投稿のきっかけ
ある機械学習のモデルの評価をする際にAUCが出てきたので、真面目に (?) 勉強しました。
相対的な値としてのAUCの意味についての記事はたくさんありますが、絶対的な値としてのAUCの意味についての記事があまり見当たらなかったので、書きます。
筆者は機械学習初心者ですので、何か間違いがあれば、ご指摘ください。
TPRとかFPRのおさらい
正か負に分類する問題で、何かしらのモデルを作成し、その性能を評価したいとします。評価する指標としては
\begin{align}
正解率 &= \frac{TP + TN}{TP + FP + TN + FN} \\
適合率 &= \frac{TP}{TP + FP} \\
再現率 &= \frac{TP}{TP + FN} \\
特異性 &= \frac{TN}{FP + TN}
\end{align}
の4つがあります。再現率は真陽性率 (True Positive Rate: TPR) とも呼ばれます。正解が正のものをどれだけ正と予測できたかを表す割合です。
偽陽性率 (False Positive Rate: FPR) は
FPR = 1 - 特異性 = \frac{FP}{FP + TN}
で定義されます。つまり、正解が負のものをどれだけ正と予測したかの割合です。
ROCのおさらい
ROCの定義
ROCとは横軸に偽陽性率(FPR)、縦軸に真陽性率(TPR)をプロットした曲線です。
分類問題は、モデルで評価されたデータと設定された閾値の大小で正・負を決定することにします。この時の閾値を変化させて、FPRとTPRを計算し、プロットして出来上がるのがROC曲線です。
FPRが低い値でTPRが高い値の方が良いモデルと判断できます。なぜなら、FPRが低く、TPRが高いということは、正解が正のものを負と予測することなく、正と予測できているからです。
具体例
具体例からROC曲線を書いてみます。あまり現実的ではないですが、ご容赦ください。
●と○を分類する問題で、あるモデル (モデル1とします) が以下のように○と●を並べ、

間に線を引いて、右にあるものを○、左にあるものを●と予測するとします。(見て分かるように、このモデル1は全く使えません)
線の引き方は以下の7通りです。左から⓵~⓻番とします。
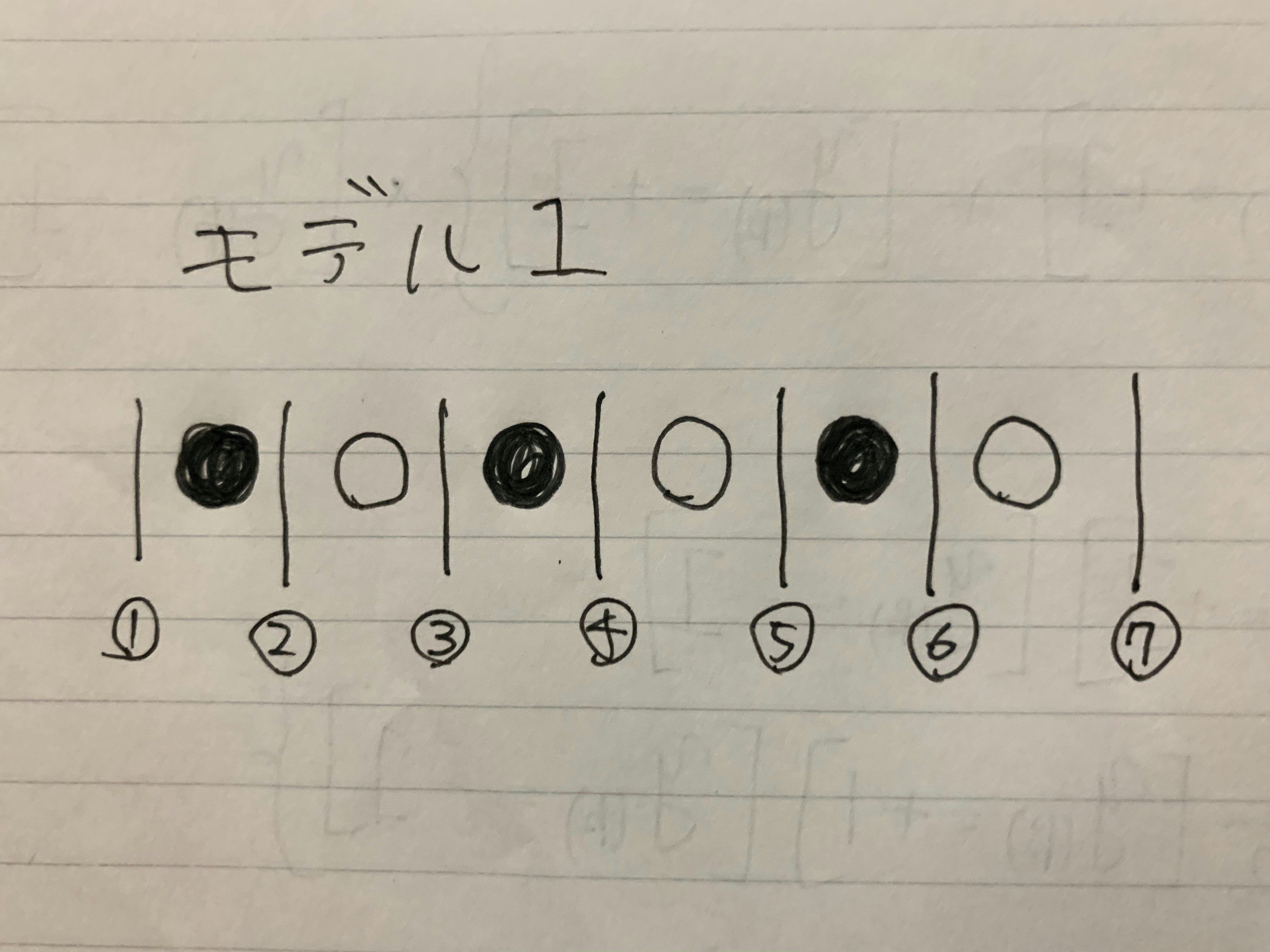
⓵番の線を閾値をした場合、全て○と予測することになるので
FRP = 1, \qquad TPR = 1
となります。同様に⓶〜⓻番の線についても同様の計算を行います。得られたFPRとTPRをまとめると
(FPR, TPR) = (1, 1), \left(\frac{2}{3}, 1 \right), \left(\frac{2}{3}, \frac{2}{3} \right),
