1. はじめに
先日、表面的な字面にとらわれず、意味的に近いテキストかどうかを判定できるOpenAIが提供しているEmbeddings APIなるものがあることを知りました。
「昨今の技術すご...」と感動したので、ぜひこの感動を共有したいなと思いキータの記事にしました。
サンプルコードも掲載するので、ぜひみなさまも「Embeddings APIすごっ」てなったら使ってみてください。
2. 結論
OpenAI Embeddings APIを使用することで、
-
従来の文字列の比較では捉えきれない、意味的な関連性を把握できる
-
類義語・関連語検索をはじめとしたユーザー体験を向上させることができる(はず)
3. OpenAI Embeddings APIとは?
OpenAIのEmbeddings APIは、単語や文の意味を文章ベクトルとしてベクトル化します。
このベクトル化した文字列同士の距離を計測することで、意味的な類似性を計算できるようになります。
これにより、単純な文字列の比較では捉えきれない、単語や文章同士が持つ文脈的な関連性を把握することが可能になります。
Embeddings APIは特定の単語や文章を高次元ベクトルに変換し、これらのベクトルを比較することで、意味的に似ている単語やフレーズを見つけ出すことができる技術です。
OpenAI Embeddings APIのポイント
単語や文章をベクトルとして扱うことで、単純な文字列の比較では把握できない、意味的に似ている単語やフレーズを見つけ出すことができる。
4. もっと簡単に説明してほしい
4-1. 二次元で説明してみる
2次元で説明します。
例えば図のように
- 「みかん」を意味する座標(0.7, 0.7)
- 「りんご」を意味する座標が(1, 0)
があるとします。
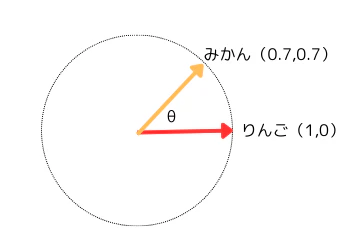
原点(0, 0)から「みかん」「りんご」の座標に矢印を伸ばします。
これで、「みかん」「りんご」をベクトルとして表現することができます。
$ \text{みかんベクトル} = (0.7, 0.7) $
$ \text{りんごベクトル} = (1, 0) $
4-2. 2つのベクトルの成す角度の意味
2つのベクトルによって作られる角度θが小さいほど、みかんとりんごの類似度は高いことを意味します。
このように、二つのベクトルの向きを計測することで、ベクトル同士の類似性を得ることができます。
そのため、
- openAI Embeddings APIを使って、文字列の文章ベクトル(座標)を取得する
- 取得した文章ベクトル同士の類似性を計算して、意味的に近いかを計算する
ことで、類義語や関連語を調べることができるようになります。
4-3. コサイン類似度を使用する
実際にどれくらい同じ向きを向いているかについては、コサイン類似度を用います。
コサイン数学は、高校数学で学習するベクトルの内積公式から算出できます。
内積公式
$$ \mathbf{A} \cdot \mathbf{B} = |\mathbf{A}| |\mathbf{B}| \cos\theta $$
コサイン類似度の公式
$$ \cos\theta = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|} $$
4-4. コサイン類似度の意味
コサイン類似度は1-から1の範囲に収まり、1に近づけば近づくほど、二つのベクトルの向きが近い(意味的に近い)ことを意味します。1
5. 従来の方法とEmbeddings APIの違い
従来の方法とEmbeddings APIには以下のような違いがあります。
5-1. 従来の方法
- 単語の一致や部分一致に基づく文字列検索、または簡単な類義語リストを使った検索
文脈や意味の違いを考慮できず、文字列が似ているかどうかだけで判断するため、適切な類義語や関連語を見つけにくい。
5-2. Embeddings APIの方法
- 単語の意味をベクトル空間にマッピングし、ベクトル間の距離で類似性を計算
意味や文脈の近さに基づく検索が可能。表面的には異なるが、意味的に似ている単語を高精度で見つけられる。
6. でも、きっとお高いんでしょ?
OpenAI Embeddings APIを利用する場合、モデルごとに異なる料金が適用されます。
料金はAPIにリクエストを送信する際に、テキストをベクトルに変換するために処理されるトークン数によって決まります。
6-1. トークン数とは?
トークンはAPIが処理するテキストの単位で、英単語や記号が1つのトークンに相当します。
例えば、1000トークンのリクエストを送信すると、1000単語分のテキストをベクトル化してくれます。
text-embedding-3-largeの料金
今回使用するtext-embedding-3-largeというモデルの場合は
100万トークンあたり$0.130(1ドル145円として、約18円)の料金が発生します。
「ハリー・ポッターと賢者の石」がだいたい13万文字くらいのため、だいたい7冊分くらいを18円でベクトル化できます。
だいたいうまい棒1本くらいの値段で。
安いですよね?
