はじめに
MLOpsを構成する機能要素としてモニタリングがあり、そこで活用できるOSSとしてEvidently AIがあります。v0.2.0以降のリリースで機能の拡充があったので、改めてEvidently AIの機能を整理してみました。
Evidently AIの概要
Evidently AI では、current データおよびreference データの dataframe と、Columnmapping をモジュールに渡すことで、2つのデータセットやモデルパフォーマンスの比較を行うことができます。これにより、モデル開発時であれば、データの特徴を調査したり、作成した 2つのモデルの性能比較に利用できます。モデル運用時であれば、データやモデルパフォーマンスがモデル開発時に比べてドリフトや劣化していないかを監視・分析するのに利用できます。
- current データ
現時点でのデータセットです。機械学習のシーンでは、推論時に渡されたデータや推論結果になります。 - reference データ
currentデータと比較対象するためのデータセットです。機械学習のシーンでは、学習時に使われたデータやその時点での推論結果になります。 - Columnmapping
どのカラムが目的変数か、各カラムが数値型変数なのかカテゴリカル変数なのか、などの情報です。
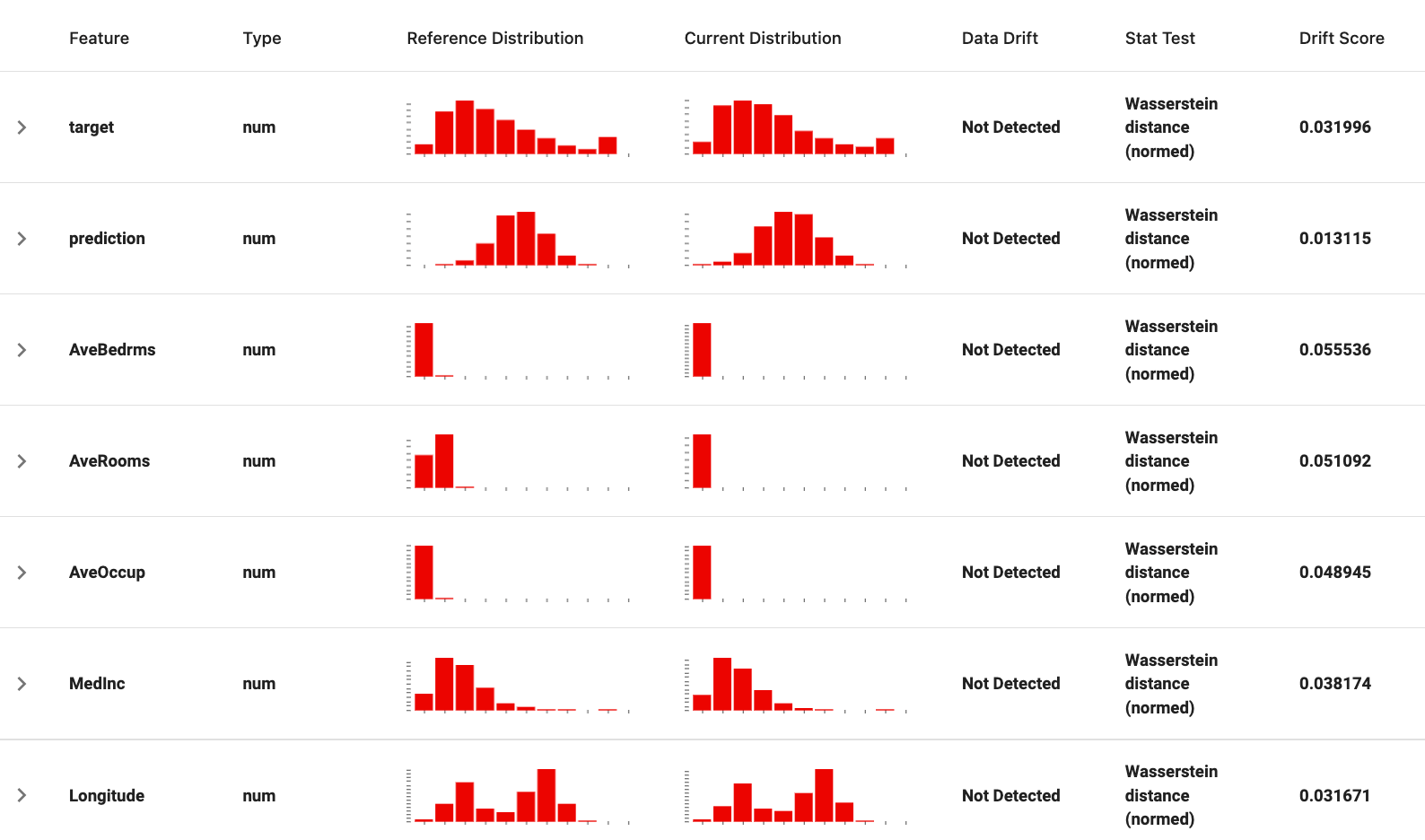
データドリフトやモデルの劣化を算出してその結果を視覚的に出力する機能を Evidently AI は提供してくれています。
補足
- データ比較について
レポート・テストの内容によっては、比較なしで、1つのデータだけを渡すことも可能です。 - Columnmapping について
Evidently AI 側で、デフォルトでデータ情報をある程度は自動識別してくれるので、Columnmapping を省略することもできます。明示的に設定したい場合は Columnmapping を使用します。
レポート機能とテスト機能
Evidently AI には大きく分けて、レポートとテストの2つの機能があります。v0.1まではレポートのみでしたが、v0.2になってからテストも追加されました。
レポート
レポートは視覚化に焦点を当てており、主に Jupyter notebook のセルのアウトプットや html 形式のファイルを出力することで、デバッグやアドホック分析など綿密な調査・監視に使用します。
テスト
チェックを自動的に実行し、意味のある問題にのみ対応する場合はテストを用います。テストの場合、事前に設定した閾値を超えてしまっていないか判定をします。
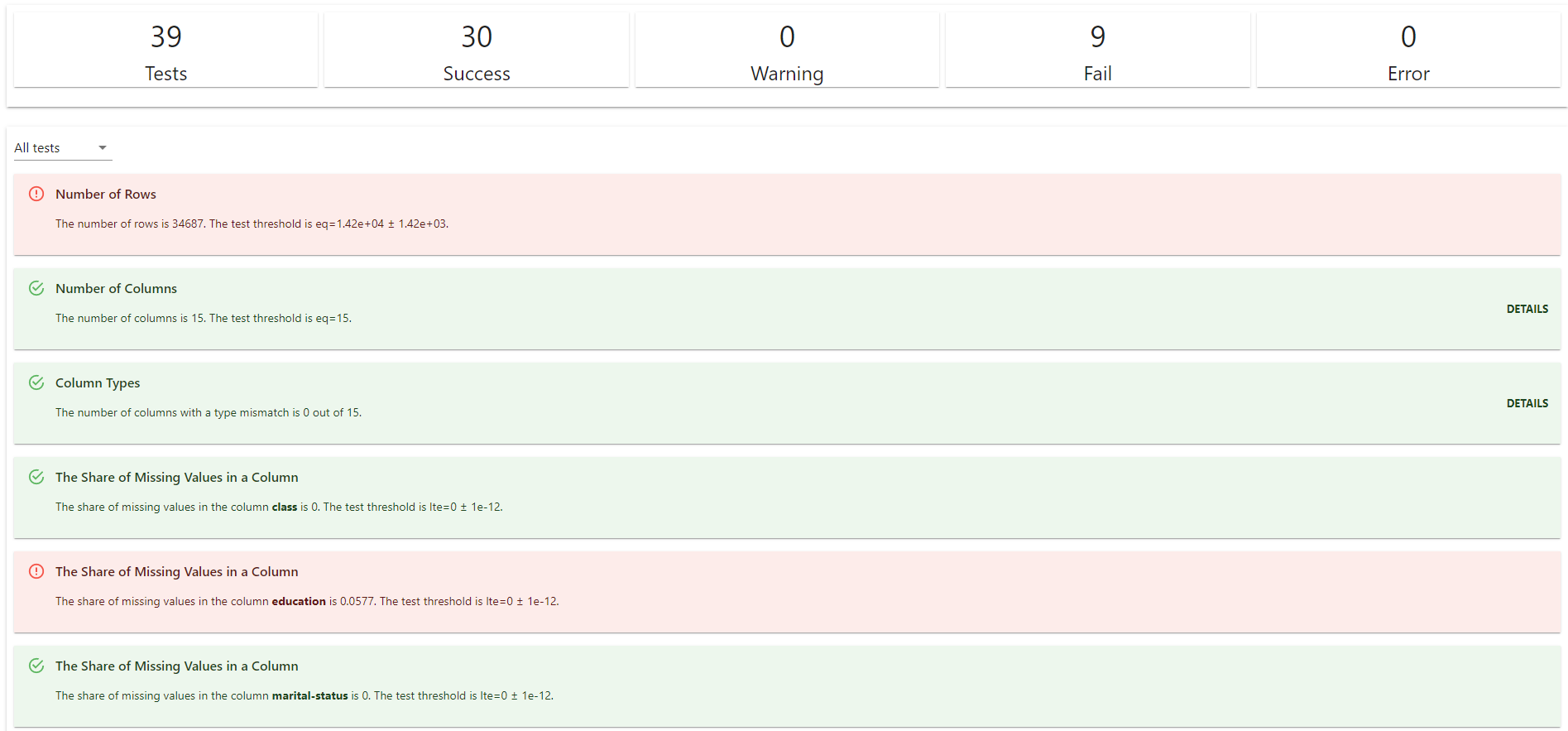
テストの出力形式は以下のような python の dict 型や json 形式の文字列で、SUCCESS または FAIL 判定を返すため、パイプラインのような自動化において、その判定結果を組み込むことができます。
{'tests': [{'name': 'Number of Rows',
'description': 'The number of rows is 34687. The test threshold is eq=1.42e+04 ± 1.42e+03.',
'status': 'FAIL',
'group': 'data_integrity',
'parameters': {'condition': {'eq': 14155 ± 1415.5},
'number_of_rows': 34687}},
{'name': 'Number of Columns',
'description': 'The number of columns is 15. The test threshold is eq=15.',
'status': 'SUCCESS',
'group': 'data_integrity',
'parameters': {'condition': {'eq': 15}, 'number_of_columns': 15}},
```以下略```
name がテストの内容で、status が判定結果を表します。
また、レポートのように Jupyter notebook のセルのアウトプットや html 形式のファイルを出力でき、下図のようにどのテストが成功したかを視覚的にわかりやすく表示することもできます。
