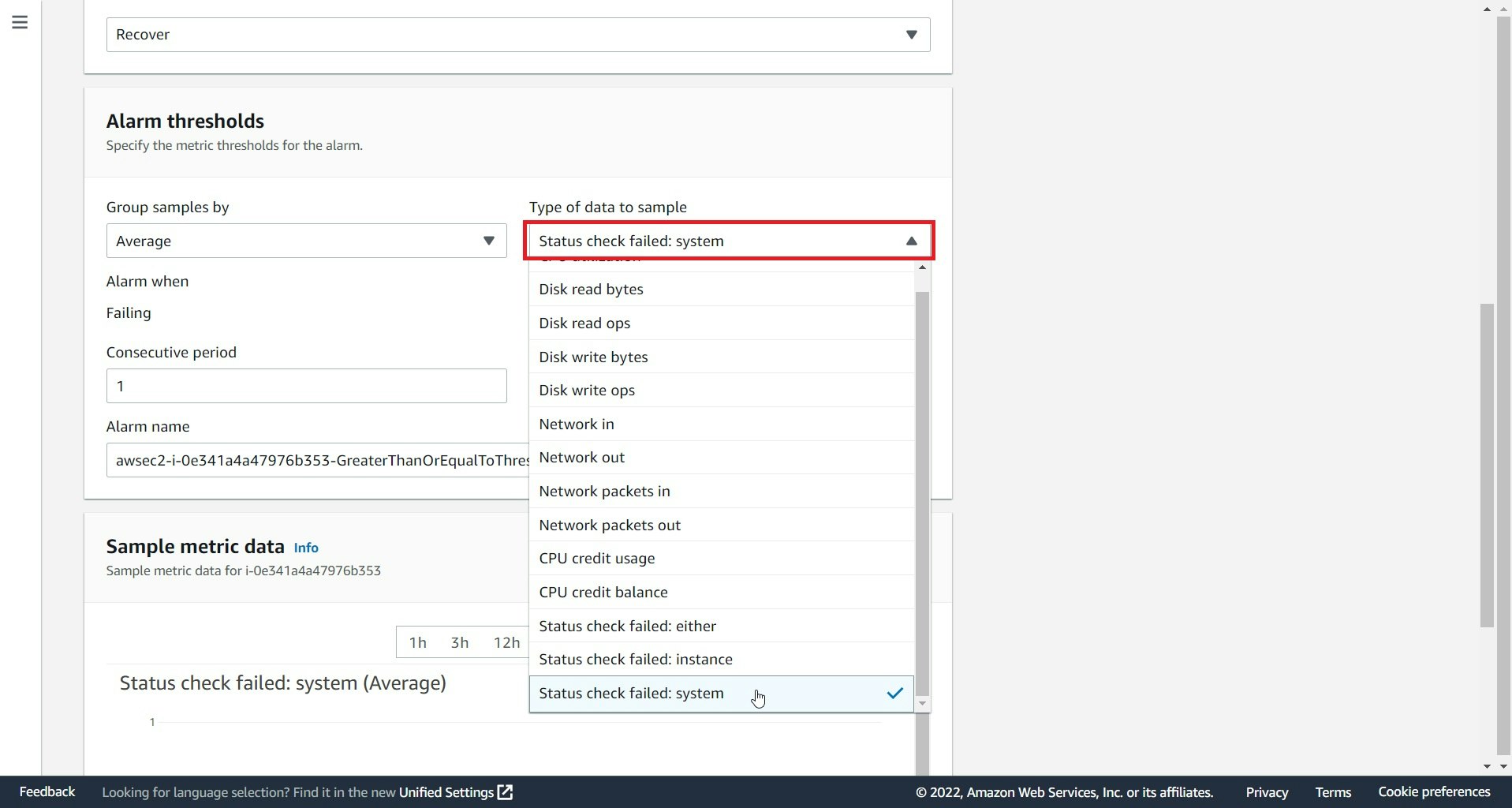
Create選択
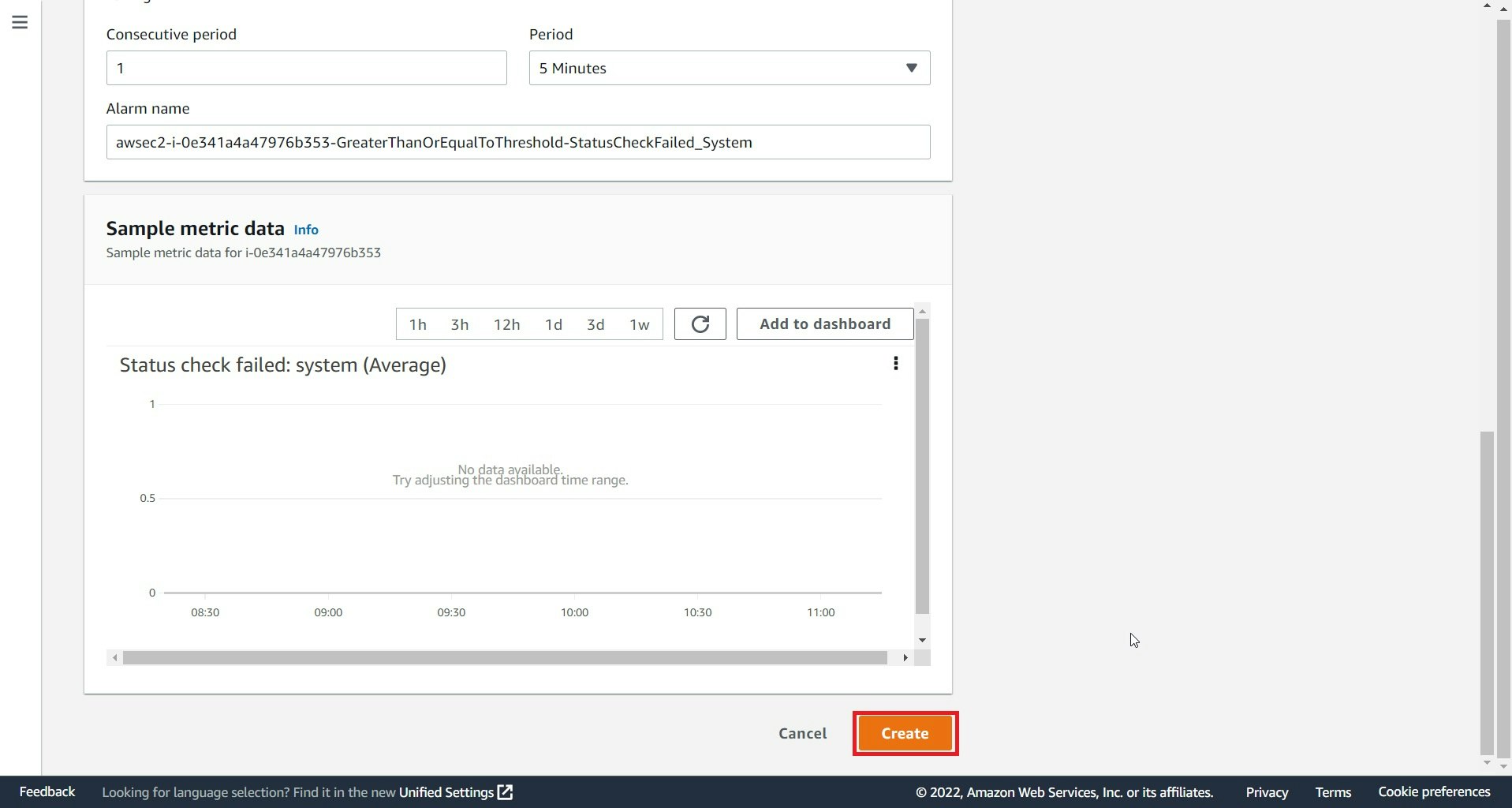
CloudWatchコンソールより、該当アラーム確認
