この記事はServerless Advent Calendar 2018の7日目の記事です。
あらすじ
S3に出力したJSONファイルをもとにDynamoDBのデータをバッチ的に更新する仕組みをサーバレスで作ったので、その際に考えた事などを共有します。
作った構成
S3にデータが置かれた後はS3 -> Lambda -> SQS -> Lambda -> DynamoDBと処理が遷移します。
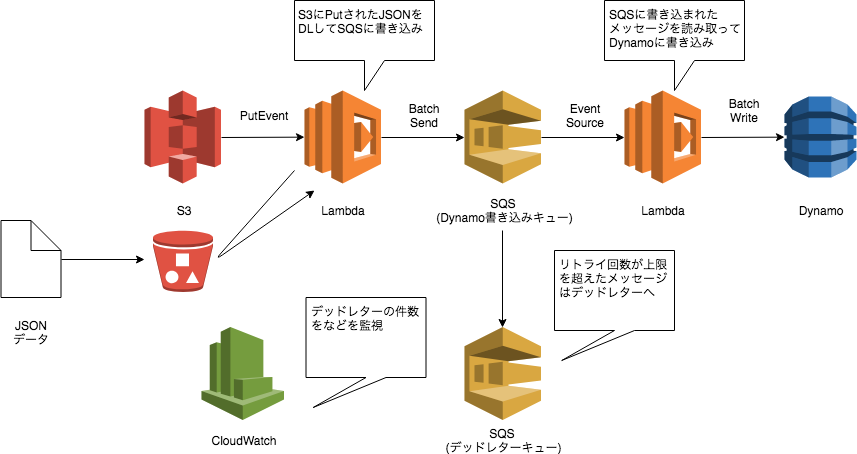
- 書き込み処理は上書きのみで処置を冪等にしている
- 書き込み順序を特に気にしない
ことを前提とした構成です。
考慮事項
この構成を取る上で以下のような考慮事項がありました。
- S3に置かれるファイルのサイズが不定
- DynamoDBの書き込みスループットに制限がある
- オートスケールするけど迅速にスケールしない
- Lambdaにはタイムアウト時間がある
つまり単純にLambdaでS3のデータを引っ張ってDynamoDBに書き込もうとした場合、タイムアウトが発生してしまう可能性が高くなってしまいます。
そこでS3からDynamoDBに直接書き込む構成でなく、一度SQSを経由することで書き込むデータの粒度を細かくする構成としました。
この構成の利点
リトライが簡単になる
SQSをLambdaのイベントソースとした場合、Lambdaは処理が正常に終了するとSQSからメッセージを削除して、正常に終了しなければメッセージを消さない、といった動きをします。
そのためDynamoDBへの書き込み時にタイムアウト等のなんらかのエラーが発生した場合でも、何もしなくても可視性タイムアウト時間が過ぎた後に再度Lambdaによって取り込みされてリトライされます。
もし、不正なフォーマットなどメッセージ自体に問題がある場合は、再送回数がRedriveポリシーのmaxReceiveCountを超えた後にDeadLetterキューに移されます。DeadLetterのメッセージ件数をCloudWatchで監視することで書き込みの失敗を検知することが可能です。
このようにリトライ周りの処理を完全にSQSとLambdaの機構自体に任せることでリトライ処理をLambdaのプログラム側で書かなくても済むようになります。
おわりに
以上、DynamoDBへのバッチ書き込みをサーバレスで実現した構成の紹介でした。
LambdaのイベントソースにSQSを指定するとメッセージのハンドリングをAWS側でやってくれるので楽ですね。