レポートとテストのプリセット
レポートとテストには、それぞれ数十種類のコンポーネント(モジュール)が用意されており、ユーザーはそれらを自由に組み合わせて使用します。
また、Evidently AI 側で、目的に合わせていくつかのコンポーネントをパッケージングしたプリセットを用意してくれています。
レポートのプリセット
レポート出力について
Jupyter notebook のセルのアウトプットに表示するには拡張機能が必要です。
DataQualityPreset
データ品質に関するコンポーネントのプリセットです。対象となるデータセットの基本的な統計量や欠損値の状態、列間の相関などを算出してくれます。主な用途としては以下が挙げられます。
- モデルを開発する前のデータの大まかな特徴把握
- モデル運用時におけるモデルパフォーマンス低下の原因調査
- モデル運用時におけるデータ仕様監視
| コンポーネント | 概要 |
|---|---|
| DatasetSummaryMetric | データセットに関する様々な統計量をまとめた表が生成されます。 |
| ColumnSummaryMetric | 列ごとに統計量をまとめた表やグラフが生成されます。 |
| DatasetMissingValuesMetric | データセット全体での欠損値の数・割合、および、列ごとの欠損値の数を確認できます。 |
| DatasetCorrelationsMetric | 列間の相関のヒートマップが生成されます。 |
DataDriftPreset
モデル開発に使用したデータに対して、運用していく中でデータの性質が変化(ドリフト)することがあります。
そこで、DataDriftPreset を利用してデータドリフトが起こっていないかを監視、
および、ドリフトが起こった場合、どの特徴量でどのようにドリフトしたかを調査します。
| コンポーネント | 概要 |
|---|---|
| DatasetDriftMetric | ドリフトした特徴量の数と割合を確認できます。 また、割合に対する閾値(デフォルトでは 50%)を基に、データセット全体に対するドリフト判定結果を確認できます。 |
| DataDriftTable | データセットの各特徴量に対してのドリフト判定結果を確認できます。 また、詳細を展開することで分布図を確認できます。 数値型の特徴量であれば、さらに current データに対する散布図を確認できます。 |
TargetDriftPreset
モデル開発に使用したデータに対して、運用していく中でデータの性質が変化(ドリフト)することがあります。そこで、TargetDriftPreset では、目的変数と予測値に焦点を当て、データドリフトが起こっていないかを監視、および、ドリフトが起こった場合、目的変数/予測値と他の特徴量との相関などに注目して、どのようにドリフトしたかを調査するのに利用できます。
| コンポーネント | 概要 |
|---|---|
| ColumnDriftMetric | 指定した列のデータドリフトの判定、および、分布図を生成します。 数値変数の場合は、さらに散布図も生成します。 |
| ColumnCorrelationsMetric | 指定した列とデータセット内の他の列との間の相関図を生成します。 ただし、指定した列が数値変数の場合は他の数値変数との相関、カテゴリカル変数の場合は他のカテゴリカル変数との相関のみです。 |
| TargetByFeaturesTable | 目的変数、あるいは、予測値がデータセット内の他の特徴量に対してどのように振舞うかを表すグラフを、特徴量ごとに生成し、一覧表として表示します。 目的変数/予測値が数値変数の場合は、縦軸を目的変数/予測値とした散布図が生成されます。 目的変数/予測値がカテゴリカル変数の場合は、カテゴリカル値ごとに分布図が生成されます。 |
RegressionPreset
回帰モデルに対する各種レポートを生成します。主な用途としては以下が挙げられます。
- 開発したモデルのパフォーマンスの確認
- 再学習前後でのモデルパフォーマンス比較
- モデル運用中のモデルパフォーマンスの監視
| コンポーネント | 概要 |
|---|---|