僕はとても安いなと感じます、はい。
ちなみにバッチ処理にすると普通にAPI叩く場合の半額で利用できたりします。
より具体的な料金やモデルごとの価格は、OpenAIの料金ページで確認してください。
OpenAIの料金ページ
7. Embeddings APIを使って、関連度を確認してみよう
では実際にEmbeddings APIを使って関連度を確認してみましょう。
7-1. サンプルケースの紹介
今回は「黄色いネズミのポケモン」という言葉との関連度を調べてみます。
調べる対象の言葉は以下のとおりです。
ピカチュウ、ミッキーマウス、ジェリー、プーさん、ポムポムプリン、コダック、ライコウ
人間であればお題の言葉の意味を考えて、「ピカチュウ」を選ぶことができます。
今回はこの意味が近い言葉を選ぶ作業をEmbveddings APIにさせます。
どのような結果になるのかを実験しましょう!
7-2. Embeddings API導入までの手順
OpenAIアカウント作成
OpenAIのアカウントを作成していない場合はアカウントを作成してください。
APIキーの取得
アカウントにログインしたら、ダッシュボードからAPIキーを取得します。
APIのクレジットを設定
APIのクレジットを設定していない場合は、クレジットを設定してください。
Embeddings API自体は料金が非常に低額のため、他に使う予定がなければ最低金額の5ドルでOKだと思います。
7-3. 環境構築と依存モジュールのインストール
実際にEmbeddings APIを使用するための環境構築を行います。
APIさえ叩ければ言語はなんでも大丈夫なので、適宜使いやすい言語を選んでください。
この記事ではJavaScriptを使用します。
JavaScriptでOpenAI APIを使用するために、今回はaxiosを使ってHTTPリクエストを送ることにします。
Node.jsをインストール
Node.jsがインストールされていない場合はインストールしてください。
インストールされているかどうかは以下のコマンドで確認できます。
node -v
公式HPからインストールしても、homebrewやバージョン管理ツール経由のインストールでもなんでもOKです。
プロジェクトディレクトリを作成
サンプルコード用のディレクトリを作成して初期化します。
mkdir openai-embeddings-example
cd openai-embeddings-example
npm init -y
axiosのインストール
APIを使用するために、axiosをインストールします。
npm install axios
7-4. サンプルコードを作成する
OpenAIのEmbeddings APIを使用して入力された単語のベクトルを取得し、関連する単語との類似度を計算するサンプルコードを紹介します。
const axios = require("axios");
// OpenAIのAPIキーを設定してください
const API_KEY = "your-openai-api-key";
// Embeddings APIにリクエストを送る関数
async function getEmbeddings(text) {
const url = "https://api.openai.com/v1/embeddings";
try {
const response = await axios.post(
url,
{
model: "text-embedding-3-large",
input: text,
},
{
headers: {
Authorization: `Bearer ${API_KEY}`,
"Content-Type": "application/json",
},
}
);
return response.data.data[0].embedding;
} catch (error) {
console.error(
"Error fetching embeddings:",
error.response ? error.response.data : error.message
);
return null;
}
}
// コサイン類似度を計算する関数
function cosineSimilarity(vecA, vecB) {
const dotProduct = vecA.reduce((acc, val, i) => acc + val * vecB[i], 0);
const magnitudeA = Math.sqrt(vecA.reduce((acc, val) => acc + val * val, 0));
const magnitudeB = Math.sqrt(vecB.reduce((acc, val) => acc + val * val, 0));
return dotProduct / (magnitudeA * magnitudeB);
}
// 類義語・関連語を計算して結果を出力する関数
async function findSimilarWords(baseWord, candidateWords) {
const baseEmbedding = await getEmbeddings(baseWord);
if (!baseEmbedding) return;
// 各単語とその類似度を格納する配列
let similarWords = [];
for (const word of candidateWords) {
const wordEmbedding = await getEmbeddings(word);
if (!wordEmbedding) continue;
const similarity = cosineSimilarity(baseEmbedding, wordEmbedding);
similarWords.push({ word, similarity });
}
// 類似度の高い順にソート
similarWords.sort((a, b) => b.similarity - a.similarity);
// ソート後の結果を出力
similarWords.forEach((item) => {
console.log(`Word: ${item.word}, Similarity: ${item.similarity}`);
});
}
const baseWord = "黄色いネズミのポケモン";
const candidateWords = [
"ピカチュウ", // 黄色いネズミのポケモン
"ミッキーマウス", // ネズミだけど、黄色くないしポケモンでもない
"ジェリー", // ネズミだけど、黄色くないしポケモンでもない
"プーさん", // 黄色いけど、ネズミじゃないしポケモンでもない
"ポムポムプリン", // 黄色いけど、ネズミじゃないしポケモンでもない
"コダック", // 黄色いポケモンだけど、ネズミじゃない
"ライコウ", //黄色いポケモンだけど、ネズミじゃない
];
findSimilarWords(baseWord, candidateWords);
7-5. 実行結果を確認する
サンプルコードができたら実際に実行しましょう。
node embeddings.js
実行結果は以下のようになります。
Word: ピカチュウ, Similarity: 0.46
Word: ミッキーマウス, Similarity: 0.40
Word: プーさん, Similarity: 0.27
Word: ジェリー, Similarity: 0.24
Word: ポムポムプリン, Similarity: 0.23
Word: ライコウ, Similarity: 0.21
Word: コダック, Similarity: 0.20
ピカチュウが一番、類似度が高いという結果を得られました!