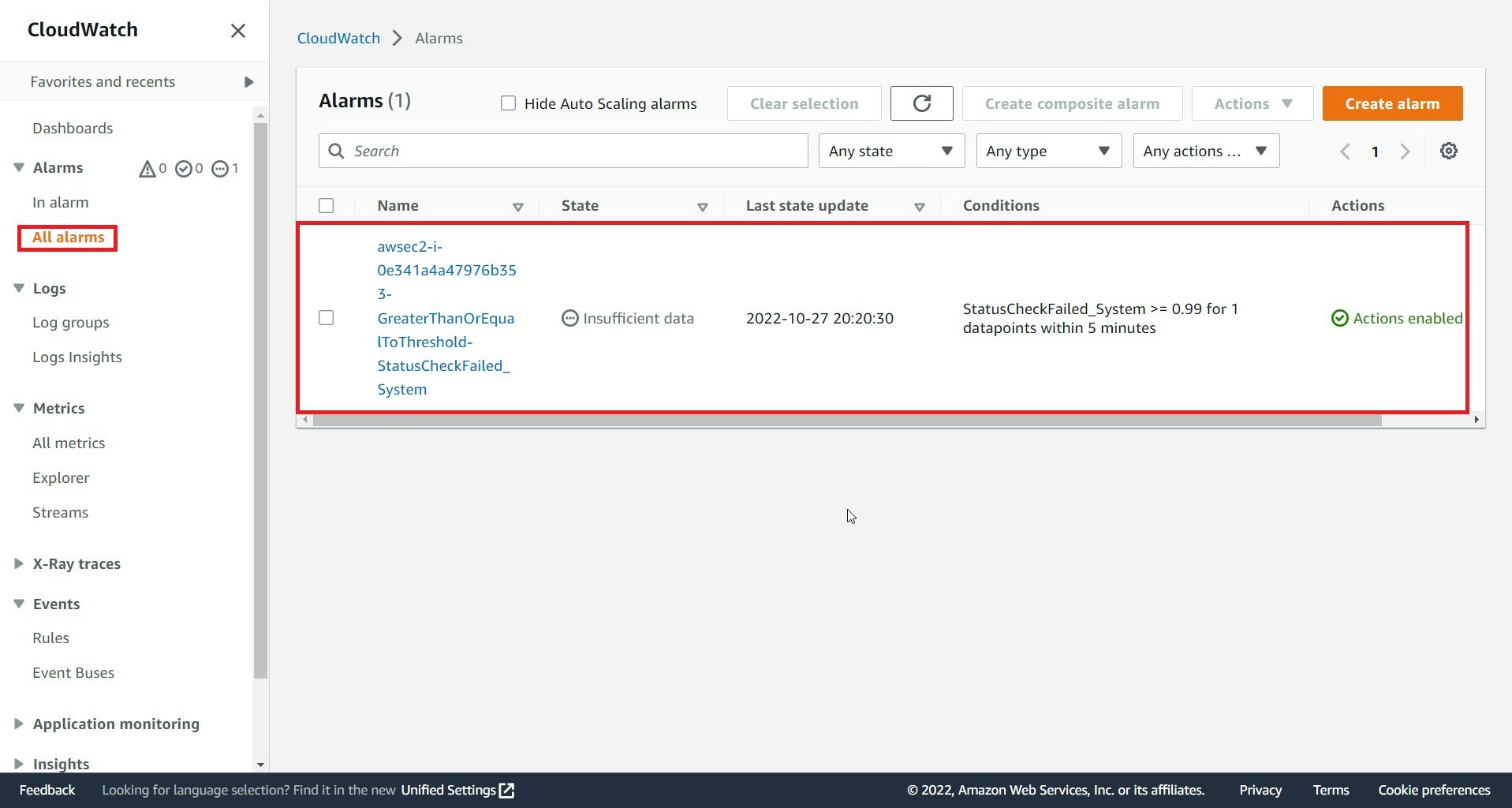
ここまでがCloudWatchアラーム作成方法です。次からは、確認です。
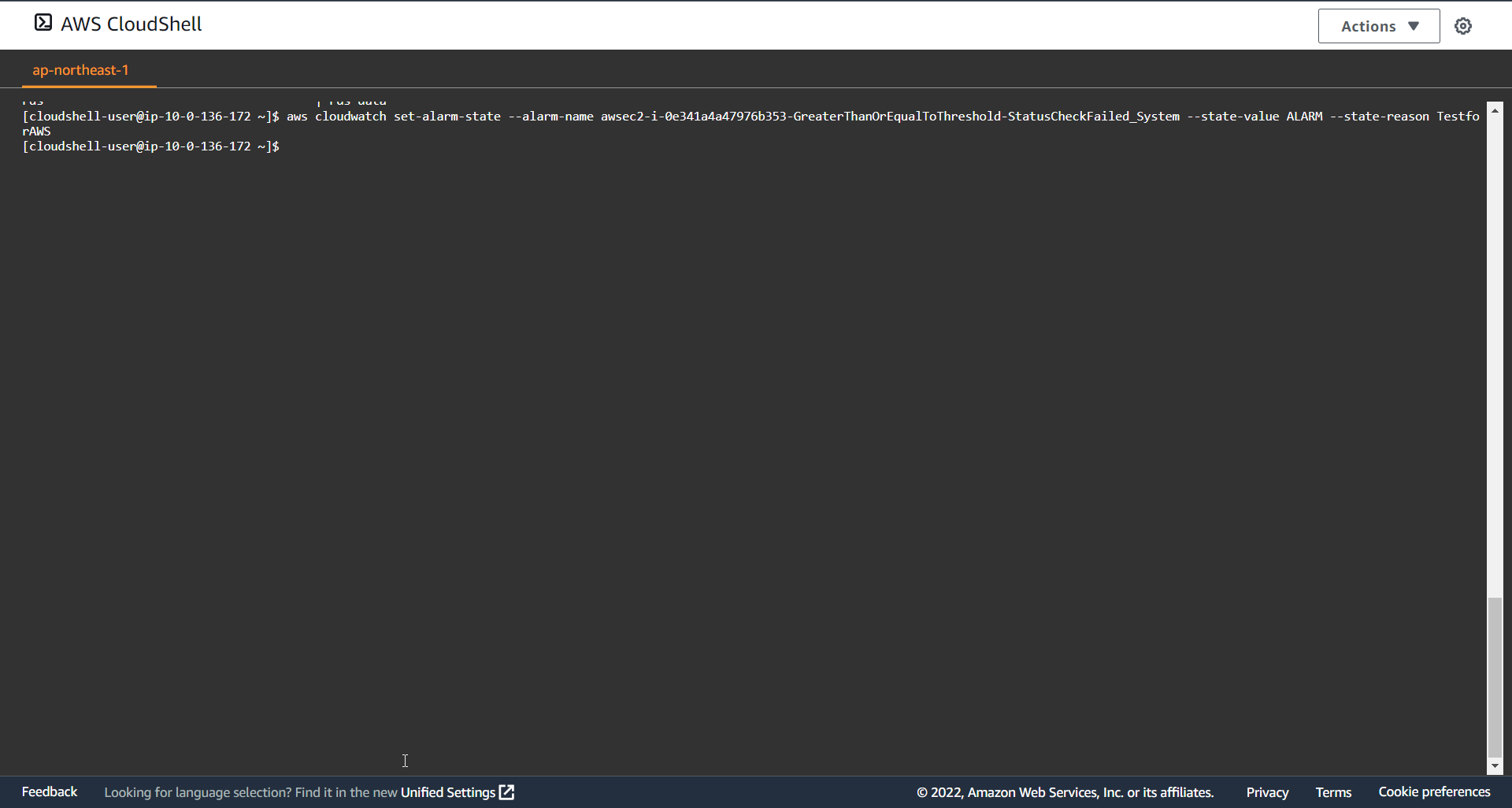
下記コマンドで、該当アラーム状態を「ALARM」状態