| RegressionQualityMetric | モデルパフォーマンスとして、平均誤差 (ME)、平均絶対誤差 (MAE)、平均絶対パーセント誤差 (MAPE) の表を生成します。 |
| RegressionPredictedVsActualScatter | 予測値 vs 実測値の散布図を生成します。 |
| RegressionPredictedVsActualPlot | 予測値と実測値の折れ線グラフを生成します。 |
| RegressionErrorPlot | モデル誤差 (予測値 - 実測値) の折れ線グラフを生成します。 |
| RegressionAbsPercentageErrorPlot | 絶対パーセント誤差(絶対誤差 / 実測値 × 100)の折れ線グラフを生成します。 |
| RegressionErrorDistribution | モデル誤差の分布図を生成します。 |
| RegressionErrorNormality | モデル誤差に対する正規Q-Qプロットを生成します。 |
| RegressionTopErrorMetric | 誤差の大きさ順に対し、上位 5% (Overestimation)、中間 90% (Majority)、下位 5% (Underestimation) の 3つにグループ分けをし、グループごとの ME の結果を表にまとめ、さらに、予測値 vs 実測値の散布図を生成します。 |
| RegressionErrorBiasTable | RegressionTopErrorMetric で分けたグループごとに、各特徴量におけるモデルパフォーマンス結果を纏めます。モデルパフォーマンス低下の要因である特徴量を調査するのに利用します。 |
ClassificationPreset
分類モデルに対する各種レポートを生成します。
分類モデルには、予測値が 0, 1, ・・・ のように明確にどのクラスに分類されるかを返す通常の分類モデルと、0 に分類される確率○○%、1 に分類される確率△△%、・・・ のように各クラスに分類される確率を返す確率的分類モデルがあります。そのため、ClassificationPreset には確率的分類モデルでしか生成されないコンポーネントがありますし、各コンポーネントでも確率的分類モデルでしか表示されない項目があります。
| コンポーネント | 概要 |
|---|---|
| ClassificationQualityMetric | モデルパフォーマンスとして、Accuracy, Precision, Recall, F1スコア、および、確率的分類の場合は ROC AUC, LogLoss の表を生成します。 |
| ClassificationClassBalance | 各クラスについてのヒストグラムを生成します。 |
| ClassificationConfusionMatrix | 混同行列を表示します。 |
| ClassificationQualityByClass | F1スコア, recall, precision を視覚的に表示します。 |
| ClassificationClassSeparationPlot | クラスごとに予測確率をプロットした散布図を表示します。 このコンポーネントは確率的分類の場合のみ表示されます。 |
| ClassificationRocCurve | ROC曲線を生成します。 このコンポーネントは確率的分類の場合のみ表示されます。 |
| ClassificationPRCurve | Precision-Recall曲線(PR曲線)を生成します。 このコンポーネントは確率的分類の場合のみ表示されます。 |
| ClassificationPRTable | Precision-Recall表を生成します。 このコンポーネントは確率的分類の場合のみ表示されます。 |
| ClassificationQualityByFeatureTable | 特徴量ごとの分類モデルパフォーマンスに関するグラフを生成し、表形式でまとめます。 |
TextOverviewPreset
テキストデータに関する各種レポートを生成し、主に、テキスト長 (Text Length)、辞書未登録単語率 (OOV %, OOV: out of vocabulary)、非英字率 (Non Letter Charater %) の 3つの観点でさまざまなメトリックが計算されます。