7-6. コサイン類似度の計算方法の解説
簡単にコサイン類似度の計算方法を紹介します。
function cosineSimilarity(vecA, vecB) {
const dotProduct = vecA.reduce((acc, val, i) => acc + val * vecB[i], 0);
const magnitudeA = Math.sqrt(vecA.reduce((acc, val) => acc + val * val, 0));
const magnitudeB = Math.sqrt(vecB.reduce((acc, val) => acc + val * val, 0));
return dotProduct / (magnitudeA * magnitudeB);
}
内積の計算
まず、二つのベクトルの内積を計算します。
例えば3次元空間における内積の公式は、A = (A1, A2, A3)、B = (B1, B2, B3)とすると、
$$ \mathbf{A} \cdot \mathbf{B} = A_1 B_1 + A_2 B_2 + A_3 B_3 $$
です。
n次元空間に一般化すると、
$$ \mathbf{A} \cdot \mathbf{B} = \sum_{i=1}^{n} A_i B_i = A_1 B_1 + A_2 B_2 + \dots + A_n B_n $$
となります。
const dotProduct = vecA.reduce((acc, val, i) => acc + val * vecB[i], 0);
reduce関数でvecAの要素をループさせて、内積を計算しています。
-
val * vecB[i]でvecAのi番目の要素とvecBのi番目の要素の積を計算 - accは合計値で、初期値は0
ベクトルの大きさの計算
次に、ベクトルの大きさを計算します。
ベクトルの大きさは、各要素の自乗を合計した後、平方根を取ることで求めることができます。
3次元空間の場合は、
$$ |\mathbf{A}| = \sqrt{A_1^2 + A_2^2 + A_2^2}$$
n次元空間の場合は、
$$|\mathbf{A}| = \sqrt{A_1^2 + A_2^2 + \dots + A_n^2}$$
となります。
const magnitudeA = Math.sqrt(vecA.reduce((acc, val) => acc + val * val, 0));
vecA.reduce((acc, val) => acc + val * val, 0)で各要素の自乗の合計値を計算した後、Math.sqrt()で平方根を求めています。
コサイン類似度の計算
コサイン類似度は、内積と各ベクトルの大きさを用いて以下の公式で導けます。
$$ \text{コサイン類似度} = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|} $$
return dotProduct / (magnitudeA * magnitudeB);
そのため、
- 分子は、vecA と vecB の内積
- 分母は、vecA と vecB のそれぞれの大きさの積
にして計算結果を返却しています。
8. Embeddings APIを使って、関連書籍を見つけてみよう
今回は書籍を例にして、関連商品を見つけることができるか検証します。
8-1. サンプルで使用する書籍
先ほどのサンプルコードの文字列を以下の通り変更します。
const baseWord = "ウォール街のランダム・ウォーカー 株式投資の不滅の心理";
const candidateWords = [
"The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns", // 「インデックス投資は勝者のゲーム」の原著タイトル
"はじめての人のための3000円投資生活",
"父が娘に語る経済の話",
"中動態の世界 意思と責任の考古学",
"心という難問 空間・身体・意味",
"統計学が最強の学問である",
"筋トレが最強のソリューションである",
"26歳の自分に受けさせたいお金の講義",
"はじめてのGTD ストレスフリーの整理術",
"テスト駆動開発",
"USJのジェットコースターはなぜ後ろ向きに走ったのか",
"FACT FULLNESS 10の思い込みを乗り越えデータを基に世界を正しく見る習慣",
"思考の整理学",
"Clean Architecture 達人に学ぶソフトウェアの構造と設計",
"サピエンス全史",
"ハイパーインフレの人類学"
];
8-2. 結果の予測
ベース書籍は「ウォール街のランダム・ウォーカー 株式投資の不滅の心理」です。
そのため、同じ投資・お金ジャンルの書籍である
- はじめての人のための3000円投資生活
- 26歳の自分に受けさせたいお金の講義
が上位に来てほしいです。
また、日本語と英語の違いを超えて、
