実はSnowflakeではCTASなどでテーブルを更新すると、ACCESS_HISTORYビューにカラムリネージュの情報が記録されています。
この記事ではStreamlit in SnowflakeとACCESS_HISTORYビューでリネージュ グラフを作成してみます。
本記事の内容は2023年11月16日時点の情報に基づきます。
ACCESS_HISTORYビューのカラムリネージュ
概要
ACCOUNT_USAGEスキーマのACCESS_HISTORYビューにはオブジェクトへの操作記録が保存されています。
さらにテーブルを更新したとき、参照先テーブルのカラムが更新先テーブルのどのカラムに反映されているか(カラムリネージュ)についても記録されています。
カラムリネージュが記録される操作は以下のとおりです。
CREATE TABLE ... AS SELECT (CTAS)
CREATE TABLE ... CLONE
INSERT ... SELECT ...
MERGE
UPDATE
例
テーブルをCTASで作成して、ACCESS_HISTORYビューを確認してみます。
以下のように元テーブル t1 とその派生先テーブル ct1 を作成します。
create or replace table t1 (c1 int, c2 int);
create or replace table ct1 as select c1 as cc1, c2 as cc2, c1 + c2 as cc3 from t1;
ACCESS_HISTORYビューの OBJECTS_MODIFIED 列を参照します。
※1 ACCOUNT_USAGEへの反映は遅いため、少し待ちます。(最大3時間)
※2 履歴の量が多いためCTASで作成したテーブル名で絞り込みます。
select *
from snowflake.account_usage.access_history
where objects_modified[0].objectName = 'LINEAGE.PUBLIC.CT1'
order by query_start_time desc;
OBJECTS_MODIFIED 列の出力結果
[
{
"columns": [
{
"baseSources": [
{
"columnName": "C2",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
},
{
"columnName": "C1",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
],
"columnId": 1034,
"columnName": "CC3",
"directSources": [
{
"columnName": "C2",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
},
{
"columnName": "C1",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
]
},
{
"baseSources": [
{
"columnName": "C2",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
],
"columnId": 1033,
"columnName": "CC2",
"directSources": [
{
"columnName": "C2",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
]
},
{
"baseSources": [
{
"columnName": "C1",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
],
"columnId": 1032,
"columnName": "CC1",
"directSources": [
{
"columnName": "C1",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
]
}
],
"objectDomain": "Table",
"objectId": 1040,
"objectName": "LINEAGE.PUBLIC.CT1"
}
]
多層構造になっているため、2層に分けて中身の解説をします。
-
root
変更のあったテーブルがリストされます。テーブル内のカラムの情報はcolumsに格納されます。[ { "columns": [] "objectDomain": "Table", "objectId": 1040, "objectName": "LINEAGE.PUBLIC.CT1" } ] -
columnsの中身
更新先テーブル(CT1)のカラムがリストされます。下のJSONはリストされたカラムのうちの一つです。
baseSources内のカラムをソースとしてcolumnNameのカラムが作成されたことが記録されます。今回のリネージュグラフにはbaseSourcesの情報を使用します。ビューを経由してテーブルにアクセスした場合、
directSourcesに参照したビュー、baseSourcesにビューが参照しているテーブルの情報が記録されます。 ビューがネストされている場合、直接参照したビューとビューが参照しているテーブルの情報以外は記録されません。ビューの関係がすべて記録されないため、今回のリネージュグラフにdirectSourcesは使いません。
{
"baseSources": [
{
"columnName": "C2",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
},
{
"columnName": "C1",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
],
"columnId": 1034,
"columnName": "CC3",
"directSources": [
{
"columnName": "C2",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
},
{
"columnName": "C1",
"objectDomain": "Table",
"objectId": 10,
"objectName": "LINEAGE.PUBLIC.T1"
}
]
},
リネージュ情報の出力