| コンポーネント | 概要 |
|---|---|
| ColumnSummaryMetric | 列ごとに統計量をまとめた表やグラフが生成されます。 ※DataQualityPresetのColumnSummaryMetricと同様 |
| TextDescriptorsDistribution | テキスト長、辞書未登録単語率、非英字率に対する分布図を生成します。 |
| TextDescriptorsCorrelation | テキスト長、辞書未登録単語率、非英字率に対する他の数値変数との相関を表示します。 相関の算出方法は、ピアソン、スピアマン、ケンドールの 3種類です。 |
| ColumnDriftMetric | TargetDriftPreset の ColumnDriftMetric において、指定列をテキストデータにしたものです。 |
| TextDescriptorsDriftMetric | テキスト長、辞書未登録単語率、非英字率に対するドリフトの判定、および、散布図と分布図を生成します。 |
テストのプリセット
テストの閾値について
テストの閾値は、特に指定しなければ Evidently AI のデフォルトのものが使用されますが、ユーザーによってカスタマイズすることもできます。詳しくはEvidently AI の公式ドキュメントで確認できます。
DataStabilityTestPreset
主な用途としては以下が挙げられます。
- モデル運用時におけるデータ仕様監視(業務システム改修などで、部署や専門性の違いからデータ仕様が予告なく変更されてしまうことがあり得ます)
- モデル運用時におけるデータドリフトの簡易的な監視(より詳細な監視には DataQualityTestPreset や DataDriftTestPreset を利用します。)
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestNumberOfRows | Current データの行数に過不足がないかをテストします。 | ・Reference データに対して行数が +/-10% 以内 ・Reference がない場合、30行より多い |
| TestNumberOfColumns | Current データの列数に過不足がないかをテストします。 | ・Reference データと列数が等しい ・Reference がない場合、1行以上ある |
| TestColumnsType | Current データの各列のデータ型に変更がないかテストします。 | reference データとすべての列でデータ型が同じ場合 |
| TestColumnShareOfMissingValues | Current データの欠損データ数の割合が増えすぎていないか、列ごとにテストをします。 | ・Reference データの欠損データ数の割合に対して 10% を超えない。 ・Reference がない場合、1つも欠損値がない。 |
| TestShareOfOutRangeValues | Current データの数値型の変数値について、reference データの最大・最小値の範囲内に収まっているか、列ごとにテストします。 | 全てのデータが範囲内に収まっている場合 |
| TestShareOfOutListValues | Current データのカテゴリカル変数の値について、未知の変数値がないか、列ごとにテストします。 | reference データのカテゴリカル変数値のリストと比較して、未知のものがない |
| TestMeanInNSigmas | Current データの数値型の変数の平均値が、 reference データの標準偏差を基に定義された範囲内にあるか、列ごとにテストします。 | reference データの平均値から 2標準偏差以内 |
DataQualityTestPreset
主な用途としては以下が挙げられます。
- モデル運用時におけるモデルパフォーマンスに影響を与えるデータ品質(≒データの統計的性質)の監視
- モデル運用時におけるデータドリフト監視