- The Little Book of Common Sense Investing(邦題:インデックス投資は勝者のゲーム)
も上位に来ることを期待しましょう。
8-3. 関連書籍の実行結果
実行結果は以下の通りです。
Word: The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns, Similarity: 0.41
Word: はじめての人のための3000円投資生活, Similarity: 0.39
Word: 26歳の自分に受けさせたいお金の講義, Similarity: 0.33
Word: FACT FULLNESS 10の思い込みを乗り越えデータを基に世界を正しく見る習慣, Similarity: 0.32
Word: 統計学が最強の学問である, Similarity: 0.28
Word: ハイパーインフレの人類学, Similarity: 0.26
Word: 父が娘に語る経済の話, Similarity: 0.25
Word: 筋トレが最強のソリューションである, Similarity: 0.25
Word: はじめてのGTD ストレスフリーの整理術, Similarity: 0.24
Word: 中動態の世界 意思と責任の考古学, Similarity: 0.22
Word: 思考の整理学, Similarity: 0.22
Word: 心という難問 空間・身体・意味, Similarity: 0.22
Word: Clean Architecture 達人に学ぶソフトウェアの構造と設計, Similarity: 0.21
Word: テスト駆動開発, Similarity: 0.18
Word: サピエンス全史, Similarity: 0.18
Word: USJのジェットコースターはなぜ後ろ向きに走ったのか, Similarity: 0.17
予想通り、投資・お金ジャンルの書籍が関連度の上位に上がってきました。
また、日本語と英語の言語的違いを超えて、「インデックスゲームは勝者のゲーム」が関連度1位になりました。
8-4. ちなみに小説だと?
小説の場合はうまくいきません。
const baseWord = "名前探しの放課後";
const candidateWords = [
"盲目的な恋と友情",
"冷たい校舎の時は止まる",
"忘れられた巨人",
"クララとお日さま",
"容疑者Xの献身",
"真夏の方程式",
"僕と未来屋の夏",
"斜陽",
"人間失格",
"銀河鉄道の夜",
"セロ弾きのゴーシュ",
"オリジン",
"天使と悪魔",
"羊と鋼の森",
"博士の愛した数式",
];
辻村深月の「名前探しの放課後」をベースワードにしています。
同じ辻村深月の
- 盲目的な恋と友情
- 冷たい校舎の時は止まる
が上位に来てほしいですが、
Word: 僕と未来屋の夏, Similarity: 0.33
Word: クララとお日さま, Similarity: 0.31
Word: 盲目的な恋と友情, Similarity: 0.30
Word: 容疑者Xの献身, Similarity: 0.30
Word: 真夏の方程式, Similarity: 0.29
Word: 銀河鉄道の夜, Similarity: 0.29
Word: 忘れられた巨人, Similarity: 0.27
Word: 天使と悪魔, Similarity: 0.26
Word: 人間失格, Similarity: 0.25
Word: 斜陽, Similarity: 0.25
Word: 冷たい校舎の時は止まる, Similarity: 0.25
Word: 博士の愛した数式, Similarity: 0.24
Word: オリジン, Similarity: 0.23
Word: 羊と鋼の森, Similarity: 0.23
Word: セロ弾きのゴーシュ, Similarity: 0.16
あくまでも与えた文字列の意味の近さで類似度を計算しているので、小説タイトルだけではうまく類似度を計算できませんでした。著者の情報も必要そうですね。
書籍の場合であればビジネス書など、タイトルが本の内容を意味している場合にうまくいきやすいです。
9. まとめ
OpenAIのEmbeddings APIを使うことで、
- 単語の意味的な距離を計算して類義語や関連語を検索できる
- 文脈や意味の近さに基づいた高精度な結果を得ることができる
- 単純な文字列マッチングを超え、意味的な関連性を活用した検索や推論が可能になる
という利点があります。
ぜひみなさまも一度試してみてください。
-
一般的にコサイン類似度は高次元になればなるほど0に近づいていく傾向があります。これは「次元の呪い」の一種で、二つのベクトルが直交する可能性が高くなるためです。詳しくは以下の記事を参照してください。
機械学習における次元の呪い(Curse of dimensionality)とは何?対策方法まで徹底解説 ↩