リネージュに必要な情報をSQLで出力します。
select
query_id,
om.value:objectDomain::string as om_object_domain,
om.value:objectName::string as om_object_name,
col.value:columnName::string as om_column_name,
bs.value:columnName::string as bs_column_name,
bs.value:objectName::string as bs_object_name
from
snowflake.account_usage.access_history as ah,
lateral flatten(input => ah.objects_modified) as om,
lateral flatten(input => om.value:columns) as col,
lateral flatten(input => col.value:baseSources) as bs
;
出力例
| QUERY_ID | OM_OBJECT_DOMAIN | OM_OBJECT_NAME | OM_COLUMN_NAME | BS_COLUMN_NAME | BS_OBJECT_NAME |
|---|---|---|---|---|---|
| 01afc0b1-3202-0f64-0002-4542000141d2 | Table | LINEAGE.PUBLIC.CT1 | CC2 | C2 | LINEAGE.PUBLIC.T1 |
| 01afc0b1-3202-0f64-0002-4542000141d2 | Table | LINEAGE.PUBLIC.CT1 | CC3 | C1 | LINEAGE.PUBLIC.T1 |
| 01afc0b1-3202-0f64-0002-4542000141d2 | Table | LINEAGE.PUBLIC.CT1 | CC3 | C2 | LINEAGE.PUBLIC.T1 |
| 01afc0b1-3202-0f64-0002-4542000141d2 | Table | LINEAGE.PUBLIC.CT1 | CC1 | C1 | LINEAGE.PUBLIC.T1 |
Graphviz
リネージュグラフの作成にGraphvizを使用します。
概要
GraphvizはOSSのグラフ可視化ツールです。dot言語という独自言語で図形を作成できます。
例

Streamlit in Snowflakeでの利用
Streamlit in Snowflakeではstreamlitオブジェクトの graphviz_chart 関数にdot言語を直接入力することで、Graphvizの図を作成することができます。Streamlit in SnowflakeではPythonのgraphvizライブラリを使用できない点に注意してください。
表の表示
Graphvizでは表とグラフを組み合わせた図を作成可能です。今回のリネージュグラフにはこの機能を使います。
公式ドキュメント
例
dot言語でリネージュを表現してみます。
リネージュで表現したいSQL(再掲)
create or replace table t1 (c1 int, c2 int);
create or replace table ct1 as select c1 as cc1, c2 as cc2, c1 + c2 as cc3 from t1;
dot言語による表記
digraph {
graph [pad="0.5", nodesep="0.5", ranksep="2"];
node [shape=plain]
rankdir=LR;
"LINEAGE.PUBLIC.T1" [
label=<
<table border="0" cellborder="1" cellspacing="0">
<tr><td><i>LINEAGE.PUBLIC.T1</i></td></tr>
<tr><td port="C2">C2</td></tr>
<tr><td port="C1">C1</td></tr>
</table>
>
];
"LINEAGE.PUBLIC.CT1" [
label=<
<table border="0" cellborder="1" cellspacing="0">
<tr><td><i>LINEAGE.PUBLIC.CT1</i></td></tr>
<tr><td port="CC2">CC2</td></tr>
<tr><td port="CC1">CC1</td></tr>
<tr><td port="CC3">CC3</td></tr>
</table>
>
];
"LINEAGE.PUBLIC.T1":"C2" -> "LINEAGE.PUBLIC.CT1":"CC2";
"LINEAGE.PUBLIC.T1":"C1" -> "LINEAGE.PUBLIC.CT1":"CC1";
"LINEAGE.PUBLIC.T1":"C1" -> "LINEAGE.PUBLIC.CT1":"CC3";
"LINEAGE.PUBLIC.T1":"C2" -> "LINEAGE.PUBLIC.CT1":"CC3";
}
Graphvizによる画像出力

コード
以上を踏まえて、Streamlitのコードに落とし込むと以下のようになります。
テーブル数が多いと全く表示されないため、 start_table と関係のあるテーブルだけ表示しています。
import json
import pandas as pd
from snowflake.snowpark import Session
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.exceptions import SnowparkSessionException
import streamlit as st
# Sessionの取得
try:
# Streamlit in Snowflakeで実行する場合
session = get_active_session()
except SnowparkSessionException:
# ローカル環境で実行する場合
with open('./snowflake_connection_parameters.json') as f:
connection_parameters = json.load(f)