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestColumnShareOfMissingValues | DataStabilityTestPreset の TestColumnShareOfMissingValues と同一 | - |
| TestMostCommonValueShare | Current データの最頻値のデータ数の割合が大幅に変化していないか、列ごとにテストします。 | ・Reference データに対して、最頻値のデータ数の割合が +/-10% 以内に収まっている ・Reference がない場合、最頻値のデータ数の割合が 80% 未満 |
| TestNumberOfConstantColumns | Current データに定数列が存在しないかテストします。 | ・Reference データよりも、定数列の列数が増えていない。 ・Reference がない場合、一つも定数列が存在しない。 |
| TestNumberOfDuplicatedColumns | Current データに重複列が存在しないかテストします。 | ・Reference データよりも、重複列の列数が増えていない。 ・Reference がない場合、一つも重複列が存在しない。 |
| TestNumberOfDuplicatedRows | Current データに重複行が存在しないかテストします。 | ・Reference データに対して、重複行の行数が +/-10% 以内に収まっている。 ・Reference がない場合、一つも重複行が存在しない。 |
| TestHighlyCorrelatedColumns | Current データの特徴量間の最大相関強度が強すぎないかテストします。 | ・Reference データの最大相関強度に対して、+10% 未満の変化である。 ・Reference がない場合、全ての相関が 0.9 未満である。 |
DataDriftTestPreset
モデル運用時におけるデータドリフト監視の用途で利用します。
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestShareOfDriftedColumns | Current データの各列の分布のドリフトについて、ドリフトした列数の割合が高すぎないかテストします。 | ドリフトした列数の割合が 1/3 以下 |
| TestColumnDrift | Current データの指定した列について、ドリフトしていないかテストします。 | 指定した列でドリフトが検出されない |
RegressionTestPreset
モデル運用時における回帰モデルのパフォーマンスの監視で利用します。
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestValueMeanError | Current データについて、平均誤差 (ME)がゼロに近いかどうかをテストします。 | ME が 誤差の標準偏差の 10% 以内 |
| TestValueMAE | Current データについて、平均絶対誤差 (MAE) が適切かテストします。 | ・Reference データに対して、MAE が +/-10% 以内に収まっている。 ・Reference がない場合、ダミーモデルの MAE 以下。(ダミーモデルは目的変数の中央値を予測するモデル。) |
| TestValueRMSE | Current データについて、二乗平均平方根誤差 (RMSE) が適切かテストします。 | ・Reference データに対して、RMSE が +/-10% 以内に収まっている。 ・Reference がない場合、ダミーモデルの RMSE 以下。 |
| TestValueMAPE | Current データについて、平均絶対パーセント誤差 (MAPE) が適切かテストします。 | ・Reference データに対して、MAPE が +/-10% 以内に収まっている。 ・Reference がない場合、ダミーモデルの MAPE 以下。 |
BinaryClassificationTestPreset
目的変数のデータドリフトの監視やモデル運用時における二値分類モデルのパフォーマンスの監視で利用します。