\left(\frac{1}{3}, \frac{2}{3} \right), \left(\frac{1}{3}, \frac{1}{3} \right), \left(0, \frac{1}{3} \right), (0, 0)
となると思います。これらの点を結んで曲線を作ったものがROC曲線です。以下の画像のようになります。
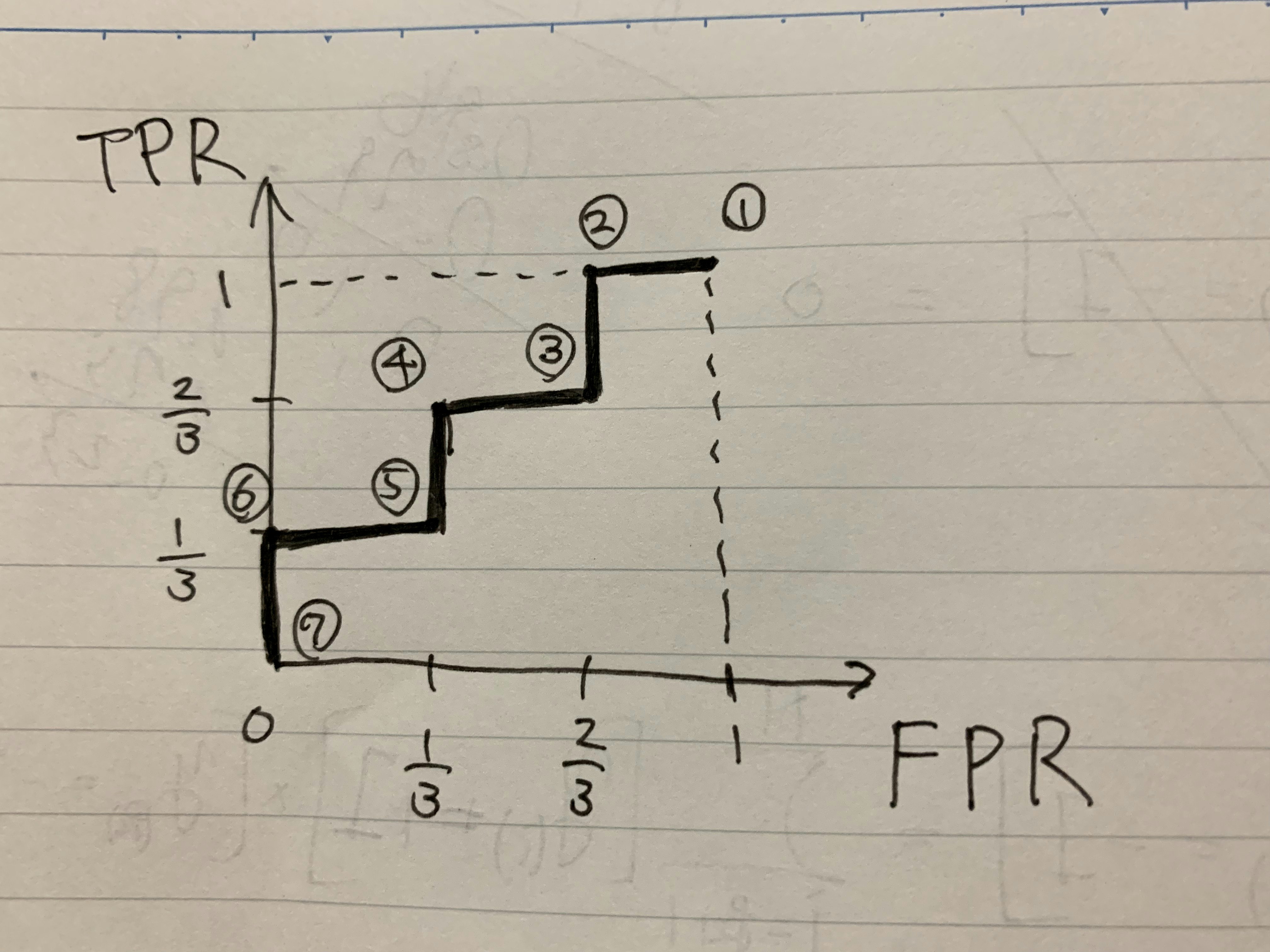
①などは線 (閾値) の場所です。FPRが低く、TPRが高い分類器が良いとお話しましたが、図を見て分かるように、このモデル1はあまり役に立たなそうです。
AUCの話
AUCのおさらい
AUC (Area Uner the Curve) とはROC曲線とFPRで囲まれる部分の面積です。先ほどの画像からAUCを計算すると
\mathrm{AUC_{モデル1}} = \frac{1}{3} \times \frac{1}{3} + \frac{1}{3} \times \frac{2}{3} + \frac{1}{3} \times 1 = \frac{6}{9}
となります。理想的なモデルでは、この値は1になります。
相対的な値としてのAUC
別のモデル2は先ほどの○と●を

のように並べました。先ほどのモデル1の左から2番目の○が1つ右に移動しました。先ほどのモデル1よりモデル2の方が良さそうです。AUCの観点からこれを定量的に判断しましょう。