session = Session.builder.configs(connection_parameters).create()
def query_lineage_df(session):
# Snowflakeからリネージュの情報を取得
query_text = '''
select
query_id,
om.value:objectDomain::string as om_object_domain,
om.value:objectName::string as om_object_name,
col.value:columnName::string as om_column_name,
bs.value:columnName::string as bs_column_name,
bs.value:objectName::string as bs_object_name
from
snowflake.account_usage.access_history as ah,
lateral flatten(input => ah.objects_modified) as om,
lateral flatten(input => om.value:columns) as col,
lateral flatten(input => col.value:baseSources) as bs
;
'''
return session.sql(query_text).to_pandas()
def query_lineage_parent_df(session, start_table):
# Snowflakeから親側のリネージュの情報を取得
query_text = f'''
with lineage as (
select
query_id,
om.value:objectDomain::string as om_object_domain,
om.value:objectName::string as om_object_name,
col.value:columnName::string as om_column_name,
bs.value:columnName::string as bs_column_name,
bs.value:objectName::string as bs_object_name
from
snowflake.account_usage.access_history as ah,
lateral flatten(input => ah.objects_modified) as om,
lateral flatten(input => om.value:columns) as col,
lateral flatten(input => col.value:baseSources) as bs
)
select
om_object_name,
om_column_name,
bs_column_name,
bs_object_name
from lineage
start with om_object_name = '{start_table}'
connect by om_object_name = prior bs_object_name
;
'''
return session.sql(query_text).to_pandas()
def query_lineage_child_df(session, start_table):
# Snowflakeから子側のリネージュの情報を取得
query_text = f'''
with lineage as (
select
query_id,
om.value:objectDomain::string as om_object_domain,
om.value:objectName::string as om_object_name,
col.value:columnName::string as om_column_name,
bs.value:columnName::string as bs_column_name,
bs.value:objectName::string as bs_object_name
from
snowflake.account_usage.access_history as ah,
lateral flatten(input => ah.objects_modified) as om,
lateral flatten(input => om.value:columns) as col,
lateral flatten(input => col.value:baseSources) as bs
)
select
om_object_name,
om_column_name,
bs_column_name,
bs_object_name
from lineage
start with bs_object_name = '{start_table}'
connect by bs_object_name = prior om_object_name
;
'''
return session.sql(query_text).to_pandas()
def query_column_df(session):
# テーブルとカラムの情報を取得
# データベースによらず情報を取得するためaccount_usageから取得する。
query_text = """
select
column_name,
table_catalog || '.' || table_schema || '.' || table_name as table_name
from snowflake.account_usage.columns;
"""
return session.sql(query_text).to_pandas()
def query_column_df(session):
# テーブルとカラムの情報を取得
# データベースによらず情報を取得するためaccount_usageから取得する。
query_text = """
select
column_name,
table_catalog || '.' || table_schema || '.' || table_name as table_name
from snowflake.account_usage.columns;
"""
return session.sql(query_text).to_pandas()
class Table:
def __init__(self, name, columns):