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestColumnDrift | DataDriftTestPreset の TestColumnDrift と同一 | - |
| TestPrecisionScore | Current データについて、適合率 (precision) が適切かテストします。 | ・Reference データに対して、precision が +/-20% 以内に収まっている。 ・Reference がない場合、ダミーモデルの precision 以上。 |
| TestRecallScore | Current データについて、再現率 (recall) が適切かテストします。 | ・Reference データに対して、recall が +/-20% 以内に収まっている。 ・Reference がない場合、ダミーモデルの recall 以上。 |
| TestF1Score | Current データについて、F1スコアが適切かテストします。 | ・Reference データに対して、F1スコアが +/-20% 以内に収まっている。 ・Reference がない場合、ダミーモデルの F1スコア以上。 |
| TestAccuracyScore | Current データについて、正解率 (accuracy) が適切かテストします。 | ・Reference データに対して、accuracy が +/-20% 以内に収まっている。 ・Reference がない場合、ダミーモデルの accuracy 以上。 |
| TestRocAuc | Current データについて、ROC AUC が適切かテストします。 このコンポーネントは確率的分類の場合のみ表示されます。 |
・Reference データに対して、ROC AUC が +/-20% 以内に収まっている。 ・Reference がない場合、ROC AUC が 0.5 より大きい。 |
BinaryClassificationTopKTestPreset
BinaryClassificationTopKTestPreset は確率的分類の場合のみ使用できます。
陽性確率をもとに陽/陰性を分類する際、BinaryClassificationTestPreset では確率閾値を用いていたのに対し、BinaryClassificationTopKTestPreset では陽性の確率の高い上位 k位までを陽性と分類します。
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestAccuracyScore | BinaryClassificationTestPreset の TestAccuracyScore と同一 | - |
| TestPrecisionScore | BinaryClassificationTestPreset の TestPrecisionScore と同一 | - |
| TestRecallScore | BinaryClassificationTestPreset の TestRecallScore と同一 | - |
| TestF1Score | BinaryClassificationTestPreset の TestF1Score と同一 | - |
| TestColumnDrift | BinaryClassificationTestPreset の TestColumnDrift と同一 | - |
| TestRocAuc | BinaryClassificationTestPreset の TestRocAuc と同一 | - |
| TestLogLoss | Current データについて、Log Loss が適切かテストします。 このコンポーネントは確率的分類の場合のみ表示されます。 |
・Reference データに対して、Log Loss が +/-20% 以内に収まっている。 ・Reference がない場合、Log Loss が 0.5 以下。 |
MulticlassClassificationTestPreset
BinaryClassificationTestPreset が二値分類モデルに対するテストであるのに対し、MulticlassClassificationTestPreset は 二値以上のマルチクラスに対する分類モデルのテストです。