先ほどと同様の位置に線 (閾値) を引き、⓵~⓻番とし、各線でのFPRとTPRを計算するとROC曲線は以下の画像になります。
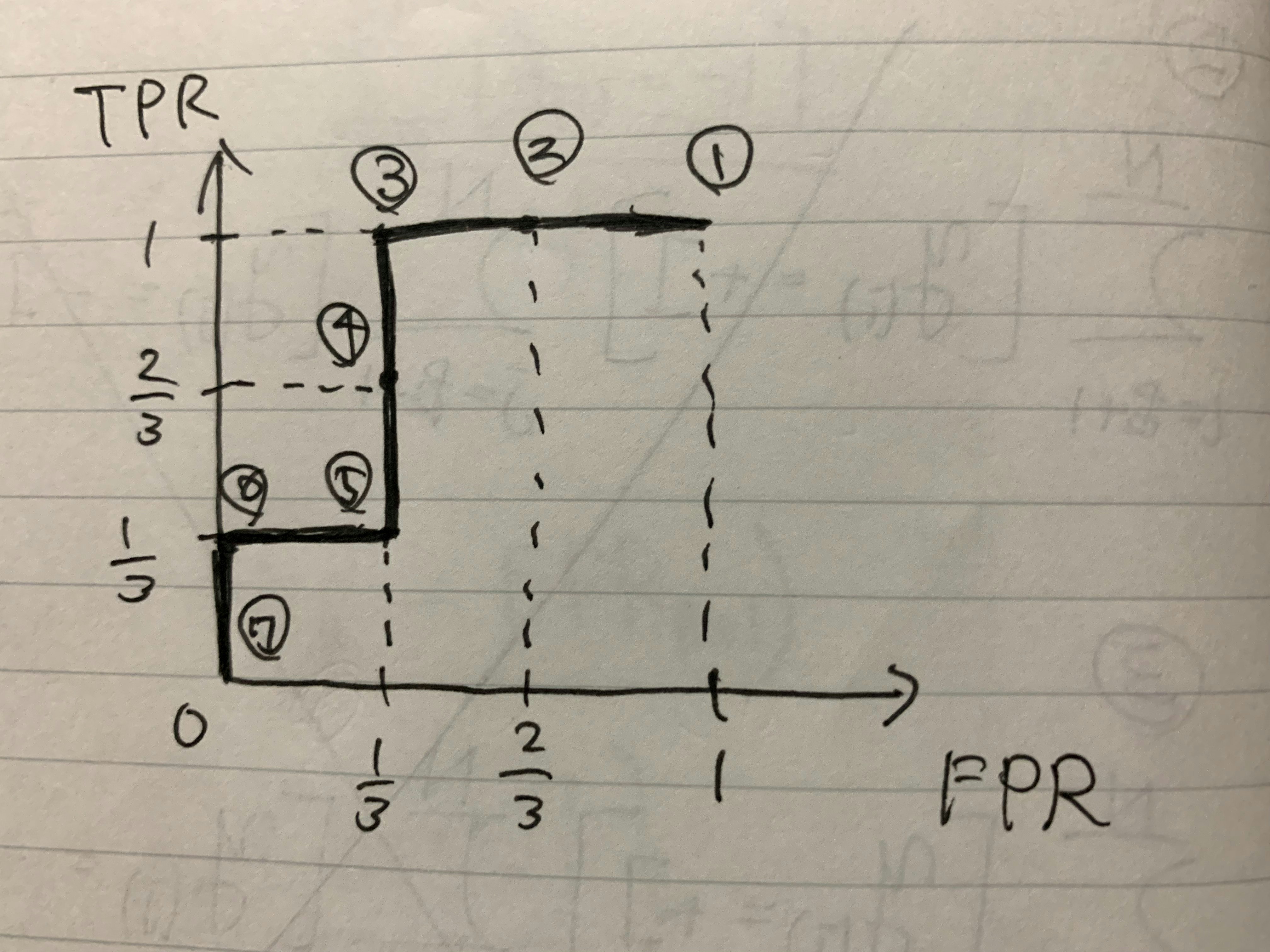
ACUは
\mathrm{AUC_{モデル2}} = \frac{2}{3} \times 1 + \frac{1}{3} \times \frac{1}{3} = \frac{7}{9}
で、モデル1のAUC (=6/9) よりも値が大きいです。モデル2の方がモデル1より良いモデルであることがAUCの観点から定量的に示されました。
AUCの値を比較する (相対的な値として解釈する) というのは、割と分かりやすい話だと思います。
絶対的な値としてのAUC
ここからが本題です。(前置きが長くなりました)
モデル1のAUCは6/9です
と言われた時に、この6/9は何を表すのでしょうか?
google大先生にお聞きしたところ、こちらの記事を見つけました (数式があって非常に分かりやすい)。以下は記事の一部を抜粋したものです。
AUC is equivalent to the probability that two randomly selected samples are correctly ranked.