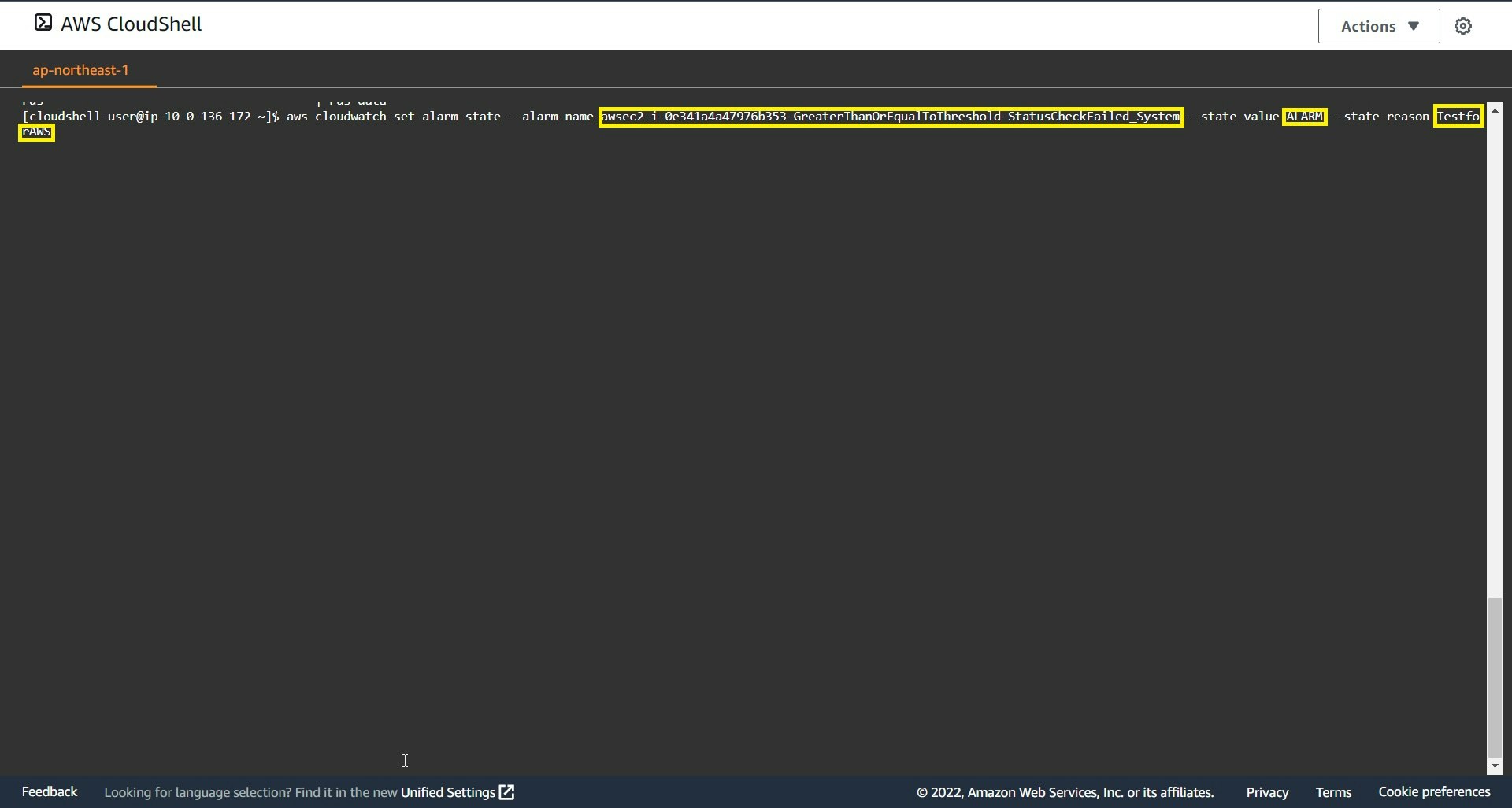
aws cloudwatch set-alarm-state --alarm-name awsec2-i-0e341a4a47976b353-GreaterThanOrEqualToThreshold-StatusCheckFailed_System --state-value ALARM --state-reason TestforAWS
コマンド実行後
EC2コンソールより、該当EC2のAlarm statusがアラーム確認

CloudWatchコンソールより、該当アラームを確認
(ALARM状態表示後、OK状態)

Historyを見ると、Type列にActionが実行されていることが確認

まとめ
EC2において、AWS基盤側の問題発生した際に対処する方法を示しました。まだ、対処していない方はぜひ検討してみてはいかがでしょうか。