マルチクラスですが、二値分類に対しても使用することができます。Precision, recall はクラスごとにテストするので、二値分類でも両方のクラスを対等に見たい場合に有効です。
注意
三値以上の場合、通常の分類モデルでは問題ありませんが、確率的分類には対応していません。(v0.2.2 時点。)出力の時点で、TestAccuracyScore, TestF1Score, TestLogLoss, TestRocAuc がERROR判定となります。
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestAccuracyScore | BinaryClassificationTestPreset の TestAccuracyScore と同一 | - |
| TestF1Score | BinaryClassificationTestPreset の TestF1Score と同一 | - |
| TestPrecisionByClass | Current データについて、適合率 (precision) が適切か、クラスごとにテストします。 |
基本的には、BinaryClassificationTestPreset の TestPrecisionScore と同様 |
| TestRecallByClass | Current データについて、再現率 (recall) が適切か、クラスごとにテストします。 | 基本的には、BinaryClassificationTestPreset の TestRecallScore と同様 |
| TestColumnDrift | BinaryClassificationTestPreset の TestColumnDrift と同一 | - |
| TestNumberOfRows | DataStabilityTestPreset の TestNumberOfRows と同一 | - |
| TestLogLoss | BinaryClassificationTopKTestPreset の TestLogLoss と同一 | - |
| TestRocAuc | BinaryClassificationTestPreset の TestRocAuc と同一 | - |
NoTargetPerformanceTestPreset
NoTargetPerformanceTestPresetは目的変数の実測値が、モデル予測後すぐに取得できない場合に利用します。
例えば、現在の状態を基に1年後の○○を予測するようなモデルの場合、予測から1年経たないと実測値を取得できません。しかし、実測値取得を待たずに、データドリフトによるパフォーマンス劣化が起こる可能性があります。そのような場合を想定し、NoTargetPerformanceTestPresetを利用して、目的変数以外の特徴量や予測値について、データドリフトやデータ品質をテストします。
| コンポーネント | 概要 | SUCCESS条件(デフォルト) |
|---|---|---|
| TestShareOfDriftedColumns | DataDriftTestPreset の TestShareOfDriftedColumns と同一 | - |
| TestColumnDrift | DataDriftTestPreset の TestColumnDrift と同一 | - |
| TestColumnShareOfMissingValues | DataStabilityTestPreset の TestColumnShareOfMissingValues と同一 | - |
| TestShareOfOutRangeValues | DataStabilityTestPreset の TestShareOfOutRangeValues と同一 | - |
| TestShareOfOutListValues | DataStabilityTestPreset の TestShareOfOutListValues と同一 | - |
| TestMeanInNSigmas | DataStabilityTestPreset の TestMeanInNSigmas と同一 | - |