self.name = name
self.columns = columns
def generate_table(table_name, column_names):
column_table_str = ''
for column_name in column_names:
column_table_str += f' <tr><td port="{column_name}">{column_name}</td></tr>\n'
return f'''
"{table_name}" [
label=<
<table border="0" cellborder="1" cellspacing="0">
<tr><td><i>{table_name}</i></td></tr>
{column_table_str}
</table>
>
];
'''
def genetate_node(from_table_names, from_column_names, to_table_names, to_column_names):
result = ''
for from_table_name, from_column_name, to_table_name, to_column_name in zip(from_table_names, from_column_names, to_table_names, to_column_names):
result += f'''"{from_table_name}":"{from_column_name}" -> "{to_table_name}":"{to_column_name}";\n'''
return result
def generate_graph(graph_parts):
return f'''digraph {{
graph [pad="0.5", nodesep="0.5", ranksep="2"];
node [shape=plain]
rankdir=LR;
{graph_parts}
}}'''
def groupby_table(df, table_column_name, column_column_name):
result = []
for name, group in df.groupby(table_column_name):
columns = group[column_column_name].values.tolist()
result.append(Table(name, columns))
return result
# Streamlitの画面表示
st.title("Lineage generator")
start_table = st.text_input('Input table name', 'DATABASE.SCHEMA.TABLE')
# Snowflakeからデータの取得
# リネージュ情報を取得
# lineage_df = query_lineage_df(session)
lineage_child_df = query_lineage_child_df(session, start_table)
lineage_parent_df = query_lineage_parent_df(session, start_table)
# リネージュに関係のあるテーブルを抽出
lineage_table_df = pd.Series()
lineage_table_df = pd.concat([lineage_table_df, lineage_child_df['BS_OBJECT_NAME'], lineage_child_df['OM_OBJECT_NAME']])
lineage_table_df = pd.concat([lineage_table_df, lineage_parent_df['BS_OBJECT_NAME'], lineage_parent_df['OM_OBJECT_NAME']])
# 各テーブルとカラムを取得
column_df = query_column_df(session)
column_df = column_df[column_df['TABLE_NAME'].isin(lineage_table_df)]
# Graphvizで表示するためにdot言語の文を生成
graph_parts = ''
table_list = groupby_table(column_df, 'TABLE_NAME', 'COLUMN_NAME')
for table in table_list:
graph_parts += generate_table(table.name, table.columns)
# graph_parts += genetate_node(lineage_df['BS_OBJECT_NAME'], lineage_df['BS_COLUMN_NAME'], lineage_df['OM_OBJECT_NAME'], lineage_df['OM_COLUMN_NAME'])
graph_parts += genetate_node(lineage_child_df['BS_OBJECT_NAME'], lineage_child_df['BS_COLUMN_NAME'], lineage_child_df['OM_OBJECT_NAME'], lineage_child_df['OM_COLUMN_NAME'])
graph_parts += genetate_node(lineage_parent_df['BS_OBJECT_NAME'], lineage_parent_df['BS_COLUMN_NAME'], lineage_parent_df['OM_OBJECT_NAME'], lineage_parent_df['OM_COLUMN_NAME'])
graph = generate_graph(graph_parts)
# Graphvizのグラフを表示
st.graphviz_chart(graph)
アプリ画面
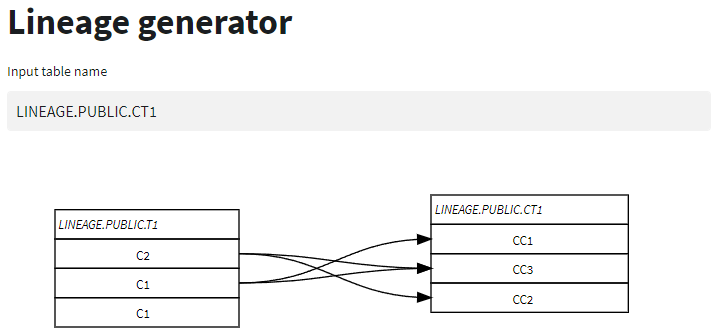
注意点
2023年10月1日現在、Streamlit in Snowflakeで動作するPythonのバージョンは 3.8 です。そのため dataclass でlistを指定できなかったりと、意外とはまるポイントがあります。
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。