だそうです。訳すと「AUCはランダムに選んだ2つのサンプルが正しくランク付けされている確率」です。
記事の中では数式を使ってこれを証明しているので、実際に証明してみて、先ほどの具体例で確かめます。
まずは証明
$N$個の有限のデータセット$(x_i, y_i) (i=1,\cdots, N)$に対し、$A(x)$は、与えられた$x$に対して対応する$y$が$+1$である確率を算出するとします。そして、$y=+1$のサンプル数を$N_{+}$, $y=-1$のサンプル数を$N_-$とおきます。ある閾値$\tau$に対するTPRとFPRは
\mathrm{TPR(\tau)} = \frac{\sum_{i=1}^N [y=+1][A(x_i) \geq \tau]}{N_+}, \quad \mathrm{FPR(\tau)} = \frac{\sum_{i=1}^N [y=-1][A(x_i) \geq \tau]}{N_-}
で計算できます。ここで$[\cdots]$は$\cdots$が真なら1, 偽なら0を返す演算子だと思ってください。
さらに話を簡単にするために、データセットを $A(x_i)$の値によって並び替えます。新しい順番のデータセットを$(x_{(i)},y_{(i)})$とおきます。TPRとFPRの値は、$A(x_{(i)}) < \tau < A(x_{(i+1)})$で変化しないため、$\tau \in \{ A(x_{(1)}), \cdots, A(x_{(N)}) \}$についてTPRとFPRを評価すれば良いことになります。$k$番目のデータセットに対するTPRとFPRは
\mathrm{TPR}_k = \frac{\sum_{i=k}^N [y=+1]}{N_+},\quad \mathrm{FPR}_k = \frac{\sum_{i=k}^N [y=-1]}{N_-}
となるため、AUCは
\begin{align}
\mathrm{AUC} &= \sum_{k=1}^{N-1} \frac{1}{2} \left( \mathrm{TPR}_{k+1} + \mathrm{TPR}_k \right) \left( \mathrm{FPR}_{k} - \mathrm{FPR}_{k+1} \right) \\
&= \frac{1}{2N_+ N_-} \sum_{k=1}^{N-1} \left(\sum_{i=k+1}^{N} [y_{(i)} = +1] + \sum_{i=k}^{N} [y_{(i)} = +1] \right) \left(\sum_{j=k}^{N} [y_{(j)} = -1] - \sum_{j=k+1}^{N} [y_{(j)} = -1] \right) \\
&= \frac{1}{2N_+ N_-} \sum_{k=1}^{N-1} \left(2 \sum_{i=k+1}^{N} [y_{(i)} = +1] + [y_{(k)} = +1] \right) [y_{(k)}=-1] \\
&= \frac{1}{N_+ N_-} \sum_{k=1}^{N-1} \sum_{i=k+1}^{N} [y_{(i)} = +1] [y_{(k)} = -1] \\
&= \frac{1}{N_+ N_-} \sum_{k < i} [y_{(k)} < y_{(i)}]
\end{align}
と計算できます。式の途中で、$^\forall i, [y_{(i)} = -1][y_{(i)} = +1] = 0$という恒等式を使いました。
得られた式をよく観察します。分母の$N_+N_-$は
+1のサンプルと-1のサンプルの組み合わせの数
と解釈できます。また、分子の和は
与えられた(i,k)に対して、サンプルが不等号を満たしいるならば1で、それ以外は0
となる演算子なので、結局AUCは
ランダムに選んだ2つのサンプルが正しくランク付けされている確率
と解釈できそうです。
具体例で確かめる
実際のモデルで計算してみます。まずはモデル1。モデル1は●と○を以下のように並べました。(わかりやすく数字をつけてます)

この時、ランダムに選べる2つのサンプルは
(1,2) \quad (1,4) \quad (1,6) \quad (2,3) \quad (2,5) \quad (3,4) \quad (3,6) \quad (4,5) \quad (5,6)
の9通りです。このうち、正しくランク付けされているのは
(1,2) \quad (1,4) \quad (1,6) \quad (3,4) \quad (3,6) \quad (5,6)
の6パターンで、確率は6/9でAUCの値と一致してます。(イェーイ!!!素晴らしい)
モデル2も同様に計算すれば、AUCの値と一致することが簡単に示せます。
まとめ
2つのAUCを比べて、モデルの良し悪しを判断するというのは分かりやすいですが、1つのAUCに対して、その値にどのような解釈を与えるかというのがはっきりしました。
やはり、式や数字が現実世界とどう対応しているのか考えることは楽しいです。
参考文献
Why is AUC equivalent to the probability that two randomly selected samples are correctly ranked?