その1:大量データの VLOOKUP 高速化
TL;DR
検索範囲をソートして、近似値検索する
背景
百万件弱のバッチデータを Excel で付き合わせる必要が出てきた。
詳細は以下の通り。
条件:
- 今回のデータはデータセット内で一意なキー情報のみ
- とある回のデータセットには、別の回のデータセットに含まれるデータが大部分(80%以上)含まれる
やりたい事:
- 2つの日のデータセット間の差分を検出
- 増加分/減少分のキー情報を特定
COUNTIF 関数や VLOOKUP 関数の「完全一致」だと時間がかかる
COUNTIF 関数を使って 0 or 1 で判断しようとしたら、数十万行分の「Ctrl + d」で、CPU使用率が振り切れてフリーズ。。。
計算量としては、データ量をn件とすると、検索範囲にある全件との比較を1レコード目からnレコード目まで実行するので、 O(n^2) となる。
VLOOKUP でも計算に時間がかかり、操作が非常に重くなった。
線形探索では、一致する値が見つかるまで一件ずつ比較するので、データ量に比例して計算量が増加する。
平均して全体の半分でヒットすると仮定しても、計算量は O(n) となる。
VLOOKUP 関数の「近似値検索」を使う
普段おまじない的に「FALSE」を指定していた VLOOKUP 関数の第4引数:[検索方法]
ザックリ言うと、ここを「TRUE」にすると、インデックス検索してくれるイメージ。
そのための前提条件として、検索範囲となるデータをソートしておく必要がある。
すると、得られる結果は、完全一致したものか、インデックスによるとこの辺にあるはず!というところのものを返してくれる。
原理的には、検索対象がソートされているので、二分探索(木)が使える。
そのため、掲載量は O(log n) となり、データ量が増えても計算量はほとんど増えない。
でも、近似値を使いたいユースケースなどほぼなく、だからこそ今まで使っていなかった。
そこで、完全一致と同様に使うには、以下の2段階にすればよい。
- 近似値検索で、検索範囲のキー情報を返す。
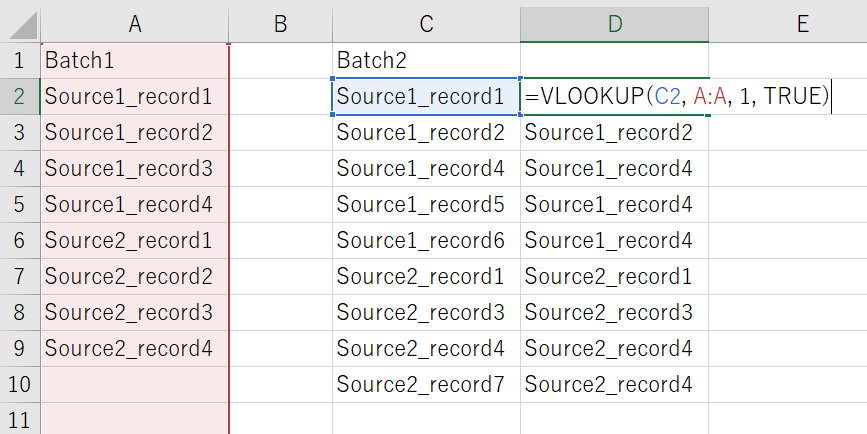
- 関数で返された値と関数に渡した検査値(キー情報)が同一かどうか比較し、同じであれば完全一致
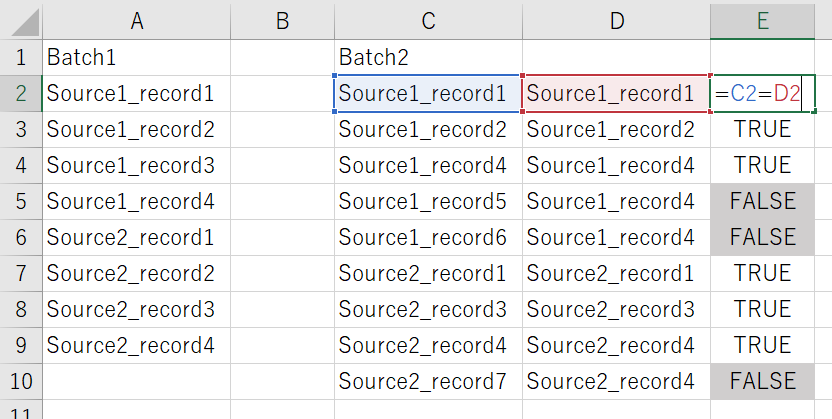
※ この考え方は他の関数(MATCHなど)にも応用できる。
おまけ(参考サイト)
計算量について:https://archives.aotsuki.org/excel-functions-optimize-lookups/
応用編(並べ替えの注意点なども):https://excel-ubara.com/excel3/EXCEL019.html